关于中文预训练模型泛化能力挑战赛的调研
-
多任务学习 -
多任务学习动机 -
为什么有效? -
模型结构 -
硬共享模式 -
软共享模式 -
共享-私有模式 -
loss优化 -
比赛项目分析 -
赛题背景 -
数据说明 -
评测标准 -
示例教程 -
优化方向 -
参考
多任务学习
多任务学习(Multi-Task Learning/MTL),有时候也称为:联合学习( joint learning)、自主学习(learning to learn)、辅助任务学习(learning with auxiliary tasks )。大多数机器学习模型都是独立对一个任务进行学习的,而多任务学习则是将多个相关任务放在一起进行学习。从损失函数角度来说,只要优化的是多个损失函数,则就是在进行多任务学习。多任务学习的目标是,通过利用相关任务的训练信号中包含的特定领域信息来提高泛化能力。当前多任务学习的研究,主要集中在两个方面:模型结构和loss优化。对比于单任务学习,多任务学习有不少优点,下面从多任务学习的动机和有效性来进行阐述。
多任务学习动机
-
从生物学上讲,可以把MTL看作是受到人类学习的启发,在学习新任务时,人类通常会使用在其他相关任务上学来的知识。 -
MTL避免重复计算共享层中的特征,既减少了内存的占用,也大大提高了推断速度。 -
单任务学习每个特定任务都需要大量带标签数据,MTL提供了一种有效的方法,来利用相关任务的监督数据。 -
多任务学习通过缓解对某一任务的多度拟合而获得正则化效果,从而使所学的表征在任务间具有通用性。
为什么有效?
-
每一个任务数据都有噪音,模型只学习一个任务容易在该任务上过拟合,而学习多个任务可以使模型通过平均噪声的方式获得更好的表示。 -
如果一个任务非常嘈杂,或者数据有限且高维,那么模型将很难区分相关和不相关的特征。MTL可以帮助模型将注意力集中在那些真正重要的特性上,因为其他任务将为这些特性的相关性或不相关性提供额外的证据。 -
对某个任务B来说,特征G比较容易学到,但对另外的任务A则比较难学到。可能因为任务A与特征G的交互比较复杂,或者其他特征阻碍了模型学习特征G的能力。这个时候,使用MTL,可以通过任务B来学习到特征G。 -
MTL使模型偏向于所有任务都偏向的特征,这有助于推广到新的任务,因为特征在足够多的训练任务中表现良好,也会在新任务上表现良好,只要它们来自相同的环境。 -
MTL通过引入归纳偏差来当做正则化,降低过拟合风险。
模型结构
如下图所示,深度学习中的多任务学习模型结构主要分为三种:硬共享模式、软共享模式和共享-私有模式。
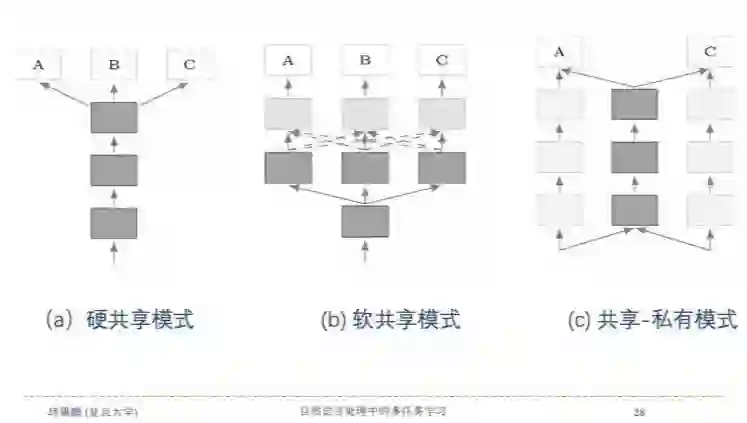
硬共享模式
从1993年开始,硬参数共享就是神经网络MTL中最常用的方法。如上图a所示,它通常在所有任务之间共享隐藏层,同时保留几个特定任务的输出层。硬参数共享可以大大降低了过拟合的风险。
软共享模式
如上图b所示,在软共享模式中,每个任务都有自己的模型和参数,对模型参数之间的距离进行正则化,从而使参数趋于相似。
共享-私有模式
如上图c所示,共享-私有模式,通过设置外部记忆共享机制来实现在所有任务上的信息共享。该模式有个优点,可以避免在共享路径上传递负迁移的信息,这些信息对另外的任务有损害。
loss优化
以最经典的硬共享模式为例,来分析下多任务学习的loss,最简单的方式就是多个任务的loss直接相加,就得到整体的loss,那么loss函数为:
其中
表示第i个任务的loss。
这种方式非常简单,但不合理之处也比较明显,不同的任务loss的量级不同,这可能导致多任务的学习被某个任务所主导或学偏。所以我们对loss函数进行简单的调整,为每一个任务的loss添加一个权重参数,则整体loss函数变为:
其中
表示第i个任务的权重。
相对于loss直接相加的方法,这种方式可以让我们调整每个任务的重要性程度,但仍然存在一些问题,因为不同的任务学习的难易程度不同,且不同的任务处于的学习阶段不同,比如某个任务接近收敛,而某个任务还没训练好,这样固定的权重就会限制任务的学习。所以在多任务学习中,还可以使用动态的加权方式,loss的权重会根据任务的学习阶段、学习的难易程度甚至是学习的效果来进行调整,这时,整体loss函数变为:
表示第t步时,任务i的权重值,关于动态权重的选择方式,可以参考以下方式:
Gradient Normalization——梯度标准化【Gradnorm: Gradient normalization for adaptive loss balancing in deep multitask networks】 Dynamic Weight Averaging ——动态加权平均【End-to-End Multi-Task Learning with Attention】 Dynamic Task Prioritization ——动态任务优先级【Dynamic task prioritization for multitask learning】 Uncertainty Weighting——不确定性加权【Multi-task learning using uncertainty to weigh losses for scene geometry and semantics】
当然除此之外,还有研究人员将MTL视为多目标优化问题,总体目标是在所有任务中找到一个帕累托最优解,具体可参考论文【Multiple-gradient descent algorithm (mgda) for multiobjective optimization】。
比赛项目分析
赛题背景
