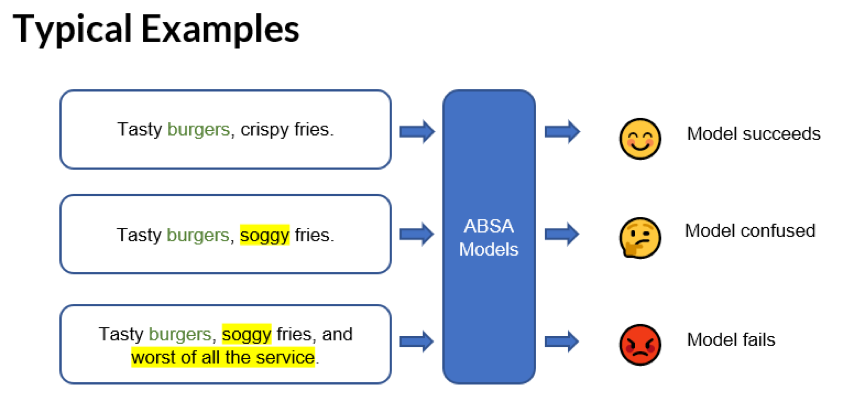
细粒度情感分析中,为什么“好吃的汉堡”被识别为负向情感?

1
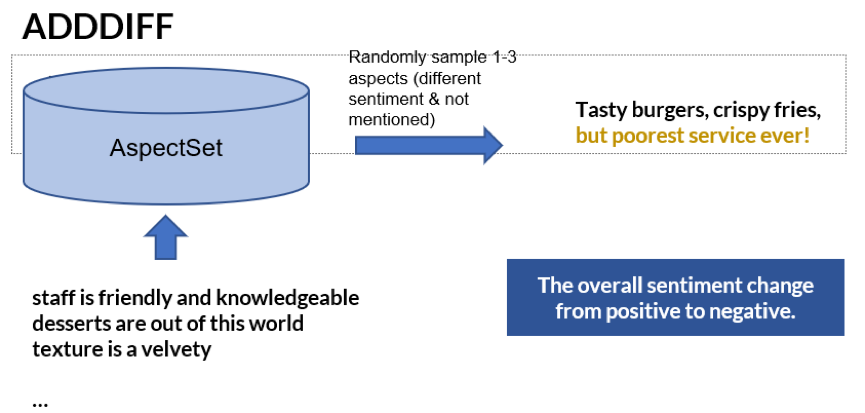
生成数据的方法介绍

2
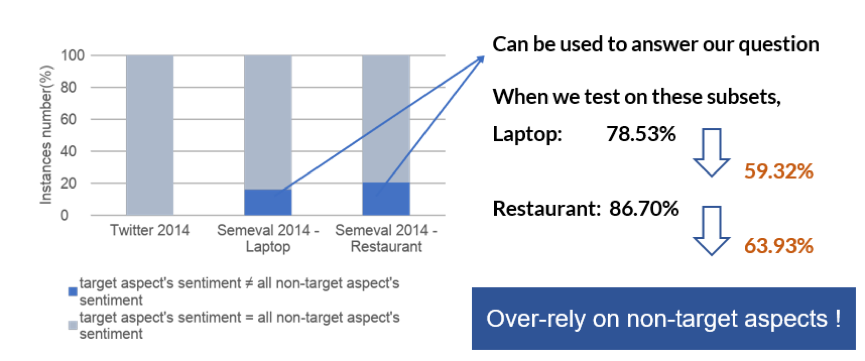
数据集的对比分析
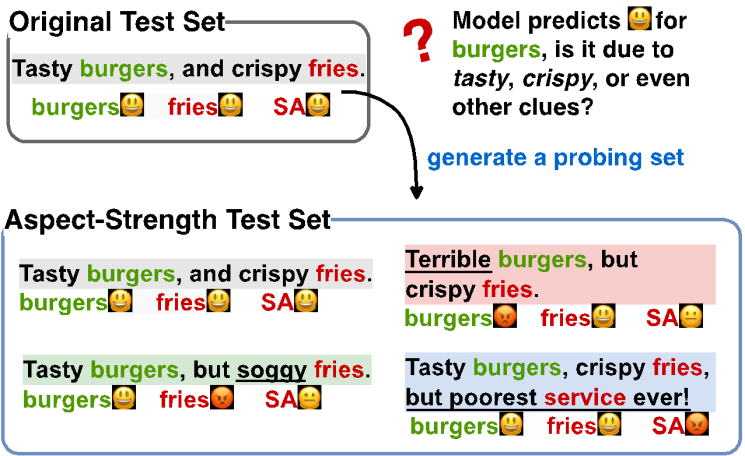


