图谱实战 | 基于半结构化百科的电影KG构建、查询与推理实践记录
转载公众号 | 老刘说NLP
本文围绕基于半结构化百科的电影知识图谱构建、查询与推理实践这一主题,完成基于百度百科的电影元组抽取、基于protégé的电影本体构建、基于D2RQ的RDF数据转换与查询、基于Apache jena的电影知识推理四个环节的实践。
这是半结构化知识图谱构建和应用的完整例子,希望大家能够对其中的一些流程,相关的工具等有个大致的了解。以对实际的工作提供帮助。
一、基于百度百科的电影元组抽取
要构建电影知识图谱,百度百科是一个很好的数据源,可以根据解析其中的infobox信息,形成对应的三元组信息,对应的百度三元组解析脚本如下:
def extract_avp_baidu(self, selector):
info_data = {}
if selector.xpath('//h2/text()'):
info_data['current_semantic'] = selector.xpath('//h2/text()')[0].replace(' ', '').replace('(','').replace(')','')
else:
info_data['current_semantic'] = ''
if info_data['current_semantic'] == '目录':
info_data['current_semantic'] = ''
info_data['tags'] = [item.replace('\n', '') for item in selector.xpath('//span[@class="taglist"]/text()')]
if selector.xpath("//div[starts-with(@class,'basic-info')]"):
for li_result in selector.xpath("//div[starts-with(@class,'basic-info')]")[0].xpath('./dl'):
attributes = [attribute.xpath('string(.)').replace('\n', '') for attribute in li_result.xpath('./dt')]
values = [value.xpath('string(.)').replace('\n', '') for value in li_result.xpath('./dd')]
for item in zip(attributes, values):
info_data[item[0].replace(' ', '')] = item[1].replace(' ', '')
return info_data
二、基于protégé的电影本体构建
Portege是当下最流行的本体构建工具,下面利用protégé本体构建工具构建电影本体,旨在掌握在Ubuntu系统下,protégé、环境的搭建及配置,并实现protégé本体构建方法,owl数据导出等操作。
1、Protégé安装部署
1)首先检查系统中是否已经安装了Java,在终端里面输入 java –version; 若如下显示,则表示已经安装,:

如果没有安装需要安装java环境,
sudo apt-get update
sudo apt-get install openjdk-8-jdk
java –version
显示上图即可
2)安装protégé
从https://protege.stanford.edu下安装protege。或者直接解压实验材料中的压缩包,在protége根目录下执行,即可启动protégé。
sudo bash ./run.sh
2、Protégé构建电影本体
1)定义本体IRI
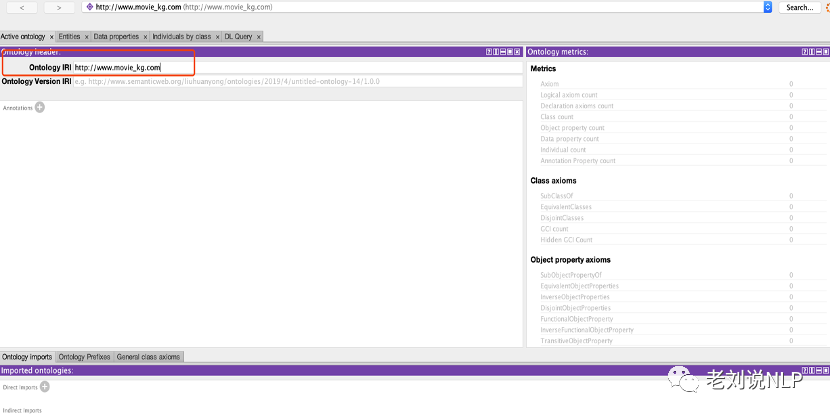
IRI即“国际化资源标识符”,可以类比于URI ,区别在于 URI 只能使用英文字符,所以没有办法很好的国际化兼容不同的文字语言,所以 IRI 就引入了 Unicode 字符来解决这个兼容问题,最后就有了国际化资源标识符(IRI)。protege中的ontology IRI,是默认的 IRI 路径。不可随意更改,必须符合RDF 文件规则。
