一行代码12倍加速Bert推理,OpenAI编程语言加持的引擎火了
机器之心报道
项目作者表示,未来还将在预热速度、训练支持、多 GPU 支持、量化和硬件支持等多方面改进推理引擎 Kernl。
一行代码的威力到底有多大?今天我们要介绍的这个 Kernl 库,用户只需一行代码,在 GPU 上就能以快几倍的速度运行 Pytorch transformer 模型,从而极大的加快了模型的推理速度。
具体而言,有了 Kernl 的加持,Bert 的推理速度比 Hugging Face 基线快了 12 倍。这一成果主要得益于 Kernl 用新的 OpenAI 编程语言 Triton 和 TorchDynamo 编写了定制的 GPU 内核。项目作者来自 Lefebvre Sarrut。
GitHub 地址:https://github.com/ELS-RD/kernl/
以下是 Kernl 与其他推理引擎的比较,横坐标中括号里的数字分别表示 batch size、序列长度,纵坐标为推理加速情况。
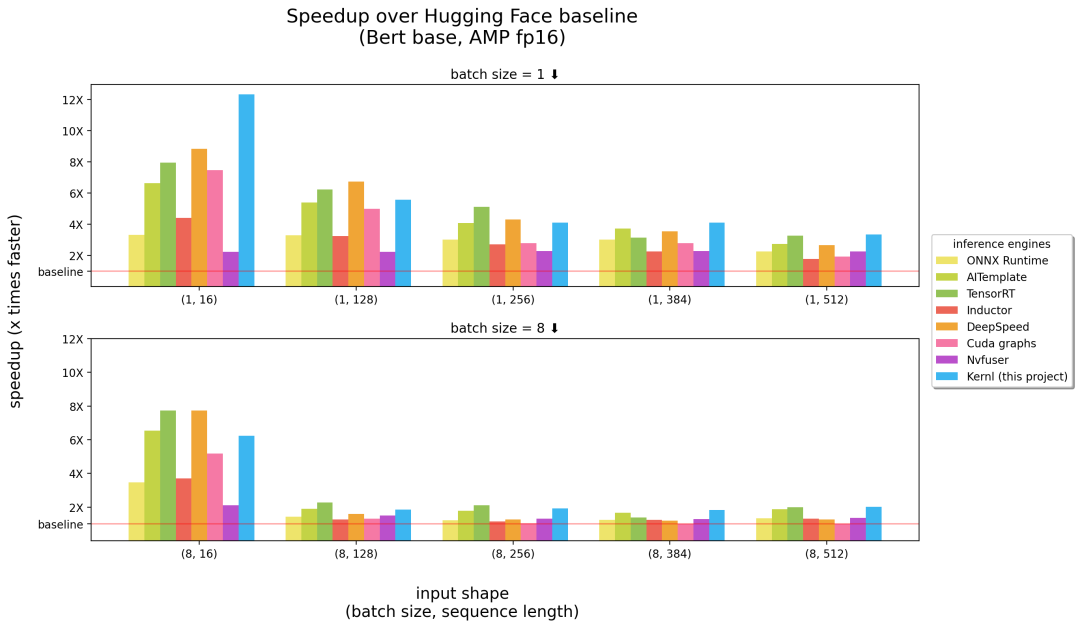
基准测试在 3090 RTX GPU 运行,以及 12 核 Intel CPU。
由上述结果可得,在长序列输入这一块,Kernl 可以说是最快的推理引擎(上图中的右半部分),在短输入序列上接近英伟达的 TensorRT(上图中的左半部分)。除此以外,Kernl 内核代码非常简短,易于理解和修改。该项目甚至添加了 Triton 调试器和工具 (基于 Fx) 来简化内核替换,因此不需要修改 PyTorch 模型源代码。
项目作者 Michaël Benesty 对这一研究进行了总结,他们发布的 Kernl 是一个用于加速 transformer 推理的库,速度非常快,有时会到达 SOTA 性能,可破解以匹配大多数 transformer 架构。
他们还在 T5 上做了测试,速度提高 6 倍,Benesty 表示这仅仅是个开始。
为什么创建 Kernl?
