腾讯内容结算下一代系统探索实践

腾讯内容结算平台作为 PCG 中台服务,主要负责公司各渠道内容相关的结算业务,为内容创作者提供收益计算、发放、提现等服务。经过多年的发展,已安全高效地承接了数千个结算项目,结算资金规模较大,涵盖了内容采买、流量计费、直播带货、内容电商等相关领域,业务合作方包括腾讯视频、微视、QQ 浏览器、腾讯新闻、腾讯内容开放平台等。
本文将从标准化、框架两个方面介绍腾讯内容结算系统在建设与实践中的思考与落地方案。
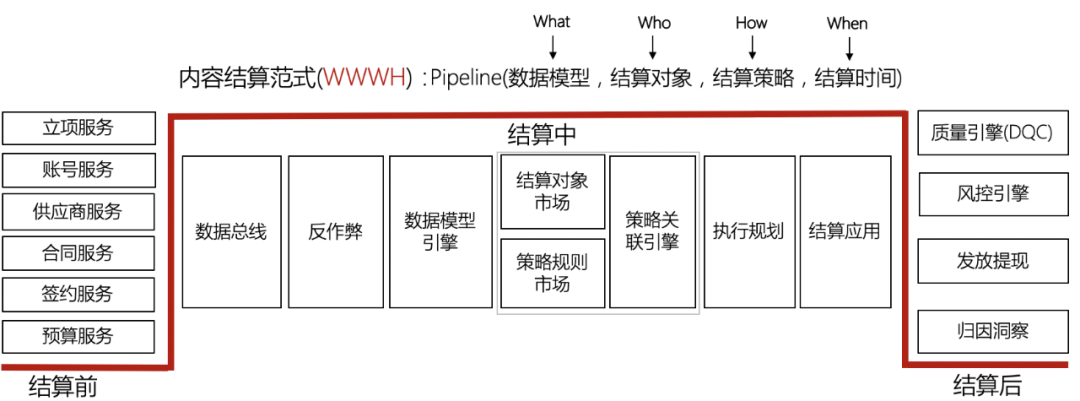
从业务层角度而言,一个项目的结算过程可以分为以下几个步骤:立项、签约、数据接入、数据模型、策略配置、收益计算、收益发放、洞察归因等过程。如下图所示:

从技术角度出发,面对大量复杂多变的结算项目场景,如何通过技术架构优化对结算的关键核心环节进行降本增效是我们关注的问题,比如,通过自动化准入机制和可视化模型配置解决前期数据耗时耗力的问题;利用原子化抽象、插件化复用,DAG 编排乐高式组装提高项目自助化能力;针对计算执行规划串并行优化 Lambda 语义表达;面对项目后期大量的收益分析,采用贡献度模型自动化归因洞察收益的波动。
在业务迭代的过程中,从研发视角看,随着新场景的不断接入,以及原有功能的迭代,系统变得越来越复杂,需求响应逐渐变慢;从用户视角看,配置复杂的结算策略,以及传承结算业务逻辑,越来越低效。以降本提效为目标,我们对系统架构进行了多次迭代,在业务发展前期,开展过单模块的重构,如策略配置、指标服务等,虽然对效率提升有一定的改善,但是还会存在以下问题:
1. 数据接入:
无系统管理历史接入记录,无法追溯变化;
人工离线验收,多轮次反复沟通,数据验收耗时较长;
2. 数据模型:
数据模型按不同项目编码实现,模型变更需改代码,上线周期长;
新增指标字段需在原表加字段,会导致表的字段越来越多,且包含大量只用一次的字段;