打开Protégé洁面后,可以看到整个界面的内容。新建一个电影知识图谱本体,在ontologyIRI中填写一个电影本体的唯一标识,通常以https://wwww为开头,我们将其命名为https://www.movie_kg.com。一个知识体系统一使用一个IRI。
2)定义类别信息(实体建模)
在新建一个本体后,即对该本体的实体类型进行定义,包括两个部分。实体类型名称的定义以及实体类型属性的定义。在实体类型名称的定义上,点击“Entities”tab标签,选择“Classes”标签。在这个界面,我们创建电影知识图谱的类/概念,所有的类都是“Thing”的子类,具体的,在Classes右键owl:Thing ,选择Add Subclass,键入Movie,相当于新建了一个“Movie”类,重复此步,依次构建 Movie,Person,Role三个实体类型。
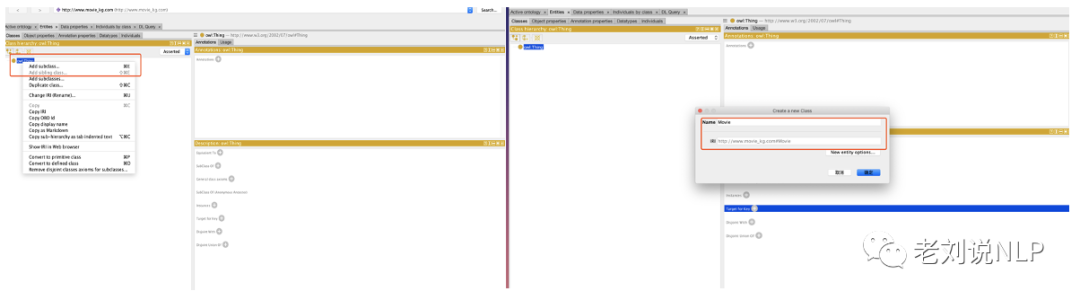
为了建模类之间的关系,protégé提供了类别属性的定义功能,例如,等价关系(equivalent)、子类(subclassof)、不相交关系(Disjoint of)等。通过建这类关系,在进行实体对齐的工作中能够用到。
3)定义对象属性(实体关系建模)
点击"Object Properties"按钮,进入到构造对象属性页面,在此界面创建类之间的关系(对象属性)对之前定义的三个类Movie,Person,Role定义关系类型。包括对关系的定义,以及关系之间关系的定义两个部分。
首先,在定义实体关系类型上,如上图所示,"domain"表示该属性是属于哪个类的(关系的头实体类型),"range"表示该属性的取值范围(关系的尾实体类型)。其次,Protégé提供了传递关系(transitive)、对称关系(Symmetric)、反对称关系(Asymmetric)、自反性(Reflexive)、反自反性(irreflexive)等实体关系类型属性的定义功能。
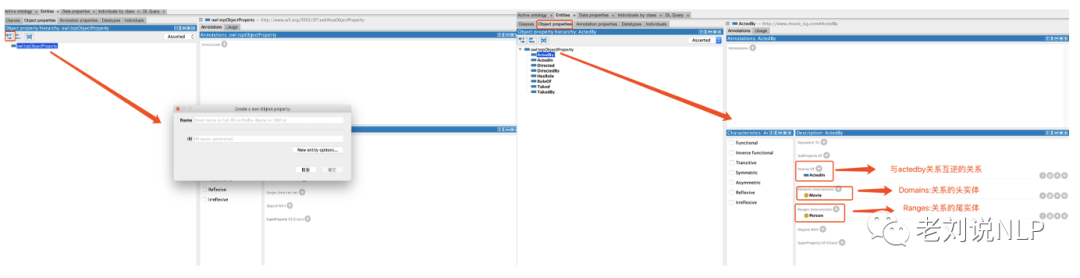
以点击actedby为例。新建属性,如actedby。
其中,inverse of用于表示说acted by与Acted as两者是互逆关系(一个人参演了某个电影,那么这个电影也就被该人物参演),通过这种定义,借助owl推理机可以完成推理操作,如记录中只有人参演某个电影,那么也能自动生成电影也就被该人物参演的信息。按照这种方式,依次定义movie actedby person、person actedin movie、movie hasrole role、role roleof movie、person directed movie、movie directedby person、person taked role、role takedby person等关系。
4)定义数据属性(实体属性建模)
在完成实体类型以及实体关系类型的定义后,需要进一步地完成对实体属性的定义。与实体关系不同,实体属性只有入度,而没有出度,是概念自身的对内关系,如人物有出生日期(Birthday)、出生地点(Birthplace),电影有电影名称(moviename)、电影简介(moveintro)。
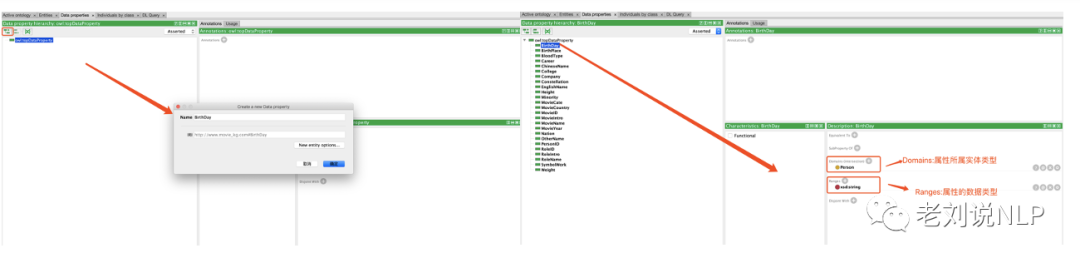
与定义实体类型相似,切换"Data properties",我们在该界面创建类的属性。先新建数据属性名称,然后在“Domain”下选择其所属的实体类型,在“Ranges”下选择属性的数据类型。Protégé提供了多种属性取值类型,包括浮点型(float)、日期型(gDay)、整型(interge),通过对属性类型的约束,相当于对后期进行知识填充设定了准入原则,有利于进行知识纠错和标准化例如,创建了“Birthday”属性名称,将“Domain”选择“Person”,以作为person的属性,在“Ranges”下选择“string”,表示取值为字符串型。重复该操作,依次构建Birthday、Birthplace、PersonID等属性类型。
5)查看本体的查看与保存
在完成对类的定义、类关系以及类属性的定义后,基本上一个本体就搭建起来了,为了对本体的整体面貌进行展示,protege可视化的方式来展示本体结构。具体地,可以点击windows->Tabs->OntoGraf,通过移动、拖拽的方式,可以看到构建好的ontology的整个网络结构标识。
