一文梳理基于梯度的黑盒迁移对抗攻击研究进展

©PaperWeekly 原创 · 作者 | 鬼谷子

引言
黑盒迁移攻击是对抗攻击中非常热门的一个研究方向,基于动量梯度的方法又是黑盒迁移攻击的一个主流方向。当前大部分研究主要通过在数据样本的尺寸,分布,规模,时序等方面来丰富梯度的多样性,使得生成的对抗样本在迁移到其它的模型攻击时,能够有更高的攻击成功率。

注意力攻击(AoA)
2.1 论文简介

数据集链接:
2.2 论文方法
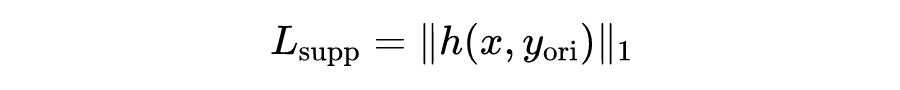
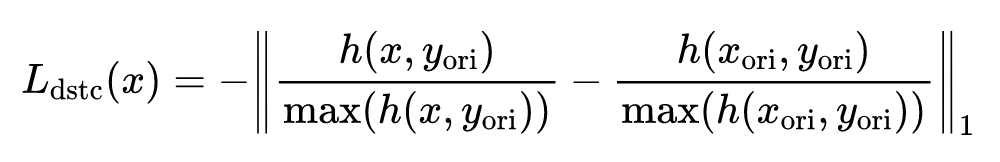
其中通过进行自归一化以消除注意力大小的影响。
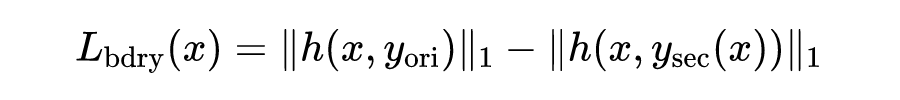
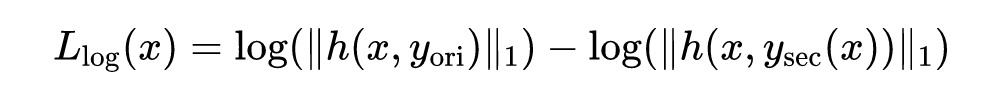
经实验可知,对数边界损失是迁移攻击效果最好的,因此该损失函数被选为目标函数的中的一项。
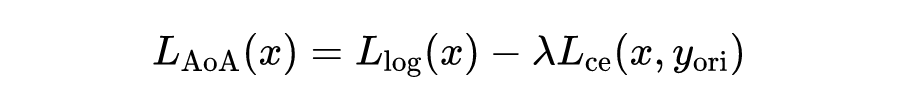
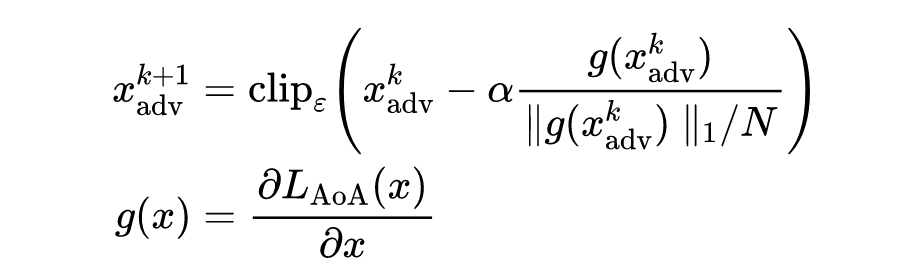

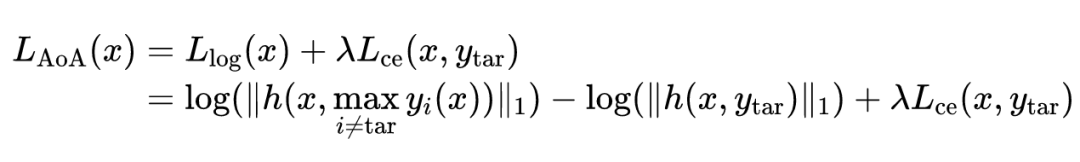

线性反向传播(LinBP)