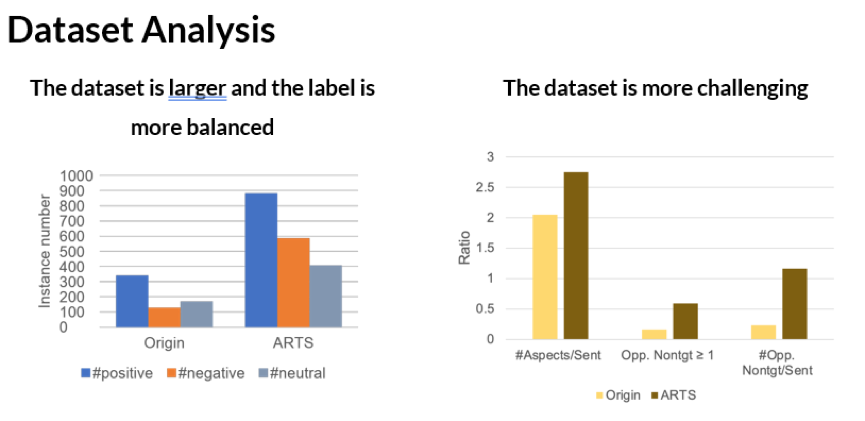
3
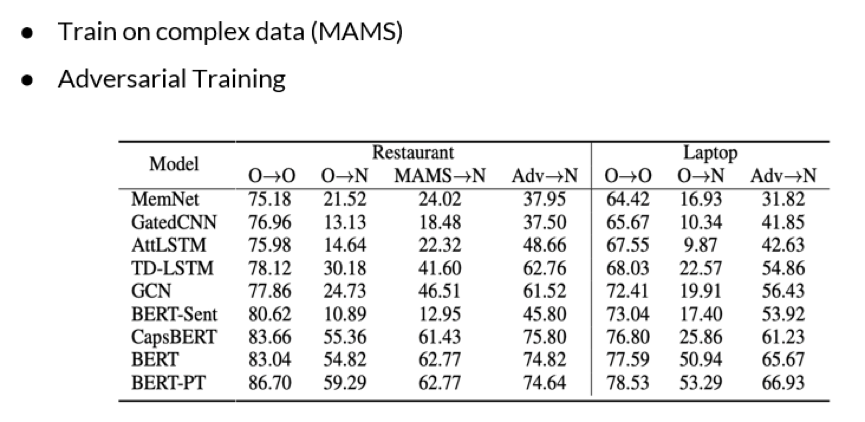
实验结果讨论与分析

