CVPR 2020 | 给黑白照片上色,修复简直「如假包换」
点击上方“CVer”,选择加"星标"置顶
重磅干货,第一时间送达

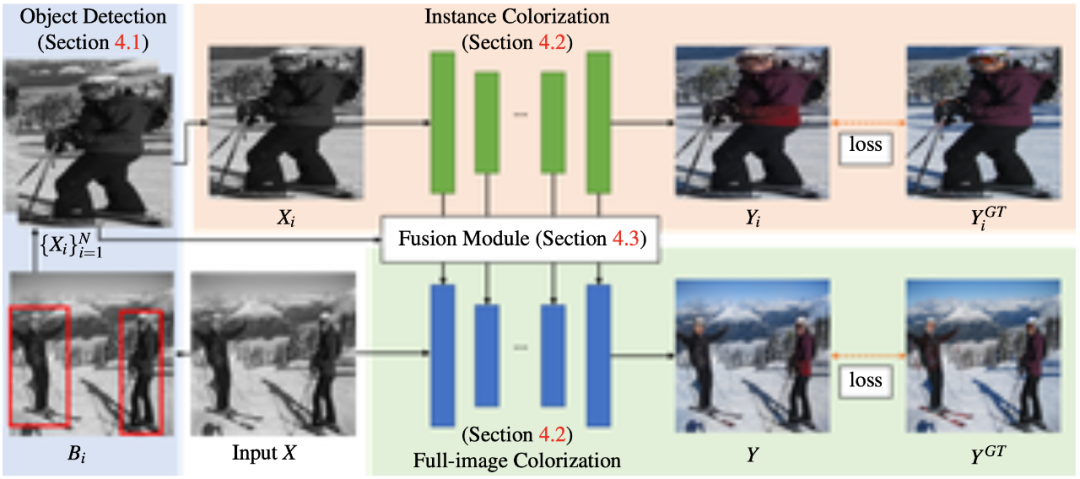
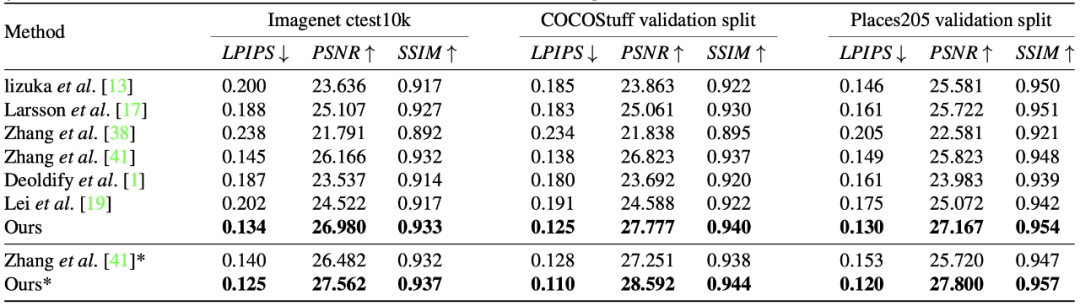
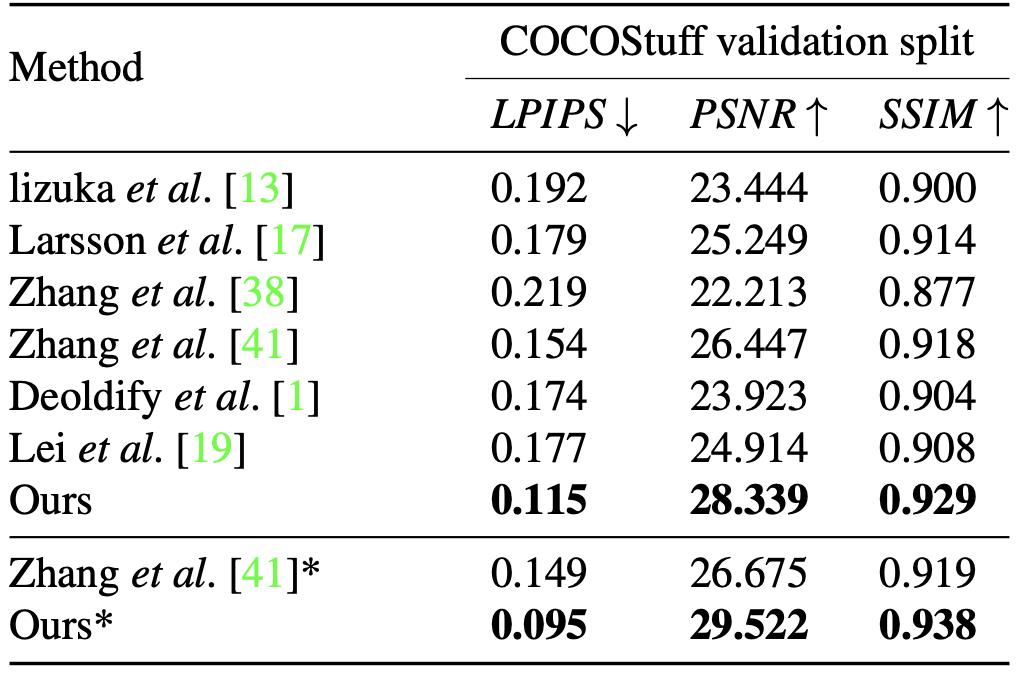
为黑白照片上色不难,但难在如何实现「以假乱真」。