腾讯AI Lab的CVPR 2018文章解读
今天和大家分享马上要召开的CVPR 2018会议,这算殿堂级的会议,今天主要主角是我和腾讯,😄说起腾讯,其实和他还有许多缘分,但是现在还挺不是个滋味,永远记得17年10月份经历的一切,腾讯虽然在互联网领域首屈一指,可是有些工作技术员也太膨胀,想在面试过程中刷自己的存在感吗?知道你们技术很厉害,但是没必要“膨胀到天”吧😒~还是原归正转,说说腾讯AI Lab被CVPR 2018收录的paper,值得学习。如果可以和他们一起共事,那应许是件很有意思的事情,不知道会擦出多少无限的火花。
首先,近10年来在国际计算机视觉领域最具影响力、研究内容最全面的顶级学术会议CVPR,近日揭晓2018年收录论文名单,腾讯AI Lab共有21篇论文入选,位居国内企业前列,我们将在下文进行详解,欢迎交流与讨论。
去年CVPR的论文录取率为29%,腾讯AI Lab 共有6篇论文入选,点击 这里 可以回顾。2017年,腾讯 AI Lab共有100多篇论文发表在AI顶级会议上,包括ICML(4篇)、ACL(3篇)、NIPS(8篇)等。
我们还坚持与学界、企业界和行业「共享AI+未来」,已与美国麻省理工大学、英国牛津大学、香港科技大学、香港中文大学等多所海内外知名院校开展学术合作,并通过年度学术论坛、联合研究、访问学者、博士生及研究生奖学金等多种形式,推动前沿研究探索、应用与人才培养。
计 算 机 视 觉 未 来 方 向 与 挑 战
计算机视觉(Computer Vision)的未来,就是多媒体AI崛起,机器之眼被慢慢打开的未来。多媒体有的时候又被称为富媒体,是对图像、语音、动画和交互信息的统称。多媒体AI就是对这些所有内容的智能处理。一份国际报告显示,到2021年,视频将占全球个人互联网流量的比例,将从15年的70%增长到82%,成为信息的主要载体。目前我们计算机视觉中心的工作重点,从以往单纯的图像转向视频AI,研究视频的编辑、理解、分析和生成等。
第一个方向是研究如何让AI理解视频中更深层、更细节的信息,分析视频里人物与人物间、人物与物体间,到物体与场景间的具体关系,这是业界热门且亟待突破的研究方向。
第二个方向,不仅要研究视觉信号,还着眼于多模态信息,如计算机视觉加文本、加语音等信号的结合。比如视觉+文本上,我们的图像与视频描述生成技术已有一定 进展。
第三个方向是多媒体AI在垂直领域的应用。如在机器人领域,用视觉信息让AI感知周围世界,构建整个空间信息,进行导航和避障等操作。在医疗领域,分析医疗影像数据,结合病历文本信息等,让AI深入参与到辅助诊疗中。
这个领域的未来挑战,更多是对具体应用场景,比如安防、无人驾驶等难度大的具体应用场景,进行更细致规划和技术延伸。
今天先来说说《CosFace: Large Margin Cosine Loss for Deep Face Recognition》
CosFace: 面向深度人脸识别的增强边缘余弦损失函数设计
由腾讯AI Lab独立完成。由于深度卷积神经网络(CNN)的研究进展,人脸识别已经取得了革命性的进展。人脸识别的核心任务包括人脸验证和人脸辨识。然而,在传统意义上的深度卷积神经网络的Softmax代价函数的监督下,所学习的模型通常缺乏足够的判别性。为了解决这一问题,近期一系列损失函数被提出来,如Center Loss,L-Softmax,A-Softmax。所有这些改进算法都基于一个核心思想:增强类间差异并且减小类内差异。
该文章主要对人脸识别的损失函数作了改进优化!