需研发同学强参与,无法自助化、自动化、平台化解决;
3. 策略配置:
历史因素,标类和非标采用不同的策略配置模块,从而导致后续收益计算等需要分别开发,成本高;
策略配置的灵活度不够,部分逻辑没法配置,需要研发手动来开发相应的代码;
策略分布碎片化,无全局可视化视野,无法直观看到一个项目结算策略的全逻辑;
4. 收益计算:
收益计算分标类和非标两套代码,维护成本较高;
规则计算的执行顺序写死,不可界面配置化;
针对以上的问题,我们从 2022 年初,启动下一代结算系统的优化升级,基于 DDD 领域驱动,打造下一代高自助化、高扩展性、高一致性、高全局性的内容结算中台架构,旨在通过平台化、自助化达到以下 4 个目标:
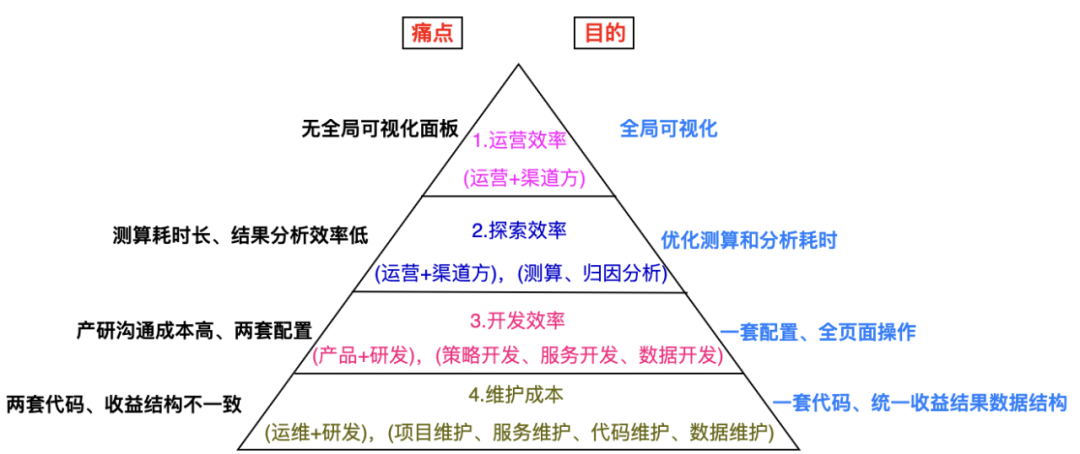
1. 提升运营效率
运营同学可通过可视化页面,看到项目的全生命周期流转,助力项目迭代和传承;
2. 提升探索效率
统一并优化策略测算、策略实验的功能;
提供多维度自动归因分析洞察能力;
3. 提升开发效率
原子化表达结算语义,同功能的模块可复用,避免重复开发;
通过插件模式,使得业务同学能参与协同共建;
4. 降低维护成本
在统一配置策略后,一套代码做到自动解析、计算;
平台化 的主要思想是,流程编排与领域知识原子化,业务插件与平台系统插件分离的插件化架构,业务形式如下图所示。目标是可以让业务运营 自助化 操作,让业务研发参与数据模型和插件共建,提高中台生产力,从而更多精力投入平台优化迭代上。
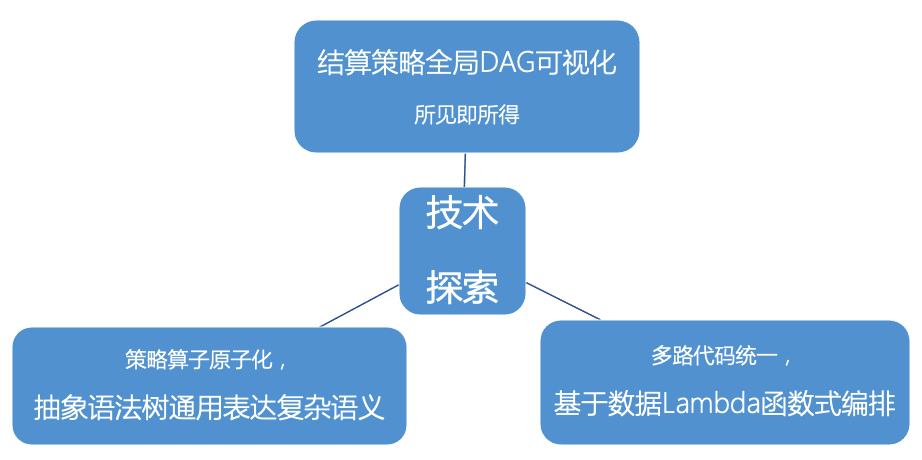
从技术上来说,平台化主要做了以下几个探索:结算策略全局 DAG 可视化,策略算子原子化,多路代码统一,如下图所示:
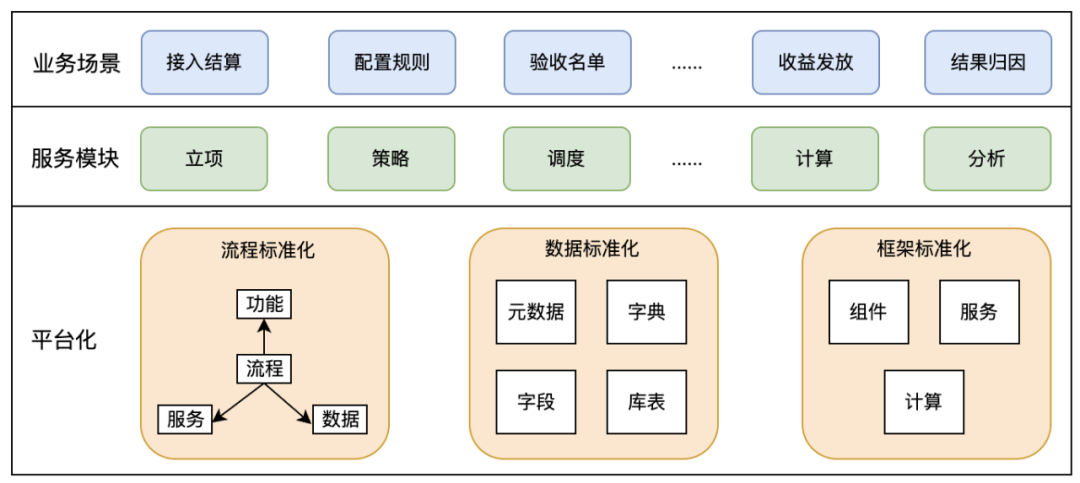