在这篇 CVPR 2020 论文中,研究者提出了一种全新的图像着色方法,通过检测出灰度图像中的不同目标,再对图像进行着色,使预测出的彩色图片更加接近真实色彩。
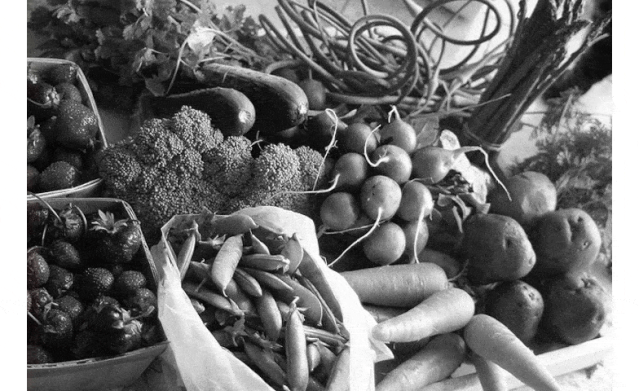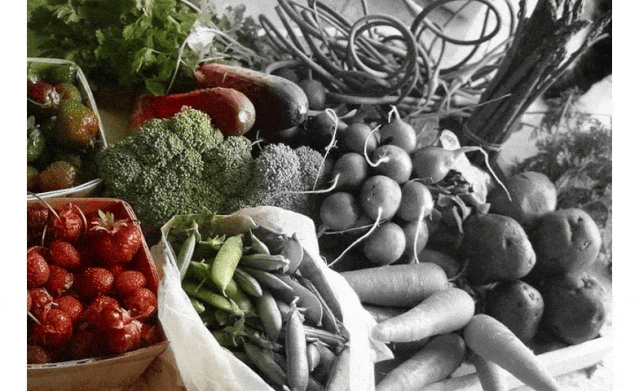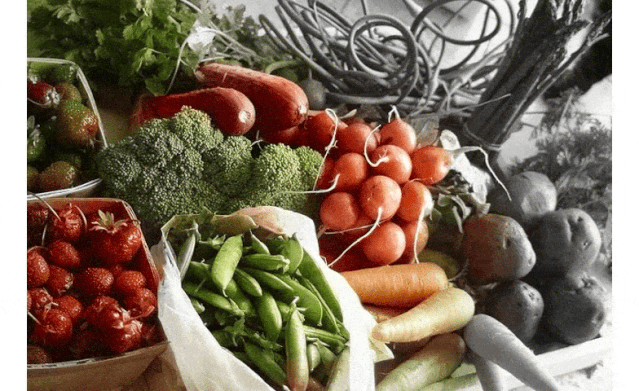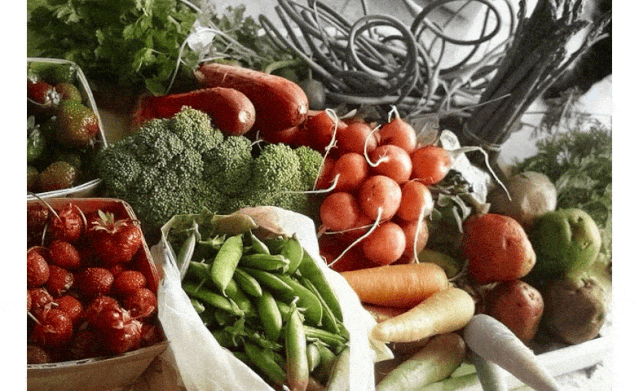