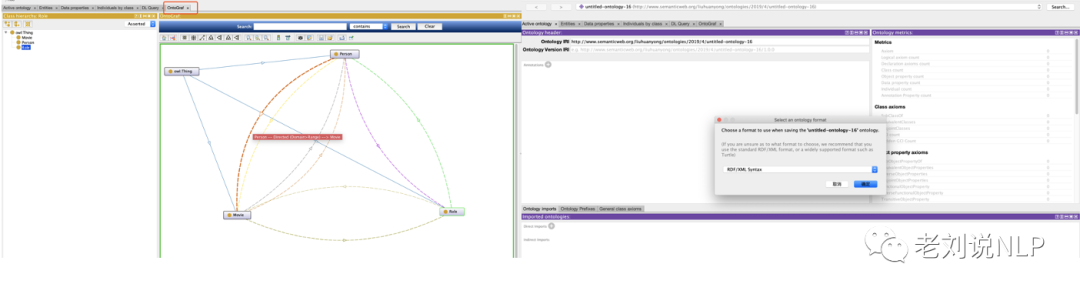
本体的导出,是其中最为关键的部分。点击File中的保存按钮,可以根据所需要的本体文件类型进行选择导出。Portege提供了利用内部表示转制成多种形式的文本表示格式,如:XML、RDF(S)、OIL、DAML、DAML+OIL、OWL等系统语言,我们选择Owl文件最终形成movie_kg.owl本体文件。
三、基于D2RQ的RDF数据转换与查询
D2rq是当前将结构化关系型数据转化成RDF数据访问的流行工具。该平台能够把关系数据库当作虚拟、只读的RDF图来访问,提供了基于rdf的访问模式,但不需要把数据以RDF的形式存储,这种以虚拟RDF图的方式访问关系数据库是其最主要的一个特性。它通过mapping文件,把对RDF的查询等操作翻译成SQL语句,最终在RDB上实现对应操作,起到的是一个查询转换的中间操作。
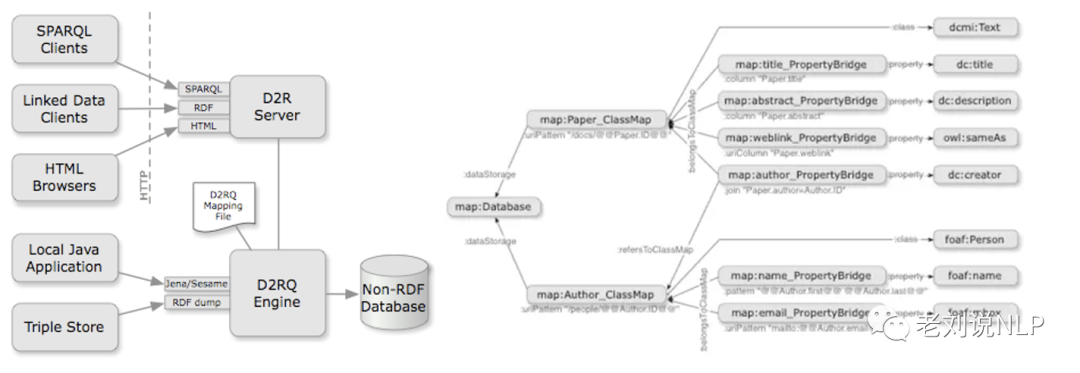
D2RQ平台提供了SPARQL访问,一个链接数据服务器,一个RDF数据集生成器,一个简单的HTML界面和Jena API访问D2RQ映射数据库,本实验在Ubuntu系统下,利用网络搭建d2rq,mysql开发环境,并完成利用d2rq完成对mysql中的数据的转换与查询,目的在于掌握在Ubuntu系统下,d2rq,mysql环境的搭建及数据库配置等操作,以及掌握csv数据导入mysq及d2rq将mysql数据转换成RDF数据的方法。
1、Mysql、Apache ant与D2rq的安装部署
1)Mysql的安装与部署
(1)首先检查系统中是否已经安装了MySQL。在终端里面输入 sudo netstat -tap | grep mysql若没有反映,没有显示已安装结果,则没有安装。若如下显示,则表示已经安装。
(2)如果没有安装,则安装MySQL。在终端输入 sudo apt-get install mysql-server mysql-client,运行结果如下所示: 在此安装过程中会让你输入root用户(管理MySQL数据库用户,非Linux系统用户)密码,按照要求输入即可。
(3)测试安装是否成功:在终端输入 sudo netstat -tap | grep mysql完成安装。
2)Apache Ant安装部署
Ant类似于Unix中的Make工具,是用来编译、生成Java的;命令行输入sudo apt-get install ant 即可完成安装
3)D2rq安装部署
(1)从https://github.com/d2rq/d2rq 获取所有文件,或解压d2rq文件。(2)编译D2rq,在根目录下输入ant , 回车即可。
2、数据导入关系数据库与RDF的映射
为了模拟从结构化关系数据到RDF数据的映射,我们使用起先整理好的知识图谱数据导入至mysql,包括person.csv、role.csv、movie.csv、movie_actor.csv、movie_director.csv、actor_role.csv共6个文件。
1)将csv图谱数据导入至mysql关系型数据库
(1)执行pip install csv,安装python处理csv的模块
(2)执行pip install pymysql,安装python操作mysql的模块
(3)执行python InsertMysql.py,将该6个文件每个对应一张表的方式,进行数据库建表操作,数据表外键建立,从csv数据到mysql数据的入库操作。如:
'''创建movie-table'''
def create_movie_table(self):
sql = """
CREATE TABLE IF NOT EXISTS Movie (
MovieID VARCHAR(255) NOT NULL PRIMARY KEY,
MovieCountry VARCHAR(255) NOT NULL,
MovieCate VARCHAR(255) NOT NULL,
MovieIntro TEXT NOT NULL,
MovieName VARCHAR(255) NOT NULL,
MovieYear VARCHAR(255) NOT NULL
