【WWW2021】反事实学习排序中的鲁棒泛化和安全查询专门化

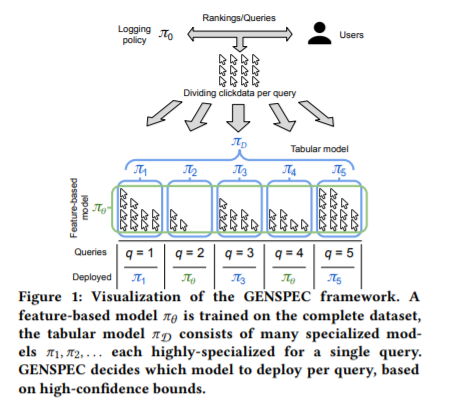
现有的反事实学习排名(LTR)工作集中于优化基于特征的模型,该模型基于文档特征预测最优排名。基于bandit算法的LTR方法通常优化表格模型,这些表格模型记住每个查询的最佳排名。这些类型的模型都有各自的优点和缺点。基于特征的模型在许多查询(包括那些以前未见过的查询)中提供了非常健壮的性能,但是,可用的特征往往限制了模型可以预测的排名。相反,表格模型通过记忆可以收敛于任何可能的排名。然而,记忆非常容易产生噪音,这使得表格模型只有在大量用户交互可用时才可靠。我们能否开发一种稳健的反事实LTR方法,在安全的情况下追求基于记忆的优化? 我们介绍了泛化和专门化(GENSPEC)算法,这是一种鲁棒的基于特征的反事实LTR方法,在安全的情况下,它会对每个查询进行记忆。GENSPEC优化了单个基于特性的模型以实现泛化:跨所有查询的健壮性能,以及用于专门化的许多表模型:每个表模型都针对单个查询优化了高性能。GENSPEC使用新颖的相对高可信度边界来选择每个查询部署哪个模型。通过这样做,GENSPEC成功地实现了专门化表格模型的高性能和基于特征的广义模型的鲁棒性。我们的结果表明,GENSPEC可以在具有足够点击数据的查询上获得最佳性能,而在数据很少或有噪声的查询上具有健壮的行为。
https://www.zhuanzhi.ai/paper/b0324110474b3753db34a6296cd76504
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“CLTR” 可以获取《【WWW2021】反事实学习排序中的鲁棒泛化和安全查询专门化》专知下载链接索引



登录查看更多
相关内容
Arxiv
7+阅读 · 2019年2月18日
相关VIP内容
相关资讯
相关论文
Arxiv
7+阅读 · 2019年2月18日