FreeWheel 全球范围 Kafka 集群上云实践

Kafka 凭借其高吞吐量、高可靠等特性一直是数据领域重要的消息中间件,云厂商消息队列的推出,促使越来越多的企业从自建迁移上公有云。那么将 Kafka 部署到公有云需要怎么做?它的弹性伸缩、容灾能力怎么样?成本如何控制?
本文将以 FreeWheel 的 Kafka 服务迁移上 AWS 为例,阐述 Kafka 在迁移公有云方面的实践过程,解答上面的问题,也希望可以给大家带来启发。
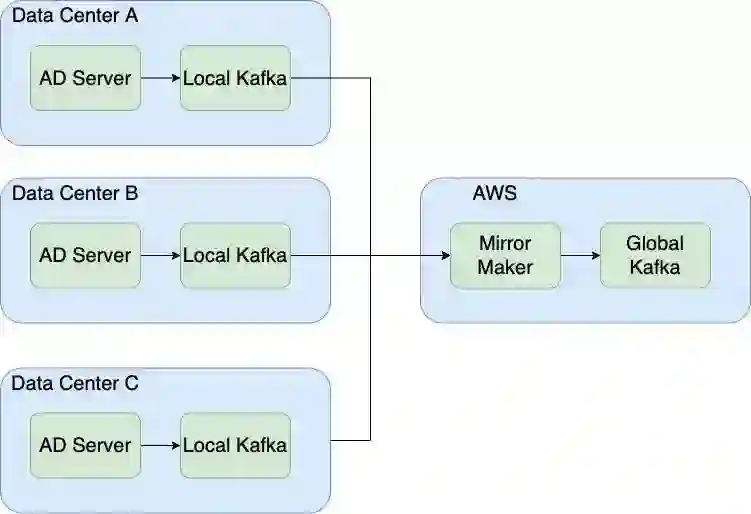
首先介绍一下 Kafka 在 FreeWheel 的应用场景。FreeWheel 是一家广告投放公司,我们的主要产品是广告投放系统。用户在浏览广告时会产生一些业务数据,我们使用 Kafka 作为处理和分析这些数据的数据总线。我们的广告服务器部署在全球 10+ 个数据中心,是一个 On-Prem 和 AWS 混合云的架构,Kafka 集群和这些服务器部署在一起。我们使用 Mirrormaker 将多个 DC 的广告日志数据同步到 AWS 的 Global Kafka 集群进行统一处理。如下图所示,在单个 DC 部署的 Kafka 集群,简称为 Local Kafka,中心数据集群为 Global Kafka。本文主要论述的是混合云架构上 Kafka 的治理经验。
既然选择了 AWS,读者肯定会问:如何利用 AWS 的原生服务来支持 Kafka?本章就来介绍我们使用 AWS 的原生服务来提升 Kafka 运维、弹性伸缩和容灾能力的秘诀。
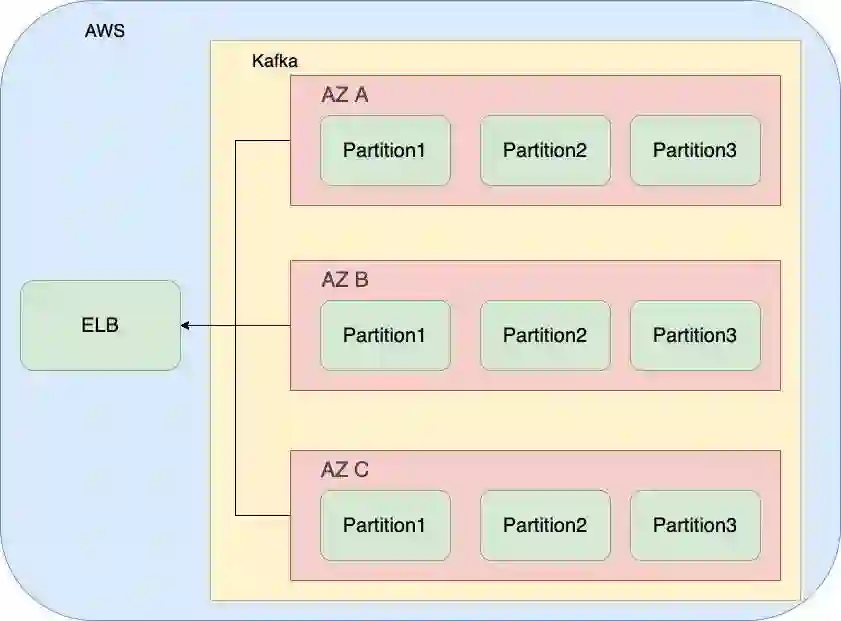
首先讲讲我们的部署方式。与在实体服务器上部署应用不同,在 AWS 上部署应用可以使用一些云服务厂家提供的独特能力来减轻运维的压力。ASG(Auto Scaling group) 是一些机器实例组成的运算组。ELB(Elastic Load Balancing) 是 AWS 提供的负载均衡服务,它可以绑定在 ASG 上。Route53 是 AWS 提供的域名解析服务。我们根据这些组件设计了 Kafka 的部署方案:将 Kafka 机器实例启动在三组 ASG 里面 (部署三组 ASG 的原因在本文论述容灾的部分),然后将一个 ELB 绑定这些 ASG。最后将 ELB 绑定在一个 Route53 上面。这样一个带有负载均衡与固定域名的 Kafka 集群就搭建好了。
突发流量是个令人头痛的问题,处理不好可能对整个服务的稳定性产生致命影响。然而云上部署最吸引人的特点就是弹性计算,我们可以利用这个特点来轻松的应对突发流量。
FreeWheel 的客户主要位于北美和欧洲,因此在这些地方发生一些重大事件或者体育赛事 (比如超级碗或者美国大选) 的时候会产生突发流量。此时需要考虑扩容 Kafka。对于这种短时间内增加的流量,我们会调整 Kafka 的机型。只需要更换更大的机型再轮番重启 Kafka,就可以实现弹性缩扩容。