)ENGINE=innodb DEFAULT CHARSET=utf8;
"""
cursor = self.conn.cursor()
cursor.execute(sql)
cursor.close()
2)生成R2ML语言的转换和映射mapping文件
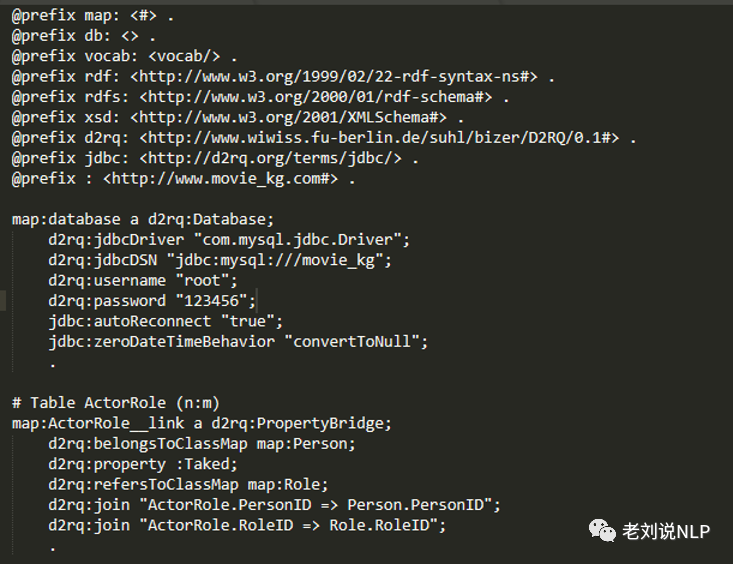
(1)在D2rq根目录下执行generate-mapping生成mapping文件 ./generate-mapping -u root -p 123456 -o movie_kg_mapping.ttl jdbc:mysql:///movie_kg Mapping文件定义了整个映射的主要模式,即把每个表映射成一个类,每一行是一个资源,每一列就是资源的属性,例如生成的mapping文件内容如下:
3)基于mapping文件,生成RDF三元组数据
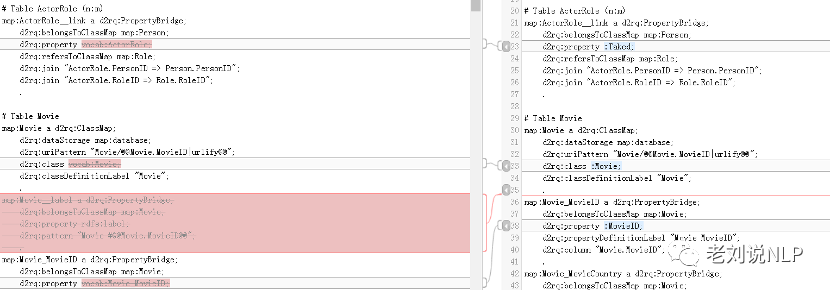
由于自动生成的mapping文件对map和property并未严格对应,因此需要修改mapping文件。包括剔除掉关于主键id的map描述,更改d2rq:class和d2rq:property,将其后面的值对应到自己定义的本体上。具体地:修改movie_kg_mapping.ttl文件,另存为movie_kg_mapping_modify.ttl 具体修改部分如下所示:
4)在D2rq根目录下执行dump-rdf生成movie_kg.nt:
执行命令:./dump-rdf -o movie_kg.nt movie_kg_mapping_modify.ttl Movie_kg.nt文件内容如下,每行一个三元组,总记录共797548条RDF三元组数据。

3、使用D2rq的sparql查询
在生成好RDF数据后,则可以应用mapping文件对关系型数据库进行查询。具体地:
1)通过D2rq,应用mapping文件实现对关系型数据库的查询 ./d2r-server movie_kg_mapping_modify.ttl
2)修改mapping文件 默认情况下sparql不支持中文,因此需要修改mapping.ttl文件,添加连接数据的字符编码属性:
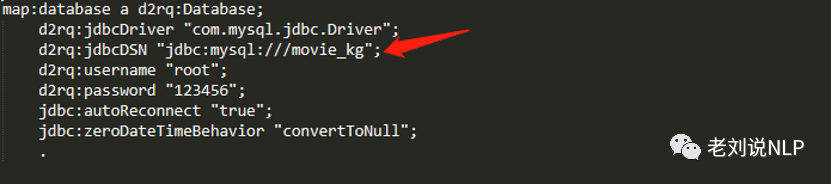
d2rq:jdbcDSN "jdbc:mysql:///movie_kg?useUnicode=true&characterEncoding=utf8";
5、启动执行sparql查询
1)在根目录执行:
./d2r-server movie_kg_mapping_modify.ttl
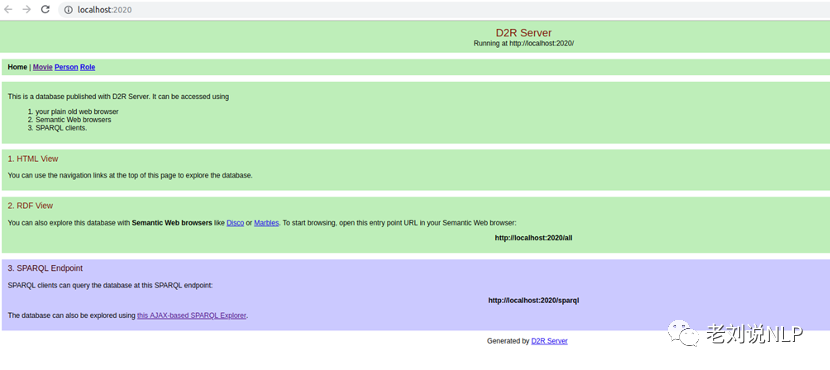
2)打开浏览器输入http://localhost:2020,可以看到交互的页面窗口
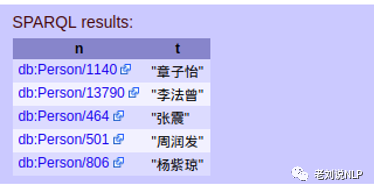
3)执行查询,在查询窗口中,输入SPARQL脚本,完成查询情况,可以得到右侧的结果,如:例1:电影卧虎藏龙都有哪些演员
SELECT ?n ?t WHERE {
?m:MovieName '卧虎藏龙'.
?n :ActedIn ?m.
?n :ChineseName ?t
}
例2:王宝强和徐峥共同参演的电影
SELECT distinct ?n WHERE {
?s1 rdf:type :Person.
?s2 rdf:type :Person.
?s1 :ChineseName "王宝强".
?s2 :ChineseName "徐峥".
?s1 :ActedIn ?m.
?s2 :ActedIn ?m.
?m :MovieName ?n
}
LIMIT 10

例3:周星驰扮演过什么角色
SELECT distinct ?n WHERE {
?s rdf:type :Person.
?s :ChineseName "周星驰".
?s :Taked ?m.
?m :RoleName ?n
}
LIMIT 10

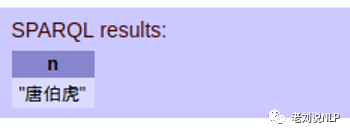
例4:周星驰在唐伯虎点秋香中扮演了什么角色
SELECT distinct ?n WHERE {
?s rdf:type :Person.