代码链接:

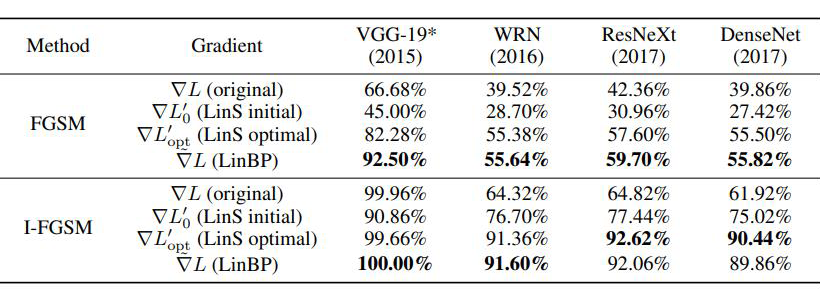
尽管该假设在小数据集模型中的实验里得到了验证,但在大数据集中的大型网络上几乎没有经验证据可以验证它,更不用说在实践中使用该假设。所以,在该论文中,作者首先需要验证大数据集中的大型网络上对抗样本的可迁移性根植于模型的近似线性特征。
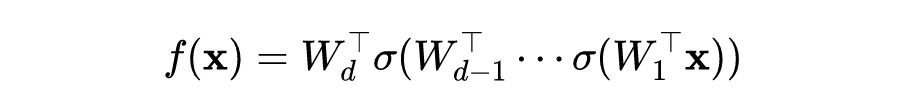
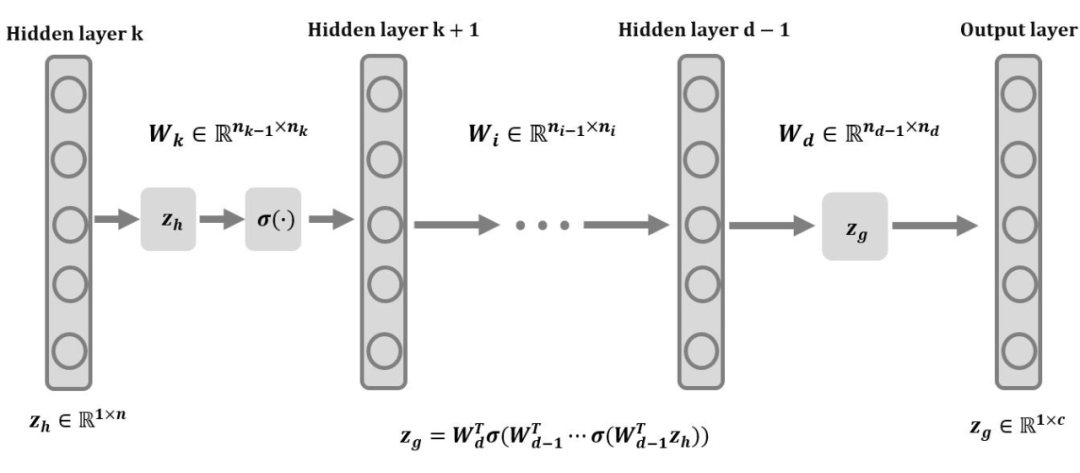
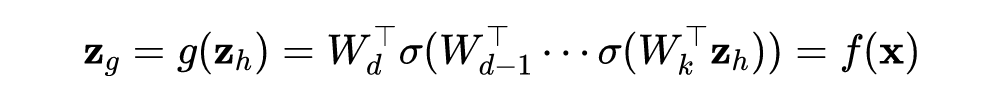
由矩阵的微分定理可知:
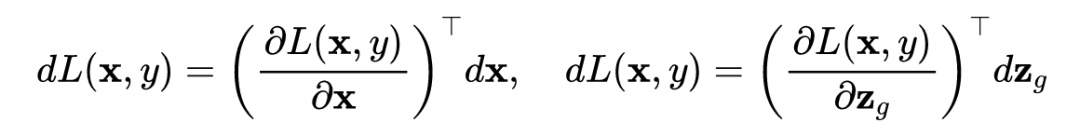