先来看下主要框架:
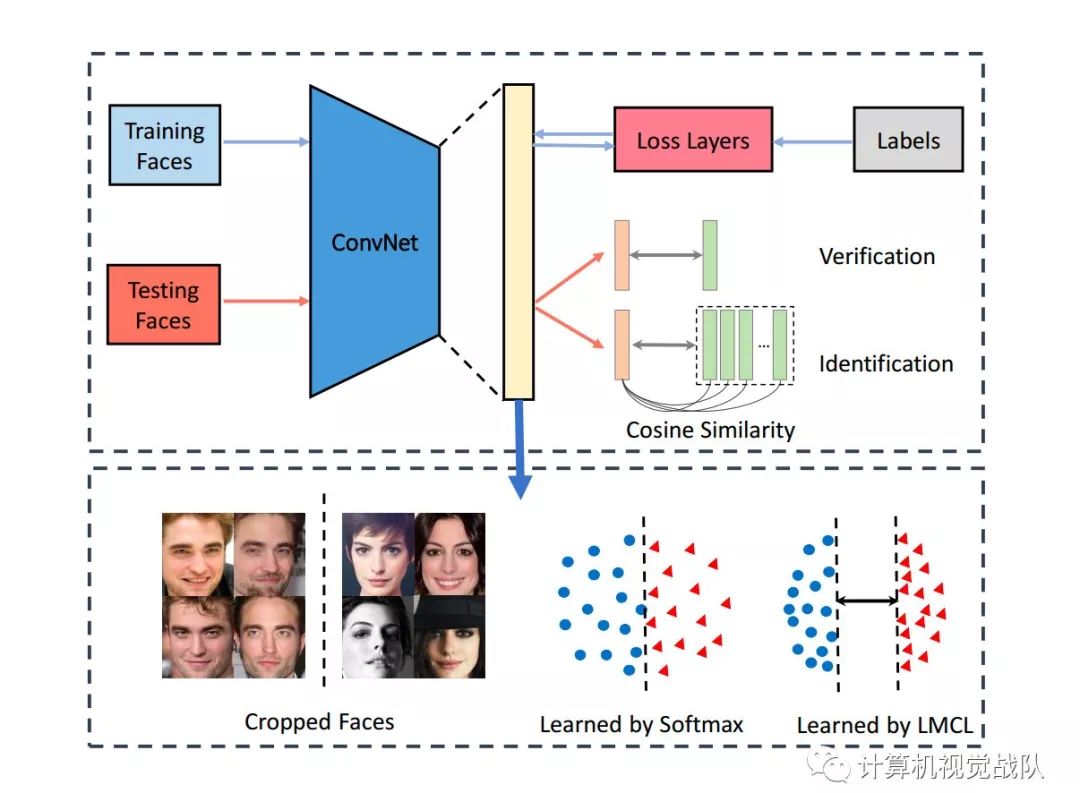
在训练阶段,在不同的类别之间,学习到了差别较大的人脸特征。在测试阶段,将测试数据输入到CosFace中,提取人脸特征,然后计算余弦相似度,进行人脸验证和识别。
那我们首先来温习下余弦距离:
余弦距离,也称为余弦相似度,是用向量空间中两个向量夹角的余弦值作为衡量两个个体间差异的大小的度量。
向量,是多维空间中有方向的线段,如果两个向量的方向一致,即夹角接近零,那么这两个向量就相近。而要确定两个向量方向是否一致,这就要用到余弦定理计算向量的夹角。
余弦定理描述了三角形中任何一个夹角和三个边的关系。给定三角形的三条边,可以使用余弦定理求出三角形各个角的角度。
现在来总结下文章的主要贡献:
采用类间方差最大化和类内方差最小化的思想,提出了一种新的类内方差损失函数LMCL,用于人脸识别
基于LMCL激励的超球面特征分布,给出了合理的理论分析
提出的方法提高了最先进的性能,并超过了大多数流行的脸数据库基准,包括LFW,YTF和MegaFace。
余弦距离和欧氏距离的对比
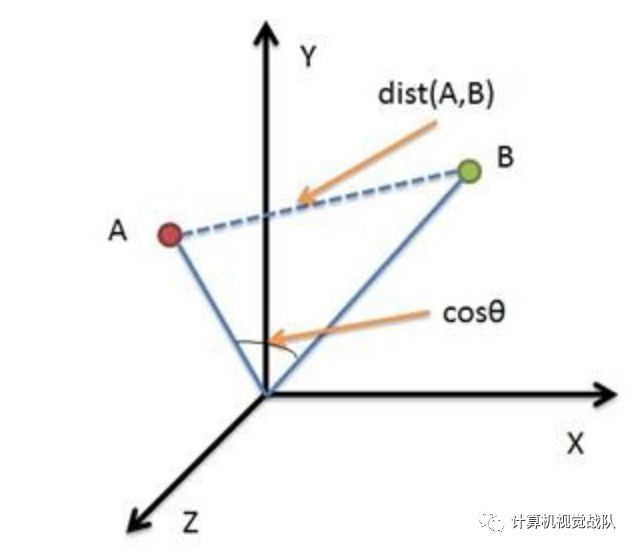
从上图可以看出,余弦距离使用两个向量夹角的余弦值作为衡量两个个体间差异的大小。相比欧氏距离,余弦距离更加注重两个向量在方向上的差异。
从上图可以看出,欧氏距离衡量的是空间各点的绝对距离,跟各个点所在的位置坐标直接相关;而余弦距离衡量的是空间向量的夹角,更加体现在方向上的差异,而不是位置。如果保持A点位置不变,B点朝原方向远离坐标轴原点,那么这个时候余弦距离cosθ是保持不变的(因为夹角没有发生变化),而A、B两点的距离显然在发生改变,这就是欧氏距离和余弦距离之间的不同之处。