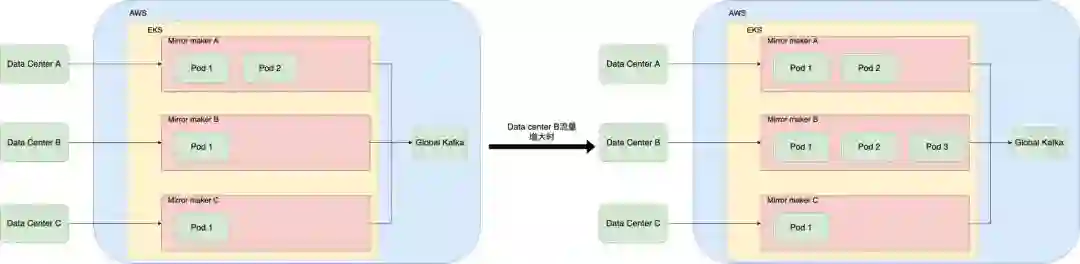
EKS(Elastic Kubernetes Service) 是 AWS 实现的 K8S 托管服务。我们把 Mirrormaker 部署在 EKS 上。每一个 Local Kafka 的流量是不同的,因此我们对 Mirrormaker 进行了差异化的配置。对于流量大的数据链路,我们配置了更多的 Pod 和 CPU 数量。当突发流量到来时,使用 EKS 可以快速扩充 Mirrormaker 的数据同步能力。如下图所示,当位于 Data Center B 中的 Local Kafka 的流量增大时,我们可以通过修改 Pod 数量来增加该条链路上的 Mirrormaker 进程数量,以此加快数据同步的速度。
熟悉 Kafka 的读者应该知道,Kafka 对于每个 topic 可以设置不同的保存时间,保存时间外的数据会被删除。正常情况下,Local Kafka 和 Global Kafka 保留数据的时间都是一天。如果想长时间保留数据怎么办呢?
这里我们使用了 S3 和 Kafka connect。S3(Amazon Simple Storage Service) 是 AWS 提供的对象存储服务,它的特点是廉价、易用,适合长时间存储数据。Kafka connect 是 Kafka 提供的数据同步框架,可以把其他数据源的数据导入 Kafka,也可以把 Kafka 内的数据同步到其他地方。connector 是运行在 Kafka connect 集群中的应用。我们使用 Confluent 公司开源的 S3 connector 把需要长期存储的数据备份到 S3。
我们对 S3 connector 进行了二次开发,使得它在备份的时候可以按照我们期望的 parquet 格式进行保存。这些格式化数据可以通过 Presto 进行查询,意味着流经 Kafka 的数据可以被长期访问,这对排查故障与比对数据有很大的作用。我们还会对这部分数据定期进行 ETL,以此监控数据的体积分布和增长趋势。
如果把服务部署在实体机房,常常要考虑跨机房容灾问题,事实上 AWS 也有类似的概念。AWS 的机房分布于全球各地,范围最大的地理概念是 region。比如美国东部有弗吉尼亚,俄亥俄等几个 region。一个 region 又包含若干个 AZ(Availability Zone),这里指的是距离较近的几个机房。因此容灾包含了 AZ 和 Region 两个级别。
上文讲到,我们把 Kafka 的 EC2 实例启动在三个 ASG 里,这是因为这三个 ASG 指定了三个 AZ,每个 ASG 里面的节点都保存有一个 topic 的完整副本。因此当其中一个 AZ 发生故障的时候,其他的 AZ 仍然可以继续服务,这样就实现了 AZ 级别的容灾。至于 region 级别的容灾,我们则使用了 S3 上备份的数据。首先,我们使用了 AWS S3 CRR(Cross-Region Replication) 服务,将 S3 上的数据实时同步到其他的 region。