StarGAN - 图像到图像的翻译

本文为 AI 研习社编译的技术博客,原标题 :
StarGAN — Image-to-Image Translation
作者 | Pranoy Radhakrishnan
翻译 | tobepellucid
校对 | Pita 审核 | 酱番梨 整理 | 立鱼王
原文链接:
https://towardsdatascience.com/stargan-image-to-image-translation-44d4230fbb48
注:本文的相关链接请访问文末【阅读原文】

StarGANs用来做什么?
通过输入来自两个不同领域的训练数据,StarGANs模型可以学习将某一个领域的图片转换成为另一个领域。
例如,把一个人的发色(属性)从黑色(属性值)转换成棕色(属性值)。
我们把领域定义为拥有相同属性值的一系列图片。黑色头发人群是一个领域,棕色头发人群则是另一个领域。
StarGAN(星型生成式对抗网络)
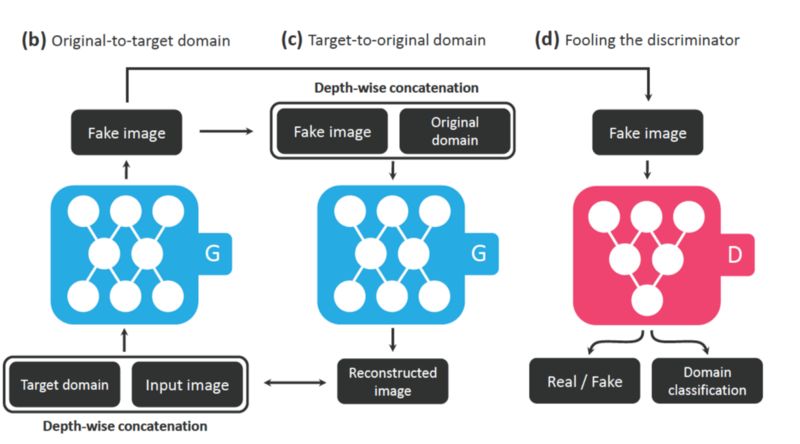
生成器把图像和目标领域标签作为输入,生成一张非真实的图像.(b)
生成器试图根据所给的原始领域标签,把非真实图像重构为原始图像。
这里,为了生成器能够产生与真实图像难以区分的图像且该图像可以被判别器分类为目标领域,判别器不仅要区分非真实性,而且要对一张图像作出它相应领域的分类。也就是说,生成器将最终学到可以生成对应于所给目标领域的真实图像。(d)
判别器的目标
这里的判别器有两个任务:
它应该能够鉴别一张图像真实与否。
在位于判别器顶部的辅助分类器的帮助下,判别器也可以预测输入给它的图像的对应领域。
辅助分类器的作用是什么?
有了辅助分类器,判别器能够学习到原始图像的映射以及它在数据集中所对应的领域。当生成器产生一张指定目标领域c(比如棕色头发)的新图像时,判别器可以预测所产生的图像的领域。因此生成器会产生新图像直到判别器给出对应的目标领域c(棕色头发)的预测为止。
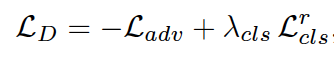
判别器的损失函数
生成器的目标
这里的生成器有三个目标:
为了生成图像接近真实,生成器的权重会被不断调整。
为了生成图像能够被判别器鉴定为目标领域,生成器的权重会被不断调整。
生成器将根据所给原始领域标签把生成的非真实图像重构为原始图像。我们将使用单一的生成器两次,第一次把原始图像翻译成目标领域的图像,第二次把翻译图像再重构成原始图像。
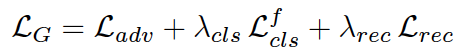
生成器的损失函数
数据集
CelebA. 名人脸部属性(CelebA)数据集包含了202,599张明星的脸部图像,每张都被标注了40个二分类属性。
拉德堡德脸部数据库(RaFD)由收集自67位参与者的4,824张图像组成,每位参与者在三个不同的注视方向上做了八种脸部表情,拍摄于三个不同的角度。
参考
StarStarGAN: Unified Generative Adversarial Networks for Multi-Domain Image-to-Image Translation
想要继续查看该篇文章相关链接和参考文献?
点击底部【阅读原文】即可访问:
https://ai.yanxishe.com/page/TextTranslation/1611
AI求职百题斩 · 每日一题


点击阅读原文,查看更多内容




