论文浅尝 | 基于知识图谱难度可控的多跳问题生成
论文笔记整理:谭亦鸣,东南大学博士生,研究兴趣:知识图谱问答。

来源:ISWC 2019
链接:https://link.springer.com/content/pdf/10.1007%2F978-3-030-30793-6_22.pdf
本文提出一个end2end神经网络模型以知识图谱为数据源,自动生成复杂的多跳问题,且问题难度是可控的。该模型以一个子图(来自知识图谱)及预设的问题答案为输入,利用基于transformer的模型生成自然语言问题。问题难度的控制因子基于命名实体的popularity指标构建得到。实验方面,利用现有的两个2-hops问答数据集,构建训练/测试数据得到的实验结果验证了该模型可以生成高质量,流利,且与输入子图密切相关的自然语言问题。
相关数据集和源码链接传送门:https://github.com/liyuanfang/mhqg.
动机
目前最好的KG QA模型基于神经网络建立,这种数据驱动的模型需要大量的训练数据,包括知识图谱中的三元组集,问题集以及对应的答案数据。为了迎合这种数据需求,近些年来,很多问答数据集被构建出来,包括简单的Single-hop信息的问题,以及更复杂信息的问题。其中复杂问题数据集又大体可以分为两类:多跳推理或者离散型推理问题。
但是,随着上述数据集被充分利用之后,模型性能的进一步提升又受到了数据集规模的限制,虽然这对Single-hop问答没什么影响,其性能在实验数据上已经媲美人类问答水平(Single-hop问题难度并不高),对于复杂问题则不然,其依然需要更多高质量的问答数据集提升模型的质量。显然复杂问题相对简单问题数据的建立难度更高,大部分现有的复杂问题都是基于人工或半自动的方式得到。
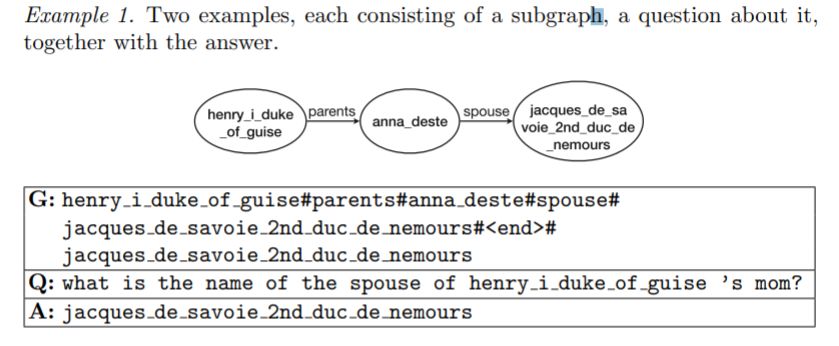
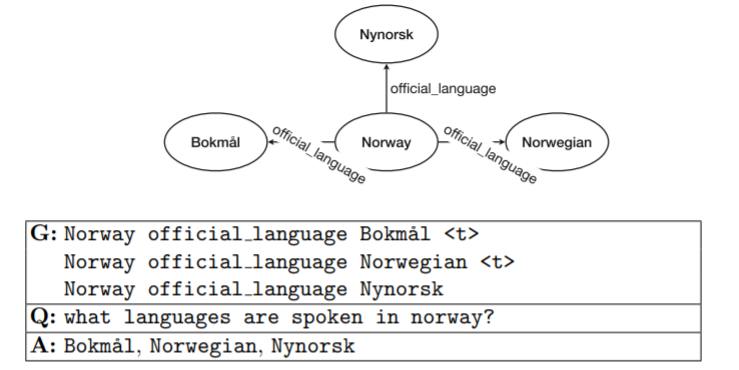
因此本文拟利用现有的复杂问题集作为训练数据(包含问题子图,对应的自然语言问题reference以及答案,来自COMPLEXWEBQUESTIONS及PathQuestion数据集),例1描述了这些数据的形式:
方法
本文将基于知识图谱的问题生成任务看作一个Seq2Seq学习问题:
假定背景知识(图谱)为G,其中包含一系列三元组事实,给定一个子图g(来自G),及n个三元组,EA表示三元组中的答案实体(可能不唯一,建例1的第二张图),模型将会生成一个自然语言问题Q = (w1,…,wm),生成过程可以描述如下:
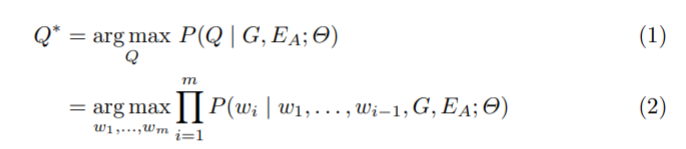
θ表示模型参数
模型的框架如下图所示:
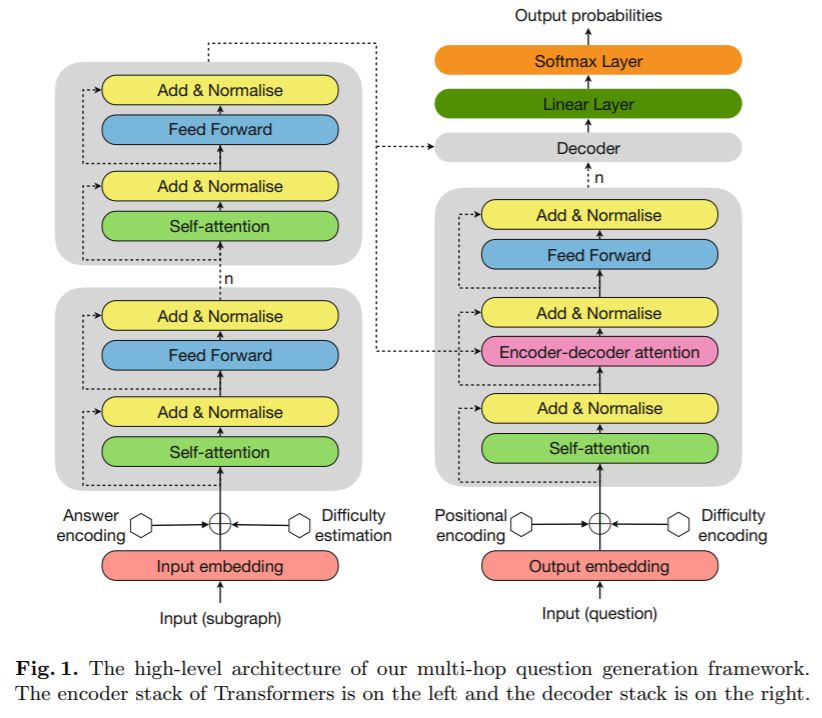
这个框架整体还是类Transformer结构,主体分为编码和解码两个部分,相关网络细节就不多赘述。
关于知识图谱编码
对于子图g,编码器以其embedding作为输入(对g中的三元组做embedding),令d_e表示实体/关系的embedding维度,d_g 表示三元组embedding的维度
初始化阶段,三元组的embedding由主体,谓词,客体的embedding拼接,加之其余值随机初始化以匹配三元组的embedding维度
每个E_A答案实体还被embedding到一个d_e维的向量中,通过一个多层感知机学习该实体是否是一个答案实体。
接着对答案embedding和原始实体embedding做元素加法以获得最终对每个答案实体的embedding
因此,对于包含n个三元组的子图g,可以表示为一个n×d_g矩阵G,以该矩阵为输入,Transformer 编码器将其映射为一个连续表示序列Z = (z1,…,zn)∈R^{n×dg}
令Q,K,V分别表示编码器中的query,key和value矩阵,给定输入G,使用query矩阵对相关的三元组做软筛选(soft select)并积累Attention,公式如下:
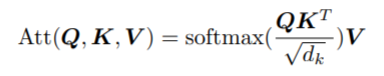
其中,KT为K的转置 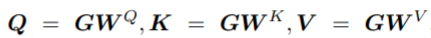
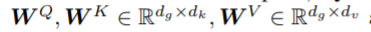
为了获得不同三元组在不同表示子空间的信息,作者使用包含k个head的Multi-head attention,并汇总它们如下:
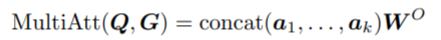
其中, 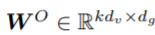
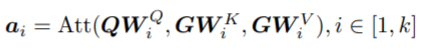
汇总后的输出x被传递到一个前馈网络,如下:
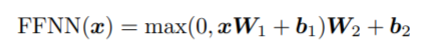
关于难度评价模型