欧氏距离和余弦距离各自有不同的计算方式和衡量特征,因此它们适用于不同的数据分析模型。欧氏距离能够体现个体数值特征的绝对差异,所以更多的用于需要从维度的数值大小中体现差异的分析,如使用用户行为指标分析用户价值的相似度或差异。
余弦距离更多的是从方向上区分差异,而对绝对的数值不敏感,更多的用于使用用户对内容评分来区分兴趣的相似度和差异,同时修正了用户间可能存在的度量标准不统一的问题(因为余弦距离对绝对数值不敏感)。
Large Margin Cosine Loss
首先从余弦的角度重新考Softmax损失。Softmax损失通过最大限度地提高Ground-truth类的后验概率,将特征从不同的类中分离出来。给定输入特征向量xi及其相应的标签yi,Softmax损失可以表述为:
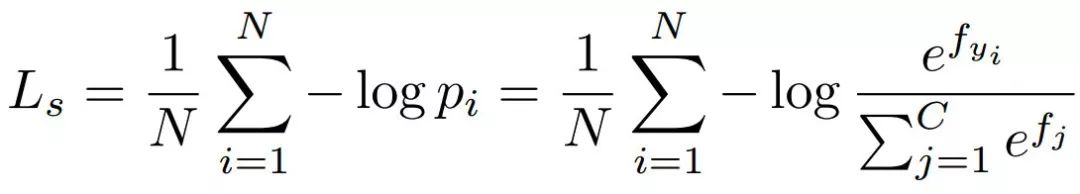
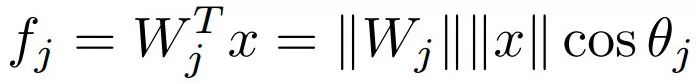
这个公式表明向量的范数和角度对后验概率都有贡献。
为了挖掘有效的特征学习,W应该是不变的。于是设置其||W||=1,在测试阶段,通常根据两个特征向量之间的余弦相似性来计算测试脸部对的脸部识别分数。这表明特征向量的范数X对评分功能没有贡献。因此,在训练阶段,设置||x||=s。因此,后验概率仅依赖于角度的余弦,修改后的损失可以表述为:
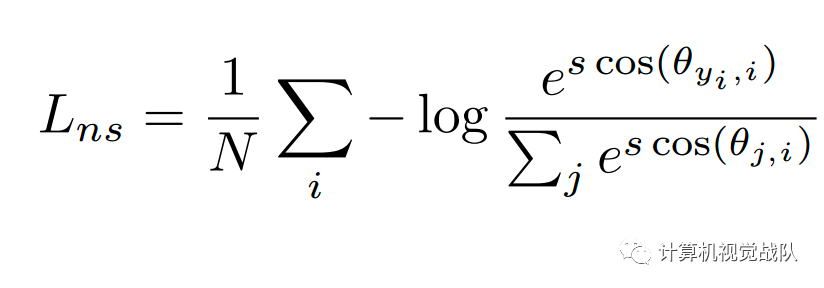
因为通过固定||x||=s来消除径向变化,所以得到的模型,学习了角空间中可分离的特征。将此损失称为Softmax损失的规范化版本(NSL)。
然而,NSL学习的特征并不是具有足够的判别性,因为NSL只强调正确的分类。为了解决这一问题,在分类边界中引入余弦边界,这自然地被纳入了Softmax的余弦公式中。
最后,最大边界余弦损失(Large Margin Cosine Loss, LMCL)定义如下:
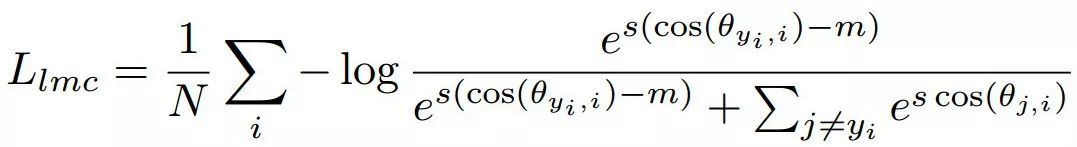
subject to
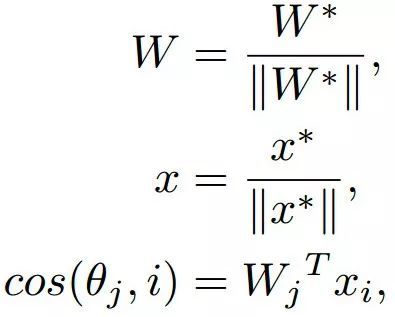
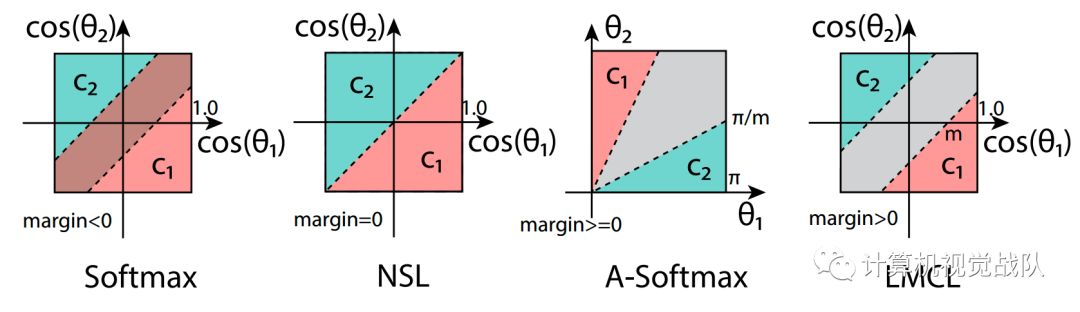
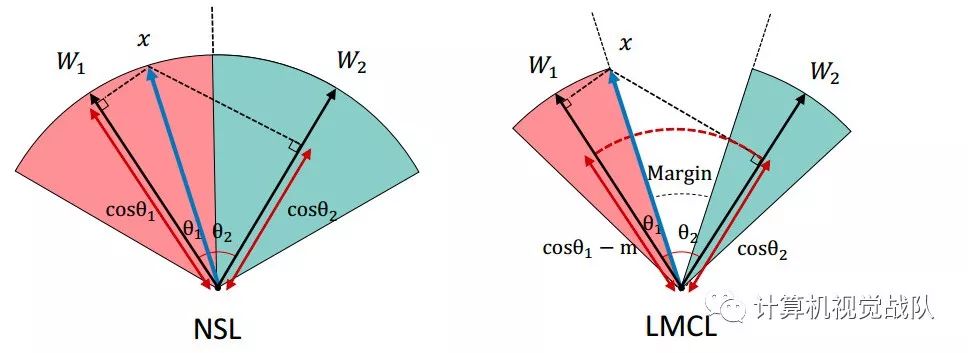
不同损失函数的比较
Softmax:
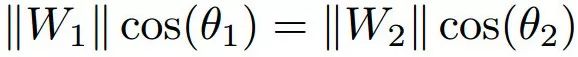
因此,它的边界依赖于权向量的大小和角度的余弦,从而在余弦空间中形成一个重叠的判定区域(margin<0)。这是如上图的第一个子图所示。如前所述,在测试阶段,只考虑人脸测试特征向量之间的余弦相似性是一种常见的策略。因此,具有软最大损失的训练分类器无法在余弦空间中对测试样本进行完全分类。
NSL:
对加权向量W1和W2进行标准化,以便它们的大小为1,这导致了由以下各方提供的决策边界:
Cos(θ1)=cos(θ2)
上图的第二个子图说明了NSL的决策边界。我们可以看到,通过去除径向变化,NSL能够在余弦空间中对测试样本进行完美的分类,margin=0。然而,它是由于没有决策margin,所以对噪声的鲁棒性不太强:任何围绕决策边界的小扰动都会改变决策。
A-Softmax:
A-Softmax通过引入额外的margin来改进Softmax损失,因此它的决策边界由:
C1:CoS(mθ1)≥cos(θ2)
C2:Cos(mθ2)≥cos(θ1)
因此,对于C1,它需要θ1≤(θ2/m),对于C2也是如此。上图的第三个子图描述了这个决策区域,其中灰色区域表示决策margin。然而,A-Softmax的margin与所有θ值并不一致:随着θ的减少,边缘变小,并且完全消失。当θ=0时。这就产生了两个潜在的问题。
