让人工智能有情感的秘诀!清华权威报告看透情感计算【附下载】

来源: 智东西
40 多年前,诺贝尔奖得主 Herbert Simon 在认知心理学方面强调,解决问题论要结合情感的影响。情感的识别和表达对于信息的交流和理解是必需的,也是人类最大的心理需求之一。人类的认知、行为等几乎都要受到情感的驱动,并影响着人际互动以及群体活动。在人与人的交往中, 情感的交流还常被用来完成人的意图的传递。 因此,在智能人机交互的研究中,拥有对情感的识别、分析、理解、表达的能力也应成为智能机器必不可少的一种功能。

什么是情感计算
让计算机具有情感能力的观点并不新鲜,它与“机器人” 一词几乎同时出现。1985 年,人工智能的奠基人之一 Minsky 就明确指出: “问题不在于智能机器能否有情感,而在于没有情感的机器能否实现智能” 。但当时,赋予计算机或机器人以人类式的情感,主要还是科幻小说中的素材,在学术界罕有人关注。1995 年情感计算的概念由 Picard 首次提出,并于 1997 年正式出版《Affective Computing(情感计算)》。在书中,她指出“情感计算就是针对人类的外在表现,能够进行测量和分析并能对情感施加影响的计算” ,开辟了计算机科学的新领域,其思想是使计算机拥有情感,能够像人一样识别和表达情感,从而使人机交互更自然。
简单来说,情感计算研究就是试图创建一种能感知、识别和理解人的情感,并能针对人的情感做出智能、灵敏、友好反应的计算系统。显然,情感计算是个复杂的过程,不仅受时间、地点、环境、人物对象和经历的影响,而且要考虑表情、语言、动作或身体的接触。
在人机交互中,计算机需要捕捉关键信息,觉察人的情感变化,形成预期,进行调整, 做出反应。例如通过对不同类型的用户建模(如操作方式、表情特点、态度喜好、认知风格、知识背景等),以识别用户的情感状态,利用有效的线索选择合适的用户模型,并以适合当前用户的方式呈现信息。 在对当前的操作做出及时反馈的同时,还要对情感变化背后的意图形成新的预期,并激活相应的数据库,及时主动地提供用户需要的新信息。 举例来说,麻省理工学院媒体实验室的情感计算小组研制的情感计算系统通过记录人面部表情的摄像机和连接在人身体上的生物传感器来收集数据,然后由一个“情感助理”来调节程序以识别人的情感。假设你对电视讲座的一段内容表现出困惑,情感助理会重放该片段或者给予解释。而目前国内情感计算的研究重点在于通过各种传感器获取有人的情感所引起的生理及行为特征信号,确定情感类别的关键特征,建立“情感模型”,从而创建个人情感计算系统。
情感计算是一个高度综合化的研究和技术领域。通过计算科学与心理科学、认知科学的结合,研究人与人交互、人与计算机交互过程中的情感特点,设计具有情感反馈的人与计算机的交互环境,将有可能实现人与计算机的情感交互。情感计算研究将不断加深对人的情感状态和机制的理解,并提高人与计算机界面的和谐性,即提高计算机感知情境,理解人的情感意图,做出适当反应的能力,其主要研究内容如下图所示:
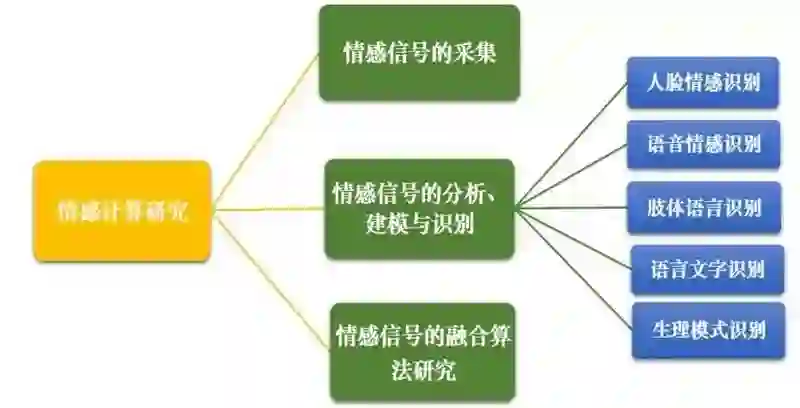
情感计算是一个多学科交叉的崭新的研究领域,它涵盖了传感器技术、计算机科学、认知科学、心理学、行为学、生理学、哲学、社会学等方面。情感计算的最终目标是赋予计算机类似于人的情感能力。要达到这个目标,许多技术问题有待解决。这些技术问题的突破对各学科的发展都产生巨大的推动作用。以下分别从情感计算的传统研究方法和新兴研究方法对技术发展进行探讨。
1、 传统的研究
传统的情感计算方法是按照不同的情感表现形式分类的,分别是:文本情感分析、语音情感分析、视觉情感分析。
1.1 文本情感计算
20世纪90年代末,国外的文本情感分析已经开始。早期, Riloff和Shepherd在文本数据的基础上进行了构建语义词典的相关研究。 McKeown发现连词对大规模的文本数据集中形容词的语义表达的制约作用,进而对英文的形容词与连词做情感倾向研究。自此之后,越来越多的研究开始考虑特征词与情感词的关联关系。 Turney等使用点互信息的方法扩展了正负面情感词典,在分析文本情感时使用了极性语义算法,处理通用的语料数据时准确率达到了74%。在近些年的研究中, Narayanan等结合各种特征及其相关联信息,提出了基于分句、整句、结果句的分类方案,获得了很好的效果。 Pang等以积极情感和消极情感为维度,对电影评论进行了情感分类。他分别采用了支持向量机、最大熵、朴素贝叶斯算法进行分类实验,发现支持向量机的精确度达到了80%。随着研究的不断深入,学者在对情感分析算法进行改进的同时,也将其应用到不同的行业中进行了实践。
文本情感计算的过程可以由 3 部分组成:文本信息采集、情感特征提取和情感信息分类。文本信息采集模块通过文本抓取工具(如网页爬虫工具)获得情感评论文本,并传递到下一个情感特征提取模块,然后对文本中自然语言文本转化成计算机能够识别和处理的形式,并通过情感信息分类模块得到计算结果。文本情感计算侧重研究情感状态与文本信息之间的对应关系,提供人类情感状态的线索。具体地,需要找到计算机能提取出来的特征,并采用能用于情感分类的模型。因此,关于文本情感计算过程的讨论,主要集中在文本情感特征标注(信息采集) 、情感特征提取和情感信息分类这三个方面 。