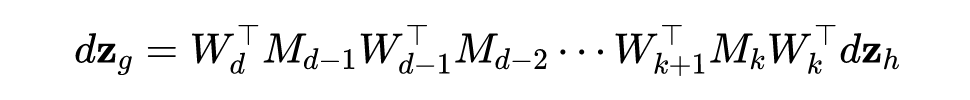
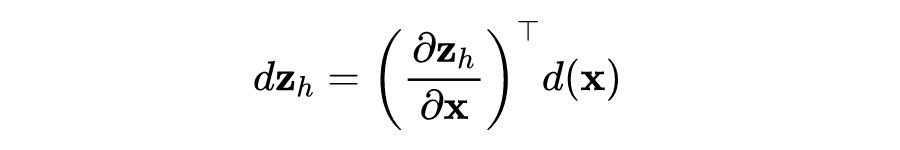
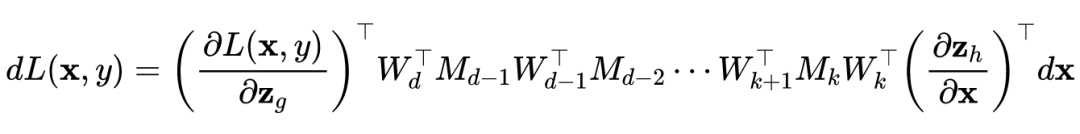
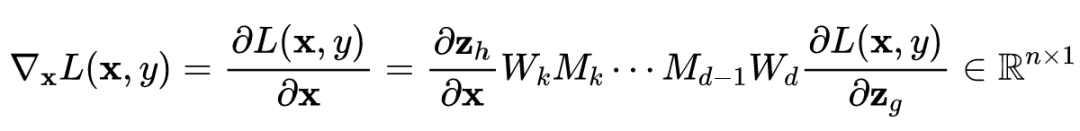
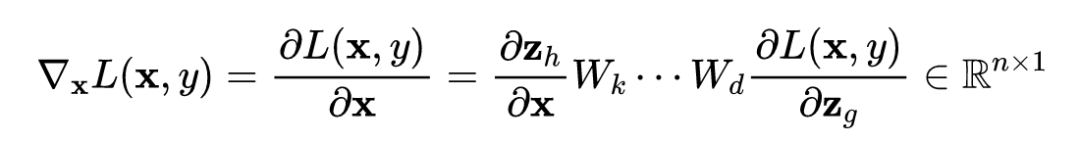
论文中采用的是行向量,以上证明是用列向量,所以结论得证。
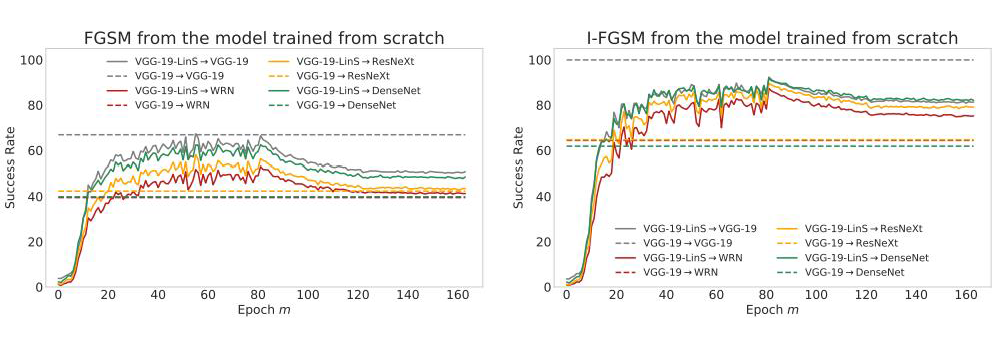
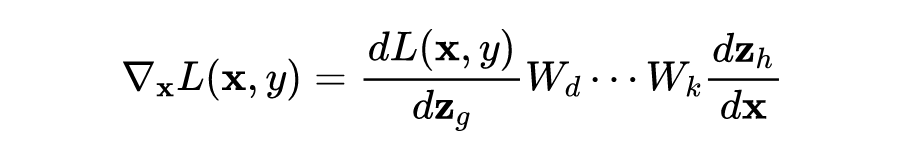
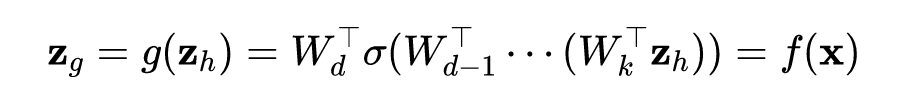

