【新知】自动化所雷震等研究人员提出 FaceBoxes:实时、高准确率的 CPU 面部检测器
选自arXiv
要想用神经网络有效地进行面部检测等操作,往往需要 GPU 等高速并行的计算设备。如果仅使用 CPU,往往会遇到速度与准确度不能兼得的困境。为了解决这个问题,中科院自动化所雷震等研究人员提出了一种名叫 FaceBoxes 的新方法,在保证了 CPU 面部识别的准确度的同时,还做到了实时处理。本文由机器之心编译。
论文:一种使用 CPU 的高准确度实时面部检测器(FaceBoxes: A CPU Real-time Face Detector with High Accuracy)

论文地址:https://arxiv.org/abs/1708.05234
尽管面部检测领域已经取得了巨大的进展,但要在 CPU 上满足高表现水平的同时实现实时的速度仍然还是一个悬而未决的难题,因为用于面部检测的有效模型往往需要过高的计算基础。为了解决这个难题,我们提出了一种全新的面部检测器 FaceBoxes,它在速度和准确度上都表现优异。具体而言,我们的方法具有轻量却又强大的网络结构,它由快速消化的卷积层(RDCL:Rapidly Digested Convolutional Layers)和多尺度卷积层(MSCL:Multiple Scale Convolutional Layers)构成。RDCL 可以让 FaceBoxes 在 CPU 上实现实时的速度;而 MSCL 的目的是在不同层上丰富感受野(receptive field)和离散化 anchor,以便处理不同尺度的面部。此外,我们还提出了一种新的 anchor 密度化策略,可以让图像上不同类型的 anchor 具有相同的密度,这可以显著提升小面部的召回率。由此,我们提出的这个检测器在 VGA 分辨率的图像上可以在单核 CPU 上以 20 FPS 的速度运行,也可在单个 GPU 上以 125 FPS 的速度运行。此外,FaceBoxes 的速度不会因人脸的数量发生改变。我们对这种方法进行了全面的评估,并且在 AFW、PASCAL 人脸数据集和 FDDB 等多个面部检测基准数据集上都得到了当前最佳的检测表现。