1、文本情感特征标注:情感特征标注是对情感语义特征进行标注,通常是将词或者语义块作为特征项。情感特征标注首先对情感语义特征的属性进行设计,如褒义词、贬义词、加强语气、一般语气、悲伤、高兴等等;然后通过机器自动标注或者人工标注的方法对情感语义特征进行标注, 形成情感特征集合。情感词典是典型的情感特征集合,也是情感计算的基础。在大多数研究中,有关情感计算的研究通常是将情感词典直接引入自定义词典中。
运用情感词典计算出文本情感值是一种简单迅速的方法,但准确率有待提高。在实际的情感计算中,会因为具体的语言应用环境而有所不同。例如, “轻薄” 一词通常认为是否定词,但是在电脑、手机却被视为肯定词汇。同时,文本中常会出现否定前置、双重否定以及文本口语化和表情使用等,这些都将会对文本情感特征的提取和判断产生较大的影响。因此在进行文本情感提取时,需要对文本及其对应的上下文关系、 环境关系等进行分析。
2、情感特征提取 :文本包含的情感信息是错综复杂的,在赋予计算机以识别文本情感能力的研究中,从文本信号中抽取特征模式至关重要。在对文本预处理后,初始提取情感语义特征项。特征提取的基本思想是根据得到的文本数据, 决定哪些特征能够给出最好的情感辨识。通常算法是对已有的情绪特征词打分,接着以得分高低为序,超过一定阈值的特征组成特征子集。特征词集的质量直接影响最后结果,为了提高计算的准确性,文本的特征提取算法研究将继续受到关注。长远看来,自动生成文本特征技术将进一步提高,特征提取的研究重点也更多地从对词频的特征分析转移到文本结构和情感词上。
3、情感信息分类 :文本情感分类技术中,主要采用两种技术路线:基于规则的方法和基于统计的方法。在 20世纪 80 年代,基于规则的方法占据主流位置,通过语言学家的语言经验和知识获取句法规则,以此作为文本分类依据。但是,获取规则的过程复杂且成本巨大,也对系统的性能有负面影响,且很难找到有效的途径来提高开发规则的效率。 20 世纪 90 年代之后,人们更倾向于使用统计的方法,通过训练样本进行特征选择和参数训练,根据选择的特征对待分类的输入样本进行形式化,然后输入到分类器进行类别判定,最终得到输入样本的类别。
1.2 语音情感计算
最早的真正意义上的语音情感识别相关研究出现在 20 世纪 80 年代中期,它们开创了使用声学统计特征进行情感分类的先河。紧接着,随着 1985 年 Minsky 教授“让计算机具有情感能力” 观点的提出,以及人工智能领域的研究者们对情感智能重要性认识的日益加深,越来越多的科研机构开始了语音情感识别研究的探索。在 20 世纪 80 年代末至 90 年代初期,麻省理工学院多媒体实验室构造了一个“情感编辑器” 对外界各种情感信号进行采集,综合使用人体的生理信号、面部表情信号、语音信号来初步识别各种情感,并让机器对各种情感做出适当的简单反应; 1999 年, Moriyama 提出语音和情感之间的线性关联模型,并据此在电子商务系统中建造出能够识别用户情感的图像采集系统语音界面,实现了语音情感在电子商务中的初步应用。
整体而言,语音情感识别研究在该时期仍旧处于初级阶段, 主要侧重于情感的声学特征分析这一方面,作为研究对象的情感语音样本也多表现为规模小、自然度低、语义简单等特点,虽然有相当数量的有价值的研究成果相继发表,但是并没有形成一套被广泛认可的、系统的理论和研究方法。进入 21 世纪以来,随着计算机多媒体信息处理技术等研究领域的出现以及人工智能领域的快速发展,语音情感识别研究被赋予了更多的迫切要求,发展步伐逐步加快。 2000 年,在爱尔兰召开的 ISCA Workshop on Speech and Emotion 国际会议首次把致力于情感和语音研究的学者聚集在一起。近 10 余年来,语音情感识别研究工作在情感描述模型的引入、情感语音库的构建、情感特征分析等领域的各个方面都得到了发展。 下面将从语音情感数据库的采集、语音情感标注以及情感声学特征分析方面介绍语音情感计算。
1、语音情感数据库的采集 :语音情感识别研究的开展离不开情感语音数据库的支撑。情感语音库的质量高低,直接决定了由它训练得到的情感识别系统的性能好坏。评价一个语音情感数据库好坏的一个重要标准是数据库中语音情感是否具备真实的表露性和自发性。目前,依据语音情感激发类型的不同,语音情感数据库可分为表演型、诱发型和自发型三种。
具体来说,表演型情感数据库通过专业演员的表演,把不同情感表达出来。在语音情感识别研究初期,这一采集标准被认为是研究语音情感识别比较可靠的数据来源,因为专业演员在表达情感时,可以通过专业表达获得人所共知的情感特征。比如,愤怒情感的语音一般会具有很大的幅值和强度,而悲伤情感的语音则反之。由于这一类型的数据库具有表演的性质,情感的表达会比真实情感夸大一点,因此情感不具有自发的特点。依据该类型数据库来学习的语音情感识别算法,不一定能有效应用于真实生活场景中。第二种称之为诱发型情感数据库。被试者处于某一特定的环境,如实验室中,通过观看电影或进行计算机游戏等方式,诱发被试者的某种情感。目前大部分的情感数据库都是基于诱发的方式建立的。诱发型情感数据库产生的情感方式相较于表演型情感数据库,其情感特征更具有真实性。最后一种类型属于完全自发的语音情感数据库,其语料采集于电话会议、电影或者电话的视频片段,或者广播中的新闻片段等等。由于这种类型的语音情感数据最具有完全的真实性和自发性,应该说最适合用于实用的语音情感识别。但是,由于这些语音数据涉及道德和版权因素,妨碍了它在实际语音情感识别中的应用。
2、语音情感数据库的标注 :对于采集好的语音情感库,为了进行语音情感识别算法研究,还需要对情感语料进行标注。标注方法有两种类型:
