Smart Compose:神经网络辅助写邮件
【导读】近日,在Google I/O大会上发布了Smart Compose功能,通过深度学习模型,为用户提供快速的邮件补全功能,极大的提高了用户的键入速度。具体是如何实现的呢?下文是Google blog上发表的最新Smart Compose技术文章,让我们通过本文,近距离认识下Smart Compose吧~
作者 | Yonghui Wu
编译 | 专知
参与 | Yongxi, Huaiwen
Smart Compose: Using Neural Networks to Help Write Emails
上周的Google I/O大会中,我们介绍了Smart Compose功能,这是Gmail中的一个新特性,可以在用户键入文字的过程中,使用机器学习算法交互式的提供句子补全建议,帮助用户提高邮件写作速度。本功能基于Smart Reply开发,为用户提供了一种全新的撰写邮件的方式。

在Smart Compose开发过程中,有几点关键问题需要解决:
延迟:由于Smart Compose在用户的每次键入时都要进行预测,那么就必须有实时性的保证,以满足用户体验,这使得在模型复杂性和预测速度上作出平衡,就显得尤为重要。
规模:Gmail的用户量超过了14亿人,为了对所有用户都能提供好用的自动补全功能,该模型功能必须十分强大,才能在微妙的上下文差异中进行个性化的建议。
公正和隐私:在开发Smart Compose时,我们需要对训练过程中潜在的偏见信息进行处理,并严格遵守用户隐私标准,以确保模型不会暴露用户的隐私信息,另外,研究人员将无法读取到线上的电子邮件信息,这意味着,他们将开发一个机器学习系统,来处理他们自己无法读取的数据集。
寻找合适的模型
经典的语言生成模型,如n-gram、BoW和RNN语言模型(RNN-LM)等,都是将单词前缀作为下一个单词的预测条件。然而,在电子邮件中,用户在邮件中键入的单词只是一个可以被模型利用的“信号”而已,为了结合更多有关用户意图的上下文信息,我们的模型也考虑了用户正在写的当前邮件的标题信息和被用户回复的那封邮件的正文信息。
整合附加上下文的方法之一是,将问题转变为seq2seq的机器翻译任务,源序列是邮件主题与被回的邮件正文(如果一个人正在回邮件)的拼接文本,目标序列是用户当前正在编写的电子邮件,虽然这种方法在预测质量上很有效果,但它无法达到我们的实时性指标要求。
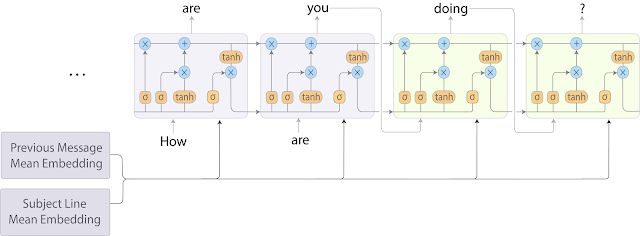
为了改进这一点,我们将一个BoW模型和一个RNN-LM模型做了结合,这比seq2seq模型要快很多,但是降低了模型的预测质量。在混合方法中,我们计算当前邮件主题与被回的邮件的正文词向量,然后用词向量的均值当成它们的编码。然后,将向量均值拼接,并在解码步骤中将它们输入到目标序列RNN-LM中,如下图所示:
加快模型训练和服务
即使模型方法确定下来,我们同样需要对各类超参数进行调整,并对模型进行几十亿次的训练,所有的操作都是非常耗时的,为了加快速度,我们使用了一整个TPUv2 Pod来进行实验,这样我们就可以在不到一天的时间里完成对模型的训练。
虽然加速了模型训练过程,但在标准CPU机器上运行的Smart Compose初始版本仍然需要几百毫秒平均延迟,这对我们节省用户时间的目标是无法接受的。幸运的是,TPU也可以用在模型运行过程中,通过将大部分计算转移到TPU上,我们将平均延迟降低到了数十毫秒,同时,也大大增加了单机可提供的请求数量。
公平与隐私
机器学习模型的公正性是非常重要的,因为语言理解模型反映了人类的认知偏差,这将导致模型出现一些不必要的单词联想建议(如脏话等)。正如Caliskan等人在最近的论文中指出的那样,“从语料库中自动导出的语义包含了类似人类的偏见”,这些信息将严重影响模型的训练。我们正在积极研究如何对抗这种潜在的偏见,另外,由于Smart Compose训练了数十亿的短语和句子信息,与垃圾邮件机器学习模型的训练方式类似,同时做了大量的测试工作,以确保我们的模型能够记忆多个用户使用的常用短语,并使用了本文的研究结论(https://arxiv.org/abs/1802.08232)。
未来的工作
我们一直致力于通过先进架构(如Transformer,RNMT+等)来改进语言生成模型的质量,并尝试最新的训练技术。一旦我们满足了严格的延迟约束,我们就会将更高级的模型部署到生产环境中,同时也在致力于个人语言模型的整合,旨在更准确地模拟个人的写作风格。
致谢:
Smart Compose语言生成模型,由以下人员开发完成: Benjamin Lee, Mia Chen, Gagan Bansal, Justin Lu, Jackie Tsay, Kaushik Roy, Tobias Bosch, Yinan Wang, Matthew Dierker, Katherine Evans, Thomas Jablin, Dehao Chen, Vinu Rajashekhar, Akshay Agrawal, Yuan Cao, Shuyuan Zhang, Xiaobing Liu, Noam Shazeer, Andrew Dai, Zhifeng Chen, Rami Al-Rfou, DK Choe, Yunhsuan Sung, Brian Strope, Timothy Sohn, Yonghui Wu, and many others.
原文链接:
https://ai.googleblog.com/2018/05/smart-compose-using-neural-networks-to.html?m=1
更多教程资料请访问:专知AI会员计划
-END-
专 · 知
人工智能领域主题知识资料查看与加入专知人工智能服务群:
【专知AI服务计划】专知AI知识技术服务会员群加入与人工智能领域26个主题知识资料全集获取

[点击上面图片加入会员]
请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请加专知小助手微信(扫一扫如下二维码添加),加入专知主题群(请备注主题类型:AI、NLP、CV、 KG等)交流~

请关注专知公众号,获取人工智能的专业知识!
点击“阅读原文”,使用专知




