利用机器学习通过网页预提取技术加快网站加载速度


发布人:Minko Gechev、David Zats、Na Li、Ping Yu、Anusha Ramesh 和 Sandeep Gupta
页面加载时间是网站用户体验最重要的决定因素之一。研究表明,更短的网页加载时间会直接增加网页浏览量、转化率,提升客户满意度。零售超市 Newegg 在应用网页预提取技术优化页面加载体验之后,网页转化率增加了 50%。
研究
http://loadstorm.com/2014/04/infographic-web-performance-impacts-conversion-rates/
现在使用 TensorFlow 工具就能利用机器学习建立强大的解决方案,帮助网站缩短页面加载时间。在本篇文章中,我们将展示一种端到端的工作流,涉及从 Google Analytics 获取网站导航数据并加以利用,以及训练一种能预测用户下一步操作的自定义机器学习模型。您可以在 Angular 应用中利用这些预测,预提取候选页面,从而大幅改进网站的用户体验。在下图中通过并列对比的方式,将未优化的默认页面加载体验(左)与已应用基于机器学习的预测式、预提取技术,而大幅改进页面加载时间的情况(右)做了比较。这两个示例都是在模拟慢速 3G 网络上进行运行。

未优化页面和基于机器学习的页面在示例 Web 应用中的加载时间对比
该解决方案的简要示意图如下:

解决方案概览
我们利用 Google Cloud 服务(BigQuery 和 Dataflow)存储和预处理网站的 Google Analytics 数据,然后使用 TensorFlow Extended (TFX) 运行模型训练流水线来训练自定义模型,由此产生一个网站专属模型,再将其转换为可在网络上部署的 TensorFlow.js 格式。这个客户端模型将被加载到一个电子商店的示例 Angular Web 应用中,用来演示如何在 Web 应用中部署该模型。让我们来具体了解一下这些组件。