?s :ChineseName "周星驰".
?s :Taked ?r.
?s :ActedIn ?m.
?m :MovieName "唐伯虎点秋香".
?r :RoleOf ?m.
?r :RoleName ?n
}
LIMIT 10
四、基于Neo4j的图数据存储与查询
除RDF格式外,图数据库也是知识图谱存储的常用格式。Neo4j是当前最为流行的图数据库。本部分内容利用网络搭建neo4j图数据库实验环境,通过neo4j-import工具将电影图谱数据导入数据库,最后通过cypher语言对实验数据进行增删改查等基本操作。
1、Neo4j安装部署
1)neo4j图数据库的下载和安装
官网下载neo4j压缩包https://neo4j.com/download/,或者使用实验材料准备好的linux版本的neo4j 3.4.5 ;
(1)解压,Neo4j 安装到目录 /usr/local/neo4j,所以将压缩包复制到该目录下解压:
tar -xzvf neo4j-community-3.4.5-unix.tar.gz
(2)启动,在 Neo4j 目录下启动:
root@ubuntu:/usr/local/neo4j/bin# ./neo4j start
2)neo4j图数据库的配置(数据库地址设置)
neo4j的配置文件在conf文件夹中,对该配置文件进行编辑,打开neo4j.conf对数据库进行配置,默认数据库为graph.db,新建数据库两种方法(1)可以通过neo4j import新建数据库(需要停掉neo4j服务,./bin/neo4j stop),例如新建kg.db数据库,将kg.db放入data/database文件夹下,修改配置文件中的默认数据库,2)无需修改配置文件,直接将原始graph.db备份为graph1.db,将新库kg.db命名为graph.db,重新启动neo4j服务即可./bin/neo4j stop
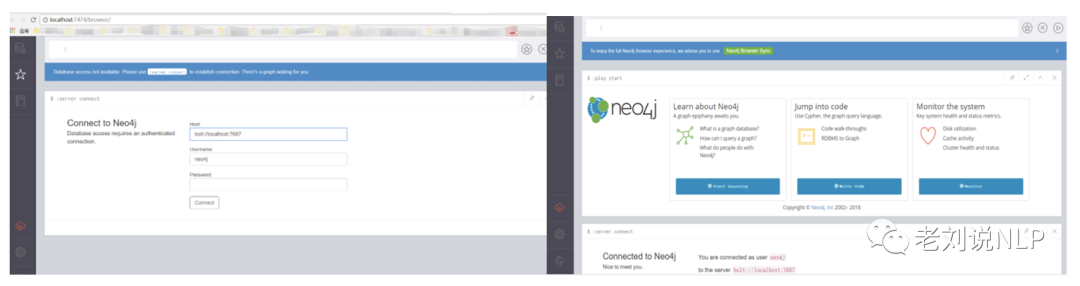
3)neo4j浏览器界面的启动、用户名和密码设置
进入bin目录下命令行输入./neo4j start 即可启动服务,浏览器输http://localhost:7474即可启动web界面。如果配置中设置 dbms.security.auth_enabled=true的话需要自己设置帐号密码,默认为usename:neo4j,password:neo4j. root@ubuntu:/usr/local/neo4j/bin# ./neo4j start,启动成功后如右图所示:
2、neo4j图数据库数据导入与展示
Neo4j图数据库的导入可以使用自带的工具进行导入,也可以使用py2neo插件通过程序脚本完成导入,下面介绍两种方式的具体过程。
1)使用neo4j-import导入图谱
(1)节点数据构造 Neo4j-import 需要定义csv的HEADER格式,nodes标准格式如下:以movie.csv为例,neo4j中每个节点都需要一个ID属性来唯一标示,方便后续建立关系使用, LABEL属性是可选的, ID是强制的。此处将movie_id标识为ID,即movie_id:ID;最后一列添加LABEL属性MOVIE,即:LABEL,可以没有列名。

同样的方法标记actor.csv,role.csv
(2)关系数据构造
同样的,Neo4j对关系数据的类型也进行了定义,relations标准格式如下,以movie_actor.csv为例,需要标明START-ID END-ID,以及关系类型TYPE,此处定义actor_id为START-ID,movie_id为END-ID,关系类型为ACTED_IN,即演员出演了某部电影
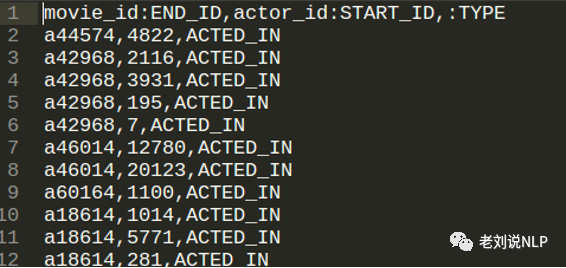
同样的方法标记movie_director.csv,movie_role.csv,actor_role.csv 标记完后所有csv文件存放在import文件夹下。
(3)数据导入
切换到 neo4j/bin目录,执行导入命令如下:
neo4j-import --multiline-fields=true --bad-tolerance=1000000 --into=graph.db --nodes=../import/actor.csv --nodes=../import/movie.csv --nodes=../import/role.csv --relationships=../import/movie_actor.csv --relationships=../import/movie_director.csv --relationships=../import/movie_role.csv --relationships=../import/actor_role.csv –skip-duplicate-nodes
其中--multiline-fields参数允许数据存在换行符时跨行插入;--nodes即节点文件路径;--relationships 关系文件路径;--skip-duplicate-nodes 重复数据跳过。运行完后会在bin目录生成graph.db,将graph.db放入data/database文件夹下覆盖原数据库文件即可。
2)使用py2neo读取csv文件导入neo4j
通过使用py2neo进行操作,先新建图谱节点,再新建图谱关系,两个步骤,在该操作中,需要注意数据的重复情况,如下所示:
(1) 连接数据库
graph =Graph(
host="127.0.0.1", # neo4j 搭载服务器的ip地址,ifconfig可获取到
http_port=7474, # neo4j 服务器监听的端口号