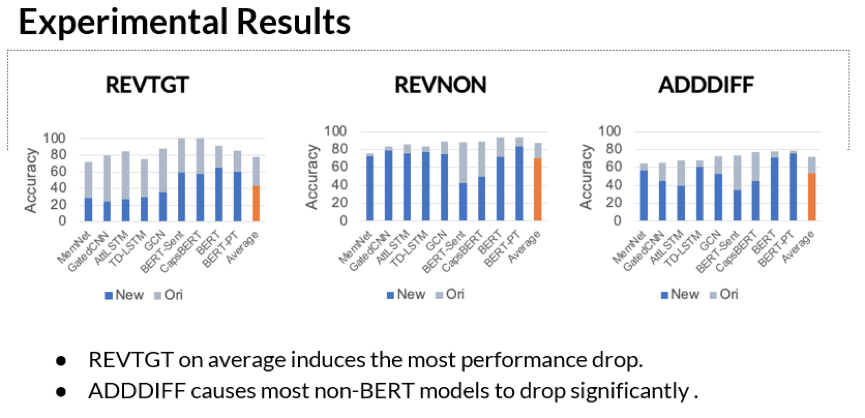
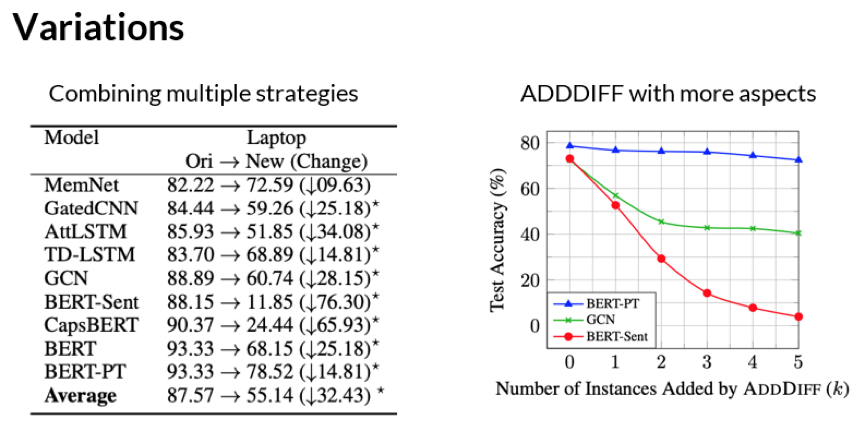
4
如何提升模型的鲁棒性
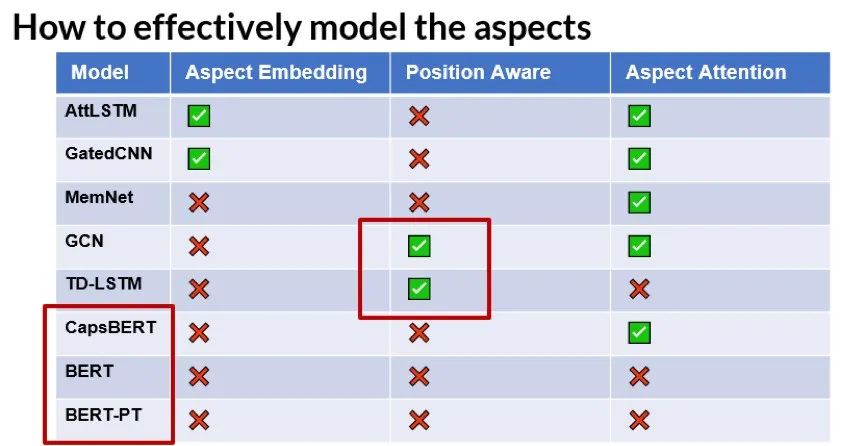
5
总结

由于微信公众号试行乱序推送,您可能不再能准时收到AI科技评论的推送。为了第一时间收到AI科技评论的报道, 请将“AI科技评论”设为星标账号,以及常点文末右下角的“在看”。
登录查看更多
相关内容

Arxiv
6+阅读 · 2020年3月1日
Arxiv
10+阅读 · 2019年9月5日
Arxiv
8+阅读 · 2019年3月22日
Arxiv
4+阅读 · 2018年5月9日





相关VIP内容
相关资讯
相关论文
Arxiv
6+阅读 · 2020年3月1日
Arxiv
10+阅读 · 2019年9月5日
Arxiv
8+阅读 · 2019年3月22日
Arxiv
4+阅读 · 2018年5月9日