Google Analytics 将每个页面访问存储为一个事件,并为事件提供诸如页面名称、访问时间和加载时间等关键切面。该数据包含了我们训练模型所需的一切内容。我们需要:
1. 将该数据转换为包含特征和标签的训练示例。
2. 确保该数据可被 TFX 用于训练。
为完成第一步,我们将利用现有支持,把 Google Analytics 数据导出到一个名为“BigQuery ”的大规模云数据仓库中。为了完成第二步操作,我们会创建一个 Apache Beam 流水线,它可以:
Apache Beam 流水线
https://github.com/tensorflow/tfx/blob/master/tfx/examples/tfjs_next_page_prediction/bigquery_beam_data_generation.py
1. 从 BigQuery 读取数据
2. 排序和过滤会话中的事件
3. 检查每个会话、创建示例、将当前事件的属性作为示例的特征、将下一事件中的访问页面作为示例的标签
4. 将这些生成的示例存储到 Google Cloud Storage 中,以便 TFX 进行训练。
我们将在 Dataflow 中运行 Beam 流水线。
在以下表格中,每一行代表一个训练示例:
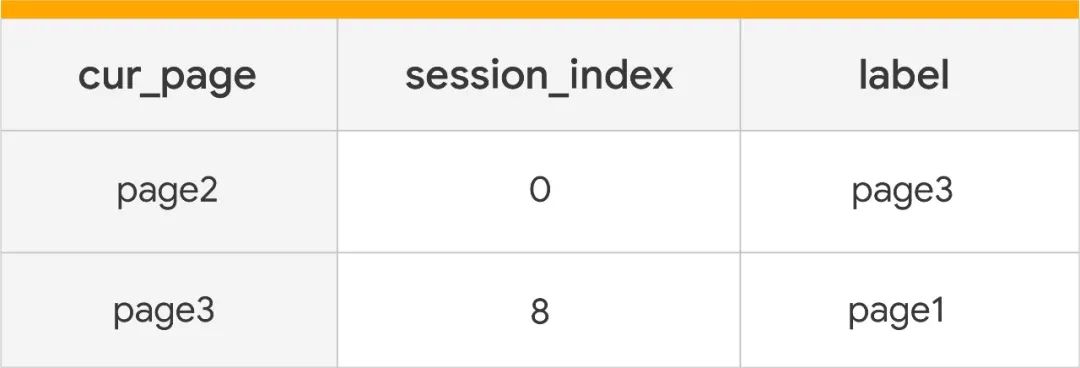
虽然本文中的训练示例只包含两个训练特征(cur_page 和 session_index),但我们可以方便地添加从 Google Analytics 获取更多特征来创建一个更丰富的数据集,并将其用于训练,从而创建更强大的模型。要想添加更多特征,可以扩展以下代码:
def ga_session_to_tensorflow_examples(session):
examples = []
for i in range(len(session)-1):
features = {‘cur_page’: [session[i][‘page’][‘pagePath’]],
‘label’: [session[i+1][‘page’][‘pagePath’]],
‘session_index’: [i],
# Add additional features here.
…
}
examples.append(create_tensorflow_example(features))
return examplesTensorFlow Extended (TFX) 是一个端到端的生产级机器学习平台,可用于数据验证、规模化训练(使用加速器)、评估和验证已生成模型等过程。
若要在 TFX 中创建模型,必须提供预处理函数和运行函数。预处理函数定义了在数据传递至主模型之前应对该数据执行的操作。这些操作包括完整地传递数据,例如创建 vocab。运行函数定义了主模型及其接受训练的方式。
我们的示例演示了如何实现 preprocessing_fn 函数和 run_fn 函数以定义和训练用于预测下一页面的模型。TFX 示例流水线则演示了如何针对众多其他关键用例实现这些函数。
流水线
https://github.com/tensorflow/tfx/tree/master/tfx/examples
完成自定义模型训练后,我们将在 Web 应用中部署该模型,这样在用户访问网站时,我们就可以利用它进行实时预测。要实现这一目的,可以使用 TensorFlow.js,它是 TensorFlow 的框架,用于直接在浏览器客户端运行机器学习模型。通过在浏览器客户端运行这段代码,可以减少与服务器端往返流量相关的延迟时间,降低服务器端费用,而且由于不必向服务器发送任何会话数据,也保护了用户的数据隐私。
TFX 运用模型重写库在训练好的 TensorFlow 模型和 TensorFlow.js 格式之间实现自动转换。作为这个库的一部分,我们已经实现了一个 TensorFlow.js 重写器。我们可以方便地在 run_fn 函数中调用该重写器来执行所需的转换。请参阅此示例了解更多详细信息。
模型重写库
https://github.com/tensorflow/tfx/blob/master/tfx/components/trainer/rewriting/README.md
重写器
https://github.com/tensorflow/tfx/blob/master/tfx/components/trainer/rewriting/tfjs_rewriter.py
示例
https://github.com/tensorflow/tfx/blob/master/tfx/examples/tfjs_next_page_prediction/tfjs_next_page_prediction_util.py
一旦准备好模型,我们就可以在 Angular 应用中使用它了。对于每次导航,我们会查询模型并预提取与未来可能被访问的页面相关的资源。
作为替代解决方案,也可以预提取与未来导航路径相关所有可能的资源,但这种做法需要更高的带宽消耗。利用机器学习,我们可以只预测下一步可能用到的页面,并减少假正例的数量。