本次比赛是CLUE与阿里云平台、乐言科技联合发起的第一场针对中文预训练模型泛化能力的挑战赛。
赛题以自然语言处理为背景,要求选手通过算法实现泛化能力强的中文预训练模型。通过这道赛题可以引导大家更好地理解预训练模型的运作机制,探索深层次的模型构建和模型训练,而不仅仅是针对特定任务进行简单微调。
比赛地址,点击文末阅读原文直达:
https://tianchi.aliyun.com/competition/entrance/531841/introduction
数据说明
本赛题精选了以下3个具有代表性的任务(更多数据可查看CLUE官网),要求选手提交的模型能够同时预测每个任务对应的标签:
OCNLI,是第一个非翻译的、使用原生汉语的大型中文自然语言推理数据集; OCEMOTION,是包含7个分类的细粒度情感性分析数据集; TNEWS,来源于今日头条的新闻版块,共包含15个类别的新闻;
任务1: OCNLI--中文原版自然语言推理
0 一月份跟二月份肯定有一个月份有. 肯定有一个月份有 0
1 一月份跟二月份肯定有一个月份有. 一月份有 1
2 一月份跟二月份肯定有一个月份有. 一月二月都没有 2
3 一点来钟时,张永红却来了 一点多钟,张永红来了 0
4 不讲社会效果,信口开河,对任何事情都随意发议论,甚至信谣传谣,以讹传讹,那是会涣散队伍、贻误事业的 以讹传讹是有害的 0
(注:id 句子1 句子2 标签)
任务2: OCEMOTION--中文情感分类
0 你知道多伦多附近有什么吗?哈哈有破布耶...真的书上写的你听哦...你家那块破布是世界上最大的破布,哈哈,骗你的啦它是说尼加拉瓜瀑布是世界上最大的瀑布啦...哈哈哈''爸爸,她的头发耶!我们大扫除椅子都要翻上来我看到木头缝里有头发...一定是xx以前夹到的,你说是不是?[生病] sadness
1 平安夜,圣诞节,都过了,我很难过,和妈妈吵了两天,以死相逼才终止战争,现在还处于冷战中。sadness
2 我只是自私了一点,做自己想做的事情! sadness
3 让感动的不仅仅是雨过天晴,还有泪水流下来的迷人眼神。happiness
4 好日子 happiness
(注:id 句子 标签)
任务3:TNEWS--今日头条新闻标题分类
0 上课时学生手机响个不停,老师一怒之下把手机摔了,家长拿发票让老师赔,大家怎么看待这种事? 108
1 商赢环球股份有限公司关于延期回复上海证券交易所对公司2017年年度报告的事后审核问询函的公告 104
2 通过中介公司买了二手房,首付都付了,现在卖家不想卖了。怎么处理? 106
3 2018年去俄罗斯看世界杯得花多少钱? 112
4 剃须刀的个性革新,雷明登天猫定制版新品首发 109
(注:id 句子 标签)
评测标准
依照参赛选手提交的模型,求出每个任务的macro f1,然后在四个任务上取平均值,macro f1具体计算公式请参考sklearn上的定义:https://scikit-learn.org/stable/modules/generated/sklearn.metrics.f1_score.html#sklearn.metrics.f1_score
示例教程
官方示例教程具体可参考:https://github.com/wellinxu/EasyTransfer/tree/master/scripts/天池大赛专区
其模型结构采用的是硬共享模式,使用bert等预训练模型对各个任务进行特征提取,作为共享层,以pooled层的结果作为共享层的输出,然后对每个任务接一层全连接进行预测,模型结构如下图所示:
使用easytransfer可以方便的使用各种预训练模型,并构建MTL模型结构,如要构建上述模型结构,可参考以下简单代码(详细代码,点击上面官方链接):

def build_logits(self, features, mode=None):
# 特征处理类
preprocessor = preprocessors.get_preprocessor(self.pretrain_model_name_or_path)
# 获取模型,定义共享层
model = model_zoo.get_pretrained_model(self.pretrain_model_name_or_path)
# 定义各个任务输出层
tnews_dense = layers.Dense(15, kernel_initializer=layers.get_initializer(0.02), name='tnews_dense')
ocemotion_dense = layers.Dense(7, kernel_initializer=layers.get_initializer(0.02), name='ocemotion_dense')
ocnli_dense = layers.Dense(3, kernel_initializer=layers.get_initializer(0.02), name='ocnli_dense')
input_ids, input_mask, segment_ids, label_ids = preprocessor(features) # 获取输入
outputs = model([input_ids, input_mask, segment_ids], mode=mode) # 计算共享层
pooled_output = outputs[1]
# 独立计算个任务输出层
ret = {
"tnews_logits": tnews_dense(pooled_output),