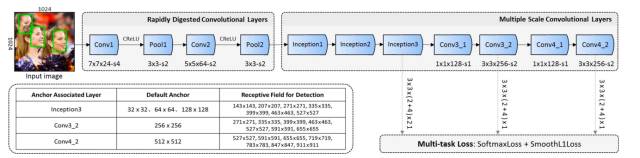
图 1:FaceBoxes 的架构以及我们的 anchor 设计的详细信息表
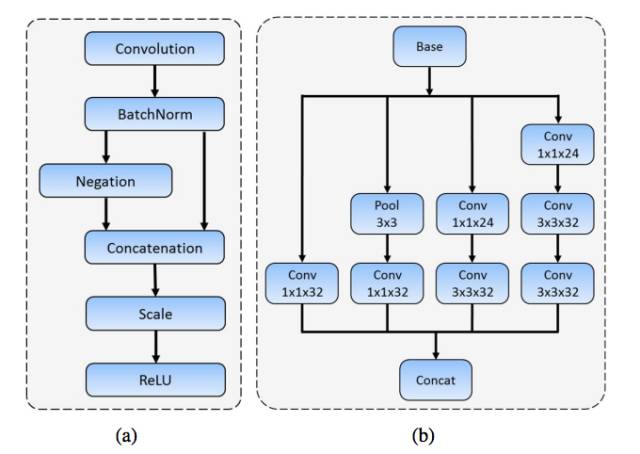
图 2:(a) C.ReLU 模块,其中 Negation 只是简单地为 Convolution 的输出乘上 -1。(b) Inception 模块
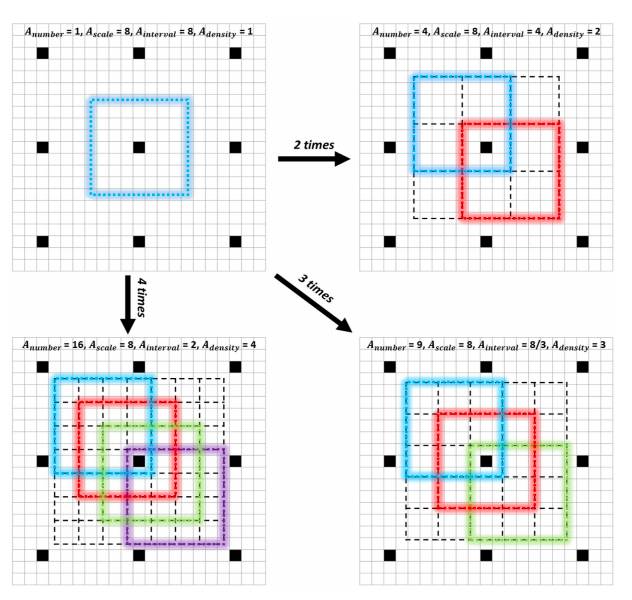
图 3:anchor 密度化示例。为了清楚说明,我们仅对一个感受野中心(即中心的黑色单元)的 anchor 进行了密度化,并且只标出了对角 anchor 的颜色
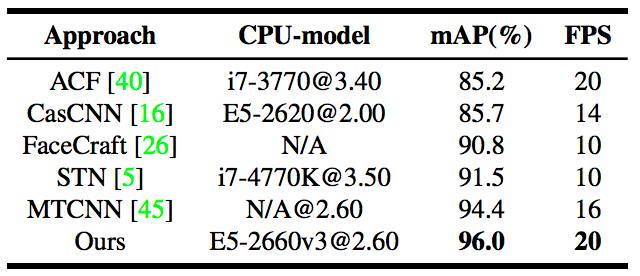
表 1:不同方法的整体 CPU 推理时间和 mAP 比较。FPS 是在 CPU 上处理 VGA 分辨率图像的速度,mAP 的意思是在 FDDB 上 1000 个假正例的真正例率。要提一下,STN [5] 的 mAP 是 179 个假正例的真正例率,并且使用了 ROI 卷积,它的 FPS 可以提速到 30,而召回率仅会降低 0.6%
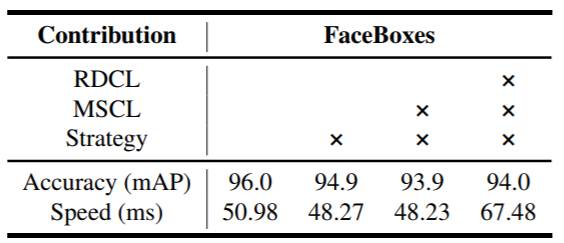
表 2:FaceBoxes 在 FDDB 数据集上增添不同方法时的结果变化。Accuracy (mAP) 表示 1000 个假正例的真正例率。Speed (ms) 是在 CPU 上处理 VGA 分辨率图像的速度
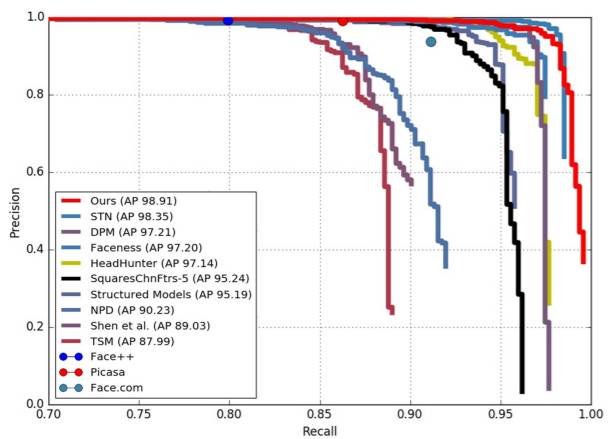
图 4:在 AFW 数据集上的精度召回率曲线
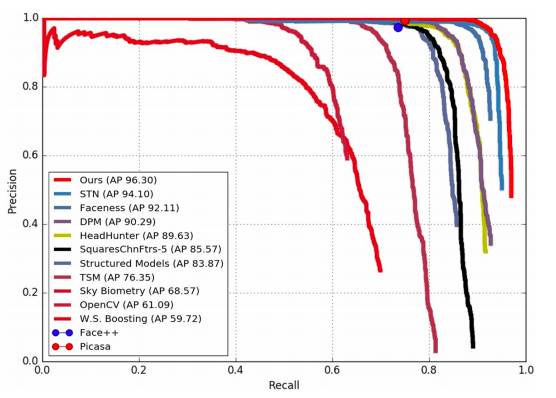
图 5:在 PASCAL 人脸数据集上的精度召回率曲线
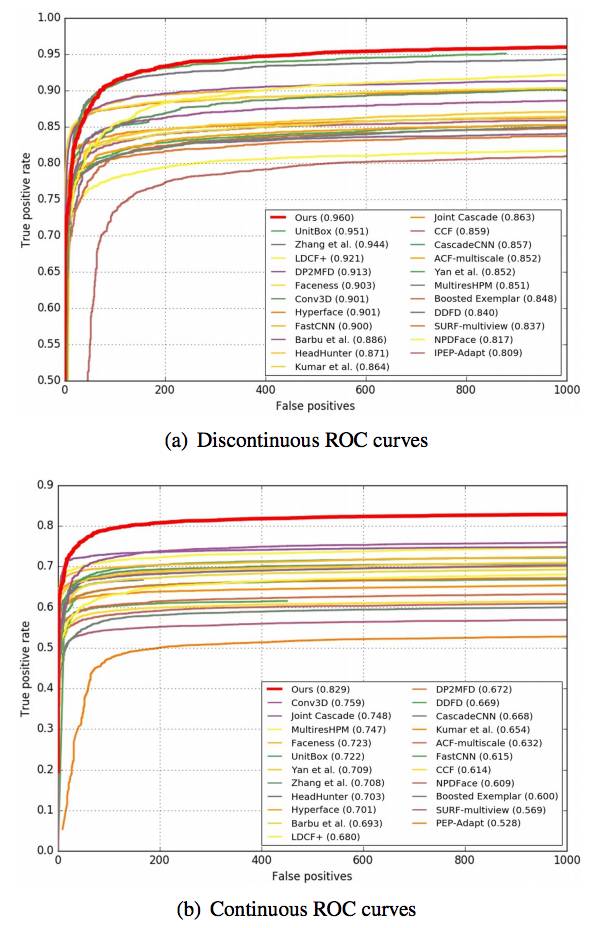
图 6:在 FDDB 数据集上的评估结果

