通过优化 S3 读取来提高效率和减少运行时间

本文将介绍一种提升 S3 读取吞吐量的新方法,我们使用这种方法提高了生产作业的效率。结果非常令人鼓舞。单独的基准测试显示,S3 读取吞吐量提高了 12 倍(从 21MB/s 提高到 269MB/s)。吞吐量提高可以缩短生产作业的运行时间。这样一来,我们的 vcore-hours 减少了 22%,memory-hours 减少了 23%,典型生产作业的运行时间也有类似的下降。
虽然我们对结果很满意,但我们将来还会继续探索其他的改进方式。文末会有一个简短的说明。
我们每天要处理保存在 Amazon S3 上的数以 PB 计的数据。如果我们看下 MapReduce/Cascading/Scalding 作业的相关指标就很容易发现:mapper 速度远低于预期。在大多数情况下,我们观测到的 mapper 速度大约是 5-7MB/s。这样的速度要比 aws s3 cp 这类命令的吞吐量慢几个数量级,后者的速度达到 200+MB/s 都很常见(在 EC2 c5.4xlarge 实例上的观测结果)。如果我们可以提高作业读取数据的速度,那么作业就可以更快的完成,为我们节省相当多的处理时间和金钱。鉴于处理成本很高,节省的时间和金钱可以迅速增加到一个可观的数量。
如果我们看下 S3AInputStream 的实现,很容易就可以看出,以下几个方面可以做些改进:
单线程读:数据是在单线程中同步读取的,导致作业把大量时间花在通过网络读取数据上。
多次非必要重新打开:S3 输入流是不可寻址的。每次执行寻址或是遇到读取错误时,总是要重复打开“分割(split)”。分割越大,出现这种情况的可能性越高。每次重新打开都会进一步降低总体的吞吐量。
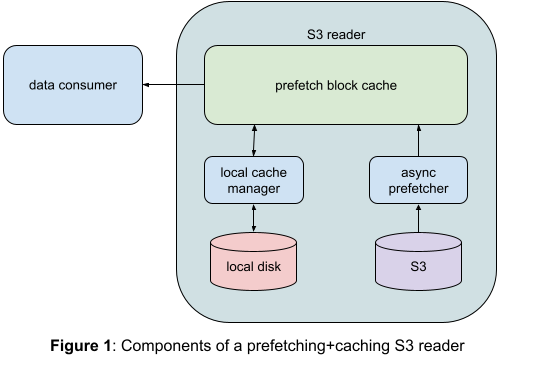
图 1:S3 读取器的预取 + 缓存组件 *
为了解决上述问题,我们采取了以下措施:
我们将分割视为是由固定大小的块组成的。默认大小是 8MB,但可配置。
每个块在异步读取到内存后,调用者才能访问。预取缓存的大小(块的数量)是可配置的。
调用者只能读取已经预取到内存中的块。这样客户端可以免受网络异常的影响,而我们也可以有一个额外的重试层来增加整体弹性。
每当遇到在当前块之外寻址的情况时,我们会在本地文件系统中缓存预取的块。
我们进一步增强了这个实现,让生产者 - 消费者交互几乎不会出现锁。根据一项单独的基准测试(详情见图 2),这项增强将读吞吐量从 20MB/s 提高到了 269MB/s。
任何按照顺序处理数据的消费者(如 mapper)都可以从这个方法中获得很大的好处。虽然 mapper 处理的是当前检索出来的数据,但序列中接下来的数据已经异步预取。在大多数情况下,在 mapper 准备好处理下一个数据块时,数据就已经预取完成。这样一来,mapper 就把更多的时间花在了有用的工作上,等待的时间减少了,CPU 利用率因此增加了。
Parquet 文件需要非顺序读取,这是由它们的磁盘格式决定的。我们最初实现的时候没有使用本地缓存。每当遇到在当前块之外寻址的情况时,我们就得抛弃预取的数据。在读取 Parquet 文件时,这比通常的读取器性能还要差。
在引入预取数据的本地缓存后,我们发现 Parquet 文件读取吞吐量有明显的提升。目前,与通常的读取器相比,我们的实现将 Parquet 文件读取吞吐量提升了 5 倍。
读取吞吐量的增加给生产作业带来了多方面的提升。
作业的总体运行时间减少了,因为 mapper 等待数据的时间减少了,可以更快地完成。
如果 mapper 耗时大大减少,那么我们就可以通过增加分割大小来减少 mapper 数量。Mapper 数量的减少可以减少由固定 mapper 开销所导致的 CPU 浪费。更重要的是,这样做并不会增加作业的运行时间。
由于 mapper 完成同样的工作所花费的时间减少,所以 CPU 整体的利用率会提高。
现在,我们的实现(S3E)使用了一个单独的存储库,提高了我们的迭代改进速度。最终,我们会将其合并到 S3A,把它回馈给社区。
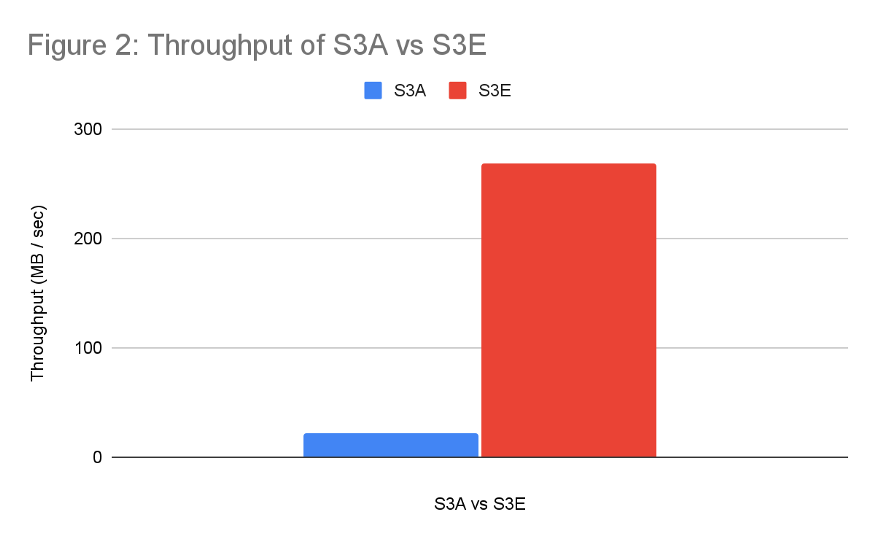
图 2:S3A 和 S3E 的吞吐量对比 *
在每种情况下,我们都是顺序读取一个 3.5GB 的 S3 文件,并将其写入本地的一个临时文件。后半部分是为了模拟 mapper 操作期间发生的 IO 重叠。基准测试是在 EC2 c5.9xlarge 实例上进行的。我们测量了读取文件的总时间,并计算每种方法的有效吞吐量。
我们在许多大型生产作业中测试了 S3E 实现。这些作业每次运行时通常都要使用数以万计的 vcore。图 3 是对比了启用 S3E 和不启用 S3E 时获得的指标。
我们使用以下方法度量这项优化所带来的资源节省情况。