论文地址:https://arxiv.org/abs/2005.10825
GitHub 地址:https://github.com/ericsujw/InstColorization
Colab 地址:https://colab.research.google.com/github/ericsujw/InstColorization/blob/master/InstColorization.ipynb

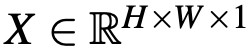 作为输入,以端到端的方式预测其丢失的在 CIE L∗a∗b∗色彩空间中的两个色彩通道
作为输入,以端到端的方式预测其丢失的在 CIE L∗a∗b∗色彩空间中的两个色彩通道
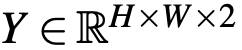
 。使用检测到的边界框从原灰度图中裁剪出不同物体,将裁剪后的图像调整大小后产生一系列实例图像
。使用检测到的边界框从原灰度图中裁剪出不同物体,将裁剪后的图像调整大小后产生一系列实例图像
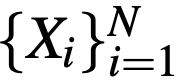 。接着,将每个实例图像 X_i 与灰度图像 X 分别输入到实例着色网络(instance colorization network)与全图着色网络(full-image colorization network)中。两个网络使用相同的结构,但网络权值各不相同。
。接着,将每个实例图像 X_i 与灰度图像 X 分别输入到实例着色网络(instance colorization network)与全图着色网络(full-image colorization network)中。两个网络使用相同的结构,但网络权值各不相同。
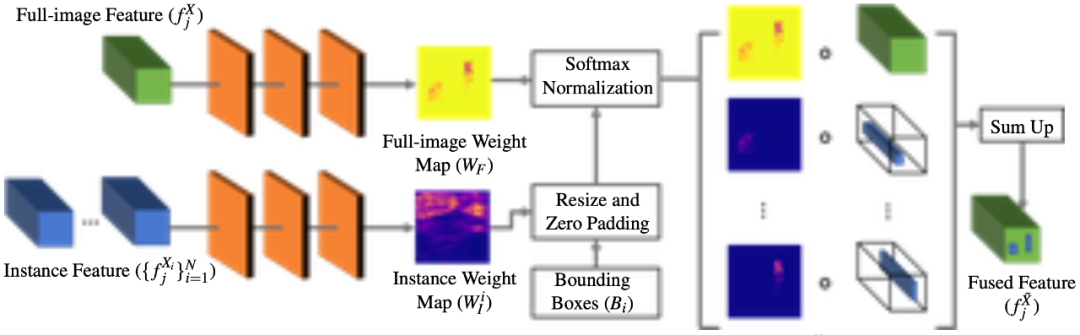
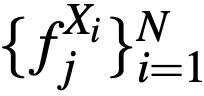 与全图特征 f^X_j 相融合。融合后的全图特征之后被输入下一层网络中。重复以上过程直到最后一层,并获得预测的彩色图像 Y。研究者首先训练了全图网络,之后训练实例网络,最后冻结以上两个网络来训练特征融合模块。
与全图特征 f^X_j 相融合。融合后的全图特征之后被输入下一层网络中。重复以上过程直到最后一层,并获得预测的彩色图像 Y。研究者首先训练了全图网络,之后训练实例网络,最后冻结以上两个网络来训练特征融合模块。


论文下载
在CVer公众号后台回复:上色0601,即可下载本论文
重磅!CVer-论文写作与投稿 交流群已成立
扫码添加CVer助手,可申请加入CVer-论文写作与投稿 微信交流群,目前已满1900+人,旨在交流顶会(CVPR/ICCV/ECCV/ICML/ICLR/AAAI等)、顶刊(IJCV/TPAMI等)、SCI、EI等写作与投稿事宜。
同时也可申请加入CVer大群和细分方向技术群,细分方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch和TensorFlow等群。
一定要备注:研究方向+地点+学校/公司+昵称(如论文写作+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群

▲长按加微信群

▲长按关注CVer公众号
请给CVer一个在看!
登录查看更多
相关内容

CVPR is the premier annual computer vision event comprising the main conference and several co-located workshops and short courses. With its high quality and low cost, it provides an exceptional value for students, academics and industry researchers.
CVPR 2020 will take place at The Washington State Convention Center in Seattle, WA, from June 16 to June 20, 2020.
http://cvpr2020.thecvf.com/
专知会员服务
26+阅读 · 2020年7月24日



相关VIP内容
专知会员服务
26+阅读 · 2020年7月24日
相关资讯
相关论文