离散型情感标注法指的是标注为如生气、高兴、悲伤、害怕、惊奇、讨厌和中性等,这种标注的依据是心理学的基本情感理论。基本情感论认为,人复杂的情感是由若干种有限的基本情感构成的,就像我们自古就有“喜、怒、哀、乐,恐、悲、 惊” 七情的说法。 不同的心理学家对基本情感有不同的定义,由此可见,在心理学领域对基本情感类别的定义还没有一个统一的结论,因此不同的语音情感数据库包含的情感类别也不尽相同。这不利于在不同的语音情感数据库上,对同一语音情感识别算法的性能进行评价。此外,众所周知,实际生活中情感的类别远远不止有限几类。基于离散型情感标注法的语音情感识别容易满足多数场合的需要,但无法处理人类情感表达具有连续性和动态变化性的情况。在实际生活中,普遍存在着情感变化的语音,比如前半句包含了某一种情感,而后半句却包含了另外一种情感,甚至可能相反。 例如,某人说话时刚开始很高兴,突然受到外界刺激,一下子就生气了。对于这种在情感表达上具有连续和动态变化的语音,采用离散型情感标注法来进行语音情感识别就不合适了。因为此时语音的情感,己不再完全属于某一种具体的情感。
维度情感空间论基于离散型情感标注法的缺陷,心理学家们又提出了维度情感空间论,即对情感的变化用连续的数值进行表示。不同研究者所定义的情感维度空间数目有所不同,如二维、三维甚至四维模型。针对语音情感,最广为接受和得到较多应用的为二维连续情感空间模型,即“激活维-效价维” (Arousal-Valence) 的维度模型。 “激活维” 反映的是说话者生理上的激励程度或者采取某种行动所作的准备,是主动的还是被动的; “效价维” 反映的是说话者对某一事物正面的或负面的评价。随着多模态情感识别算法的研究,为了更细致的地描述情感的变化,研究者在“激活维-效价维” (Arousal-Valence) 二维连续情感空间模型的基础上,引入“控制维” , 即在“激活维-效价维-控制维(Arousal-Valence/Pleasure-Power/Dominance) ”三维连续情感空间模型上对语音情感进行标注和情感计算。需要强调的是,离散型和连续型情感标注之间,它们并不是孤立的,而是可以通过一定映射进行相互转换。
情感声学特征分析 :情感声学特征分析主要包括声学特征提取和声学特征选择、声学特征降维。采用何种有效的语音情感特征参数用于情感识别,是语音情感识别研究最关键的问题之一,因为所用的情感特征参数的优劣直接决定情感最终识别结果的好坏 。
声学特征提取。 目前经常提取的语音情感声学特征参数主要有三种:韵律特征、音质特征以及谱特征。 在早期的语音情感识别研究文献中,针对情感识别所首选的声学特征参数是韵律特征,如基音频率、振幅、发音持续时间、语速等。这些韵律特征能够体现说话人的部分情感信息,较大程度上能区分不同的情感。因此,韵律特征已成为当前语音情感识别中使用最广泛并且必不可少的一种声学特征参数除了韵律特征,另外一种常用的声学特征参数是与发音方式相关的音质特征参数。三维情感空间模型中的“激发维”上比较接近的情感类型,如生气和高兴,仅使用韵律特征来识别是不够的。
音质特征包括共振峰、频谱能量分布、 谐波噪声比等,不仅能够很好地表达三维中的“效价维”信息,而且也能够部分反映三维中的“控制维”信息。因此,为了更好地识别情感,同时提取韵律特征和音质特征两方面的参数用于情感识别,已成为语音情感识别领域声学特征提取的一个主要方向。谱特征参数是一种能够反映语音信号的短时功率谱特性的声学特征参数, Mel 频率倒谱系数(Mel-scale Frequency Cepstral Coefficients,MFCC)是最具代表性的谱特征参数,被广泛应用于语音情感识别。由于谱特征参数及其导数,仅反映语音信号的短时特性,忽略了对情感识别有用的语音信号的全局动态信息。近年来,为了克服谱特征参数的这种不足之处,研究者提出了一些改进的谱特征参数,如类层次的谱特征、调制的谱特征和基于共振峰位置的加权谱特征等。
声学特征选择。 为了尽量保留对情感识别有意义的信息,研究者通常都提取了较多的与情感表达相关的不同类型的特征参数,如韵律特征、音质特征、谱特征等。 任意类型特征都有各自的侧重点和适用范围, 不同的特征之间也具有一定的互补性、相关性。此外,这些大量提取的特征参数直接构成了一个高维空间的特征向量。这种高维性质的特征空间,不仅包含冗余的特征信息,导致用于情感识别的分类器训练和测试需要付出高昂的计算代价,而且情感识别的性能也不尽如人意。因此,非常有必要对声学特征参数进行特征选择或特征降维处理,以便获取最佳的特征子集,降低分类系统的复杂性和提高情感识别的性能。
特征选择是指从一组给定的特征集中,按照某一准则选择出一组具有良好区分特性的特征子集。特征选择方法主要有两种类型:封装式(Wrapper)和过滤式(Filter)。Wrapper 算法是将后续采用的分类算法的结果作为特征子集评价准则的一部分,根据算法生成规则的分类精度选择特征子集。 Filter 算法是将特征选择作为一个预处理过程,直接利用数据的内在特性对选取的特征子集进行评价,独立于分类算法。
声学特征降维。 特征降维是指通过映射或变换方式将高维特征空间映射到低维特征空间,已达到降维的目的。特征降维算法分为线性和非线性两种。最具代表性的两种线性降维算法,如主成分分析 PCA(Principal Component Analysis)和线性判别分析 LDA(Linear DiscriminantAnalysis),已经被广泛用于对语音情感特征参数的线性降维处理。也就是, PCA 和 LDA 方法被用来对提取的高维情感声学特征数据进行嵌入到一个低维特征子空间,然后在这降维后的低维子空间实现情感识别,提高情感识别性能。