user="neo4j", # 数据库user name,如果没有更改过,应该是neo4j
password="123")
(2)读取csv文件
movies_df = pd.read_csv(r'./movie.csv')
actors_df = pd.read_csv(r'./actor.csv')
relations_df=pd.read_csv('./movie_actor.csv')
(3)创建节点(实体)
1.创建标签为Actor的节点
def create_nodes_auto(df,label):
length=df.shape[0]
count = 0
for i in range(length):
properties={}
for j in df.columns:
properties[j]=str(df.iloc[i, :][j])
print(properties)
node = Node(label,
**properties
)
graph.create(node)
count+=1
print('create {} nodes successfully!'.format(count))
(4)创建节点关系(实体关系)
def create_rels_actor_movie(df,label):
selector = NodeSelector(graph)
for i in range(relations_df.shape[0]):
#
movie_id = str(movies_df.iloc[i, :]['movie_id'])
movie_node = selector.select("Movie", movie_id=movie_id).first()
actor_id = str(actors_df.iloc[i, :]['actor_id'])
actor_node = selector.select("Actor", actor_id=actor_id).first()
relationship = Relationship(actor_node, 'ACTED_IN', movie_node)
graph.create(relationship)
3)Neo4j数据的展示 Neo4j图数据库,基于D3js提供了一个图数据库可视化交互页面,从该页面中的左侧可以看到整个图谱的情况,包括节点的类型和规模(Node labels)、关系的类型与规模(Relationship types)以及实体属性类型(property keys)。
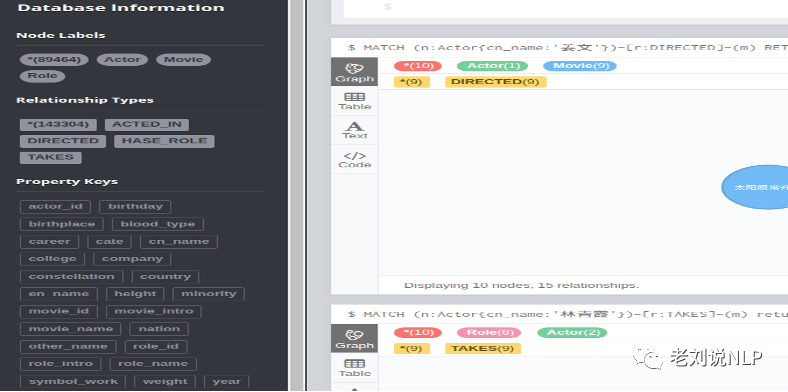
其中, Neo4j中实体包括节点(node)和关系 (relation), node可以有标签label,标识某一类节点,如Actor标识演员节点;node可以有属性(property),如Actor节点中的cn_name,birthday等;relation包括ACTED_IN,HASE_ROLE等。
4)利用cypher进行图谱查询建立索引
Cypher语言是一个十分友好的语言,通过箭头以及节点,使得整个查询语句十分形象,可以通过编写查询模式的方式,在目前已建立好的知识图谱中实施查询。
(1)索引建立。 在导入数据之后,一般情况下为了提高查询速度,都会对节点建立索引。例如,执行:
CREATE INDEX ON :Actor(cn_name),该操作将给标签为Actor的节点属性cn_name建立索引,建立索引的好处是后续查询更快。
(2)图谱查询。 基于cypher针对Neo4j进行实用查询。例如:想找到姜文导演了哪些作品?可转换为:
“match (n:Actor{cn_name:‘姜文’})-[r:DIRECTED]-(m) Return n,r,m”
进让子弹飞中都有哪些角色?可转换为:
“match (n:Movie{movie_name:‘让子弹飞’})-[r:HASE_ROLE]-(m) Return n,r,m”
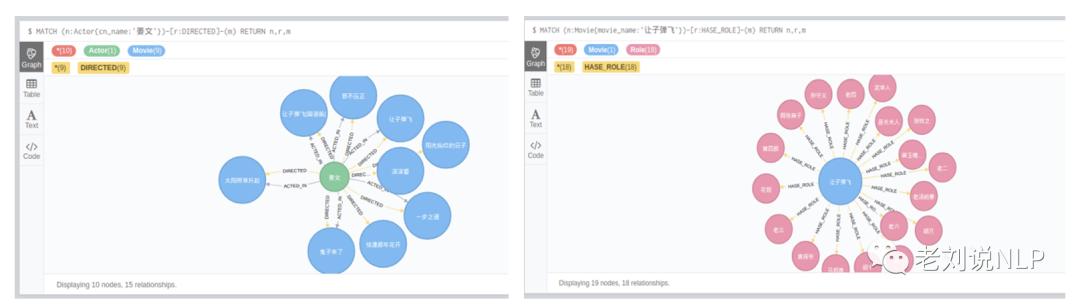
分别执行该语句后,可以得到查询的结果。结果包括三种,一个是Graph图展示,一个是文本形式Text,另一个是Code型,在Graph图中,支持节点的扩展、拖拽、颜色更改以及节点属性切换显示等功能。
五、基于Apache jena的电影知识推理
本部分利用网络搭建Apache jena开发环境。利用jena及jena-fuseki进行自定义规则的推理查询。
1、Jena及jena-fuseki安装部署
1)Apache jena的下载
1)下载JENA,http://jena.apache.org/download/index.cgi下分别下载 apache-jena-3.11.0.zip apache-jena-fuseki-3.11.0.zip
2)分别解压两个文件至本地,形成apache-jena-3.11.0, apache-jena-fuseki-3.11.0两个文件夹
2)Apache jena的配置
1.进入apache-jena-3.11.0文件夹 2.运行: export JENA_HOME=path_to/apache-jena-3.11.0(注意,path_to/apache-jena-3.11.0表示apache-jena-3.11.0的绝对路径)
3)apache jena RDF文件的存储
