北师大刘嘉:认知神经科学如何打开 AI 黑箱?

作者 | 青暮

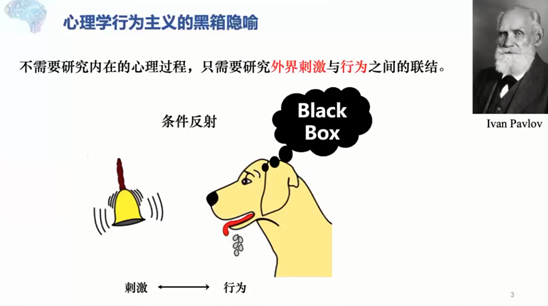
行为主义
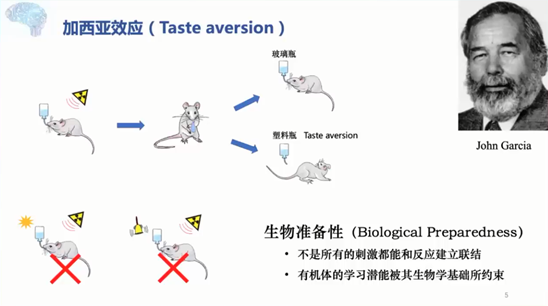
Garcia效应
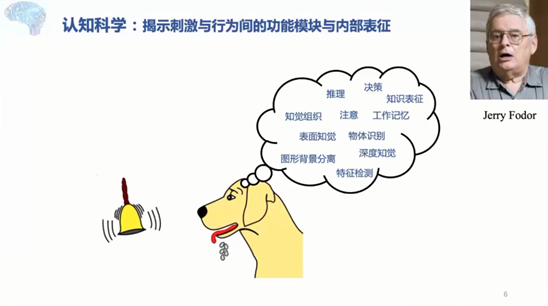

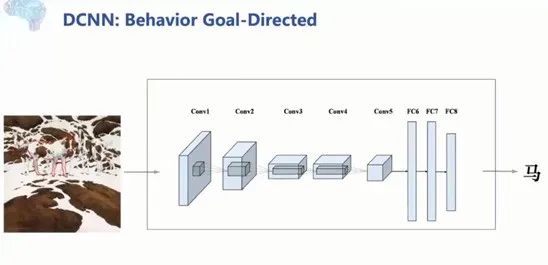
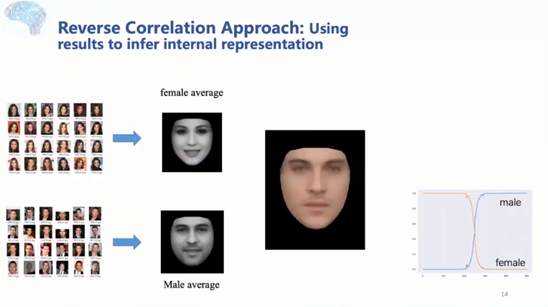
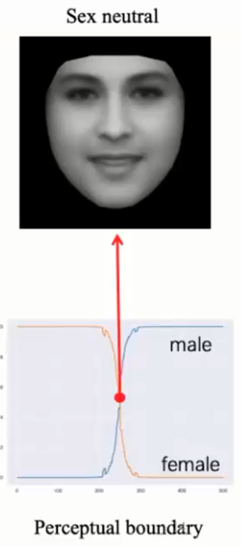
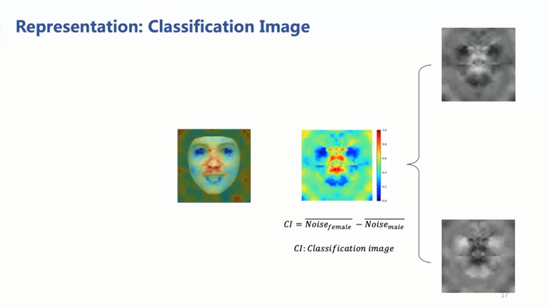
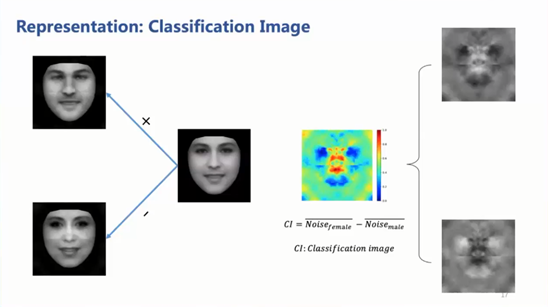
打开深度神经网络的黑箱





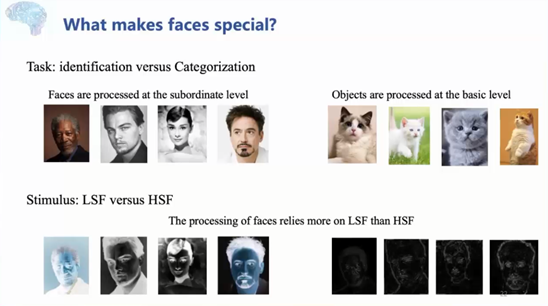
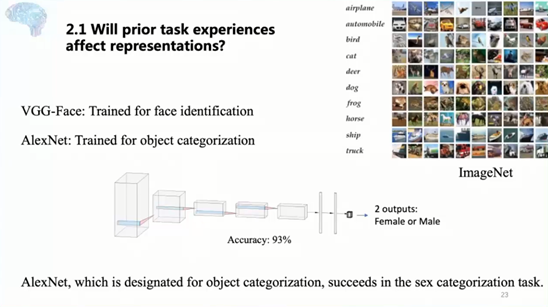
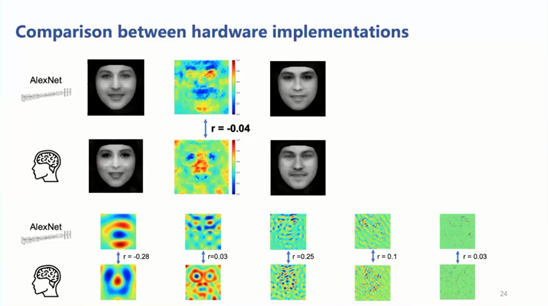
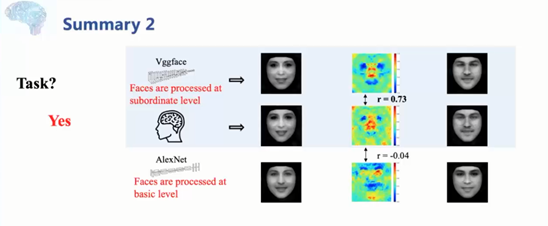

ACL 2020原定于2020年7月5日至10日在美国华盛顿西雅图举行,因新冠肺炎疫情改为线上会议。为促进学术交流,方便国内师生提早了解自然语言处理(NLP)前沿研究,AI 科技评论将推出「ACL 实验室系列论文解读」内容,同时欢迎更多实验室参与分享,敬请期待!
![]()
点击"阅读原文",直达“ACL 交流小组”了解更多会议信息。

登录查看更多
相关内容





相关VIP内容
相关资讯
相关论文