来试试读论文的新神器!AMiner发布“论文背景文献”一键生成工具,帮你搞清一篇论文的“来龙去脉”

来自 DBLP、ArXiv、STM 等多家学术出版机构和平台的数据表明,在过去 20 年间,计算机科学、物理学、统计学等研究领域的出版物总量都有大幅增加。像 CVPR、AAAI 等有关人工智能等新兴领域的顶级会议,每年的论文接受量也已经高达上千篇。面对雨后春笋一样涌现的学术出版物和千上万篇学术论文,任何一名研究者都不可能了解所有新领域,即使这一领域和自己的研究方向近似。
如果有一种工具,可以把一篇论文的源头梳理清楚,就能极大地减少无效检索的时间,快速了解一个新领域的发展脉络。
在以往的研究中,计算机领域的相关学者提出了很多数据挖掘技术,比如概念抽取、主题演变、算法图谱等。但是,这些数据挖掘技术更多是着眼于提炼学术文献中的关键术语信息,研究它们之间的关系与变化,却很少关注学术出版物本身较深层次的内容以及关联关系。
近日,AMiner 团队的硕士生殷达等人提出一种新方法——论文溯源树(https://mrt.aminer.cn/),通过刻画学术文献的发展演变脉络,来帮助科研人员了解前沿论文是如何演变而来的。相关研究论文“MRT: Tracingthe Evolution of Scientific Publications”已被 TKDE 2021 接收。
“MRT 溯源树”是一个通过构建论文演变图帮助学者研究论文发展的工具,目标是研究论文中各种思路方法的演变过程。
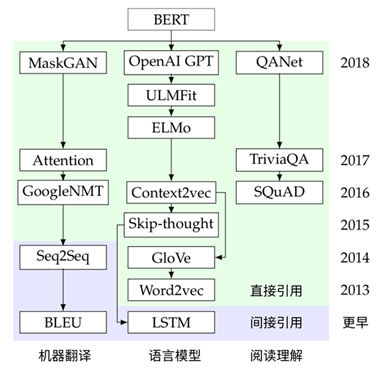
以知名 NLP 研究论文“BERT:Pre-training of Deep Bidirectional Transformers for Language Understanding”为例,BERT 对于预训练模型、文本向量、序列编码等方法的使用来源于语言模型这一方向上的 ELMo、Word2vec、LSTM 等工作中,而 MLM、Transformer 等内容则可以追溯到机器翻译领域中的 MaskGAN、Attention is all you need 等文章。
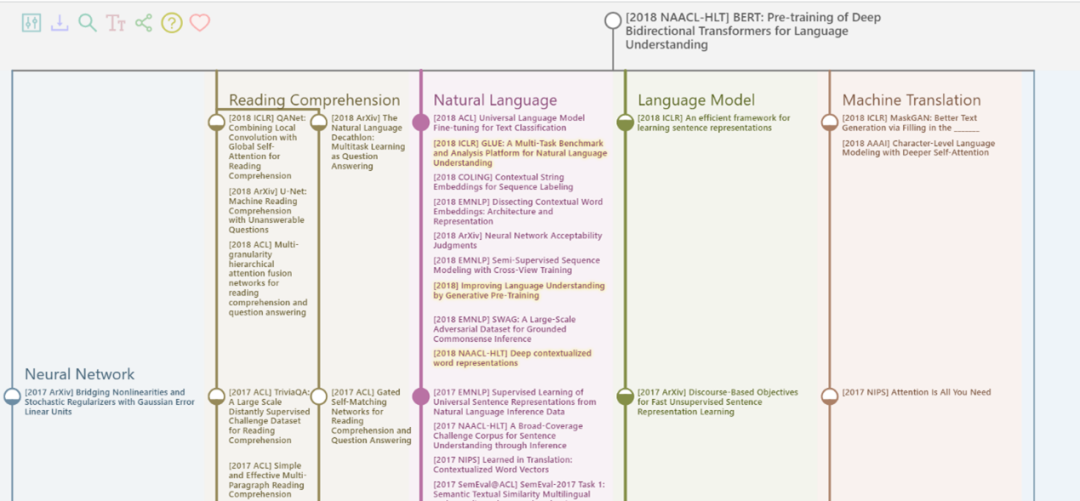
图:BERT 论文溯源(部分)
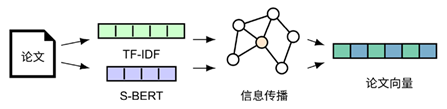
为了生成关于 BERT 的“论文溯源树”,研究团队采用了检索,阅读,构图,推理等若干步骤。
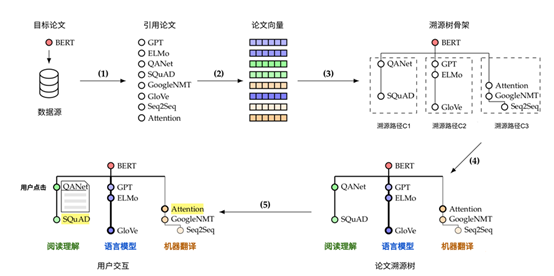
MRT 溯源树技术原理
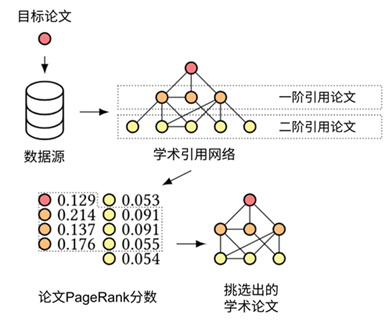
首先,算法将目标论文放入诸如 SemanticScholar 或是 AMiner 这样的开放数据源中进行检索,获取其论文标题、摘要及其引用信息,再根据引用信息扩展出多层引用网络,并采用 PageRank 算法进行排序,筛选与目标论文较为相关的文献。