KDD 2020 | Facebook搜索向量召回读后感

作者:MXie
链接:https://zhuanlan.zhihu.com/p/184920498
编辑:深度传送门
这篇paper主要介绍的是Facebook过去几年在向量召回方面的工作。向量召回作为目前搜索/推荐比较常用的召回源,各家都积累了了一些适用于自身业务的经验。FB这篇文章的模型结构比较基础,就是传统的dssm结构,特征上融合了语义信息以及一些在ranking阶段常用的context及用户信息。但是在数据样本的选择构建上,融合新的召回源,整个搜索链路的优化,以及逐步递进解决问题的思路上有很多我们可以学习的地方。可以将这篇paper提到的某些trick融入到我们自身的业务上。
向量召回的本质在于通过模型学习到query以及doc的embedding,利用embedding的信息去表达,从而利用近邻搜索的方式找到与目标query相关的doc。在向量召回阶段需要考虑到两个问题,一个是极大候选集带来的离线训练以及线上服务的压力,另外一个是与现有的term matching共存使用的问题。
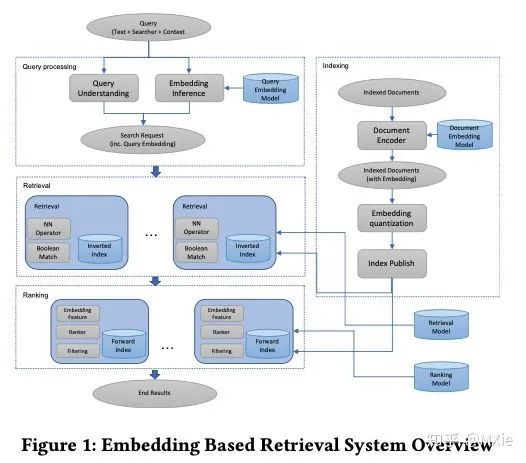
模型离线训练方面
模型结构方面,FB选用的是经典的双塔结构,一边是搜索request相关的信息(query encoder),包括query,user,context等,另一边是doc相关的信息(document encoder),之后通过相似度计算得出最后的分数。FB将这种融合了文本信息和搜索用户新的embedding起名为unified embedding,工业界这种特征使用方式已经是双塔结构的标配。
不同于rank使用auc作为离线衡量指标,FB采用了top K recall的方式进行衡量。下面公式中的T为基于业务逻辑(如点击/人工标注)圈定出的target doc,而 

