学界 | 机器学习如何从上游抑制歧视性行为?斯坦福 AI 实验室的最新成果给出了答案

将控制权交到关注公平的有关方手上。
AI 科技评论按:随着机器学习系统越来越多地运用于许多重大决策中,如何对其公平性实现精细地控制已经成了我们亟需解决的问题。为解决这一问题,目前已有一些研究人员通过引入公平机器学习模型来平衡准确性和公平性,然而,一些包括公司、政府在内的机构态度不明朗甚至持与公平对立的立场,所以他们往往不会选择使用这些公平模型。在这样的环境下,斯坦福 AI 实验室的研究人员通过引入了一种新的方法,即令关注公平的有关方通过对不公平性进行具体限制来控制表示的公平性,从而对机器学习中的公平性实现可控性。斯坦福 AI 实验室发布文章介绍了这一成果,AI 科技评论编译如下。

01 概述
机器学习系统越来越多地被应用于高风险决策中,对信用评分、刑事判决等领域都带来了影响。这就提出了一个亟待解决的问题:我们如何确保这些制度不因种族、性别、残疾或其他少数群体身份而产生歧视性行为?为解决这一问题,一些研究人员通过引入公平机器学习模型来平衡准确性和公平性;然而,一些包括公司、政府在内的机构态度不明朗甚至持与公平对立的立场,所以他们往往不会选择使用这些公平模型。
值得庆幸的是,目前已有研究人员提出了一些用以学习公平表示的方法。关注公平的有关方(如数据采集者、社区组织者或监管机构) 使用这些方法,可以将数据转换为公平表示,然后仅呈现表示,进一步提高公平性,从而使所有下游机器学习模型更难产生歧视性行为。
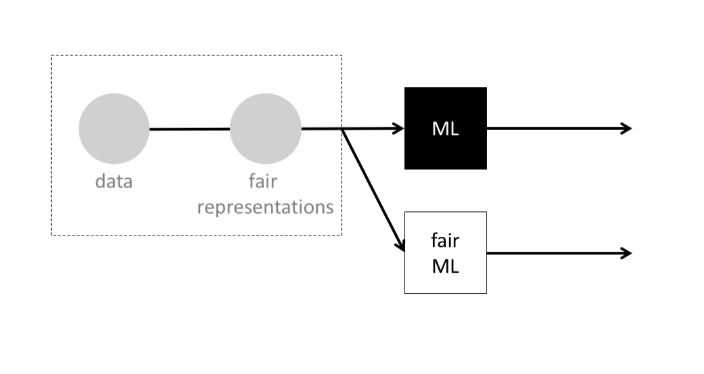
图 1 学习和最终以控制良好的数据公平表示呈现,能够抑制下游机器学习产生歧视性行为
在这篇文章中,我们介绍了一种基于理论的机器学习公平表示方法,并且我们还发现一系列现有方法都属于该方法的特例。此外,我们还注意到所有现有的机器学习公平表示方法,也可以用来平衡有用性和公平性,产生有用性和公平性两者相平衡的表示。然后有关方必须多次运行学习流程,直到找到他们满意的表示结果。基于这种理论,我们引入了一种新的方法,即令有关方通过对不公平性进行具体限制来控制表示的公平性。与早期的公平表示相比,这种方式可以让机器更快地学到,同时满足多个公平概念的要求,并涵盖更多有用的信息。
02 公平表示的理论方法
我们首先假设得到一组通常用来表示人的数据点(x)以及他们的敏感属性(u),这些属性通常是指他们的种族、性别或其他少数群体身份。我们必须学习一个模型(qϕ)来将任一数据点映射到新的表示 (z) 上。我们的目标是双重的:该表示应该是能够表达出信息的,即包含数据点相关的大量有用信息;同时这一表示应该是公平的,即包含有关敏感属性的限制信息;这样的做法可以抑制机器学习下游产生歧视性行为(为了简洁起见,我们聚焦人口均等,这是一种非常直观和严格的公平概念,但我们的方法适用于许多公平概念,如后面的结果所示)。请注意,仅仅从数据中删除敏感属性(例如种族)并不能满足这种公平概念,因为下游机器学习模型可能会基于相关特征(例如邮政编码),这种做法称为「划红线注销(redlining)」。
首先,我们将我们的目标转化为互信息(mutual information)的信息理论概念。两个变量之间的互信息被正式定义为变量的联合概率与变量的边缘概率乘积之间的 KL 散度(Kullback-Leibler Divergence)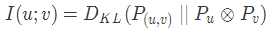
为了实现表现力,我们希望最大化数据点 x 和以敏感属性 u 条件的表示 z 之间的互信息:max I(x;z∣u)。(通过限制敏感属性,我们确保刺激数据点中与敏感属性相关的信息出现在表示中。)
为了实现公平,我们希望限制表示 z 和敏感属性 u 之间的互信息:I(z;u)<ϵ,其中 ϵ 由有关方设置。
接下来,由于两组互信息都很难得到优化,我们需要寻找近似值:
我们用最大化下边界−Lr≤I(x;z∣u)来取代最大化 I(x;z∣u)的方法,而最大化下边界则依赖于我们引入的一个新模型 pθ(x∣z,u)。我们可以明显发现,最大化−Lr 会有利于映射出,表示 z 加上敏感属性 u 得到的新模型可以成功地重建数据点 x。
接着,我们通过约束上限 C1≥I(z;u)来代替对 I(z;u)的约束。很显然,对 C1 的约束则可以阻止复杂表示。
或者我们也可以约束与 I(z;u)更相关的近似值——C2,它依赖于我们引入的一个新模型 pψ(u∣z)。而约束 C2 可以阻止新模型 pψ 使用表示 z 来重构敏感属性 u 的映射。
综上所述,我们的最终目标是找到模型 qϕ、 pθ, 和 pψ 来帮助成功实现对数据点 x 的重建,同时限制表示 z 的复杂性,并限制敏感属性 u 的重构:

