【斯坦福CS224N硬核课】如何融合知识到语言模型中,60页ppt

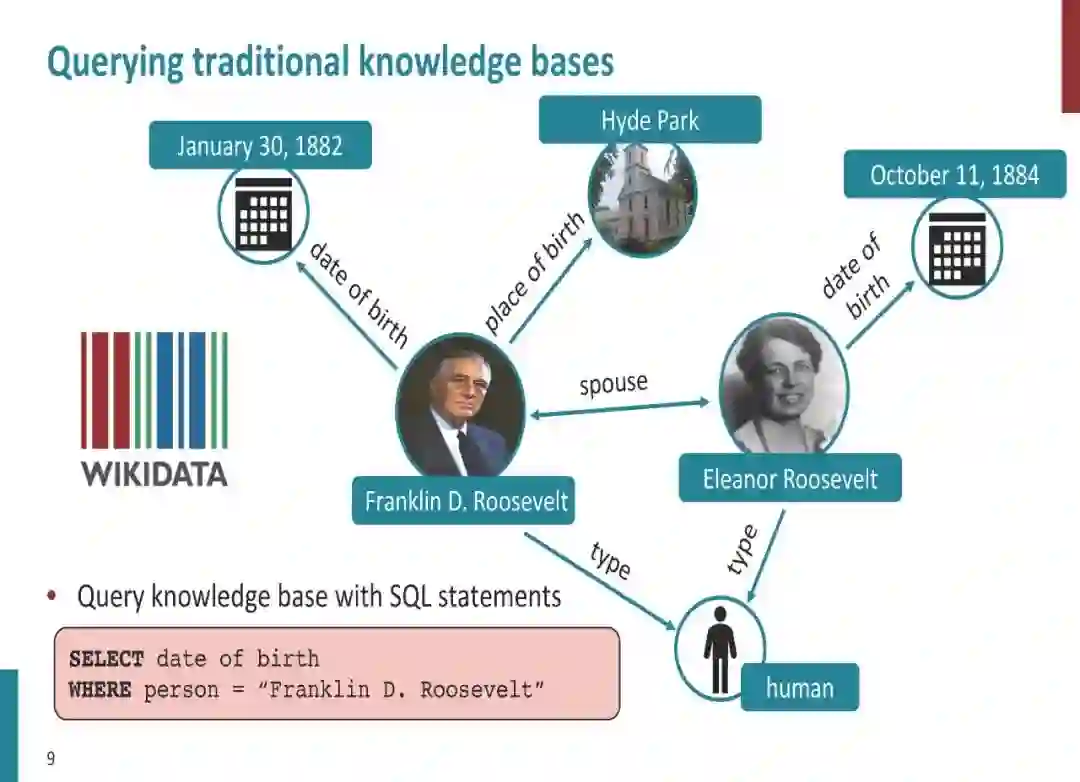
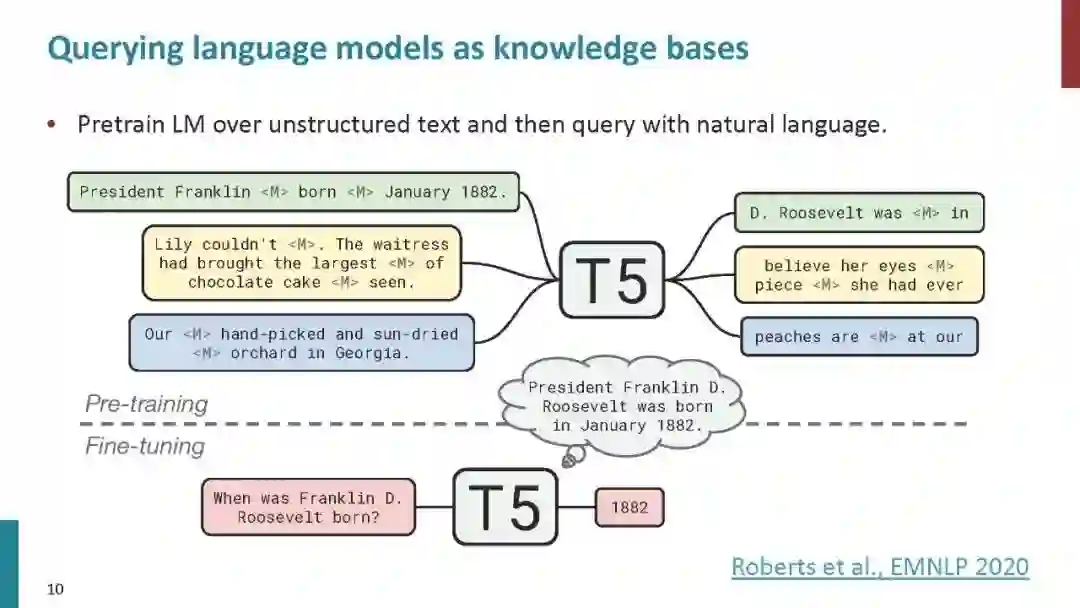
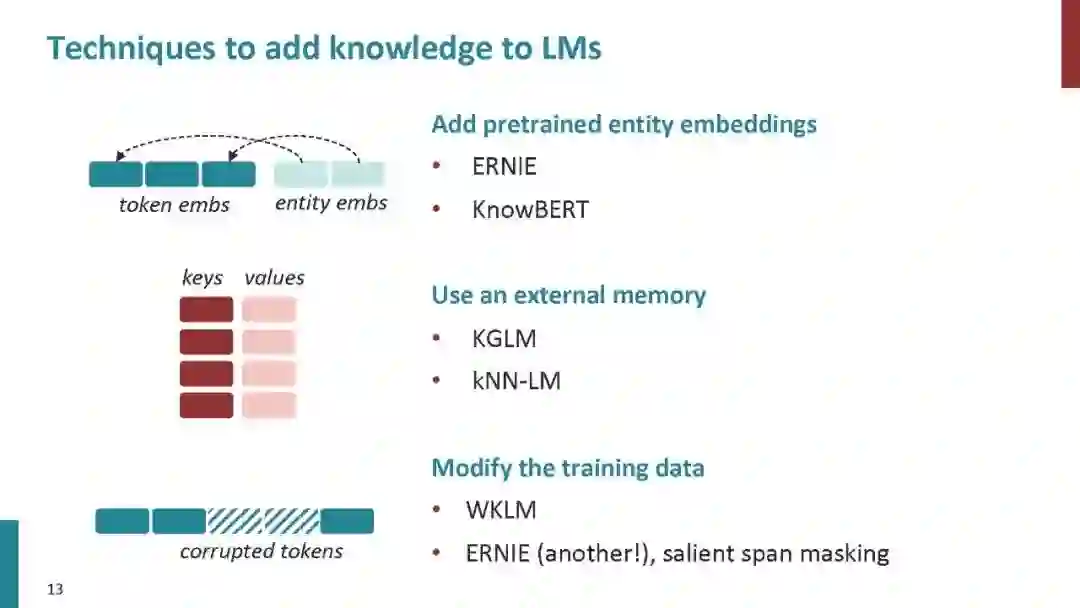
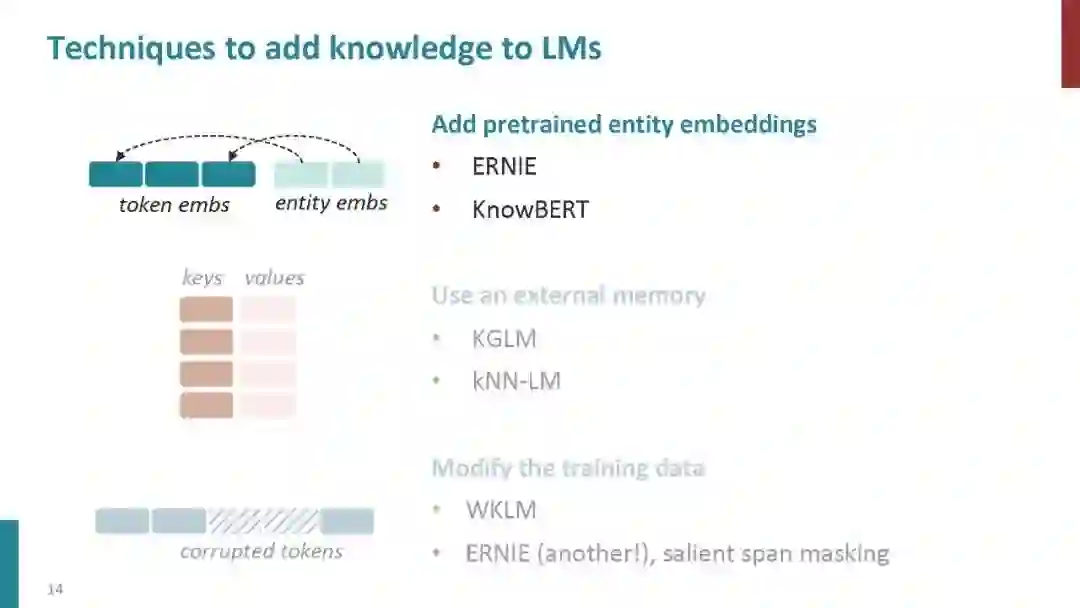
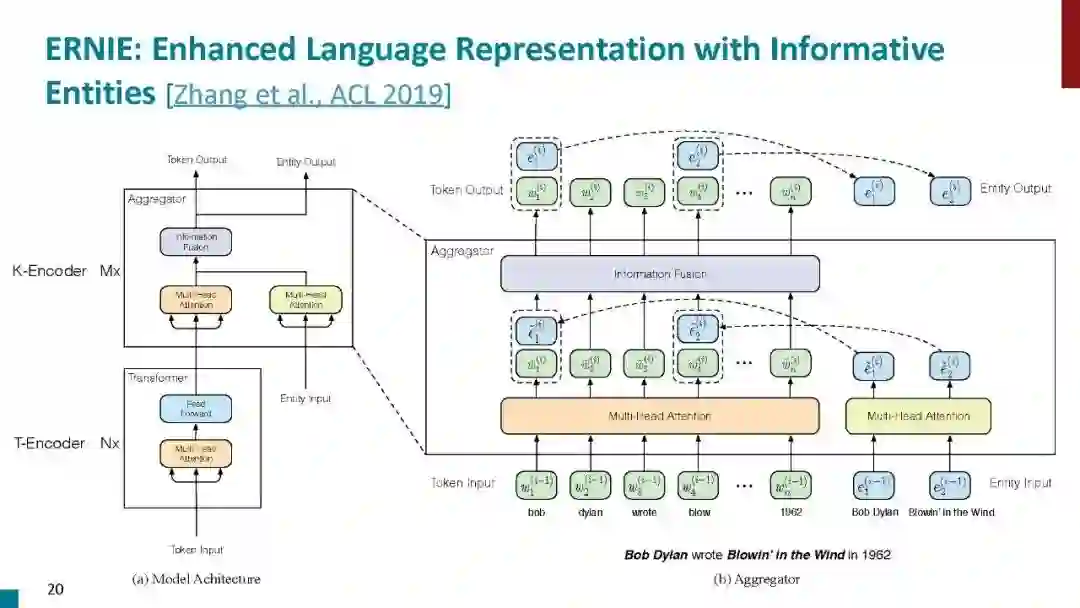
以ELMO (Peters et al., 2018)、GPT (Radford et al., 2018)和BERT (Devlin et al., 2019)为代表的预训练语言模型受到了广泛关注,并提出了大量的变体模型。在这些研究中,一些研究人员致力于将知识引入语言模型(Levine et al., 2019; Lauscher et al., 2019; Liu et al., 2019; Zhang et al., 2019b)。ERNIE-Baidu (Sun et al., 2019)引入新的掩蔽单元,如短语和实体,在这些掩蔽单元中学习知识信息。作为奖励,来自短语和实体的语法和语义信息被隐式地集成到语言模型中。此外,ERNIE-Tsinghua (Zhang et al., 2019a)探索了一种不同的知识信息,将知识图谱整合到BERT中,同时学习词汇、句法和知识信息。Xiong et al. (2019) 将实体替换检查任务引入到预先训练的语言模型中,并改进若干与实体相关的下游任务,如问答和实体类型。Wang et al.(2020)提出了一种将知识注入语言模型的插件方式,他们的方法将不同种类的知识保存在不同的适配器中。这些方法所引入的知识信息并没有很重视KG中图表化的知识。
http://web.stanford.edu/class/cs224n/index.html#schedule














专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“LM60” 可以获取《【斯坦福CS224N硬核课】如何融合知识到语言模型中,60页ppt》专知下载链接索引



登录查看更多
相关内容



相关VIP内容
相关资讯
相关论文