根据应用的具体情况,可能需要预提取不同类型的资源,例如:JavaScript、图像或数据。在这个演示中,我们将预提取产品的图像。
这里面临的挑战在于:如何以一种高效的方式实现这一机制,同时又不影响应用加载时间或运行时性能。我们可以使用以下技术来降低性能倒退的风险:
延迟加载模型和 TensorFlow.js,避免阻塞初始页面加载时间
在主线程之外查询模型,这样就不会在主线程中掉帧,还能达到 60fps 的渲染体验
能同时满足以上两个约束条件的网络平台 API 就是 Service Worker。Service Worker 是一个脱离网页、由浏览器在后台的新线程中运行的脚本。它允许您接入请求周期,并为您提供缓存控制。
Service Worker
https://developers.google.com/web/fundamentals/primers/service-workers
当用户在应用中导航时,我们会向 Service Worker 发送消息,告知用户已经访问过哪些页面。根据导航历史记录,Service Worker 会对未来的导航进行预测,并预提取相关的产品资源。
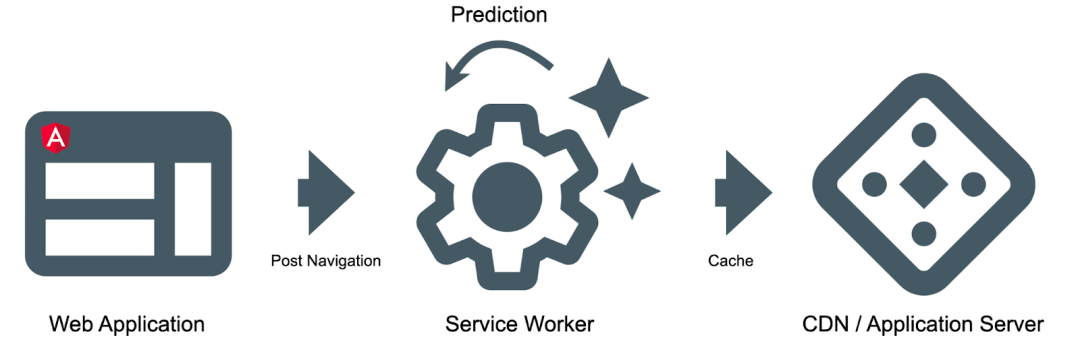
让我们来看看各个运行部分的简要概览。
我们可以从 Angular 应用的主文件中加载 Service Worker:
// main.ts
if ('serviceWorker' in navigator) {
navigator.serviceWorker.register('/prefetch.worker.js', { scope: '/' });
}以上代码片段将下载 prefetch.worker.js 脚本并在后台运行该脚本。下一步,我们要将导航事件发送到 Service Worker:
// app.component.ts
this.route.params.subscribe((routeParams) => {
if (this._serviceWorker) {
this._serviceWorker.postMessage({ page: routeParams.category });
}
});在以上代码片段中,需要注意网址参数的变更。在变更时,我们将页面类别发送到 Service Worker。
在 Service Worker 的实现过程中,我们需要处理来自主线程的消息,根据这些消息做出预测,然后预提取相关的信息。简要过程如以下代码所示:
// prefetch.worker.js
addEventListener('message', ({ data }) => prefetch(data.page));
const prefetch = async (path) => {
const predictions = await predict(path);
const cache = await caches.open(ImageCache);
predictions.forEach(async ([probability, category]) => {
const products = (await getProductList(category)).map(getUrl);
[...new Set(products)].forEach(url => {
const request = new Request(url, {
mode: 'no-cors',
});
fetch(request).then(response => cache.put(request, response));
});
});
};我们要在 Service Worker 中监听来自主线程的消息。接收到消息后,则触发逻辑响应,进行预测和预提取信息。
首先在预提取函数中预测:哪些是用户接下来可能会访问的页面。然后,对所有预测进行迭代并提取相应资源,用于提升后续导航的用户体验。
如果想了解详细信息,可以关注 TensorFlow.js 示例代码库中的示例应用。
示例代码库
https://github.com/tensorflow/tfjs-examples
您可以查看模型训练代码示例,该示例展示了 TFX 流水线和 Apache Beam 流水线,前者用于训练页面预提取模型,后者用于将 Google Analytics(分析)数据转换为训练示例;还可以查看部署示例,了解如何在 Angular 示例应用中部署 TensorFlow.js 模型用于客户端预测。
模型训练代码示例
https://github.com/tensorflow/tfx/tree/master/tfx/examples/tfjs_next_page_prediction
部署示例
https://github.com/tensorflow/tfjs-examples/tree/master/angular-predictive-prefetching
该项目的成功离不开 Becky Chan、Deepak Aujla、Fei Dong 和 Jason Mayes 的巨大努力和有力支持,在此深表感谢。

点击“阅读原文”访问 TensorFlow 官网

不要忘记“一键三连”哦~

分享

点赞

在看