近年来,新发展起来的基于人类认知机理的流形学习方法比传统的线性 PCA 和 LDA 方法更能体现事物的本质,更适合于处理呈非线性流形结构的语音情感特征数据。但这些原始的流形学习方法直接应用于语音情感识别中的特征降维,所取得的性能并不令人满意。主要原因是他们都属于非监督式学习方法,没有考虑对分类有帮助的已经样本数据的类别信息。尽管流形学习方法能够较好地处理非线性流形结构的语音特征数据,但是流形学习方法的性能容易受到其参数如邻域数的影响,而如何确定其最佳的邻域数,至今还缺乏理论指导,一般都是根据样本数据的多次试验结果来粗略地确定。因此,对于流形学习方法的使用,如何确定其最佳参数,还有待深入研究。
1.3 视觉情感计算
表情作为人类情感表达的主要方式,其中蕴含了大量有关内心情感变化的信息,通过面部表情可以推断内心微妙的情感状态。但是让计算机读懂人类面部表情并非简单的事情。 人脸表情识别是人类视觉最杰出的能力之一。 而计算机进行自动人脸表情识别所利用的主要也是视觉数据。 无论在识别准确性、 速度、 可靠性还是稳健性方面, 人类自身的人脸表情识别能力都远远高于基于计算机的自动人脸表情识别。 因此,自动人脸表情识别研究的进展一方面依赖计算机视觉、 模式识别、人工智能等学科的发展, 另一方面还依赖对人类本身识别系统的认识程度,特别是对人的视觉系统的认识程度。
早在 20 世纪 70 年代,关于人脸表情识别的研究就已经展开,但是早期主要集中在心理学和生物学方面。随着计算机技术的发展,人脸表情识别技术逐渐发展起来,至上世纪 90 年代,该领域的研究已经非常活跃。大量文献显示表情识别与情感分析已从原来的二维图像走向了三维数据研究,从静态图像识别研究专项实时视频跟踪。 下面将从视觉情感信号获取、情感信号识别以及情感理解与表达方面介绍视觉情感计算。
视觉情感信号获取 :表情参数的获取, 多以二维静态或序列图像为对象, 对微笑的表情变化难以判断, 导致情感表达的表现力难以提高, 同时无法体现人的个性化特征,这也是表情识别中的一大难点。 以目前的技术, 在不同的光照条件和不同头部姿态下, 也不能取得满意的参数提取效果。由于三维图像比二维图像包含更多的信息量, 可以提供鲁棒性更强, 与光照条件和人的头部姿态无关的信息, 用于人脸表情识别的特征提取工作更容易进行。因此, 目前最新的研究大多利用多元图像数据来进行细微表情参数的捕获。 该方法综合利用三维深度图像和二维彩色图像, 通过对特征区深度特征和纹理彩色特征的分析和融合, 提取细微表情特征, 并建立人脸的三维模型, 以及细微表情变化的描述机制。
视觉情感信号识别:视觉情感信号的识别和分析主要分为面部表情的识别和手势识别两类:
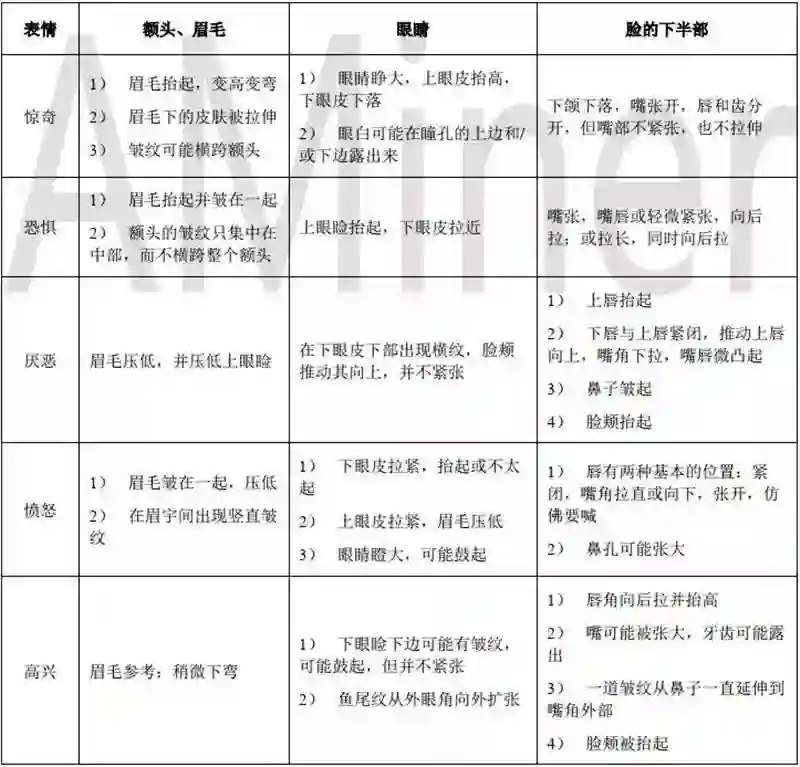
对于面部表情的识别, 要求计算机具有类似于第三方观察者一样的情感识别能力。由于面部表情是最容易控制的一种,所以识别出来的并不一定是真正的情感,但是,也正由于它是可视的,所以它非常重要,并能通过观察它来了解一个人试图表达的东西。到目前为止, 面部表情识别模型都是将情感视为离散的, 即将面部表情分成为数不多的类别, 例如“高兴” 、 “悲伤” 、 “愤怒” 等。 1971 年, Ekman 和 Friesen 研究了 6 种基本表情(高兴、悲伤、惊讶、恐惧、愤怒和厌恶), 并系统地建立了上千幅不同的人脸表情图像库。六种基本表情的具体面部表现如下表 所示。 1978 年, 他们研究了情感类别之间的内在关系, 开发了面部动作编码系统(FACS)。系统描述了基本情感以及对应的产生这种情感的肌肉移动的动作单元。他们根据人脸的解剖学特点,将其划分成大约 46 个既相互独立又相互联系的运动单元(AU) ,并分析了这些运动单元的运动特征及其所控制的主要区域以及与之相关的表情,给出了大量的照片说明。面部识别器一般要花五分钟来处理一种面部表情, 准确率达到 98%。
马里兰大学的 Yeser Yacoob 和 Larry Davis 提出了另一种面部表情识别模型,它也是基于动作能量模版,但是将模版、子模版(例如嘴部区域)和一些规则结合起来表达情感。例如,愤怒的表情在从眼睛区域提取的子模版中,特别是眉毛内敛、下垂,在嘴巴区域子模版中,特别是嘴巴紧闭, 两个子模板结合起来, 就很好表达了愤怒这一情感。后续的研究总体上结合生物识别方法及计算机视觉进行, 依据人脸特定的生物特征,将各种表情同脸部运动细节(几何网格的变化) 联系起来, 收集样本, 提取特征,构建分类器。 但是目前公开的用于表情识别研究的人脸图像数据库多是采集志愿者刻意表现出的各种表情的图像, 与真实情形有出入。
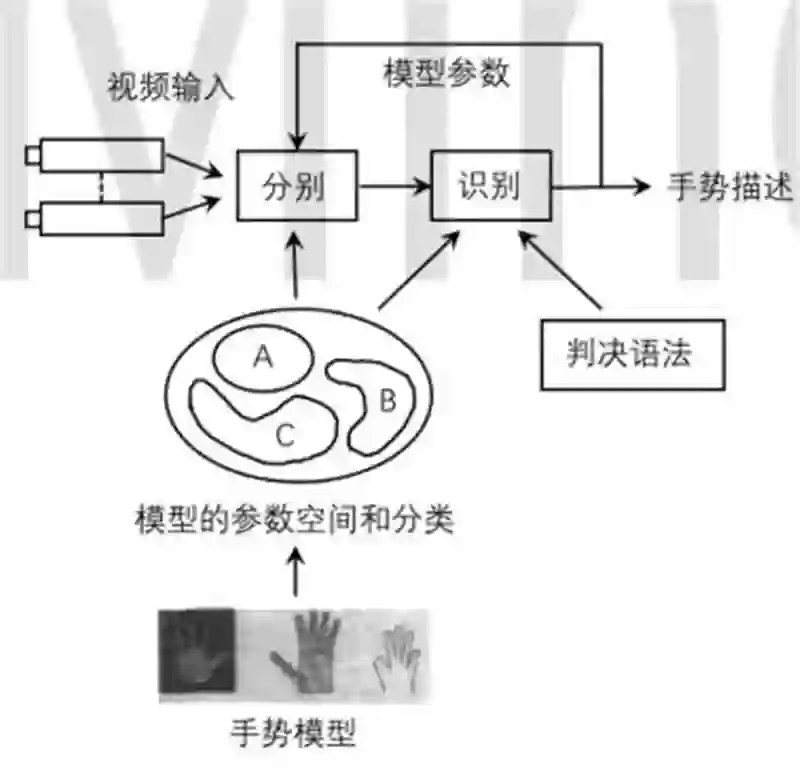