在该论文中,作者提出了一种梯度方差调整的对抗攻击的方法,其目的是增强基于迭代梯度的攻击方法生成对抗样本的可迁移性。在每次迭代进行梯度计算时,不再直接使用当前梯度进行动量累积,而是进一步考虑上一次迭代的梯度方差来调整当前梯度,从而稳定更新方向,避免不良局部最优。

代码链接:
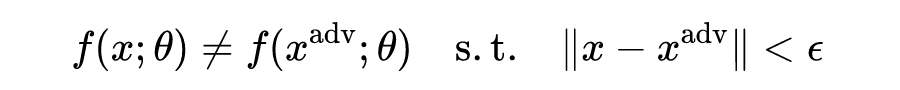
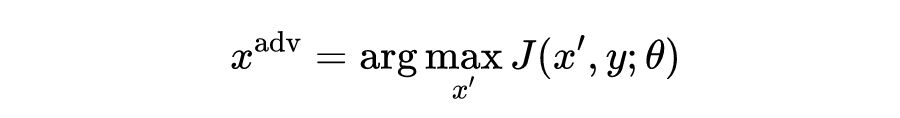
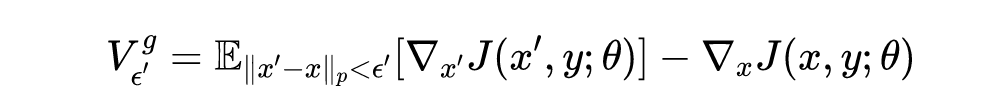
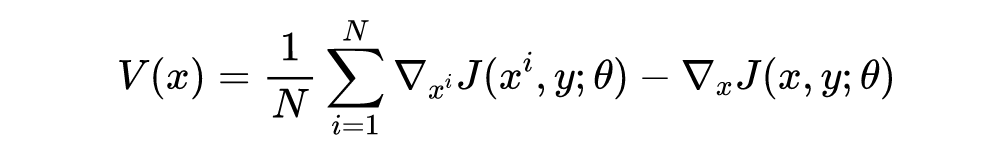


梯度加速和尺度不变对抗攻击
在该论文中,作者从将对抗样本生成视为优化过程的角度,提出了两种新的方法来提高对抗样本的可迁移性,即 Nesterov 迭代快速梯度符号方法(NI-FGSM)和尺度不变攻击方法(SIM)。
NI-FGSM 旨在将 Nesterov 加速梯度适应于迭代攻击中,从而有效地预见并提高对抗样本的可迁移性。SIM 方法是基于对深度学习模型的尺度不变特性,利用它来优化输入图像尺度副本上的对抗扰动,以避免对白盒模型的过拟合被攻击并产生更多可转移的对抗样本。