首先,对于视觉上相似的困难类C1和C2,在W1和W2之间有一个较小的角度,因此边缘较小。
第二,从技术上讲,要克服余弦函数的非单调性困难,必须使用一个特殊的分段函数。
LMCL:
LMCL定义余弦空间中的决策余量,而不是角度空间(如A-SoFTMax):
C1:COS(Th 1)±COS(Th 2)+m
C2:COS(Th 2)±COS(Th 1)+m
LMCL理论分析
前面主要从分类的角度讨论LMCL。在学习超球面上的判别特征方面,余弦边缘作为增强特征识别能力的重要组成部分。需要对余弦范围的定量可行选择(即超参数m的边界)进行详细的分析。m的最优选择可能导致对高分辨人脸特征更好的学习。在下面,我们将深入研究特征中的决策边界和角度边缘。推导超参数m的理论界的空间。
可以观察到,最大角边受W1和W2之间夹角的影响。因此,当给出W1和W2时,余弦范围应具有有限的变量范围。
具体来说,假设一个场景,所有属于I类的特征向量都与I类的相应权重向量Wi完全重叠。换句话说,每个特征向量都与i类的权向量相同,显然特征空间处于一个极端的情况,所有的特征向量都位于它们的类中心。在这种情况下,保证全局决策边界的最大化(即余弦边界的严格上界)。
因此,在单位超球面上,Softmax损失的最优解应该均匀地分配权向量。基于这个假设,引入余弦边界m的变量范围如下所示:
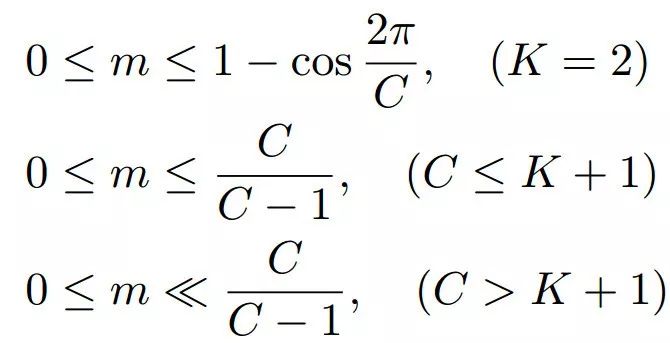
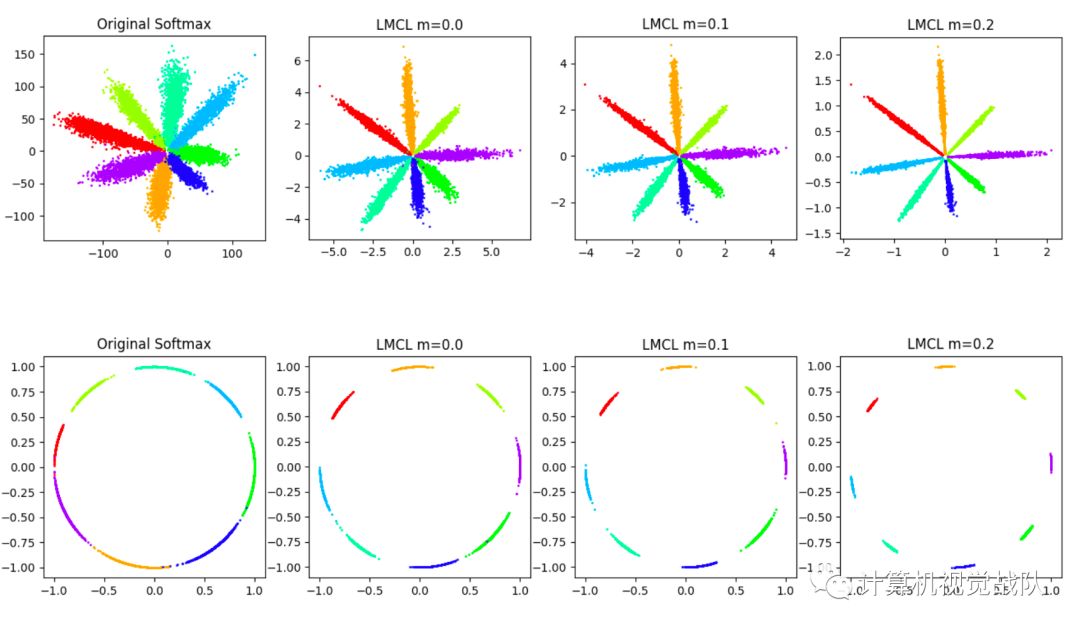
现在进行了一个toy experiment,以更好地可视化特征和验证提出的方法。从8个不同的标识中选择人脸图像,其中包含足够的样本,以清楚地显示出图上的特征点。使用原始的Softmax损失和不同m值设置的LMCL训练了几个模型。