对于手势识别来说, 一个完整的手势识别系统包括三个部分和三个过程。 三个部分分别是:采集部分、 分类部分和识别部分; 三个过程分别是: 分割过程、 跟踪过程和识别过程。 采集部分包括了摄像头、 采集卡和内存部分。 在多目的手势识别中, 摄像头以一定的关系分布在用户前方。 在单目的情况下, 摄像头所在的平面应该和用户的手部运动所在的平面基本水平。分类部分包括了要处理的分类器和结果反馈回来的接收比较器。 用来对之前的识别结果进行校正。识别部分包括了语法对应单位和相应的跟踪机制, 通过分类得到的手部形状通过这里一一对应确定的语义和控制命令。 分割过程包括了对得到的实时视频图像进行逐帧的手部分割, 首先得到需要关注的区域, 其次在对得到的区域进行细致分割, 直到得到所需要的手指和手掌的形状。跟踪过程包括对手部的不断定位和跟踪,并估计下一帧手的位置。 识别过程通过对之前的知识确定手势的意义, 并做出相应的反应, 例如显示出对应的手势或者做出相应的动作, 并对不能识别的手势进行处理, 或者报警或者记录下特征后在交互情况下得到用户的指导。 手势识别的基本框架如下图所示:
2、新兴的研究
2.1 网络海量数据的情感计算
随着时代的发展,网络赋予情感计算新的、更大的数据平台,打开了情感计算的新局面。网络系统由于沟通了人类的现实世界和虚拟世界,可以持续不断地对数量庞大的样本进行情感跟踪,每天这些映射到网络上的情绪不计其数,利用好这些数据反过来就可以验证心理学结论,甚至反哺心理学。由于大数据的分布范围极其广泛,样本数量非常庞大,采用单一的大数据处理方法往往得不到有效的情感要素,统计效果较差。但是,如果将大数据和心理学结合起来,局面就会大不一样:心理学中,不同情感可以采用维度标定,如冷暖或软硬,同时各种心理效应影响人类对事物的情感判断,如连觉效应、视觉显著性、视觉平衡等,在大数据中引入心理学效应和维度,对有效数据进行心理学情感标准划分,使得数据具有情感维度,这样就会让计算机模拟人类情感的准确性大大提升。网络海量数据的情感主要有以下几个社会属性:
情感随群体的变化:在社交网络,如论坛、网络社区等群体聚集的平台上流露出群体的情感,通过这些情感展现可以达到影响其他个人的行为。
情感随图片的变化:在社交媒体出现大量的图片,这些图片的颜色、光度、图片内容等各不相同。图片的特征直接影响到了观看者的情感。
情感随朋友的变化:在社交平台上,朋友发表的微博、微信状态等容易展现个人的情感。朋友间的关系比陌生人间的关系更加深入,所以朋友的情感更容易引起情感变化,在海量数据中,个人情感容易优先受朋友情感的影响。
情感随社会角色的变化:在社交网络中,个人在不同的群体所处的角色也不一样,个人情感流露时也会跟着所处的角色不一样而展现不同的情感。
情感随时间的演变:人的情绪是变化无常的,所处的环境不一样,则表现出来的情感也将不一样。即使是同一件事,不同的情景下展现的情感也会不一样。另外,事件的发展是个动态的过程,随着事件的演变,人的情感也会跟着变化。
2.2 多模态计算
虽然人脸、姿态和语音等均能独立地表示一定的情感,但人的相互交流却总是通过信息的综合表现来进行。所以, 只有实现多通道的人机界面,才是人与计算机最为自然的交互方式,它集自然语言、语音、手语、人脸、唇读、头势、体势等多种交流通道为一体,并对这些通道信息进行编码、压缩、集成和融合,集中处理图像、音频、视频、文本等多媒体信息。多模态计算是目前情感计算发展的主流方向。每个模块所传达的人类情感的信息量大小和维度不同。在人机交互中,不同的维度还存在缺失和不完善的问题。因此,人机交互中情感分析应尽可能从多个维度入手,将单一不完善的情感通道补上,最后通过多结果拟合来判断情感倾向。
在多模态情感计算研究中,一个很重要的分支就是情感机器人和情感虚拟人的研究。美国麻省理工学院、日本东京科技大学、美国卡内基·梅隆大学均在此领域做出了较好的演示系统。目前中科院自动化所模式识别国家重点实验室已将情感处理融入到了他们已有的语音和人脸的多模态交互平台中,使其结合情感语音合成、人脸建模、视位模型等一系列前沿技术,构筑了栩栩如生的情感虚拟头像,并积极转向嵌入式平台和游戏平台等实际应用。
目前, 情感识别和理解的方法上运用了模式识别、人工智能、语音和图像技术的大量研究成果。例如:在情感语音声学分析的基础上,运用线性统计方法和神经网络模型,实现了基于语音的情感识别原型;通过对面部运动区域进行编码,采用 HMM 等不同模型,建立了面部情感特征的识别方法;通过对人姿态和运动的分析,探索肢体运动的情感类别等等。不过,受到情感信息捕获技术的影响, 以及缺乏大规模的情感数据资源,有关多特征融合的情感理解模型研究还有待深入。随着未来的技术进展,还将提出更有效的机器学习机制。
人才
1、 全球学者概况
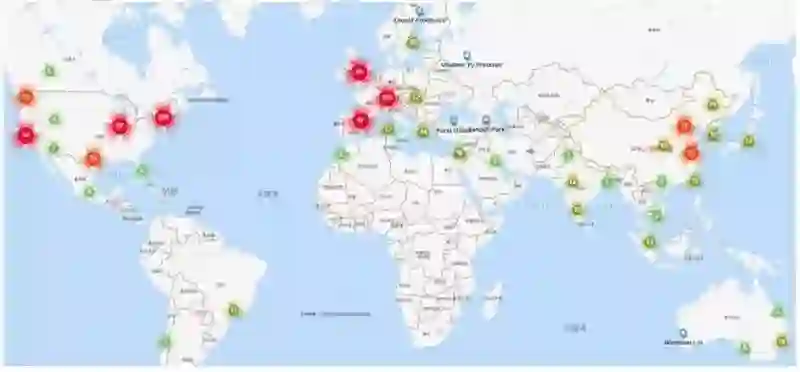
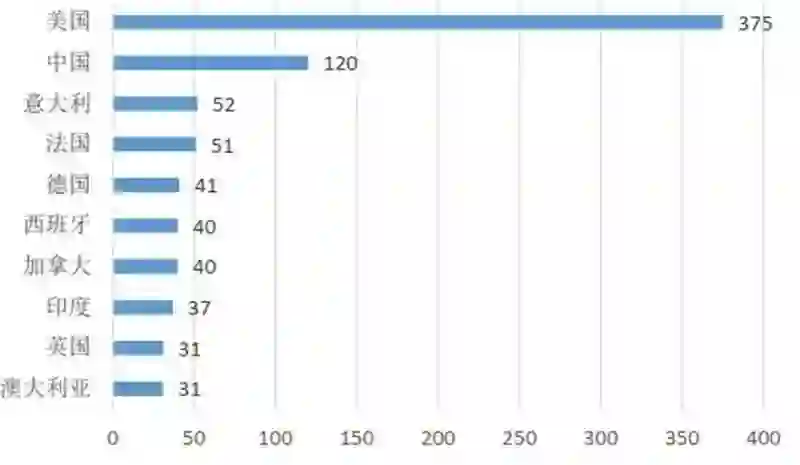
学者分布地图对于进行学者调查、分析各地区竞争力现况尤为重要, 下图为情感计算领域全球顶尖学者分布状况。 其中, 颜色越趋近于红色, 表示学者越集中;颜色越趋近于绿色,表示学者越稀少。 从地区角度来看,北美洲、欧洲是情感计算领域学者分布最为集中的地区,亚洲东部地区次之, 南美洲和非洲学者极为匮乏。从国家角度来看, 情感计算领域的人才在美国最多,中国次之,意大利、法国等洲国家也有较多的学者数量,整体上讲其它国家与美国的差距较大。
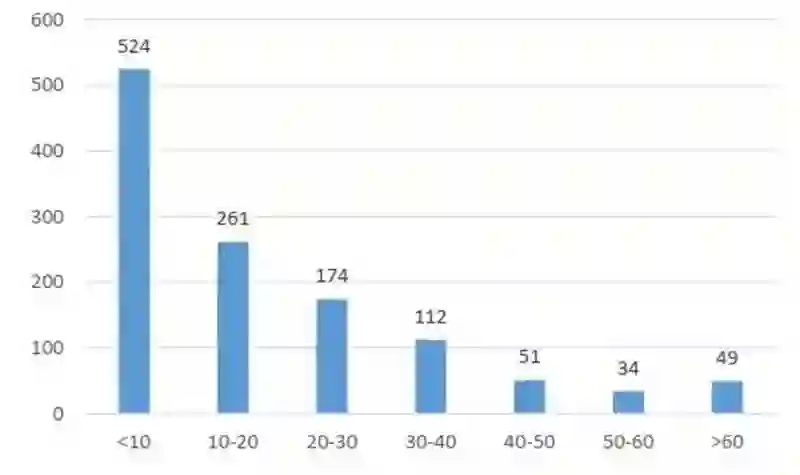
情感计算领域学者的 h-index 分布如下图所示,分布情况整体呈阶梯状,大部分学者的 hindex 分布在中低区域,其中 h-index 在<10 的区间人数最多,有 524 人, 占比 43.4%, 50-60 区间人数最少, 有 46 人, 占比 3.8%。
