ICLR 2020 | 图表示的预训练策略

©PaperWeekly 原创 · 作者|张笑
单位|成都数联铭品
研究方向|图表示和知识挖掘

背景
在图像和自然语言处理领域,预训练和微调的模式取得较大成功,图表示模型的预训练方法还在起步阶段,其不仅需要增加前置的任务,同时还需要专业知识选择出与下游任务相关性强的样本和任务,再进行训练。否则很有可能出现反效果(类比于原始 BERT,NSP 任务实质上效果有限)。

动机
这篇论文考察的是生物化学领域,再具体点是分子结构和蛋白质结构。分子、蛋白质较容易获得独立的结构,同时它们都是限个小元素的排列组合而成,并且每个子结构的研究也比较丰富,比如元素周期表,化学键,蛋白质的多肽结构,子结构的初级功能也有一定的研究(分子的性质,合成分子性质的假设实验,蛋白质控制细胞凋亡和增殖等),有较丰富的整图级的预训练任务。
需要说明的是,本文的样本是多个独立的小结构,不同于社交网络或者用户-商品这类图谱(连通网络非常大)。所以对后者,仍然需要重新设计抽取小结构以及设置小结构任务的方案。针对这篇文章,下文将 graph-level 称为整图级。
本文主要工作在设计节点级别的预训练方案,补充整图级别预训练策略;实验发现,两类策略分开进行预训练,对下游任务的提升有限,甚至有时会起到反效果。
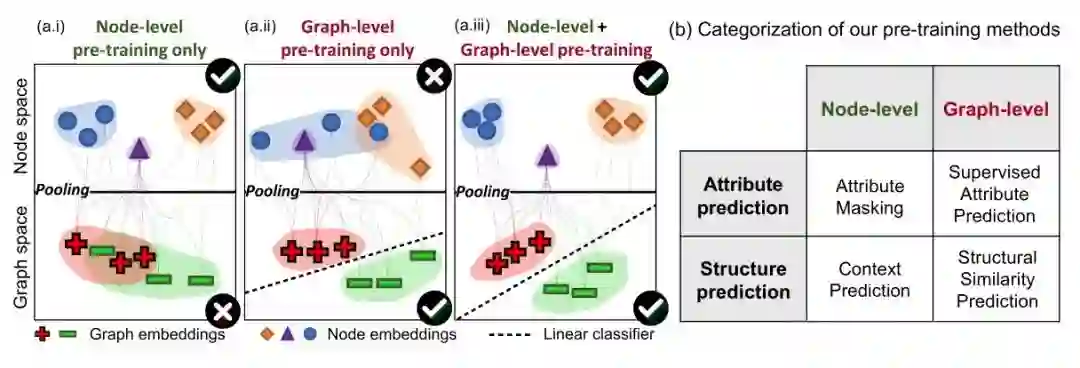

框架
3.1 准备知识
图上的监督学习:令图 







GNNs:对每个节点,记为目标节点 v,通过聚合 v 的所有邻居节点和相应的边的表示,迭代生成 v 的表示向量。
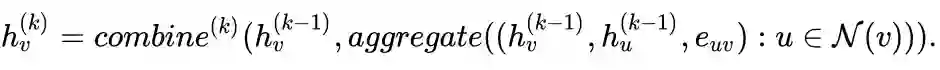
其中 