为了简单起见,我们提取人脸图像的二维特征。如上所述,m不应大于1−cos(π/4)(约为0.29),因此建立了m=0,m=0.1和m=0.2的三种比较选择。
如下图所示,第一行和第二行分别在欧几里得空间和角空间中显示特征分布。我们可以看到,原始的Softmax损失在决策边界上产生了模糊,而提出的LMCL的性能要好的多。随着m的增加,不同类别之间的角度边界被放大。
Exploratory Experiments
在实验中可以看出,m的变化对结果有不一样的影响。我们可以看到,没有边界的模型(在本例中为m=0)导致最差的性能。随着m的增加,这两个数据集的精度都得到了一致的提高,并且在m=0.35时达到饱和。这表明了边界值m的有效性。通过增加边界m,可以显着地提高学习特征的鉴别能力。
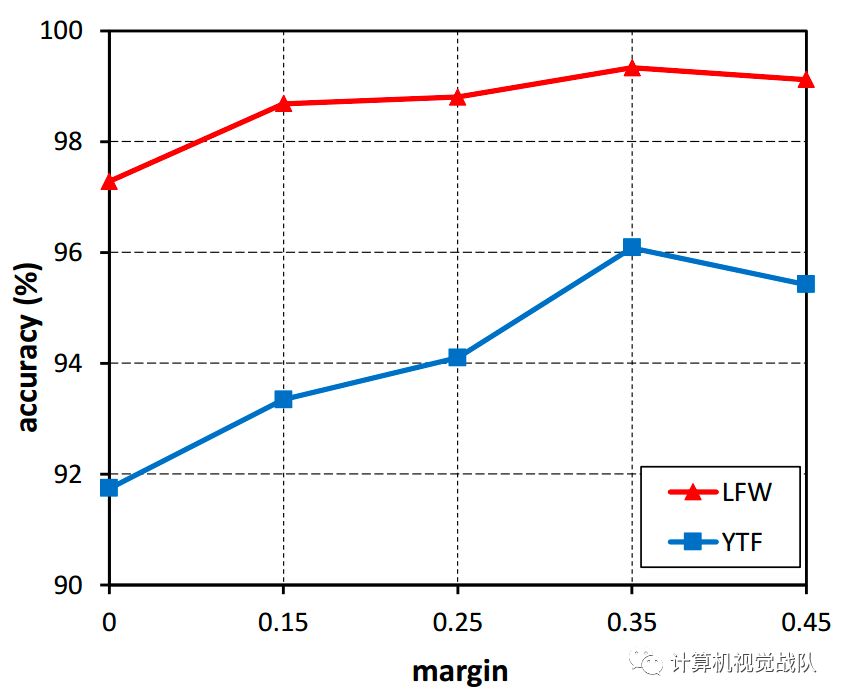
其中,归一化也对结果有影响,如下表:

很明显,使用特征归一化方案的模型在这三个数据集上一致优于没有特征归一化方案的模型。如上所述,特征归一化消除了根本的方差,并且学习到的特征在角度空间中可以更有判断力,这个实验证实了这一点。
与不同损失函数比较试验:
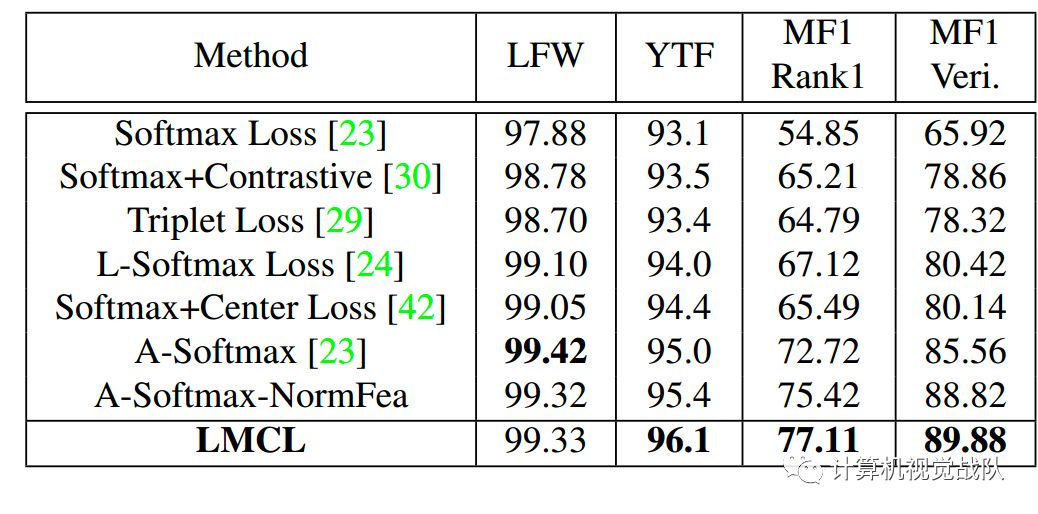
[23] W. Liu, Y. Wen, Z. Yu, M. Li, B. Raj,and L. Song. SphereFace: Deep Hypersphere Embedding for Face Recognition. InConference on Computer Vision and Pattern Recognition (CVPR), 2017. 2, 3, 4, 6,7, 8