各国情感计算 TOP学者的流失和引进是相对比较均衡的,其中美国是情感计算领域人才流动大国,人才输入和输出幅度领先于其他国家,且从数据来看人才流出大于人才流入。英国、加拿大和印度等国人才迁徙流量小于美国;中国人才流入略高于人才流出。人才的频繁流入流出,使得该领域的学术交流活动增加,带动了人才质量提升的同时,也促进了领域理论及技术的更新迭代, 逐渐形成一种良性循环的过程。

2、 国内学者概况
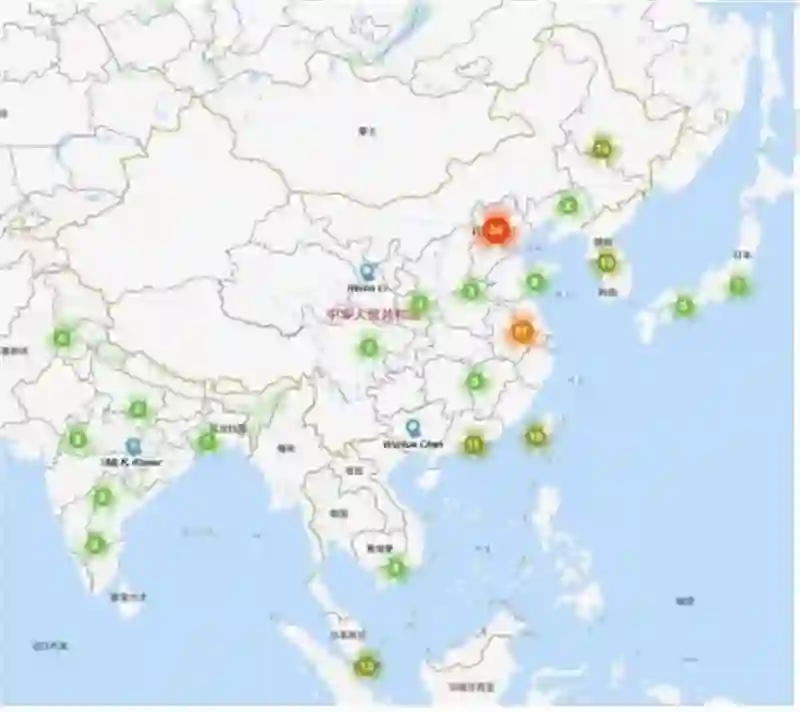
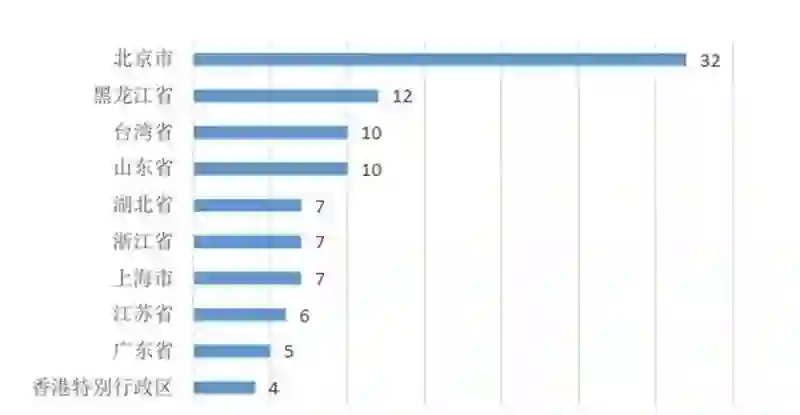
AMiner 选取情感计算领域国内专家学者绘制了学者国内分布地图,如下图所示。通过下图我们可以发现,京津地区在情感计算领域的人才数量最多,东部及南部沿海地区的也有较多的人才分布,相比之下,内陆地区信情感计算领域人才较为匮乏,这也从一定程度上说明了情感计算领域的发展与该地区的地理位置和经济水平都是息息相关的。同时,通过观察中国周边国家的学者数量情况,特别是与日本、东南亚等亚洲国家相比,中国在情感计算领域顶尖学者数量方面具有较为明显的优势。 图 8 是我国情感计算领域顶尖学者最多的 10 个省份。
情感计算应用
近年来, Picard 领导的美国麻省理工学院多媒体实验室相继提出了近 50 种情感计算应用项目。例如,将情感计算应用于医疗康复,协助自闭症者,识别其情感变化,理解患者的行为;在教育中应用情感计算,实现对学习状态的采集及分析,指导教学内容的选择及教学进度进行;还可以将情感计算应用于生活中,计算机能够感知用户对音乐的喜好, 根据对情感反应的理解判断,为用户提供更感兴趣的音乐播放等。
1、 课堂教学
在美国,公立学校的预算限制引发大规模的教师裁员和教室拥挤不堪。教师工作时间紧张,还要考虑和满足每个学生的需求。结果就是,那些课业困难的孩子容易受到忽视。因为只要孩子不提出问题,老师就不会关注到他。
在过去三年里,有企业把面部识别技术应用到了第一线教学当中。在 SensorStar 实验室,他们用相机捕捉学生上课反应,并且输入到计算机里面,运用算法来确定学生注意力是否转移。通过面部识别软件 EngageSense,计算机能够测量微笑、皱眉和声音来测定学生课堂参与度。孩子们的眼睛是专注于老师的吗? 他们是在思考还是发呆?他们是微笑还是皱着眉头?或者他们只是觉得困惑?还是无聊?测量之后,老师将会收到一份反馈报告,基于面部分析, 报告会告诉老师他们的学生学习兴趣何时最高、何时最低。这样,老师能够对自己的教学方案做出调整,满足更多学生的需求。此外,比尔和梅林达盖茨基金会资助了传感器手镯(sensor bracelets)的开发,这可以用来追踪学生的参与水平。腕部设备能够发送小电流,通过在神经系统响应刺激时测量电荷的细微变化便可以得知学生的课程兴奋程度。
心理学家 Paul Ekman 将面部识别技术研究提升到了一个新的层次。他对 5000 多种面部运动进行了分类,以帮助识别人类情绪。他的研究为 Emotient Inc、 Affectiva Inc 和 Eyeris 等公司提供了帮助,这些公司将心理学和数据挖掘相结合,检测人的细微表情,并对人的反应进行分类。目前为止,面部识别技术的重点是协助联邦执法和市场调研。不过,圣地亚哥市的研究人员也在医疗行业试用这项技术,测定孩子接受外科手术之后的疼痛程度。
2、 机器学习定制学生课堂学习内容
TechCrunch 公司的员工设计了在线教育平台,来提供一对一指导和精熟学习( masterylearning)。这是应用创新型思维,通过实时的评估和定制化的学习方式,有效地解决本杰明提出的著名的“Sigma 2 Problem” 。深度学习系统将学生学习效果数据进行分类,并且在此基础上制定相关的教学内容。该系统还可以推荐附加练习,并且根据学生个人能力和教学要求,实时推荐课程内容,调整教学速度 。
北卡罗来纳州州立大学研究员开发了一种软件,通过摄像头捕捉和分析学生面部表情,以此改变在线课程。 目前,大多数情感计算技术还仅仅停留在学术研究领域。 但也已经有公司开始应用这项技术,并能成功地分辨学生表情,并根据他们的学习能力和方式,来自动调整适合的学习内容和环境。英特尔公司正是这其中的一员。有了这些学生表情数据,可以让“Emoshape”这样的情感计算智能系统,自动分析情感,并做出适当回复。这些系统具备了解决个体问题的能力,也使老师能够提供高度个性化的内容来激发学生的学习兴趣。
人工智能和大数据已经促成了大部分行业的技术革新,从电子商务到交通、金融、医疗。人工智能和大数据已经在教育方面取得进展。 尽管有些反对的声音,比如说如何保护学生隐私、如何提高教学效率等, 但需要指出的是,这些技术的应用并不是要代替老师,而是扮演辅助老师的角色,识别学生的个体需求,以制定更加智能的教学方案。
3、 情绪监测
为了深度挖掘人类情感的奥秘, 美国麻省理工学院计算机科学与人工智能实验室打造了用无线信号监测情绪的 EQ-Radio。在没有身体感应器和面部识别软件辅助的情况下, EQ-Radio通过测量呼吸和心跳的微小变化, 利用无线信号捕捉到一些肉眼不一定能察觉的人类行为,判断一个人到底处于以下四种情绪中的哪一种:激动、开心、生气或者忧伤,正确率高达 87%。美国麻省理工学院教授和该项目的负责人 Dina Katabi 预测,这个系统会被运用于娱乐、消费者行为和健康护理等方面:电影工作室和广告公司也可以用这个系统来测试观众实时的反应;而在智能家居的环境中,该系统可以通过捕捉与人的心情有关的信息,调节室内温度,或者建议你应该呼吸一些新鲜空气。