图表示学习:为了得到全图 G 的表示向量
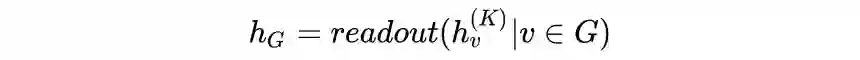
3.2 图神经网络预训练策略
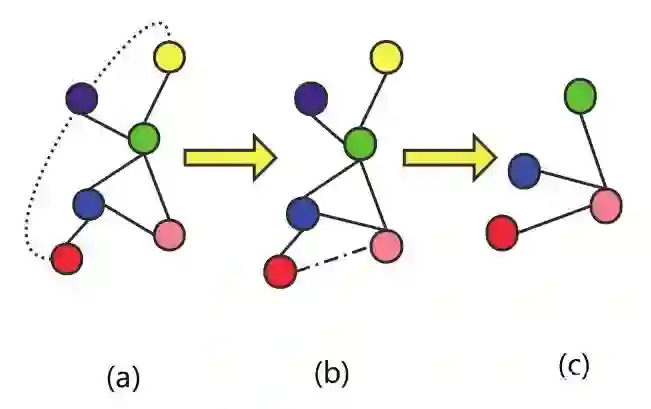
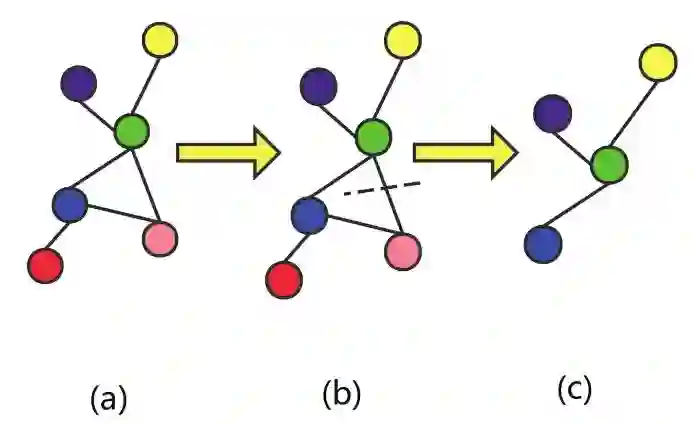
3.2.1 节点级预训练:使用无标签的数据,自监督学习特定领域的知识/规则,包括上下文预测和属性遮掩
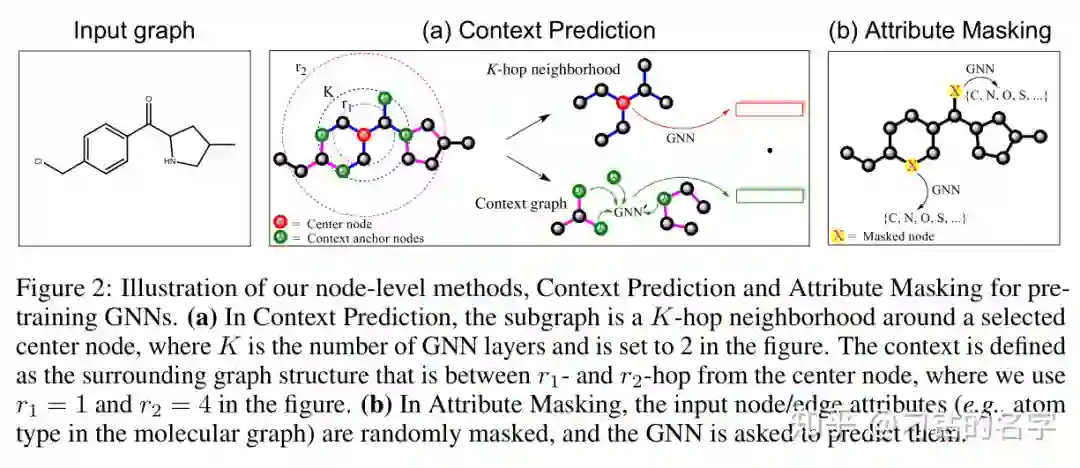
 到
到
 hop之间的部分作为上下文。具体构造应该是
hop之间的部分作为上下文。具体构造应该是
 网络除去
网络除去
 网络部分。选择
网络部分。选择
 ,则邻居和上下文存在重叠部分,称为上下文锚定节点,见 figure 2(a) 中绿色节点。
,则邻居和上下文存在重叠部分,称为上下文锚定节点,见 figure 2(a) 中绿色节点。
 . 上下文预测的目标是一个二分类问题,即一个特定的邻居和一个特定的上下文编码是否属于同一个节点,采用 negative sampling 方式进行训练:
. 上下文预测的目标是一个二分类问题,即一个特定的邻居和一个特定的上下文编码是否属于同一个节点,采用 negative sampling 方式进行训练:
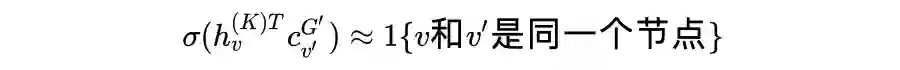 直接用于下游预测任务的微调,因此希望直接将特定领域信息编码进
中。对于分子和蛋白质,有比较多的已观测的属性,且它们组成的结构和相应的规则比较固定。所以整图级的预训练任务非常多,于是整图级的性质预测问题,即是一个多任务分类问题。
直接用于下游预测任务的微调,因此希望直接将特定领域信息编码进
中。对于分子和蛋白质,有比较多的已观测的属性,且它们组成的结构和相应的规则比较固定。所以整图级的预训练任务非常多,于是整图级的性质预测问题,即是一个多任务分类问题。