在 Lefebvre Sarrut,项目作者在生产中运行几个 transformers 模型,其中一些对延迟敏感,主要是搜索和 recsys。他们还在使用 OnnxRuntime 和 TensorRT,甚至创建了 transformer-deploy OSS 库来与社区分享知识。
最近,作者在测试生成语言,并努力加速它们。然而事实证明,使用传统工具做到这些非常困难。在他们看来,Onnx 是另一种有趣的格式,它是一种针对机器学习所设计的开放式文件格式,用于存储训练好的模型,具有广泛的硬件支持。
但是,当他们处理新的 LLM 架构时,Onnx 生态系统(主要是推理引擎)存在以下几种限制:
没有控制流的模型导出到 Onnx 很简单,这是因为可以依赖跟踪。但是动态行为更难获得;
与 PyTorch 不同,ONNX Runtime/TensorRT 还没有原生支持实现张量并行的多 GPU 任务;
TensorRT 无法为具有相同配置文件的 transformer 模型管理 2 个动态轴。但由于通常希望能够提供不同长度的输入,因此需要每个批大小构建 1 个模型;
非常大的模型很常见,但 Onnx(作为 protobuff 文件)在文件大小方面有一些限制,需要将权重存储在模型之外来解决问题。
一个非常烦人的事实是新模型永远不会被加速,你需要等着其他人来为此编写自定义 CUDA 内核。现有解决方案并不是不好,OnnxRuntime 的一大优点是它的多硬件支持,TensorRT 则以非常快速著称。
所以,项目作者想要在 Python/PyTorch 上有像 TensorRT 一样快的优化器,这也是他们创建 Kernl 的原因。
如何做到?
内存带宽通常是深度学习的瓶颈,为了加速推理,减少内存访问往往是一个很好的策略。在短输入序列上,瓶颈通常与 CPU 开销有关,它必须被消除。项目作者主要利用了以下 3 项技术:
首先是 OpenAI Triton,它是一种编写 CUDA 等 GPU 内核的语言,不要将它与 Nvidia Triton 推理服务器混淆,它的效率更高。几个操作的融合实现了改进,使得他们不在 GPU 内存中保留中间结果的情况下链接计算。作者使用它重写注意力(由 Flash Attention 替换)、线性层和激活以及 Layernorm/Rmsnorm。
其次是 CUDA 图。在预热(warmup)步骤中,它将保存每个启动的内核及它们的参数。然后,项目作者重建了整个推理过程。
最后是 TorchDynamo,这个由 Meta 提出的原型机帮助项目作者应对动态行为。在预热步骤中,它会跟踪模型并提供一个 Fx 图(静态计算图)。他们使用自己的内核替换了 Fx 图的一些操作,并在 Python 中重新编译。
未来,项目路线图将涵盖更快的预热、ragged 推理(padding 中没有损失计算)、训练支持(长序列支持)、多 GPU 支持(多并行化模式)、量化(PTQ)、新 batch 的 Cutlass 内核测试以及提升硬件支持等。
更多详细内容请参阅原项目。
令人心动的AI offer:特斯拉、阿里达摩院、荣耀等2023校招、社招等你来
「TalentAI」将持续带来人工智能相关职位的招聘信息,欢迎正在找工作与看新机会的朋友关注,也欢迎企业伙伴与我们联系合作。本期「TalentAI」推荐职位如下:
上海人工智能实验室校招与社招:机器学习/深度学习方向、计算机图形学方向、自然语言处理方向、多媒体处理方向等。
荣耀终端社招:图像识别处理、视频行为识别、计算机图形学算法、NLP算法等。
数坤科技社招:算法leader/总监、技术总监/经理、前端开发总监/经理。
苏州讯飞社招:算法实习生、算法与引擎开发工程师、音频DSP软件工程师、音频嵌入式软件工程师。
博世集团校招:人工智能系统架构师、Devops/数字孪生应用工程师、车联网信息安全技术顾问、车辆信息安全流程体系顾问。
第四范式校招: 机器学习算法工程师、机器学习系统工程师、前端开发工程师、产品经理等。
启元世界校招:强化学习算法工程师、NLP算法工程师、物理动画AI算法工程师、虚拟人算法工程师。
特斯拉社招:Site Reliability Engineer,Software QA Engineer等。
毫末智行招聘:决策规划专家、运动控制算法工程师、ADAS功能模型开发工程师、AEB算法专家、电路设计工程师等。
地平线社招:感知融合方向算法工程师、SLAM/3D算法工程师。
极氪智能科技校招:智能驾驶规控算法工程师、智能驾驶感知算法工程师、车联网安全研究员等。

© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com