现有的情绪监控方法大多依赖于视听设备或者是安装在人身上的感应器,这两种技术都有缺点:面部表情并不一定符合内心状态,而安装在身上的感应器(比如胸带和心电监护仪)会造成各种不便,而且一旦它们的位置稍微移动,监测到的数据就不精确了。
EQ-Radio 会发送能监测生理信息的无线信号,该信号最终会反馈给设备本身。其中的算法可以分析心跳之间的微小变化,从而判断人们的情绪。消极情绪会被判定为“忧伤” , 而正面 且高涨的情绪会被判定为“激动” 。尽管这样的测量会因人而异,但其中还是有内在统一性。通过了解人们处于不同的情绪状态下,他们的心跳会如何变化,我们就可以对他所处的情绪状态进行有效的判断。
在他们设计的实验中,参与实验者选择他们记忆中最能代表激动、开心、生气、忧伤以及毫无情感的一段视频或音乐。在掌握了这段时长两分钟的视频里的五种情绪设置后, EQ-Radio可以精确地通过一个人的行为判断他处于这四种情绪中的哪一种。与微软研发的基于视觉和面部表情的 Emotion API 相比, EQ-Radio 在识别喜悦、忧伤和愤怒这三个情绪上精确度更高。同时,这两种系统在判断中性情绪时的精准度差不多,因为毫无情绪的脸总是更容易被识别。
目前,对美国麻省理工学院计算机科学与人工智能实验室而言,最艰巨的任务就是摆脱不相关数据的干扰。比如,为了分析心率,他们要抑制呼吸可能带来的影响,因为呼吸时,人的肺部起伏比他心跳时的心脏起伏要大。

4、 医疗康复
近年来,情感计算运用于自闭症治疗得到越来越多的关注。例如, 美国麻省理工学院情感计算团队正在开发世界上第一个可穿戴的情感计算技术设备:一个具有社交智能的假肢,用来实时检测自闭症儿童的情感, 帮助机器人使用自闭症儿童独有的数据, 来评估这些互动过程中每个孩子的参与度和兴趣。 这个装置用一个小型照相机,分析孩子的面部表情和头部运动来推断他们的认知情感状态。还有一种叫“galvactivator” 的工具,通过测量穿戴者的皮肤电流数据,推断孩子的兴奋程度。这个像手套一样的设备可以利用发光二极管描绘出人体生理机能亢奋程度的图谱。这种可视化的展现方式,能够清晰地展示出人的认知情感水平。 NAO 机器人和个性化的机器学习在治疗自闭症患者上也表现出很大的优越性:
人类治疗师会向孩子展示一张照片或者闪存卡片,用来表示不同的情绪,以教会他们如何识别恐惧、 悲伤或喜悦的表情。治疗师随后对机器人进行编程, 向孩子们展示这些相同的情绪,并且在孩子与机器人交往时观察孩子。孩子们的行为提供了宝贵的反馈信息,机器人和治疗师可以根据反馈信息继续学习。
研究人员在这项研究中使用了 SoftBank Robotics NAO 类人机器人。NAO 将近 2 英尺高,类似于装甲超级英雄,通过改变眼睛的颜色、 肢体的运动以及声音的音调来表达不同的情绪。参加这项研究的 35 名自闭症儿童中,有 17 人来自日本, 18 人来自塞尔维亚,年龄从 3 岁到 13岁不等。他们在 35 分钟的会议中以各种方式对机器人做出反应,从看起来无聊和困倦,到在房间里兴奋地跳来跳去,拍手,大笑或触摸机器人。研究中的大多数孩子对机器人的看法是,它不仅仅是一个玩具,应该尊重 NAO,因为它是一个真实的人。另外,人类用许多不同的方式改变自己的表情,但机器人则通过同样的方式来改变表情,这对孩子来说更加有利,因为孩子可以通过非常有条理的方式学习如何表达表情 。
麻省理工学院的研究小组意识到, 具有深度学习能力的治疗机器人能够更好感知儿童的行为的。深度学习系统使用分层的多层数据处理来处理其任务,每一个连续的层都是对原始数据抽象的表示。
尽管自 20 世纪 80 年代以来深度学习的概念已经出现,但直到最近才有足够的计算能力来实现这种人工智能。深度学习已被用于自动语音和对象识别程序中, 这种应用非常适合解决面部、 身体和声音等多重特征的问题,从而更好地理解抽象的概念,如儿童的参与感。
对于治疗机器人,研究者构建了一个个性化框架,可以从收集的每个孩子的数据中学习。研究人员拍摄了每个孩子的脸部表情、 头部和身体动作、 姿势和手势, 记录了儿童手腕上显示器的心率、 体温和皮肤汗液反应作为数据。这些机器人的个性化深度学习网络是根据这些视频、音频和生理数据的层次, 针对孩子的自闭症诊断和能力、 文化和性别的信息构建的。研究人员将机器人对儿童行为的估计与五位人类专家的估计数字进行了比较,这些专家连续对孩子的录像和录音进行编码,以确定孩子在会议期间高兴或不安程度,是否感兴趣以及孩子的表现。比较发现,机器人对儿童行为的估计要比专家更加具体清晰。
5、 舆情监控
网络调查法、 统计规则法和文本内容挖掘是三种经常被使用的网络舆情分析方法。大数据时代的来临使传统的舆情分析方式发生改变,大数据时代数据量突增、 数据产生的速度极快、冗余信息占比高的特性不仅给舆情分析带来新的发展机遇, 也带来了新的难度和挑战。基于简单调查和统计的舆情分析方法将无法适用于大数据环境下的网络社区文本。当前国内外对舆情分析技术的研究也大多以大数据环境为背景,与传统舆情分析技术相比,大数据时代网络社区的舆情分析技术更多地集中于对数据的获取, 并采取文本数据分析、数据挖掘、语义分析等技术获取舆情信息。 当前国内外的舆情分析技术研究主要集中于话题识别与话题跟踪、意见领袖识别以及情感倾向判别这三个方面。