损失函数方面,FB采用的是triplet loss。给点一个三元组 




训练数据的选取以及处理上是这篇文章最为着重介绍的地方。通过实验,FB采用点击数据作为正样本,随机采样数据作为负样本。
负样本的判定上有两种方案,利用展现未点击的数据或者随机选取样本作为负例,通过实验发现,随机选取作为负例的实验效果更好,作者给出的解释是在触发阶段,模型遇到的大部分问题都是很容易被解决的easy case,选用展现未点击数据作为负例对于hard case比较友好,但是在解决easy case的能力上并不由于随机选取的方法。
正样本的选取上同样有两种方案,利用点击数据或者展现数据。通过实验发现两者的效果基本相近,在点击的数据基础上添加展现数据也没有收益。
特征工程方面主要有下面三个部分:
文本信息:char粒度的n-gram是一种比较常用的方案,相较于单词粒度的n-gram,他的优势在于特征空间比较小,serving和training阶段的成本都更低。同时,这种方式可以更好的减少out-of-vocabulary(误拼/方言)情况。通过实验发现,在char粒度特征的基础之上添加单词粒度的特征,在有一定embedding查表冲撞的基础上,模型依然有稳定的收益。单纯依赖文本信息的模型相比较term match的优势在于能够处理模糊匹配以及识别出term中最重要的信息。
context信息,在query侧,添加搜索用户的地理位置及语言信息,在doc侧,添加一些公开的例如group这种信息。
社交embedding信息:基于FB大量的用户行为数据,另外训练一个模型生成用户和entity的embedding。我个人觉得这应该是直接利用ranking侧生产的特征。
线上服务方面
FB开始采用的是在现有系统的基础上再搭建一套向量召回的服务,但是这样会遇到以下几个问题。
性能上撑不住
维护两套索引系统,成本太高
term match与embedding match两套系统召回的doc重复度很高
因此FB重建了一同融合term match与embedding match的召回系统,搞了大名鼎鼎的Faiss,通过Faiss进行向量压缩并且将它融合进倒排索引中。这套系统有两个优势
可以同时优化term matching和embedding matching。
支持在向量召回的基础上添加term matching的限制,从而提升召回的效率
向量压缩主要包括两个部分:
Coarse quantization:粗糙压缩,通过k-means等手段进行聚类,通过聚类的结果来表达embedding。
product quantization:精细化的压缩,从而可以更高效的计算embedding间距离。
在做向量压缩的时候,比较重要的几个参数是coarse quantization的聚类数,product qquantization的bytes长度以及分配给query embedding的cluster数量。这些参数基本就是基于各家的业务实验科学了。
整体系统融合
首先作者介绍了如何将向量召回融入到term match系统中。线上召回的时候先找到相关的cluster,再根据probe约束,做embedding相似度计算,召回相关的docs,这里面的probe是系统的一个参数。模型serve处理上,也是比较传统的query处线上实时预估,docs的embedding则存储在索引中。
考虑到性能以及业务逻辑,向量召回不会对全部的query起作用,比如一些简单的query,本身就包含特定的需求,向量召回并不会提供额外的信息。在索引方面,只会存储最近一个月有活跃行为的信息。在实践中很多时候是根据召回数确认是否需要调用向量召回。
向量召回作为retrieval的一个部分,处于整体搜索链路比较前的位置,有可能有召回到较好的doc但是在排序阶段没有办法排到前边去,排序模型对新的数据不敏感,没有办法很好的处理新的数据分布。因此FB提出了下边两种方案来解决这个问题:
将召回生成的embedding作为ranking阶段的特征,可以直接将embedding作为特征或者计算query和doc的embedding各种相似度,通过大量实验证明,consine similarity有较好的结果。
为了解决向量召回准确率较低的问题,将向量召回的结果直接进行人工标注,然后再基于标注的结果进行训练。我个人认为这种方法比较暴力并且效率比较低。
Advanced Topics
Hard Mining,Hard mining的主要作用是构造一个对于解决当前业务问题效率更高的训练集,作者这里针对与正负样本提出了不同的解决办法。
负样本:通过实验数据发现,即使增加了社交信息等context信息,模型依旧对于人名搜索不是很友好。这种状况很有可能是负样本过于简单导致的,因为负样本是随机选择,这样会导致人名大概率与target不同。针对这种问题,作者提出的解决方案是找到与正样本近似的负样本。
在训练时,找到同batch内与该三元组中正例最相似的其他三元组的正例样本作为负例。这种方法的缺陷在于在batch内找负样本很难找到与正例较为相似的,也就无法提供足够的难度给到模型。
另外一种方法是对于每一个query生成top k的docs,再根据上边提到的生成负例方法找到负例组成新的三元组,用新的数据进行训练。
通过实验发现,上述两种方法并没有比直接random sample的负例效果好,分析数据后发现这是由于模型对于简单的样本表现能力反而被削弱了,调整了hard mining的比例后,效果有了大幅度提升。同时,对于hard selection的策略,基于实验发现并不是选择与正例样本最接近的样本作为负样本效果最好,而是应该选取101-500位的。作者也提到了随机负样本和hard mining负样本两者的组合方式。当两者mixed训练时,比例在100:1效果最好。当两者分开训练时,先训练hard samples再训练random samples效果更好。
正样本:作者的思路在于将挖掘之前没有被召回过的正例,作者提到他的做法是 we mined potential target results for failed search sessions from searchers’ activity log,我理解的是在用户没有点击的搜索行为中,去挖掘潜在的相关doc,这个挖掘方法是通过向量召回top k作为正样本加入模型中。这是我的猜测,大家如果有其他的sense,可以留言交流。
Embedding Ensemble ,整篇文章都提到了训练样本可以分为easy和hard,这两部分对于模型都很重要,复杂样本可以提升模型的准确性,简单样本可以更好的模拟整个召回数据分布,但是如何最大程度的利用训练数据就变成了一个问题。作者提出了一个multi-stage的方法,第一个stage关注recall,第二个stage关注与复杂问题的解决。两个方案是weighted concatenation和cascade model。
weighted concatenation:
,考虑到线上serving的时候query和doc侧的embedding都要保留只有一个,因此作者考虑归一化后进行计算, 在第二个stage的处理上,作者比较了使用hard mining和展现未点击作为负样本两种策略,离线效果上展现未点击的召回率较高,但是这种方法的准确性较差,线上效果也没有使用hard mining好。