1.准备好原先生成的movie_kg.nt文件, 将movie_kg.nt文件移动至apache-jena-fuseki-3.11.0的根目录. 2.进入到apache-jena-3.11.0/bin文件目录下 3.运行./tdbloader2 --loc tdb path_to/movie_kg.nt(注意,path_to/movie_kg.nt表示movie_kg.nt的绝对路径) 执行结束后,会在bin文件目录下生成一个tdb文件夹,里面是tdb数据库内容 4.查看tdb文件夹中内容, 里面有dat, idn等文件
4)apache-jena-fuseki启用tdb文件
1.将整个tdb目录移动到apache-jena-fuseki-3.11.0文件夹下 2.jena-fuseki加载tdb文件启动 进入到apache-jena-fuseki-3.11.0根目录,执行命令 ./fuseki-server --loc=tdb /db 启动成功后, 3030端口开启 3.打开http://127.0.0.1:3030,可以看到jena-fuseki的操作界面
5)apache-jena-fuseki数据的查询 1.打开http://127.0.0.1:3030, 点击dataset, 进入query的问答界面 2.在查询框中写入前缀,内容如下: PREFIX rdf: http://www.w3.org/1999/02/22-rdf-syntax-ns# PREFIX rdfs: http://www.w3.org/2000/01/rdf-schema# PREFIX owl: http://www.w3.org/2002/07/owl# PREFIX xsd: http://www.w3.org/2001/XMLSchema# prefix : http://www.movie_kg.com# 3.查询电影”功夫”的三元组信息,在查询框中写入查询体,内容如下: SELECT * WHERE { ?s :MovieName '功夫'. ?s ?p ?o. } 4.点击运行,得到结果:
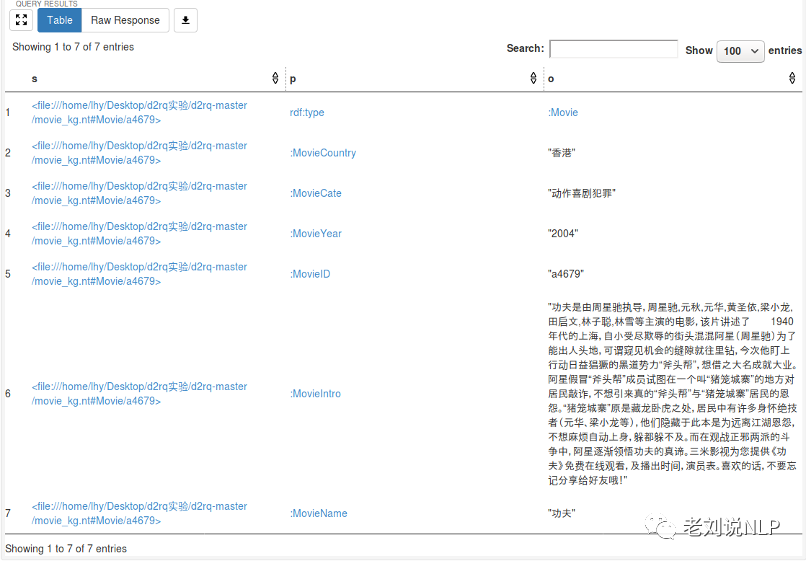
从中我们发现,关于电影"功夫"相关的知识三元组有7条记录。
2、推理规则的配置与启动
1)配置本体文件
1)将之前构建好的电影本体文件ontology.owl, 将.owl后缀改成.ttl后缀,因为fuseki-jena只识别ttl文件。
2)将该文件移动至apache-jena-fuseki-3.11.0/run/databases的文件夹下。
2)配置推理规则文件
1.进入到apache-jena-fuseki-3.11.0/run/databases文件夹下
2.新建配置文件, 命名文件名称为”rules.ttl”
3.在rulers.ttl文件中输入如下内容(或参见文件夹下的rulers.ttl,复制并加以更改即可):
@prefix : <http://www.movie_kg.com#> .
@prefix owl: <http://www.w3.org/2002/07/owl#> .
@prefix rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#> .
@prefix xsd: <XML Schema> .
@prefix rdfs: <http://www.w3.org/2000/01/rdf-schema#> .
[ruleInverse: (?p :ActedIn ?m) -> (?m :ActedBy ?p)]
[ruleInverse: (?p :Directed ?m) -> (?m :DirectedBy ?p)]
[ruleInverse: (?p :HasRole ?m) -> (?m :RoleOf ?p)]
[ruleInverse: (?p :Taked ?m) -> (?m :TakedBy ?p)]
4.保存该rules.ttl文件
5.关于推理规则的配置说明:
@prefix : http://www.movie_kg.com# .相当于本体的前缀,这个用于解析三元组数据。
规则的定义规范,[规则名称:(旧知识三元组)->(新知识三元组)],如果自己需要新建规则的话,则按照这种规则方式进行添加。
3)配置fuseki启动文件
1.进入到apache-jena-fuseki-3.11.0/run/configuration文件夹下 2.新建配置文件, 命名文件名称为”fuseki_conf.ttl” 3.在fuseki_conf.ttl文件中输入如下内容(或参见文件夹下的fuseki_conf.ttl,复制并加以更改即可):
@prefix tdb: <http://jena.hpl.hp.com/2008/tdb#> .
@prefix rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#> .
@prefix rdfs: <http://www.w3.org/2000/01/rdf-schema#> .
@prefix ja: <http://jena.hpl.hp.com/2005/11/Assembler#> .
@prefix fuseki: <http://jena.apache.org/fuseki#> .
<#service1> rdf:type fuseki:Service ;
fuseki:name "movie_kg" ;
fuseki:serviceQuery "sparql", "query" ;
fuseki:serviceReadGraphStore "get" ;
fuseki:dataset <#dataset> ;
.
<#dataset> rdf:type ja:RDFDataset ;
ja:defaultGraph <#modelInf> ;
.