话题识别与话题跟踪首先在文本中识别出新话题, 接下来在一段时间内检测并实时跟踪话题,实现该话题的再现,研究其随时间发展的演化过程。聚类方法常用于进行话题识别。在国外研究中,话题检测与跟踪(TDT)是了解社交媒体热点话题及其演变过程的重要手段。
意见领袖的发现和识别重点在于评价指标的制定以及模型的构建。例如,曹玖新等将网络社区用户看作一个个节点,根据节点之间信息的交互和传播过滤, 从用户结构、行为和情感三个特征维度挖掘意见领袖。
情感倾向判别在舆情研究中最为常见,首先收集 web 金融领域的文本数据属性, 接下来构建金融领域的情感词典, 最后结合语义分析,将语义规则应用到情感及情感强度识别当中,提升了分类器的准确率 M。王永等人将倾向分析应用到客户评论信息挖掘当中,结合情感词之间的依存关系计算面向产品特征的情感倾向得分,从网络评论中获取有价值的商业信息。国外针对 Twitter 的情感倾向分析研究居多,用以获取有价值的信息和舆论导向,例如,结合语言规则特征可以分别获取正面和负面的 Twitter 文章,反应公众的舆情态度。

趋势
1、 论文研究发展趋势
Trend analysis(http://trend.aminer.cn)基于 AMiner 的 2 亿篇论文数据进行深入挖掘,包括对技术来源、热度、发展趋势进行研究,进而预测未来的技术前景。技术趋势分析描述了技术的出现、变迁和消亡的全过程,可以帮助研究人员理解领域的研究历史和现状,快速识别研究的前沿热点问题。
下图是当前情感计算领域的热点技术趋势分析,通过 Trend analysis 分析挖掘可以发现当前该领域的热点研究话题 Top10 是 Affective Computing、 Social Robot、 Emotion Recognition、 Human Computer Interaction、 Feature Extraction、 Support Vector Machine、 Facial Expression、 Human RobotInteraction、 Behavioural Sciences Computing、 Face Recognition。

根据Trend analysis的分析我们可以发现, 该领域当前最热门的话题是Affective Computing,从全局热度来看, Affective Computing 的话题热度虽然有所起伏, 但从 20 世纪 90 年代开始,热度迅速上升,甚至在五年内超过了此前的话题 Top 1 Emotion Recognition, 并且至今其话题热度始终保持在 Top1,论文的发表数量也较多;Social Robot 的研究热度跟随 Affective Computing同期上升,近几年话题热度更是超越 Emotion Recognition 成为 Top2 话题;另外,前期比较热门的 Feature Extraction 经过了一段时间的低迷期后,也回到了 Top3 的位置。
2、 情感计算技术预见
研究者根据情感计算领域近十年的相关论文,利用大数据分析、机器学习、人工智能等技术手段,建立算法模型及研发 demo 系统,分析挖掘出该领域的技术发展热点。 技术预见图中点的大小表示该技术的热点(主要由相关论文数量的多少决定,相关论文越多,热度越高,点越大),各技术之间的连线表示 2 个技术关键词同时在 N 篇论文中出现过(当前 N 的取值为 5)。

根据情感计算技术预见图,可以得出情感计算领域相关度最高的技术有 3 项,分别为:feature extraction、 human computer interaction 和 emotion recognition。
按照技术前沿度,可以列出相关的主要技术关键词,以及该技术历年的变化趋势(论文发表数量变化趋势),及重要代表性成果。具体如下图所示 :
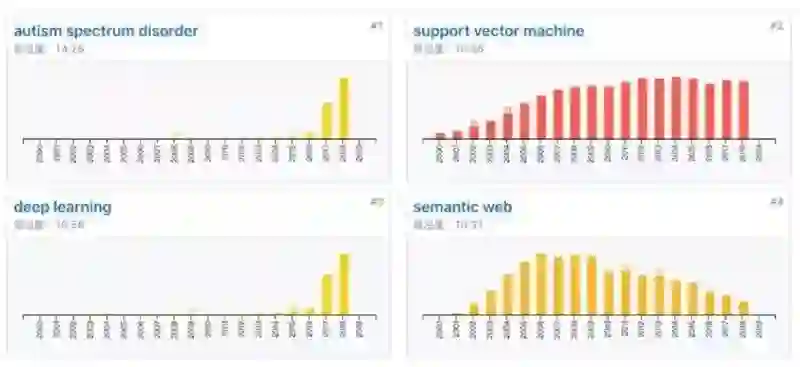
图 15 中我们可以看出,情感计算领域预测前沿度比较高的前四热词有:autism spectrumdisorder(前沿度为 1428)、 support vector machine(前沿度为 1096)、 deep learning(前沿度为 1058)和 semantic web(前沿度为 1031)。
如果说目前的传统计算机(包括应用现有智能计算方法的计算机)只包含了反映理性思维(Thinking)的“脑(Brain)”,那么,情感计算将为该机器增添了具有感性思维(Feeling)的“心(Heart)”(这是应用文学方式对机器进行拟人化比喻。按认知科学讲,感性思维仍源于脑活动)。可以认为,情感计算是在人工智能理论框架下的一个质的进步。因为从广度上讲它扩展并包容了情感智能,从深度上讲情感智能在人类智能思维与反应中体现了一种更高层次的智能。情感计算必将为计算机的未来应用展现一种全新的方向。

未来智能实验室是人工智能学家与科学院相关机构联合成立的人工智能,互联网和脑科学交叉研究机构。
未来智能实验室的主要工作包括:建立AI智能系统智商评测体系,开展世界人工智能智商评测;开展互联网(城市)云脑研究计划,构建互联网(城市)云脑技术和企业图谱,为提升企业,行业与城市的智能水平服务。
如果您对实验室的研究感兴趣,欢迎加入未来智能实验室线上平台。扫描以下二维码或点击本文左下角“阅读原文”