图 2 学习公平表示的「硬约束」目标
其中 ϵ1 和 ϵ2 是有关方设定的限制。
这为我们提供了一个学习公平表示的原则性方法。我们还得到了一个巧妙的发现:事实证明,现有的一系列学习公平表示的方法优化了我们的双重目标,得到一个「软正则化」(soft-regularized)版本!

图 3 学习公平表示的「软正则化」损失函数
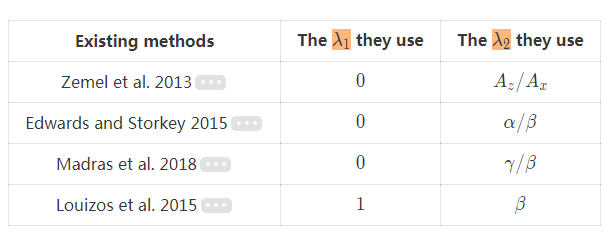
我们可以看到该框架泛化了一系列现有方法!
03 学习可控公平表示
现在让我们仔细观察「软正则化」损失函数,可以明显发现现有的学习公平表示的方法会产生有用性和公平性兼具的表示,表现力和公平性之间的平衡由 λs 的选择所控制。如果我们能优化我们的「硬约束」目标,那么有关方就可以通过设置 ϵ,来对不公平性进行具体限制。
所以,我们引入了:

图 5 机器学习可控公平表示的损失函数
直观而言该损失函数意味着,每当我们考虑由于 C1>ϵ1 或 C2>ϵ2 导致的不公平时,λs 将额外强调未满足的约束;这种额外的强调将一直持续到 C1 和 C2 满足有关方设定的限制为止。而当 C1 和 C2 在安全在限制范围内时,将优先考虑最小化 Lr ,进而有利于产生富有表现力的表示。
04 结果
有了最后一块拼图,剩下的就是评估我们的理论是否能使其在实践中学习可控的公平表现。为了进行评估,我们学习了三个真实数据集的表示:
UCI 德国信用数据集,包含 1,000 个人,其中二进制敏感属性满足条件 age<50 / age>50 的应受到保护。
来自美国人口普查的 40000 名成人的 UCI 成人数据集,其中二进制敏感属性 Man / Woman 应受到保护。(性别不是二元的,在使用这些数据集时将性别视为二元是有问题的,也是这项工作的局限)
60,000 名患者的遗传健康数据集,其中要保护的敏感属性是年龄和性别的交集:年龄组 (9 个可能的年龄组) × 性别 (Man / Woman)
不出所料,我们的结果证实在所有三组学习公平表示中,有关方对 ϵ1 和ϵ2 的选择,控制了不公平的近似值 C1 和 C2。
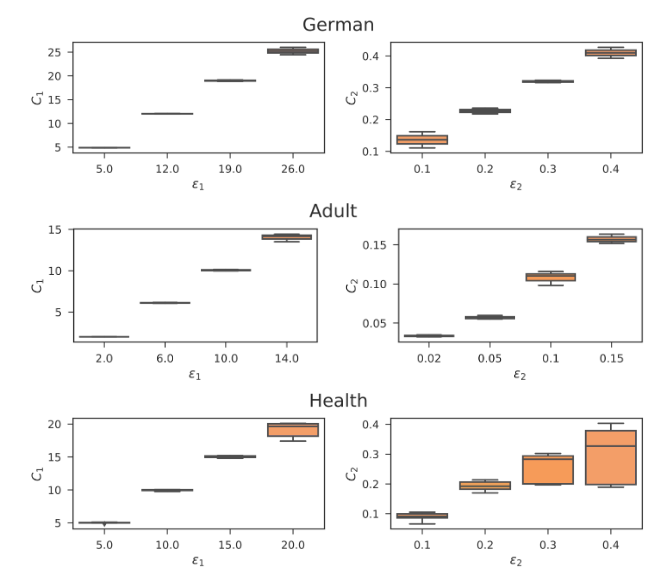
图 6 三个真实数据集实验数据,我们学到了满足 C1 ≈ ϵ1 和 C2 ≈ ϵ2 的表示
结果还表明,与现有方法相比,我们的方法可以产生更具表现力的表示。
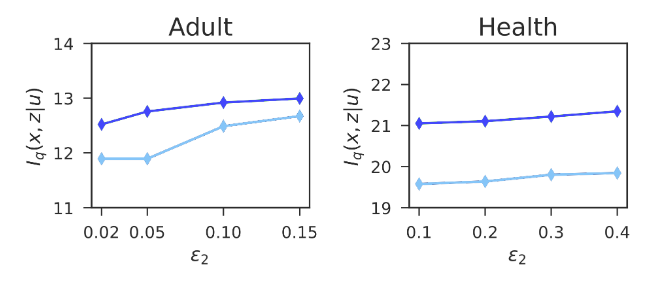
图 7 我们的方法(深蓝色),现有的方法(浅蓝色)
并且,我们的方法能够同时处理许多公平的概念。
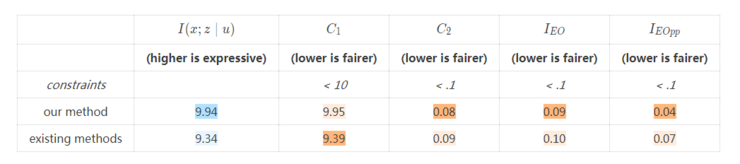
图 8: 当学习满足许多(在人口统计、几率均等和机会均等上的)公平性约束的成人数据集表示时,我们的方法学习的表示更具表现力,并且表现比除了一种公平标准外的所有标准都更好。
虽然最后两个结果可能看起来令人惊讶,但它们得出这一结果的原因是,现有方法要求有关方多次运行学习过程直到找到他们认为大致满意的表示为止,而我们的方法直接优化了尽可能具有表现力的表示,同时也同等满足了所有有关方对表示不公平的限制。
05 总结
为了补充公司和政府可以选择使用的公平机器学习模型,这项工作朝着将公平机器学习的控制权交给关注公平的一方(如数据采集者、社区组织者或监管机构))迈出了一步。我们为学习公平表示提供了一种理论方法,使机器学习下游更难以产生歧视性行为,并且提供了一种新方法,使关注公平的一方能够通过 ϵ 来对不公平性进行特定限制从而控制表示的公平性。
研究者在进行公平机器学习的研究工作时,认识到局限性和盲点尤为重要;否则就会冒着开发出难以实际应用的解决方案的风险,同时掩盖其他人所同样付出的努力。我们这项成果的一个主要限制是,关注公平的一方的 ϵ 限制了对不公平性的近似值,我们也希望未来的工作可以更进一步,并能够对 ε 进行映射从而正式保证机器学习下游的公平性。这项成果的另一个可能存在的限制是,像许多公平机器学习的研究领域一样,中心人口均等、几率和机会均等等公平概念所带来的限制。我们认为,未来的工作需要与社会公正所依据的平等概念建立更深层次的联系,这样才能避免狭隘的技术解决方案主义,并建立更公平的机器学习。
论文:Learning Controllable Fair Representations
论文作者:Jiaming Song*, Pratyusha Kalluri*, Aditya Grover, Shengjia Zhao, Stefano Ermon
论文下载地址:https://arxiv.org/abs/1812.04218
via http://ai.stanford.edu/blog/controllable-fairness/