"ocemotion_logits": ocemotion_dense(pooled_output),
"ocnli_logits": ocnli_dense(pooled_output),
"label_ids": label_ids
}
return ret
作为baseline,官方示例中的loss计算,也是简单使用各个任务的loss直接加和。具体的,在训练过程中,每个batch都只有一个任务的数据,也就是说每个batch只会对当前任务的loss进行优化,且没有对应的权重。示例中的模型结构和loss的思想与论文【Multi-Task Deep Neural Networks for Natural Language Understanding】基本一致,更多细节可以点击链接阅读论文。
优化方向
本次比赛的关键点是多任务与预训练模型结合,所以优化方向我们可以从多任务训练跟预训练模型两方面着手,比如:
修改MLT模型结构,示例中使用的是硬共享模式,可以尝试使用共享-私有模式来学习每个任务的独立特征。 修改各个任务的下游输入特征,示例中每个任务都是pooled层结果作为下游输入,因为任务的差异性,可以为不同的任务选择不同的下游输入特征,比如使用sequence_output特征,更有句法特性的底层encoder_layer特征或者融合特征等。 修改各个任务的下游网络,示例中每个任务的下游网络都是一层全连接层,对此可以进行适当调整,比如某个任务的下游网络替换成LSTM等等。 修改loss,示例中简单使用加和的方式作为整体loss,而比赛中的三个项目在难度与loss量级上都是有一定差距的,我们可以给每个任务的loss设置一个固定权重,也可以使用其他方式计算动态权重,来平衡各任务loss。 选择合适的预训练模型,当前研究人员提出了很多预训练模型,对于本次比赛而言,不同的预训练模型可能有较大的结果差异,所以选择一个合适的或者熟悉的预训练模型是非常必要的,可参考【 NLP集大成之预训练模型综述】。 对预训练模型进行再训练,在示例中是直接使用预训练模型来微调下游任务的,本次比赛中,也有一定数量的训练文本,可以使用这些文本,对预训练模型进一步预训练,从而提高模型在 相关任务上的表现,可参考【 NLP重铸篇之BERT如何微调文本分类 】。
作者:许惠琳 CLUE助理研究员
参考
【1】多任务学习优化(Optimization in Multi-task learning)
【2】模型汇总-14 多任务学习-Multitask Learning概述
【3】多任务学习-Multi-Task-Learning
【4】复旦大学邱锡鹏教授做客达观NLP研讨会:自然语言处理中的多任务学习
【5】Multi-Task Learning for Dense Prediction Tasks: A Survey
【6】An Overview of Multi-Task Learning in Deep Neural Networks
【7】Multi-Task Deep Neural Networks for Natural Language Understanding
【8】NLP集大成之预训练模型综述
【9】NLP重铸篇之BERT如何微调文本分类
【10】Multiple-gradient descent algorithm (mgda) for multiobjective optimization
【11】Gradnorm: Gradient normalization for adaptive loss balancing in deep multitask networks
【12】End-to-End Multi-Task Learning with Attention
【13】Dynamic task prioritization for multitask learning
【14】Multi-task learning using uncertainty to weigh losses for scene geometry and semantics
【15】中文语言理解测评基准(CLUE):https://www.cluebenchmarks.com/index.html
【16】EasyTransfer:make the development of transfer learning in NLP applications easier.
【17】NLP中文预训练模型泛化能力挑战赛:https://tianchi.aliyun.com/competition/entrance/531841/introduction
由于微信平台算法改版,公号内容将不再以时间排序展示,如果大家想第一时间看到我们的推送,强烈建议星标我们和给我们多点点【在看】。星标具体步骤为:
(1)点击页面最上方"AINLP",进入公众号主页。
(2)点击右上角的小点点,在弹出页面点击“设为星标”,就可以啦。
感谢支持,比心

推荐阅读
征稿启示| 200元稿费+5000DBC(价值20个小时GPU算力)
完结撒花!李宏毅老师深度学习与人类语言处理课程视频及课件(附下载)
模型压缩实践系列之——bert-of-theseus,一个非常亲民的bert压缩方法
文本自动摘要任务的“不完全”心得总结番外篇——submodular函数优化
斯坦福大学NLP组Python深度学习自然语言处理工具Stanza试用
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLPer(id:ainlper),备注工作/研究方向+加群目的。

阅读至此了,分享、点赞、在看三选一吧🙏