<#modelInf> rdf:type ja:InfModel ;
#使用推理规则推理
ja:reasoner
[ja:reasonerURL <http://jena.hpl.hp.com/2003/GenericRuleReasoner> ;
ja:rulesFrom <file:rulers.ttl的绝对路径> ] ;
ja:baseModel <#g> ;
.
<#g> rdf:type tdb:GraphTDB ;
tdb:location "tdb文件夹的绝对路径" ;
tdb:unionDefaultGraph true ;
.
4.保存fuseki_conf.ttl文件
4)推理服务器的启动
1.进入到apache-jena-fuseki-3.11.0 2.ctrl+c,将之前的服务关闭. 3.执行命令:./fuseki-server, 启动fuseki服务,提示3030端口开启 4.打开http://127.0.0.1:3030,可以看到jena-fuseki的操作界面 5.推理运行与结果查询 a)打开http://127.0.0.1:3030, 点击dataset, 进入query的问答界面 b)在查询框中写入前缀,内容如下:
PREFIX rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#>
PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#>
PREFIX owl: <http://www.w3.org/2002/07/owl#>
PREFIX xsd: <http://www.w3.org/2001/XMLSchema#>
prefix : <http://www.movie_kg.com#>
-
查询电影”功夫”的三元组信息,在查询框中写入查询体,内容如下:
SELECT * WHERE {
?s :MovieName '功夫'.
?s ?p ?o.
}
-
点击运行,得到结果:
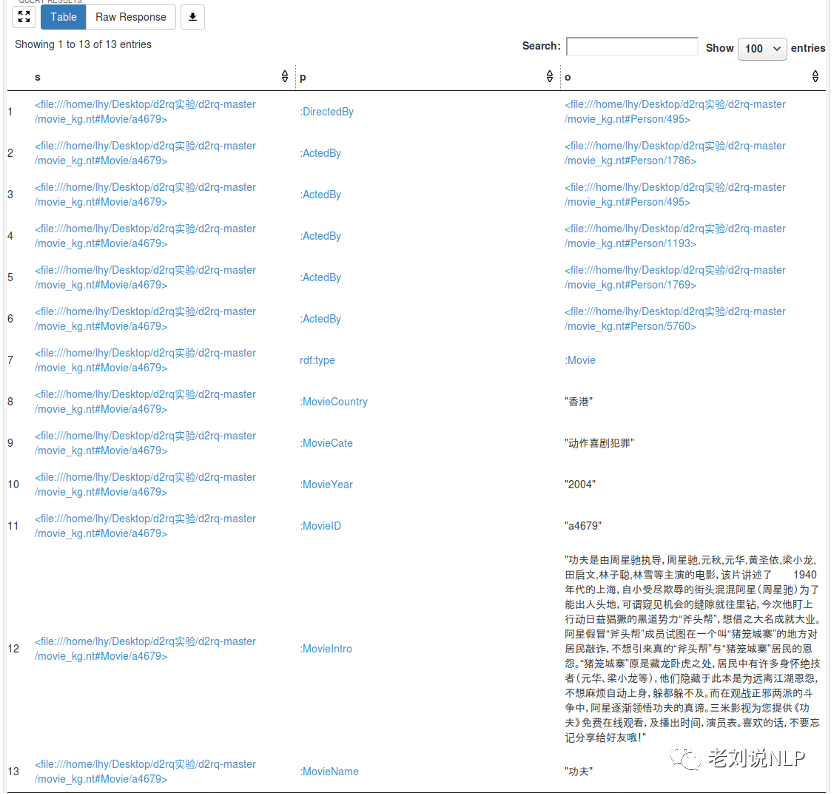
从中,我们可以看到,关于电影”功夫”的三元组记录,由之前的7条增加至13条,出现了之前没有的三元组关系如ActedBy, DirectedBy。5) 同样的, 我们查询电影”功夫”都被那些人参演的结果.这个也是推理的结果.我们输入查询体, 点击查询.
SELECT distinct ?m WHERE {
?s :MovieName '功夫'.
?s ?ActedBy ?n.
?n :ChineseName ?m
}
-
返回结果如下:
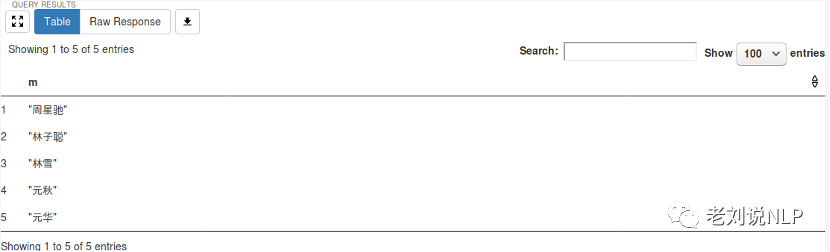
从结果中我们可以看到,可以直接通过推理结果完成某个三元组的直接访问。
七、总结
本文围绕基于半结构化百科的电影知识图谱构建、查询与推理实践这一主题,完成基于protégé的电影本体构建、基于D2RQ的RDF数据转换与查询、基于Apache jena的电影知识推理三个环节的实践。
实际上,我们需要认识到的是:
1、上述方法,更多的是在学术场景下使用,在真实的应用场景中更多的还是通过中间处理组建,进行转换,上述操作更多的是作为一种教学入门级的处理。
2、当前的知识图谱构建依旧是以半结构化数据或者结构化数据的处理,大家都被堵在数据标准化融合这一数据治理的环节,其中涉及到许多技术难题和工程难题。
关于作者
老刘,刘焕勇,NLP开源爱好者与践行者,主页:https://liuhuanyong.github.io。
就职于360人工智能研究院、曾就职于中国科学院软件研究所。
老刘说NLP,将定期发布语言资源、工程实践、技术总结等内容,欢迎关注。
OpenKG
OpenKG(中文开放知识图谱)旨在推动以中文为核心的知识图谱数据的开放、互联及众包,并促进知识图谱算法、工具及平台的开源开放。

点击阅读原文,进入 OpenKG 网站。