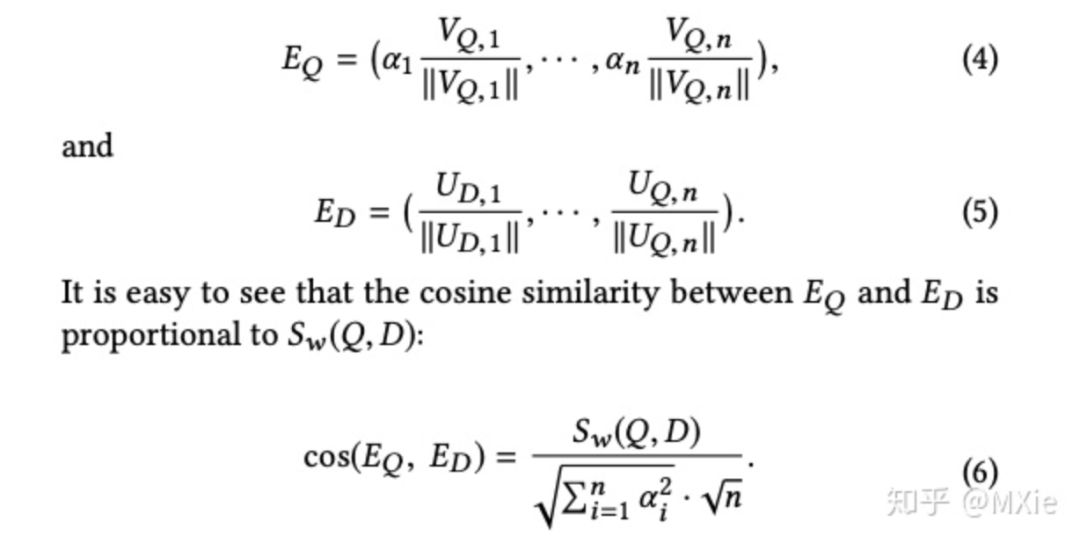
Cascade Model:与weighted方法不同,cascade需要得到第一阶段的结果之后才会进行第二阶段的计算。观察实验诗句发现,unified embedding在一些简单的text匹配上反而表现的没有基础模型好,这是由于context信息起到了过重的作用。为了解决这个问题,作者提出了使用text-matching的方法做第一阶段召回,用unified-embedding的方法做第二阶段召回。
整篇文章完整的介绍了向量检索从0到1的过程,无论在算法还是工程上都有很多值得我们借鉴和学习的地方,在分析问题和解决问题的思路上我觉得给调参工程师树立了很好的榜样,要针对特定的问题做特定的分析从而给出合理的解决方案,而不是无脑调参。
由于微信平台算法改版,公号内容将不再以时间排序展示,如果大家想第一时间看到我们的推送,强烈建议星标我们和给我们多点点【在看】。星标具体步骤为:
(1)点击页面最上方"AINLP",进入公众号主页。
(2)点击右上角的小点点,在弹出页面点击“设为星标”,就可以啦。
感谢支持,比心

推荐阅读
征稿启示| 200元稿费+5000DBC(价值20个小时GPU算力)
完结撒花!李宏毅老师深度学习与人类语言处理课程视频及课件(附下载)
模型压缩实践系列之——bert-of-theseus,一个非常亲民的bert压缩方法
文本自动摘要任务的“不完全”心得总结番外篇——submodular函数优化
斯坦福大学NLP组Python深度学习自然语言处理工具Stanza试用
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLPer(id:ainlper),备注工作/研究方向+加群目的。

阅读至此了,分享、点赞、在看三选一吧🙏