代码链接:
5.2 论文方法
NAG 是在标准梯度下降法中引入一些轻微的改变,它可以加快训练过程并显着提高收敛性。NAG 可以看作是一种改进的动量方法,其可以表示为:
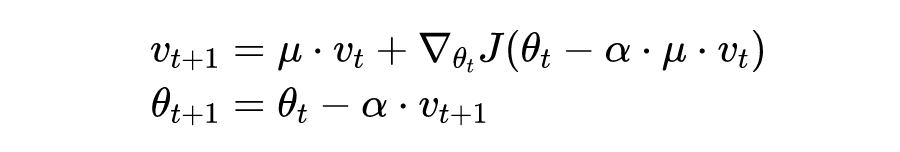
典型的基于梯度的迭代攻击在每次迭代时贪婪地扰乱梯度符号方向的图像,通常陷入较差的局部最大值,并且比单步攻击表现出弱的可迁移性。但有研究表明在攻击中采用动量可以稳定其更新方向,这有助于摆脱陷入不良的局部最大值并提高可迁移性。
与动量相比,除了稳定更新方向之外,NAG 的预期更新对先前累积的梯度进行了修正, NAG 的这种前瞻性特性可以帮助更轻松、更快地摆脱不良的局部最大值,从而提高可迁移性。在该论文中作者将 NAG 集成到基于迭代梯度的攻击中,以利用 NAG 的前瞻性属性并构建强大的对抗性攻击,作者将其称为 NI-FGSM。
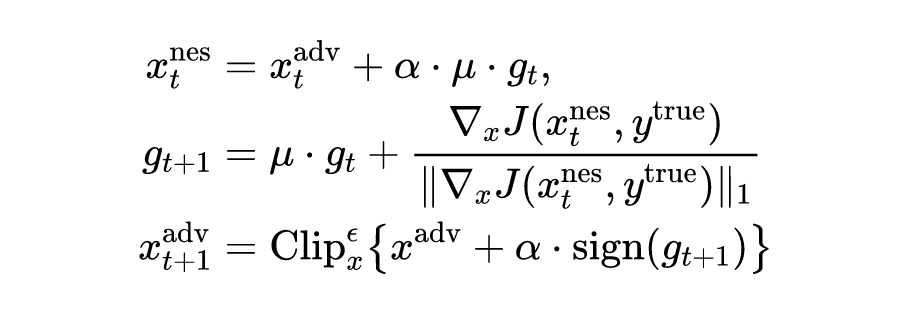
除了为对抗攻击考虑更好的优化算法外,作者还通过模型增强来提高对抗样本的可迁移性。作者介绍了保损变换和模型增强的正式定义如下所示:
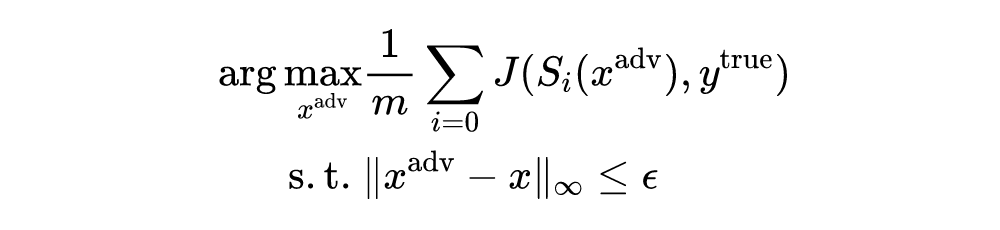