思考
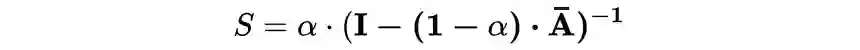
 , A 是邻接矩阵,D 是对角阵,元素为 A 的每行的和
, A 是邻接矩阵,D 是对角阵,元素为 A 的每行的和
 . 此时 S(i,j) 表示第 i 个节点对 j 节点的亲密分。设置两个参数
. 此时 S(i,j) 表示第 i 个节点对 j 节点的亲密分。设置两个参数
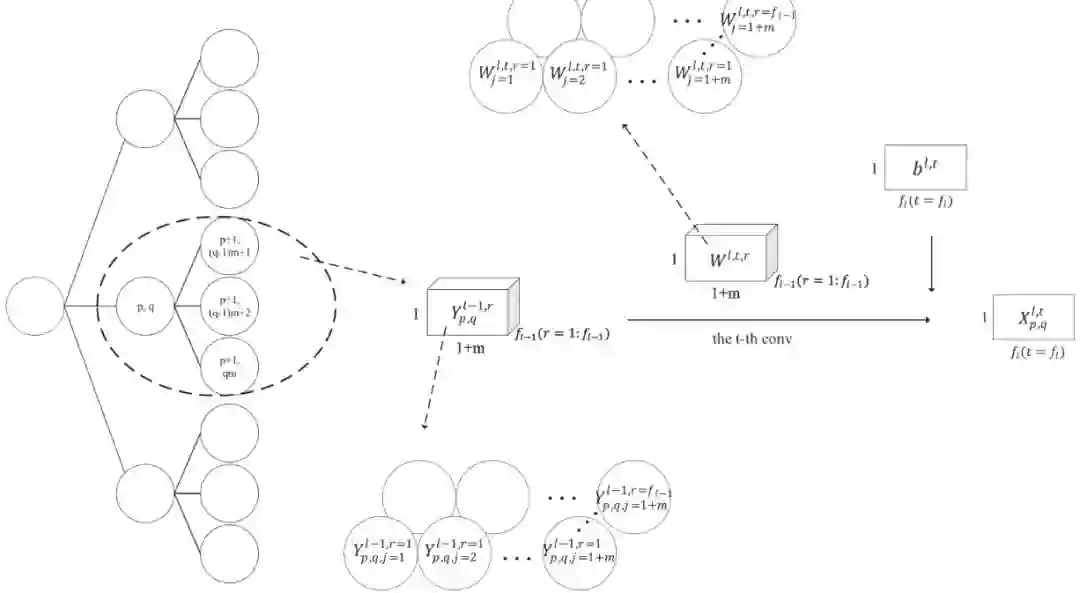
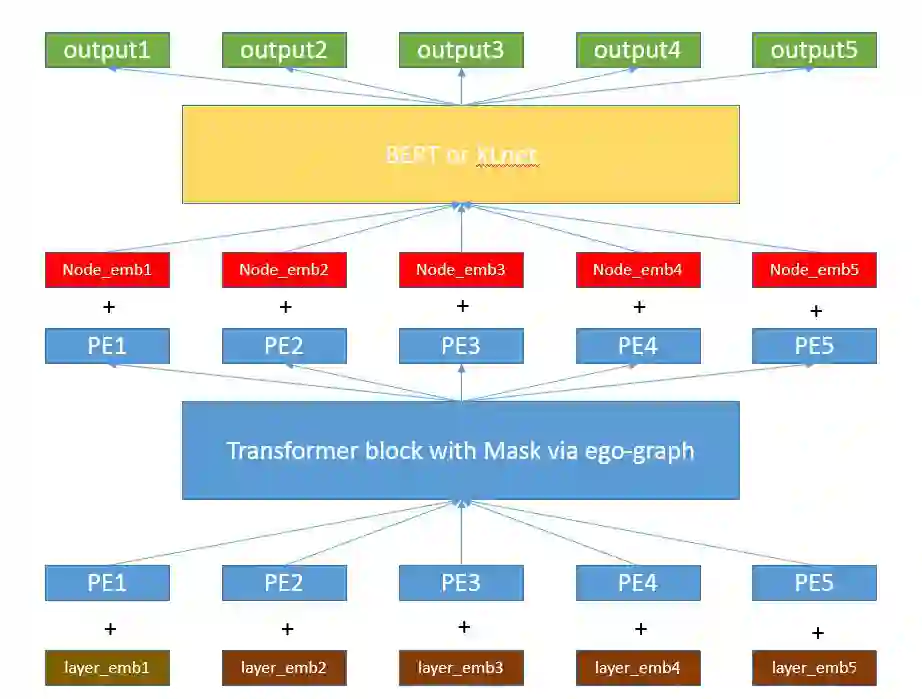
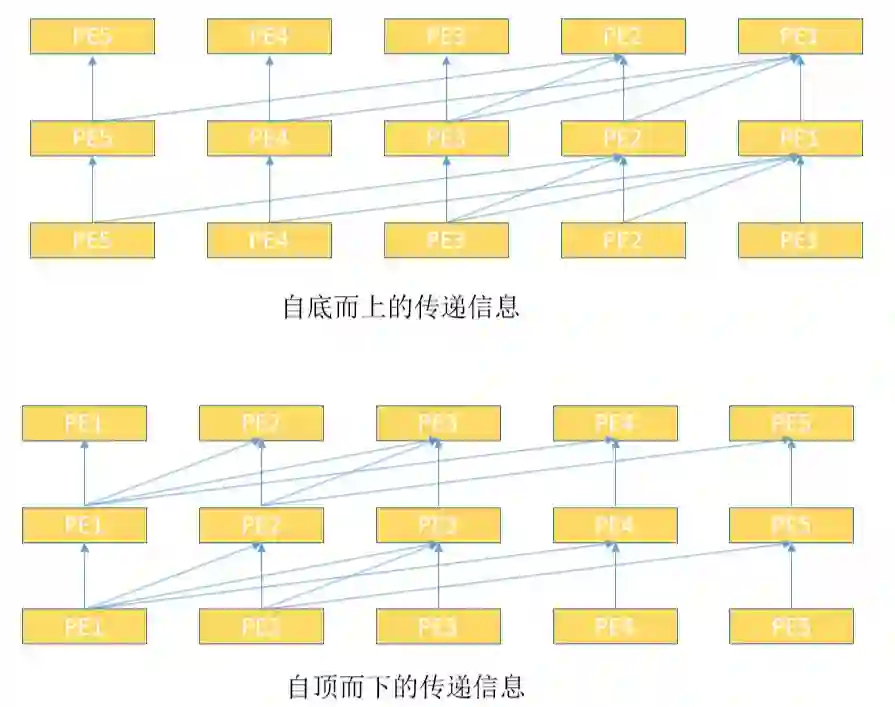
 和 t,分别表示亲密分数的下限和选取最大的 t 个节点作为邻居(邻居数长短不一),以此得到 i 节点的上下文节点序列,随后采用 transformer 进行建模。注意,与第一种方法不同的是,这里存在一些节点,满足条件的邻居个数少于 t 个,但不需要进行补齐。
和 t,分别表示亲密分数的下限和选取最大的 t 个节点作为邻居(邻居数长短不一),以此得到 i 节点的上下文节点序列,随后采用 transformer 进行建模。注意,与第一种方法不同的是,这里存在一些节点,满足条件的邻居个数少于 t 个,但不需要进行补齐。
def generate_auxiliary_link_set(G, sorted_nodes_set)
auxiliary_link_set = []
for k, node in enumerate(sorted_nodes_set):
neighbor_of_nodes = G.neighbor(node)
tmp = []
for neighbor_of_node in neighbor_of_nodes:
idx = sorted_nodes_set.index(neighbor_of_node)
if idx < k:
tmp.append(idx)
auxiliary_link_set.append([tmp, len(neightbor)-len(tmp)])
return auxilary_link_set


参考文献
[1] Strateyies For Pre-training Graph Neural Networks
[2] Graph-BERT : Only Attention is Needed for Learning Graph Representations
[3] Multi-Stage Self-Supervised Learning for Graph Convolutional Networks
[4] GResNet : Graph Resdual Network For Reviving Deep GNNS From Suspened Animation
[5] Depth-based subgraph convolutional auto-encoder for network representation learning
更多阅读




#投 稿 通 道#
让你的论文被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学习心得或技术干货。我们的目的只有一个,让知识真正流动起来。
📝 来稿标准:
• 稿件确系个人原创作品,来稿需注明作者个人信息(姓名+学校/工作单位+学历/职位+研究方向)
• 如果文章并非首发,请在投稿时提醒并附上所有已发布链接
• PaperWeekly 默认每篇文章都是首发,均会添加“原创”标志
📬 投稿邮箱:
• 投稿邮箱:hr@paperweekly.site
• 所有文章配图,请单独在附件中发送
• 请留下即时联系方式(微信或手机),以便我们在编辑发布时和作者沟通
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。