然而只有先做到标准化,平台才能顺利的运转起来,因此在平台化启动前,我们对业务进行了梳理和抽象,从下面三个方面进行标准化建设。
综合标类与非标结算,我们将结算分成三步:结算前、结算中、结算后。其中结算前包括立项、预算占用、供应商录入、合同签约、策略配置,这些步骤在项目初期还未开始结算时就都配置好。结算中包括数据接入、模型配置、任务调度、收益计算、结果双校,这些是收益计算的过程。结算后包括收益发放、数据报表、客诉服务,这些是在收益计算完成后的过程。并非每个项目都要走完这里的所有流程,通过立项时的配置某些环节可以被跳过。
结算平台中逻辑的流转即数据的流转,因而只有数据标准化后,平台框架才能运转。系统接入的数据分为三类:指标数据、名单数据、策略数据,其中指标数据用于收益计算和条件判断,名单数据用于对象圈定和收益发放,策略数据用于链接指标和名单。数据标准化的方式主要包括:字典标准化、字段标准化、数据表标准化,相同枚举值全局唯一、相同含义的字段名全局唯一、数据表名分段式代表业务含义等。
框架标准化主要分为两个方面:底层规范、功能模块。底层规范主要包括统一代码风格、基础库、日志规范等;功能模块主要指按功能进行微服务拆分,分为数据模型、策略插件、调度服务、计算服务等模块,模块内部高内聚,模块间低耦合,服务间通过微服务调用,不允许直接访问数据库等。
平台化的实现按项目阶段可分为三部分:结算前、结算中、结算后,从技术角度来看可分为两部分:后台服务、数据服务。其中结算前主要是后台服务,结算中包括了后台服务和数据服务,结算后也主要是后台服务。
结项前主要包括立项、预算占用、录入供应商、合同签约等环节,我们按照每个环节进行微服务拆分,服务之间通过 rpc 接口进行调用。内容生产者只有录入公司供应商系统后,才能进行电子合同签约,且占用了预算后该项目才能发放收益。收益发放前,会进行大量的在线风控监测,保障系统安全。
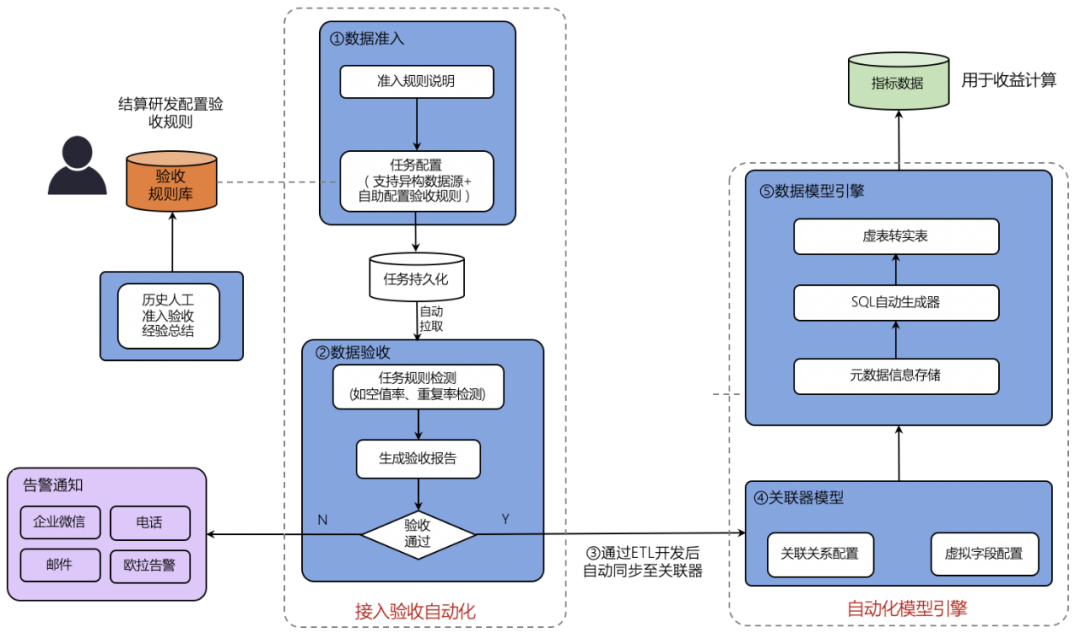
数据接入是结算中的第一步。平台接入的数据包括指标数据和名单数据,目前支持公司大数据平台的离线数据表和 Excel 上传的方式,接入数据作为结算数仓的 ODS 数据,会经过一次 ETL 的过程,产生 DWD 层数据,该层数据的元数据信息会被导入模型配置系统中,用于数据模型的配置。
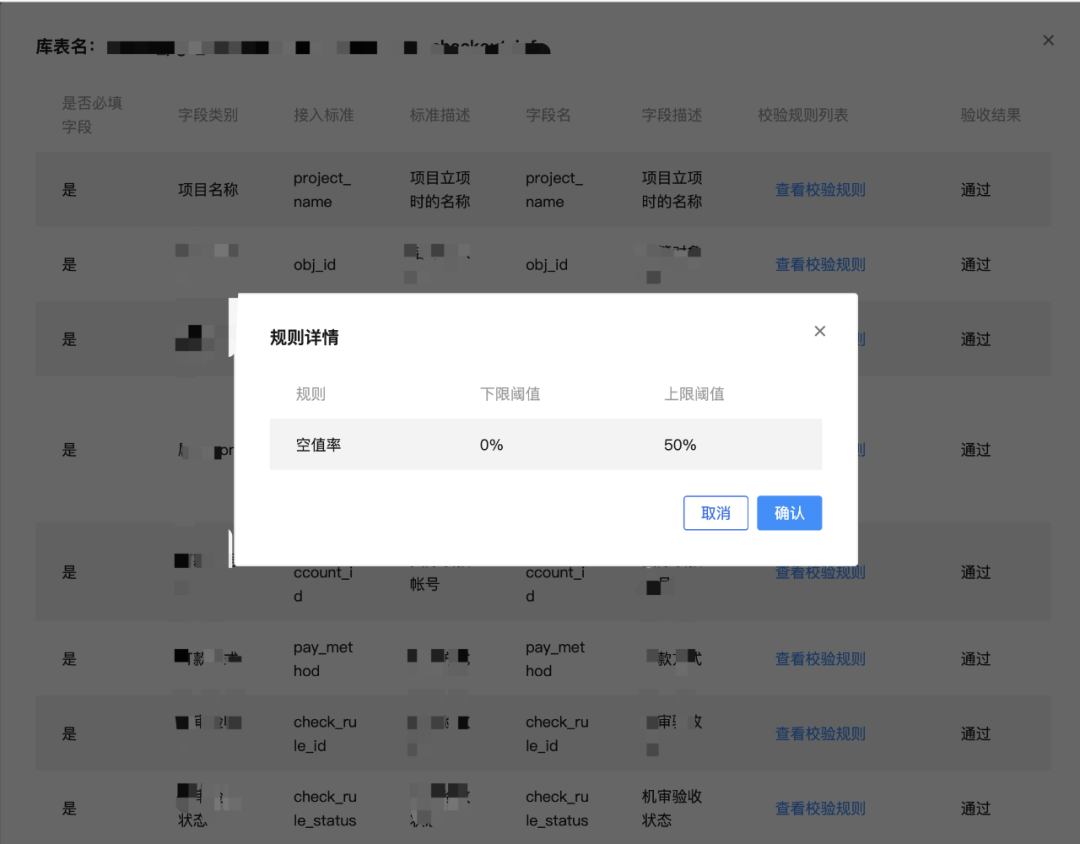
数据校验:通过对历史接入数据的梳理,我们总结出 11 种数据校验和质量规则,如:空值率校验、重复值校验、波动校验等,整体如下图所示:
结算平台提供了校验能力来检测数据是否符合平台接入标准,并对后续数据进行质量监控和告警。用户在系统上配置数据的验收规则,提交任务一段时间后会收到数据的验收结果,告知是否符合平台标准,系统界面如下图所示:
数据模型的目标是解决数据最后一公里的问题。其输入是经过 ETL 之后的业务数据,其输出数据用于结算策略的配置、收益计算、报表分析。数据模型的配置页面,其功能包括配置衍生字段、配置数据表 Join 关联关系,然后通过定时任务拉取元数据信息到结算平台,再对外提供接口服务。模型配置 示例如下:
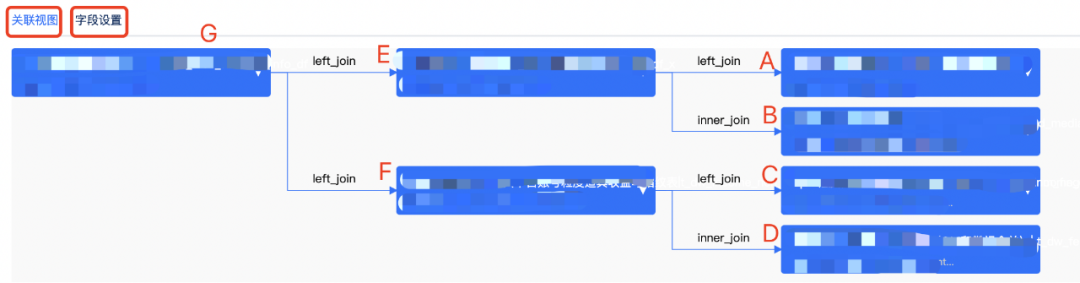
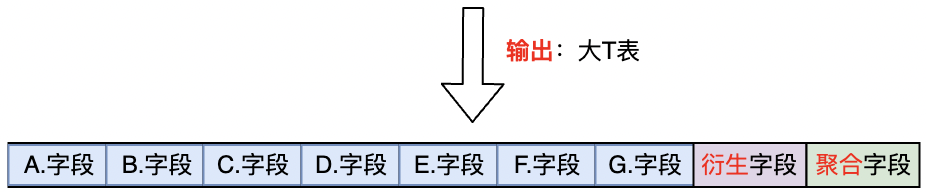
模型执行:模型是从叶子节点开始执行的,每个父节点和它所有的子节点 join 成一个临时表,然后递归往上执行,一直到根节点,最后将所有字段作为分组维度,对聚合指标进行聚合,生成大 T 表供收益计算使用。上图中配置的模型,其执行过程如下:
create table T asselectG. 字段, E. 字段, A. 字段, B. 字段,F. 字段, C. 字段, D. 字段, 衍生字段 1, 衍生字段 2, 衍生字段 1, 衍生字段 2from(selectG. 字段, E. 字段, A. 字段, B. 字段,F. 字段, C. 字段, D. 字段, 衍生字段 1, 衍生字段 2fromG left join(selectE. 字段, A. 字段, B. 字段fromE left join A on E.* = A.*join B on E.* = B.*) E' on G. 字段 = E'. 字段left join(selectF. 字段, C. 字段, D. 字段fromF left join C on F.* = C.*join D on F.* = D.*) F' on G. 字段 = F'. 字段) tmpgroup byG. 字段, E. 字段, A. 字段, B. 字段,F. 字段, C. 字段, D. 字段, 衍生字段 1, 衍生字段 2
数据接入和数据模型一起构成了数据自动化模块,只需通过平台操作就行,整体流程如下图所示:
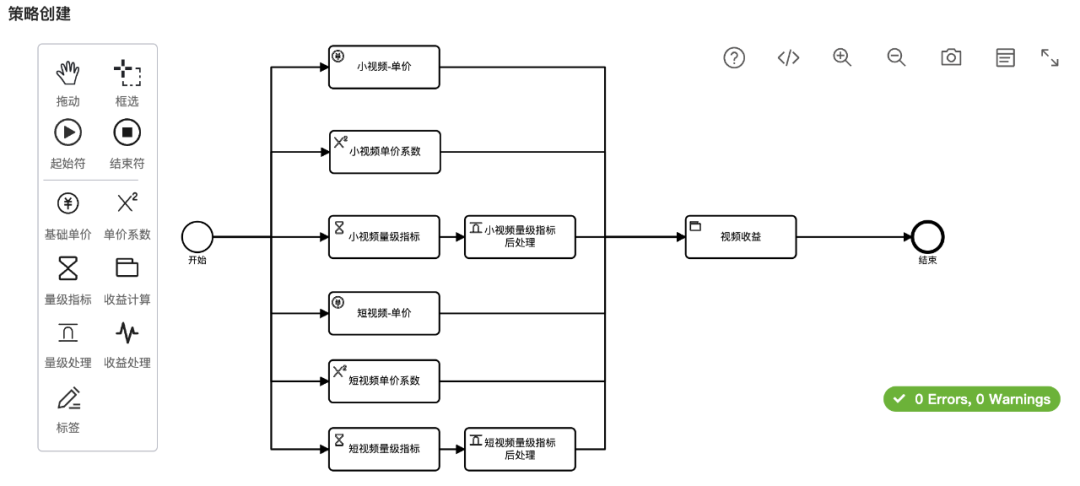
结算策略的配置是对收益计算过程的描述,是结算项目的核心,其语意描述能力是衡量配置能力的标准。我们在设计之初,定下两个目标:协议的描述能力要灵活可扩展、协议要与实现无关来确保插件式架构。为此我们分析了系统中所有的项目,通过对所有结算策略进行抽象,概括出其模式,然后进行原子化分解,最终以 插件表达式 和 流程编排 的方式来描述结算策略。
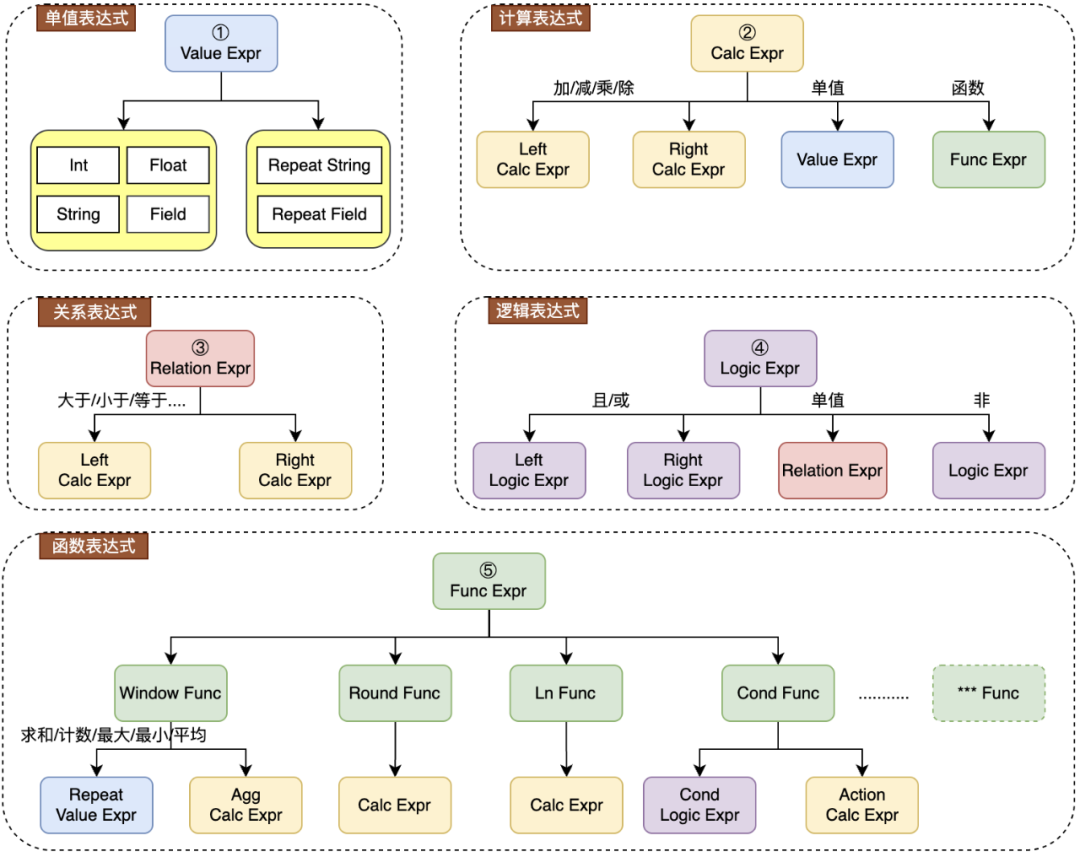
插件表达式:插件可以理解成一个表达式计算,我们借鉴了 SQL 引擎的 ExpressionTree 方案。表达式的定义通 pb 协议描述,我们将表达式分为 5 种基础类:①单值表达式、②计算表达式、③逻辑表达式、④关系表达式、⑤函数表达式,其中函数又可以细分成多种,表达式之间可以进行嵌套、组合,从而其描述能力是可扩展的。之所以抽象成 5 种类型,主要是参考了 SQL 的语法元素,并考虑结算业务的需要,目标是能覆盖所有的策略场景,并以结构化的形式表现出来。
流程编排:结算策略是插件的 DAG 组合。结合策略需要,我们定义了 6 种插件,每种插件表达式的输出是一种类型的变量,分为:单价插件、单价系数插件、量级插件、量级处理插件、收益插件、收益处理插件。在可视化页面上通过拖拽的方式将插件编排成 DAG 图,后面的插件可以引用前面插件的输出结果作为输入变量,DAG 的结束节点必须为收益插件,其结果用作收益发放的金额,这样就构建出一个结算策略了。
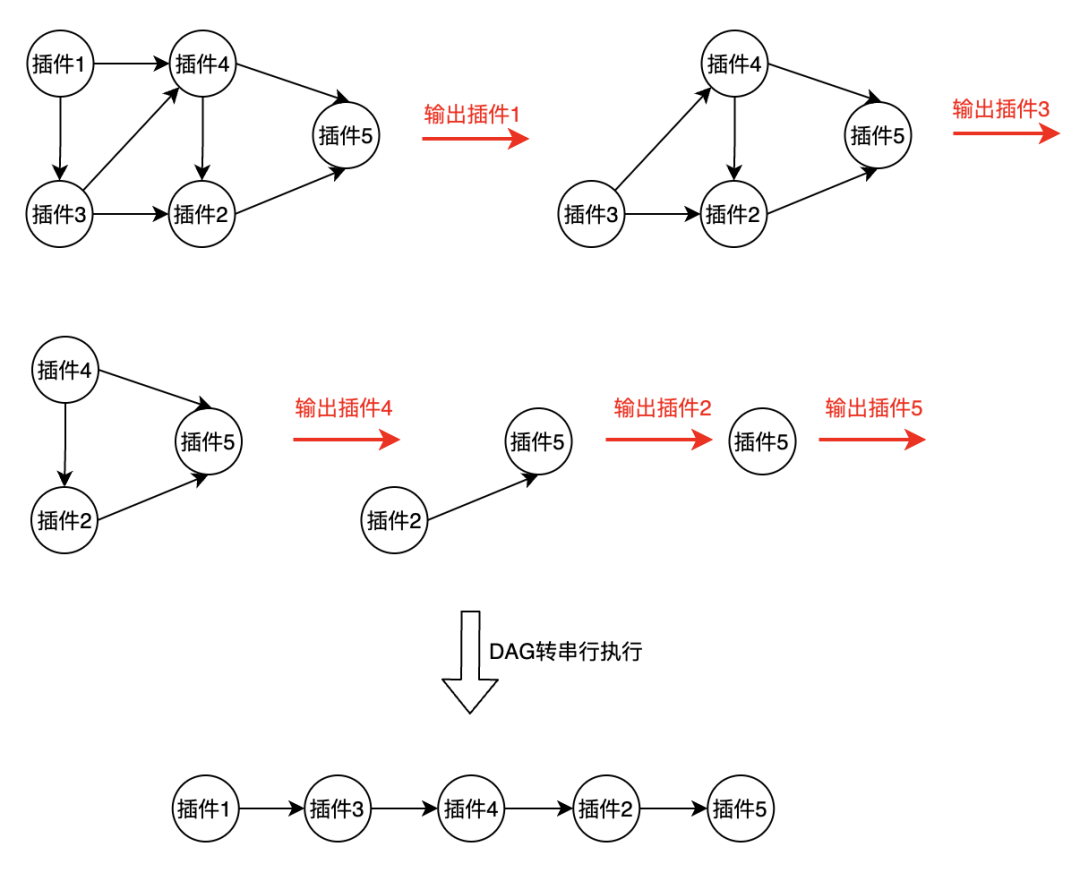
收益的计算过程就是 DAG 的执行过程。收益计算主要分成三步,第一步是 DAG 转串行执行,第二步是解析插件 DSL 生成一个 SparkSQL 引擎能执行的表达式,第三步是按调度顺序串行顺序执行每个表达式,并将结果保留成变量。
DAG 的执行是图中插件的顺序执行过程,倘若一个插件的上游有两个节点,则其需要等这两个插件都执行完才能计算,且依赖这两个插件的计算结果。上游的两个插件彼此没有依赖关系,在逻辑上可以并行执行。结算的输入为离线数据集,由于该插件需聚合上游两个插件的结果,因此需要离线数据的 join 操作才能完成。而 join 操作需要知道关联条件,且数据并不一定具有唯一主键,带来了笛卡尔积的风险,而且 join 操作会耗费大量的 shuffle 资源,带来性能损耗。
DAG 转串行执行:由于插件没有改变数据集的粒度,相当于在原数据集上添加新的列,因而可以采用串行执行的思路来规避 join 的出现。调度系统通过拓扑排序对 DAG 中的插件进行排序,然后串行执行每个插件,一次只执行一个插件,上游插件在执行完毕后将结果作为中间变量传递给下游,从而保障了下游插件在计算前上游插件都已经计算完毕。由于插件使用到了集合指标作为表达式输入,因此不能按条执行每条数据,为了简化计算我们全链路采用 SQL 表达式进行集合计算。这样既避免了数据 join 的操作,也在同等语意下节省了计算资源。