import numpy as np
import torch
import torch.nn as nn
from torch.autograd import Variable
import torch.nn.functional as F
import torchvision
from torchvision import transforms
import matplotlib.pyplot as plt
from torch.autograd.gradcheck import zero_gradients
import os
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.fc1 = nn.Linear(784, 300)
self.fc2 = nn.Linear(300, 100)
self.fc3 = nn.Linear(100, 10)
def forward(self, x):
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
def SI_attack(model, images, labels, alpha, mu, m, T):
x_adv = images.detach()
g_t = torch.zeros_like(images)
loss_fn = nn.CrossEntropyLoss()
epsilon = alpha / T
for t in range(T):
g = torch.zeros_like(x_adv)
x_nes = x_adv + alpha * mu * g_t
for i in range(m):
x_temp = (x_nes / (12**i)).detach()
x_temp.requires_grad = True
outputs_temp = model(x_temp)
loss_temp = loss_fn(outputs_temp, labels)
loss_temp.backward()
g += x_temp.grad.detach()
g = g / m
g_t = mu * g_t + g / torch.unsqueeze(torch.norm(g, p=1, dim=1), 1)
x_adv = torch.clamp(x_adv + alpha * torch.sign(g_t), 0 ,1).detach()
return x_adv
def VMI_attack(model, images, lables, iteration, mu, number, epsilon, alpha):
g = torch.zeros_like(images)
v = torch.zeros_like(images)
x_adv = images.detach()
loss_fn = nn.CrossEntropyLoss()
for i in range(iteration):
x_adv.requires_grad = True
outputs = model(x_adv)
loss = loss_fn(outputs, lables)
loss.backward()
g_prime = x_adv.grad.detach()
g = mu * g + (g_prime + v) / torch.unsqueeze(torch.norm(g_prime + v, p=1 , dim=1),1)
grad_temp = torch.zeros_like(x_adv)
for k in range(number):
x_temp = x_adv.detach() + (torch.randn(x_adv.shape)-0.5) * 2 * epsilon
x_temp.requires_grad = True
output_temp = model(x_temp)
loss_temp = loss_fn(output_temp, lables)
loss_temp.backward()
grad_temp += x_temp.detach()
print('grad_temp:', grad_temp.shape)
v = grad_temp / number - g_prime
x_adv = x_adv + alpha * torch.sign(g)
x_adv = x_adv.detach()
print('x_adv:', x_adv.shape)
return x_adv
def AOA_attack(model, input_x, labels, alpha, target):
delta = torch.zeros_like(input_x)
input_x.requires_grad = True
# Compute CrossEntropyLoss
outputs = model(input_x)
if target == 'untarget':
loss1 = nn.CrossEntropyLoss()(outputs, labels)
grad1 = torch.autograd.grad(outputs[0][labels], input_x, retain_graph = True, create_graph=True) # source map
one_hot_labels = torch.eye(len(outputs[0]))[labels]
sec_labels = torch.argmax((1-one_hot_labels)*outputs)
grad2 = torch.autograd.grad(outputs[0][sec_labels], input_x, retain_graph = True, create_graph=True) # second map
# Compute Log Loss
loss2 = torch.log(torch.norm(grad1[0],p=1)) - torch.log(torch.norm(grad2[0], p=1))
# AOA loss
loss = loss1 - alpha * loss2
delta = torch.autograd.grad(loss, input_x, retain_graph = True)
else:
loss1 = nn.CrossEntropyLoss()(outputs, labels)
grad1 = torch.autograd.grad(outputs[0][labels], input_x, retain_graph = True, create_graph=True) # source map
one_hot_labels = torch.eye(len(outputs[0]))[labels]
sec_labels = torch.argmax((1-one_hot_labels)*outputs)
grad2 = torch.autograd.grad(outputs[0][sec_labels], input_x, retain_graph = True, create_graph=True) # second map
# Compute Log Loss
loss2 = torch.log(torch.norm(grad2[0],p=1)) - torch.log(torch.norm(grad1[0], p=1))
# AOA loss
loss = loss1 + alpha * loss2
delta = torch.autograd.grad(loss, input_x, retain_graph = True)
return torch.clamp(delta[0], 0 , 1)
if __name__ == "__main__":
# Define data format
mnist_transform = transforms.Compose([transforms.ToTensor(), transforms.Lambda(lambda x : x.resize_(28*28))])
testdata = torchvision.datasets.MNIST(root="./mnist", train=False, download=True, transform=mnist_transform)
testloader = torch.utils.data.DataLoader(testdata, batch_size=8, shuffle=True, num_workers=0)
# Load model parameters
# net = torch.load('mnist_net_all.pkl')
net = Net()
alpha = 1
target = 'target'
for step, (batch_x, batch_y) in enumerate(testloader):
for idx in range(batch_x.shape[0]):
image = batch_x[idx].view(1,-1)
label = torch.unsqueeze(batch_y[idx],0)
adversarial_examples = image + AOA_attack(net, image, label, alpha, target)
print(adversarial_examples)
更多阅读




#投 稿 通 道#
让你的文字被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
📝 稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
📬 投稿通道:
• 投稿邮箱:hr@paperweekly.site
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿

△长按添加PaperWeekly小编
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧


