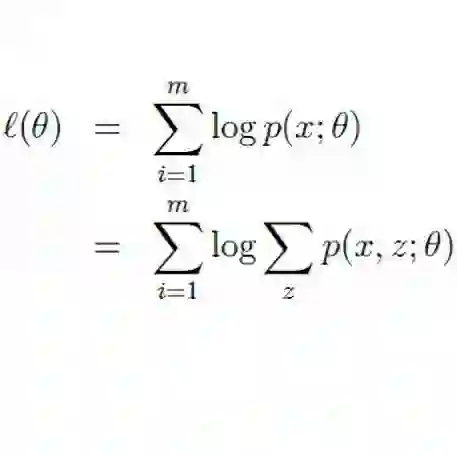K-means聚类与EM算法

一:内容预告
K-means的原理
初始类中心的选择和类别数K的确定
K-means和EM算法、高斯混合模型的关系
二:K-means的原理
频率学派和贝叶斯学派的区别
频率学派和贝叶斯学派的区别
频率学派和贝叶斯学派的
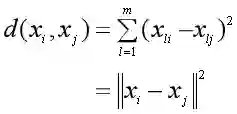
接着,把所有样本与所属类中心的距离平方和,定义为损失函数:
其中rnk∈{0,1},n=1,2,...,N,k=1,2,...,K,如果rnk=1,那么表示样本xn属于第k类,且对于j≠k,有rnj=0,也就是样本xn只能属于一个类别。
于是我们需要找到{rnk}和{μk}的值,使得距离平方之和J最小化。
K-means是一种迭代算法,每次迭代涉及到两个连续的步骤,分别对应rnk的最优化和μk的最优化,也对应着EM算法的E步(求期望)和M步(求极大)两步。
首先,为μk选择一些初始值,也就是初始化K个类中心。
然后,执行以下两个步骤,直至收敛。
第一步:保持μk固定,选择rnk来最小化J,也就是把样本指派到与其最近的中心所属的类中,得到一个聚类结果。
第二步:保持rnk固定,计算μk来最小化J,也就是更新每个类别的中心。
具体来说,也就是E步和M步:
E步:在类中心μk已经确定的情况下,最优化rnk
这一步比较简单,我们可以分别对每个样本xn进行最优化。
将某个样本分配到第k个类别,如果该样本和第k个类别的距离最小,那么令rnk=1。
对N个样本都这样进行分配,自然就得到了{rnk},使所有样本与类中心的距离平方和最小,从而得到了一个聚类结果。
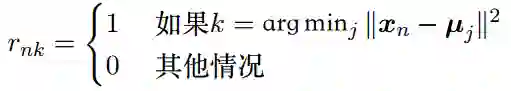
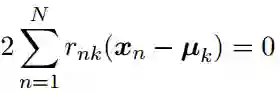
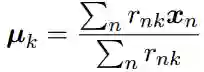
-
K-means可能收敛到目标函数J的局部极小值,不能保证收敛到全局最小值。 -
聚类之前,需要对数据集进行标准化,使样本的均值为0,标准差为1。 -
初始类中心的选择会直接影响聚类结果,选择不同的初始类中心,可能会得到不同的聚类结果。 -
K均值聚类算法的复杂度是O(mnk),m是样本的特征维度,n是样本个数,k是类别个数。
四:初始化类中心和确定类别数
频率学派和贝叶斯学派的区别
频率学派和贝叶斯学派的区别
K-means的思想比较简单,关键在于初始类中心的选择和类别数K的确定,这对聚类的结果有比较大的影响。
(一)第一种方法
用层次聚类法进行初始聚类,然后把这些类中心作为K均值聚类的初始类中心。
层次聚类的复杂度为O(mn3),m是样本的特征维度,n是样本个数,复杂度也是蛮高的,那为什么用层次聚类的结果来初始化类中心呢?
我想是因为层次聚类的结果,完全是由算法确定的,是一个客观的结果。这样就把K-means的初始类中心的选择问题,由主观决定变成了客观决定。
(二)第二种方法
首先随机选择一个点,作为第一个初始类中心点,然后计算该点与其他所有样本点的距离,选择距离最远的点,作为第二个初始类的中心点,以此类推,直到选出K个初始类中心点。
(一)轮廓系数
轮廓系数(Silhouette Coefficient)可以用来判定聚类结果的好坏,也可以用来确定类别数K。
一个好的聚类结果,要能保证类别内部样本之间的距离尽可能小(密集度),而类与类之间样本的距离尽可能大(离散度)。
轮廓系数就是一个用来度量聚类的密集度和离散度的综合指标。
轮廓系数的计算过程和使用如下:
①计算样本xi到同类Ck其他样本的平均距离ai,将ai称为样本xi的簇内不相似度,ai越小,说明样本xi越应该被分配到该类。
②计算样本xi到其他类Cj所有样本的平均距离bij,j=1, 2 ,..., K,j≠k,称为样本xi与类别Cj的不相似度。
定义样本xi的簇间不相似度:bi =min{bi1, bi2, ...,bij,..., biK},j≠k,bi越大,说明样本xi越不属于其他簇。
③根据样本xi的簇内不相似度ai和簇间不相似度bi,定义样本xi的轮廓系数si,作为样本xi分类合理性的度量。
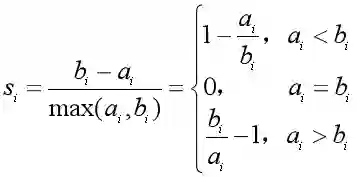
④轮廓系数范围在[-1,1]之间,该值越大,聚类结果越好。
si接近1,则样本xi被分配到类别Ck的结果比较合理;si接近0,说明样本xi在两个类的边界上;si接近-1,说明样本xi更应该被分配到其他类别。
⑤计算所有样本的轮廓系数si的均值,得到聚类结果的轮廓系数S,作为聚类结果合理性的度量。轮廓系数越大,聚类结果越好。
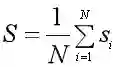
⑥使用不同的K值进行K均值聚类,计算各自的轮廓系数S,选择较大的轮廓系数所对应的K值。
(二)肘部法则
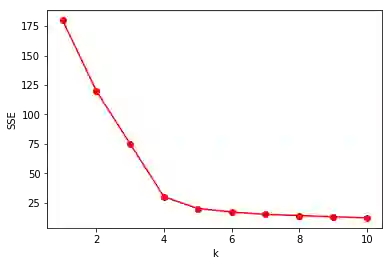
K-means的损失函数,是所有样本到类别中心的距离平方和J,也就是误差平方和SSE:
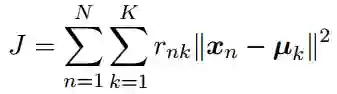
从类别数K=1开始,当类别数K小于真实的类别数时,随着类别数的增大,SSE会快速地下降。
而当类别数到达真实类别数的临界点后,SSE开始缓慢下降,也就是说SSE和K的关系曲线一个肘部形状,这个肘部所对应的K值可以认为是合适的类别数。
那么我们选择不同的K值,训练多个模型,然后计算模型的SSE,选择SSE开始缓慢下降时的K值,作为聚类的类别数。
如下图,可以选择4或5作为聚类的类别数。
五:与EM、GMM的关系
频率学派和贝叶斯学派的区别
这一部分,需要EM算法和高斯混合模型的前置知识。
这篇是我在博客园上总结的:
《聚类之高斯混合模型与EM算法》
https://www.cnblogs.com/Luv-GEM/p/10851395.html
关于K-means与EM算法、高斯混合模型的关系,主要有以下三点:
1:K-means是一种非概率的聚类算法,属于硬聚类方法,即一个样本只能属于一个类(类与类之间的交集为空)。
相比之下,高斯混合模型(GMM)是一种基于概率的聚类算法,属于软聚类方法,每个样本按照一个概率分布,属于多个类。
2:K-means在一次迭代中的两个步骤,可以看做是EM算法的E步和M步。
而且K-means可以看做,用EM算法对⾼斯混合模型进行参数估计的⼀个特例,也就是高斯混合模型中分模型的方差σ2相等,为常数,且σ2→0时的极限情况。
3:K-means和基于EM算法的高斯混合模型,对参数的初始化值比较敏感。
由于K-means的计算量远小于基于EM算法的高斯混合模型,所以通常运⾏K-means,来找到⾼斯混合模型的⼀个初始值,再用EM算法进行调节。
具体而言,用K-means划分K个类别,再用各类别样本所占的比例,来初始化K个分模型的权重;用各类别中样本的均值,来初始化K个高斯分布的期望;用各类别中样本的方差,来初始化K个高斯分布的方差。
为了理解以上几点,尤其是第2点,我们可以先从图形来看。
假设高斯混合模型由4个高斯分布混合而成,高斯分布的密度函数如下。。
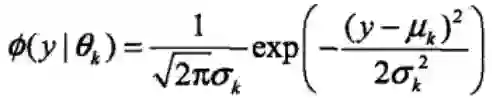
Ø(y|θk)是第k个高斯分布的概率密度,被称为第k个分模型,参数为θk=(μk, αk2)。
令均值μ=[0,2,4,6],方差σ2=[1,2,3,1],则4个高斯分布的概率密度函数的图形如下。
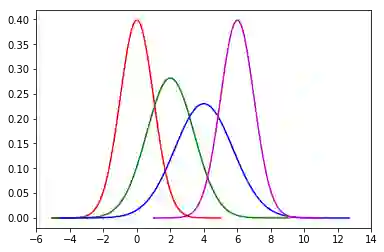
我们可以看到,4个图形之间有重叠的部分,也就说明每个样本可以按照一个概率分布αk,属于多个类,只是属于某类的概率大些,属于其他类的概率小些。
这表明高斯混合模型是一种软聚类方法。
然后令均值μ不变,方差σ2=[0.01, 0.01, 0.01, 0.01],也就是4个分模型的方差σk2相等,而且σk2→0,那么4个高斯分布的图形如下。
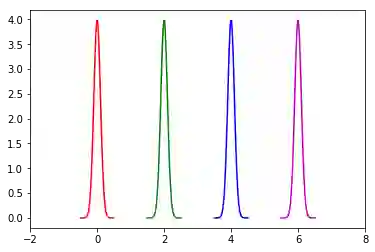
每个高斯分布的图形之间没有交集,那么每个样本只属于一个类,变成了硬聚类。
这也就是高斯混合模型的特例:K-means。
用EM算法对高斯混合模型进行极大似然估计,在E步,我们需要基于第i轮迭代的参数θ(i)=(αk, μk, σk)来计算γjk,γjk是第j个样本yj来自于第k个高斯分布分模型的概率,k=1,2,...,K。
在高斯混合模型中,γj是一个K维的向量,也就是第j个样本属于K个类的概率。假设分模型的方差σk2都相等,且是一个常数,不需要再估计,那么在EM算法的E步我们计算γjk

考虑σ2→0时的极限情况,如果样本yj属于第k类的概率最大,那么该样本与第k类的中心点的距离非常近,(yj - μk)2将会趋于0,于是有:
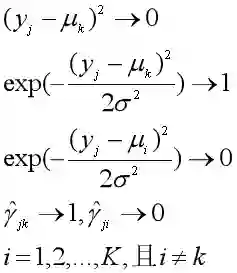
也就是样本yj属于第k类的概率近似为1,属于其他类别的概率近似为0,也就成为了一种硬聚类,也就是K-means。
其实在σ2→0的极限情况下,最大化高斯混合模型的完全数据的对数似然函数的期望,等价于最小化K均值聚类的目标函数J。
比如有4个高斯分布,样本yj的γj为[0.55, 0.15, 0.2, 0.1],那么属于第1类的概率γj1最大。
而当分模型的方差σ2→0时,样本yj的γj可能为[0.98, 0.01, 0.005, 0.005],也就是该样本直接被分配到了第1类,成为了硬聚类。
import matplotlib.pyplot as plt
import math
import numpy as np
""" 1: 4个高斯分布的均值 """
u1 = 0
u2 = 2
u3 = 4
u4 = 6
""" 2: 4个高斯分布的标准差 """
sig1 = math.sqrt(1)
sig2 = math.sqrt(2)
sig3 = math.sqrt(3)
sig4 = math.sqrt(1)
def x(u,sig):
return np.linspace(u - 5*sig, u + 5*sig, 100)
x1 = x(u1,sig1)
x2 = x(u2,sig2)
x3 = x(u3,sig3)
x4 = x(u4,sig4)
""" 3: 概率密度 """
def y(x,u,sig):
return np.exp(-(x - u) ** 2 /(2* sig**2))/(math.sqrt(2*math.pi)*sig)
y1 = y(x1,u1,sig1)
y2 = y(x2,u2,sig2)
y3 = y(x3,u3,sig3)
y4 = y(x4,u4,sig4)
plt.plot(x1, y1, "r-")
plt.plot(x2, y2, "g-")
plt.plot(x3, y3, "b-")
plt.plot(x4, y4, "m-")
plt.xticks(range(-6,16,2))
plt.show()参考资料:
1、《统计学习方法》(第二版)
2、《Pattern Recognition and Machine Learning》
点击阅读原文,查看博客园的文章。
END
推荐阅读
数学之美中盛赞的 Michael Collins 教授,他的NLP课程要不要收藏?
From Word Embeddings To Document Distances 阅读笔记
模型压缩实践系列之——bert-of-theseus,一个非常亲民的bert压缩方法
可解释性论文阅读笔记1-Tree Regularization
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLPer(id:ainlper),备注工作/研究方向+加群目的。