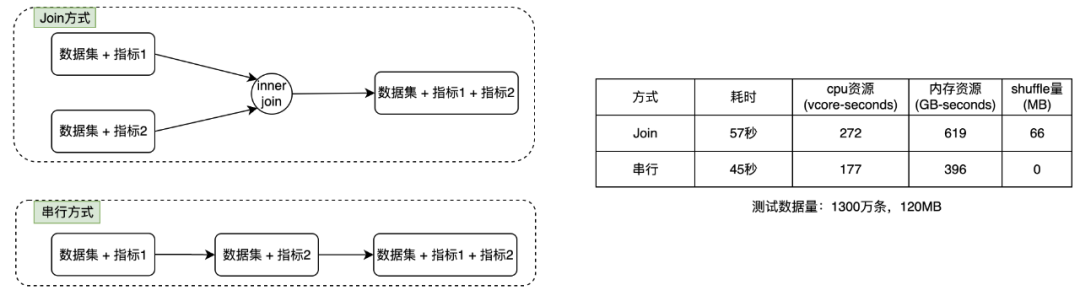
为了证明串行执行的性能更佳,我们也做了简单的实验来进行对比,从耗时、内存消耗、cpu 消耗三个维度进行对比分析,如下图所示,可以看到串行执行的性能全面优于 Join 执行。
插件解析:插件解析是一个多叉树的深度优先遍历过程,每个子 Expr 输出的表达式片段会通过括号括起来,来保障顺序的准确性。插件 DSL 翻译成 SQL 的代码统一放在 common-plugin 工程目录下,每个插件会有一个目录,如:price-plugin、income-plugin 等,通过调用 common-plugin 提供的函数生成其对应的 SQL 片段。之所以每个插件还需要其自己的目录,主要考虑到后续每个插件可能会有定制化的操作等。
DAG 计算:插件的执行通过 Spark 调用 Lambda 表达式来实现。每个插件的执行就是一次 Lambda 表达式调用 SQL-piece 的过程,按照上文中调度引擎解析的顺序串行执行每个 SQL-piece,计算的输入集是数据模型输出的大 T 表,每次执行的结果都作为中间临时表,最后一个 SQL-piece 的结果作为收益数据,用于打款发放。整体的查询规划及计算过程如下图所示:
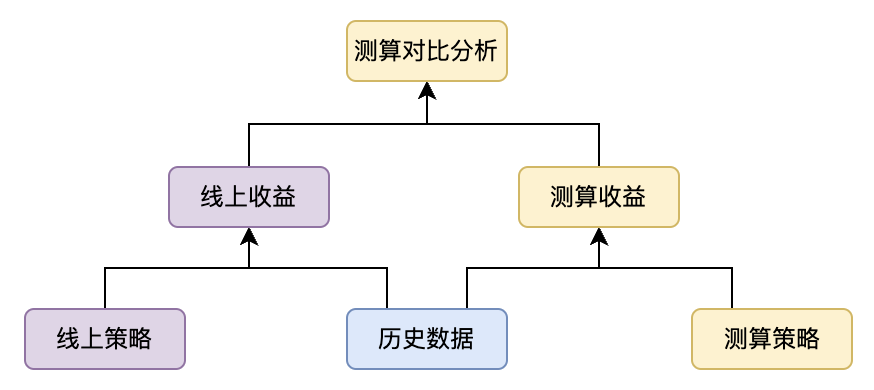
策略测算是策略迭代生效前的评估,使用历史数据加业务新策略来计算收益,再将收益和历史线上收益作对比,以此来评估新策略带来的影响。结算平台在收益计算完毕之后会自动生成同步任务,将结果同步到 BI 分析平台,这样用户就可以使用 BI 工具对结果进行分析了。