[24] W. Liu, Y. Wen, Z. Yu, and M. Yang.Large-Margin Softmax Loss for Convolutional Neural Networks. In International Conferenceon Machine Learning (ICML), 2016. 2, 8
[29] F. Schroff, D. Kalenichenko, and J.Philbin. Facenet: A unified embedding for face recognition and clustering. In Conferenceon Computer Vision and Pattern Recognition (CVPR), 2015. 2, 8
[30] Y. Sun, Y. Chen, X. Wang, and X. Tang.Deep learning face representation by joint identification-verification. InAdvances in Neural Information Processing Systems (NIPS), 2014. 2, 8
[42] Y. Wen, K. Zhang, Z. Li, and Y. Qiao.A discriminative feature learning approach for deep face recognition. InEuropean Conference on Computer Vision (ECCV), pages 499–515, 2016. 2, 6, 8
与不同方法实验比较:
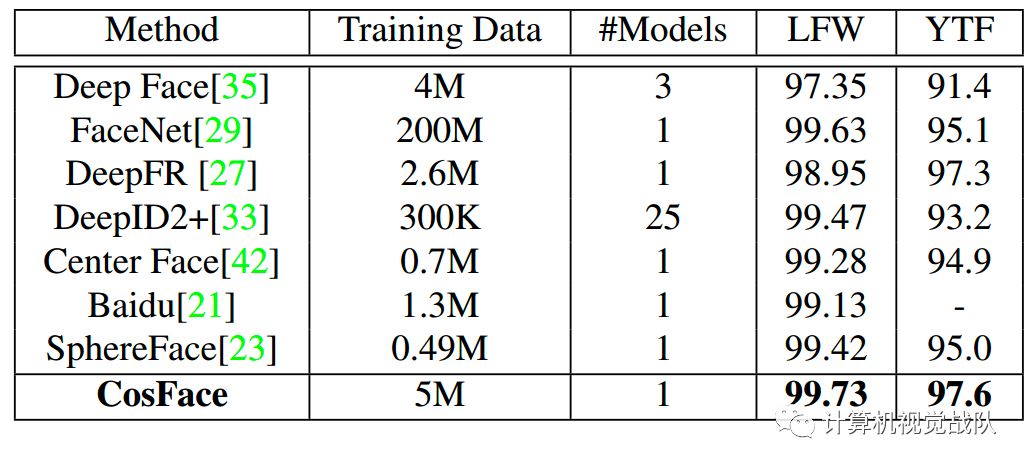
[21] J. Liu, Y. Deng, T. Bai, Z. Wei, andC. Huang. Targeting ultimate accuracy: Face recognition via deep embedding.arXiv preprint arXiv:1506.07310, 2015. 8
[27] O. M. Parkhi, A. Vedaldi, A.Zisserman, et al. Deep face recognition. In BMVC, volume 1, page 6, 2015. 8
[33] Y. Sun, X. Wang, and X. Tang. Deeplylearned face representations are sparse, selective, and robust. In Conferenceon Computer Vision and Pattern Recognition (CVPR), 2015. 2,
8
[35] Y. Taigman, M. Yang, M. Ranzato, andL. Wolf. Deepface: Closing the gap to human-level performance in faceverification. In Conference on Computer Vision and Pattern Recognition (CVPR),2014. 2, 8
总结
本次推送中,我们总结了一种创新的方法——LMCL来指导深层CNN学习高分辨率人脸特征,并且总结陈列了一个良好的几何和理论解释,以验证所提出的LMCL方法的有效性。提出的方法始终在几个人脸的基准上达到最先进的结果。希望通过LMCL学习鉴别特征的大量探索,对人脸识别界有一定的帮助。
注:剩余的CVPR文章我们后期慢慢与大家分析,谢谢大家的支持与关注!
如果想加入我们“计算机视觉战队”,请扫二维码加入学习群,我们一起学习进步,探索领域中更深奥更有趣的知识!