本文主要提到了两个衡量难度的因素:问题中实体链接的confidence;子图中实体的selectivity
前者指的是对问题做命名实体识别时,具有较高confidence的实体识别一般具有较小的ambiguity,这使得子图很容易理解所问的目标实体,且生成的问题也更易于回答。
后者指的是识别完实体后图谱中可匹配的实体的候选数量,当候选实体较多时,意味具有更低的selectivity,这表示问题所问的内容具有较高的模糊性,也就更难。
基于此,作者构建了难度评价模型如下:
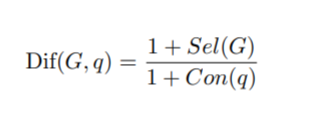
其中G和q分别表示子图和问题,Con表示confidence,Sel表示selectivity,该难度得分被标准化到[0,1]之间。考虑单靠得分不具备明确的区分度,比如想生成较难的问题该怎么定义阈值,因此作者随机抽取了200个简单例子做难度测量,最终取其得到的最高值作为阈值。
关于带有难度控制因子的解码
本文利用一个多层感知机DE将难度信息编码进解码器,其由输入线性层,整流线性单元层和输出线性层构成。公式如下:
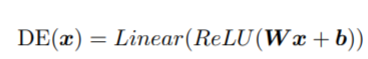
其中,x表示难度level,W和b是可训练的模型参数。
实验
数据集相关
实验使用到了三个多跳问题集:
WebQuestionsSP,ComplexWebQuestions,PathQuestion
对于每个实例,WebQuestionsSP,ComplexWebQuestions都包含自然语言问题,SPARQ query及答案实体和一些辅助信息
PathQuestion相对上述数据集缺少了实体对应知识库(Freebase)的ID,因此处理方式稍有不同。
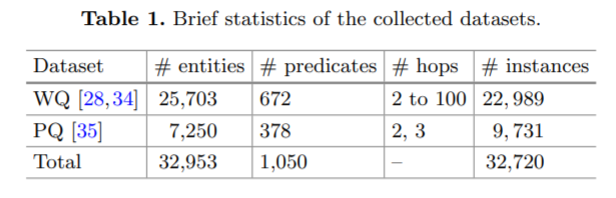
数据集统计信息如下表:
作者对其实验细节在文章中做了详细描述,有需要可以去瞅瞅
实验结果
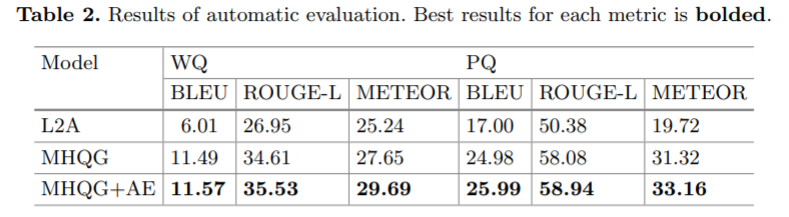
由于是自然语言生成类的任务,这里使用的评价指标均为翻译常用的自动评价指标BLEU,METEOR等
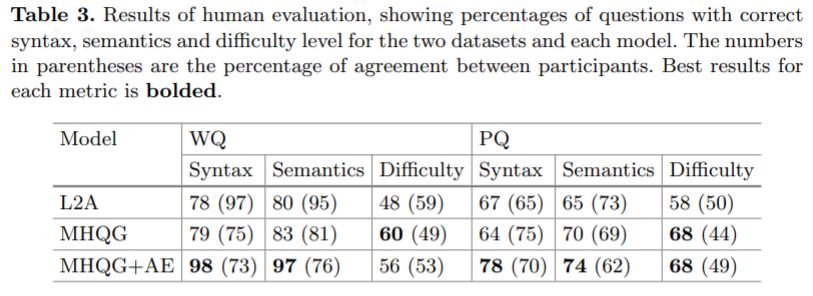
同时,作者也提供了人工评价结果如下:
OpenKG
开放知识图谱(简称 OpenKG)旨在促进中文知识图谱数据的开放与互联,促进知识图谱和语义技术的普及和广泛应用。

点击阅读原文,进入 OpenKG 博客。