图 3:MapReduce 作业资源消耗对比 *
虽然不同的生产作业工作负载有不同的特征,但我们看到,在 30 个成本高昂的作业中,大部分的 vcore 都减少了 6% 到 45%。
我们的方法有一个吸引人的地方,就是在一个作业中启用时不需要对作业的代码做任何修改。
目前,我们把这个增强实现放在了一个单独的 Git 存储库中。将来,我们可能会升级已有的 S3A 实现,并把它回馈给社区。
我们正在把这项优化推广到我们的多个集群中,结果将发表在以后的博文上。
鉴于 S3E 输入流的核心实现不依赖于任何 Hadoop 代码,我们可以在其他任何需要大量访问 S3 数据的系统中使用它。目前,我们把这项优化用在 MapReduce、Cascading 和 Scalding 作业中。不过,经过初步评估,将其应用于 Spark 和 Spark SQL 的结果也非常令人鼓舞。
当前的实现可以通过进一步优化来提高效率。同样值得探索的是,是否可以使用过去的执行数据来优化每个作业的块大小和预取缓存大小。
原文链接:https://medium.com/pinterest-engineering/improving-efficiency-and-reducing-runtime-using-s3-read-optimization-b31da4b60fa0
点击底部阅读原文访问 InfoQ 官网,获取更多精彩内容!
独家对话英特尔CTO Greg:让创新成为主流,英特尔将始终拥抱开发者
六年目睹企业间内卷怪现状:爬虫与反爬之战
腾讯员工入职满15年可提前退休;双11天猫总交易额5403亿元,京东超3491亿元;中芯国际重大人事震荡 | Q资讯
从软件历史看架构的未来:编程不再是精英们的游戏

点个在看少个 bug 👇