任何项目的结算都是由平台方和双校方一起计算的,然后拿两边的结果按 cp 维度进行比较,单 cp 误差控制在极小阈值范围内才认为双校通过。平台方生成的明文数据用作账号收益展示,也会推送到公司财经系统进行打款,双校方会生成收益指纹数据,该数据被财经系统用作收益对账,主要是防止数据被中途篡改,同时,收益发放支持按比例灰度发放机制。
1. 运营效率的提升:
全链路可视化,运营效率提升 30%+;
2. 探索效率的提升:
测算优化,速度提升 60% 以上;
全链路的归因分析,减少 80% 波动定位时间;
3. 开发效率的提升:
数据模型可配置化,手动升级成自助配置化;
非标标类统一建设,研发效能提升 50%;
4. 维护成本的降低:
策略即代码,杜绝硬编码,系统维护成本降低 50%;
本文从标准化、框架两个方面介绍腾讯内容结算系统在建设与实践中的思考与落地方案。经过不断的摸索建设和实践,结算平台化已初具规模、有力地支撑了多条业务线的快速迭代。
未来,平台化会细化标准化的粒度度,降低业务开发同学成本;深化框架能力,在稳定性、性能、易用性方面持续进行提升。此外,我们在产研新流程方向也会持续优化用户体验,完善运营机制,不断提升产研迭代的流程。
作者介绍
王冬,腾讯内容开放平台结算研发团队技术负责人,10 多年后端架构领域和大数据领域实践经验,长期关注微服务技术、大数据技术、分布式系统等。
张鹏,腾讯内容开放平台结算团队后端研发工程师,主要负责结算系统的平台开发,对微服务、大数据等相关技术领域感兴趣;
董浩,腾讯内容开放平台结算团队后端研发工程师,主要负责结算系统相关研发工作,对后端技术架构较为熟悉。
最后感谢 kyler, richard, stan, vivienne 的支持,感谢腾讯内容开放平台结算研发团队、结算产品团队、平台研发中心以及相关每一位共同付出的成员。
河南赋红码事件程序员不背锅;马斯克:向TikTok和微信学习;华为宣布将调整绩效考核指标 | Q资讯

点个在看少个 bug 👇