当 region 级别的灾难发生的时候,我们会在其他的 region 启动 Kafka 集群,然后将一段时间内 S3 上的数据写回 Kafka。最后根据 timestamp 将各个 local Kafka 的 Mirrormaker consumer offset 调整到事故发生的时候,打开 Mirrormaker, 将新的数据写入 Kafka。请注意,这里的操作必然会引发一部分数据重复或者丢失,然而对应 region 级别的小概率灾难,这些代价是值得付出的。
有云平台使用经验的读者会说,云计算好是好,但是使用起来太贵了!别急,这里我来教大家几招 Kafka 云上部署的省钱秘籍。节约成本,要从计算和存储两个方向考虑。
AWS 的计算成本体现在机型上。对于 Kafka,我们的最佳实践是使用 R 系列的机型。R 系列机型和其他机型相比,在 CPU 核心数相同的情况下,它的内存会更大。因为 Kafka 会消耗比较多的堆外内存,同时高内存也意味着更高的 cache 命中率,所以 R 系列机型最适合 Kafka。
但是 R 系列的机型也非常昂贵,那么如何有效降低成本呢?我们做了两方面的优化。
第一个方面是部署架构的优化。上文提到,我们的 Kafka 是跨 AZ 部署的。根据 Kafka 的原理,Kafka 的所有读写均由 Leader 支持,所以我们把 Leader 集中到一个 AZ 当中,此时该集群的主要压力都转移到了该 AZ。其他 AZ 中只有 Follower,那么在这些 AZ 中的实例机型就可以比较小。只有在主 AZ 发生故障时,其他 AZ 的机器再动态扩容。通过 AZ 间非对称部署,可以降低 Kafka 的计算费用。另外,AWS 会对跨 AZ 的数据传输收取费用。如果 Kafka 的下游应用也部署在和 Kafka Leader 相同的 AZ,就可以避免跨 AZ 的数据传输的收费。
第二个方面是使用 ARM 架构的机器。传统的服务器架构以 x86 为主,然而近些年 AWS 推出了 ARM 架构的机器。这部分机器在 CPU 核心、带宽以及内存大小等参数不变的情况下,比同等的 x86 机器价格上便宜了 15% 左右,CPU 性能提高了 20% 左右。我们的 Kafka connect 集群已经替换成了 ARM 架构的机器,节约了 30% 左右的成本。未来我们会测试 Kafka 和 Mirrormaker 与 ARM 架构的兼容性,如果能成功迁移,成本还会进一步降低。
AWS 的存储成本体现在 S3 和 EBS 上。我们针对它们也进行了优化。
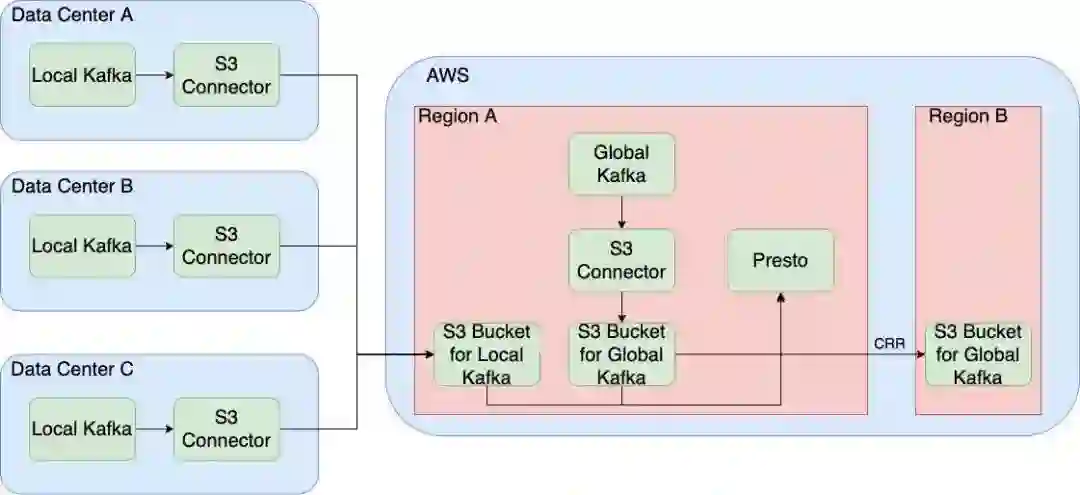
S3 上面主要存储了 Kafka 的备份数据。一条数据从写入 Local Kafka 到写入 Global Kafka 共被备份到 S3 三次。它第一次是被 Local Kafka 的 connect 集群备份到 S3;第二次是被 Global Kafka 的 connect 集群备份到 S3;最后一次是被 CRR 备份到跨 region 的 S3。显然这种多次备份是不经济的。
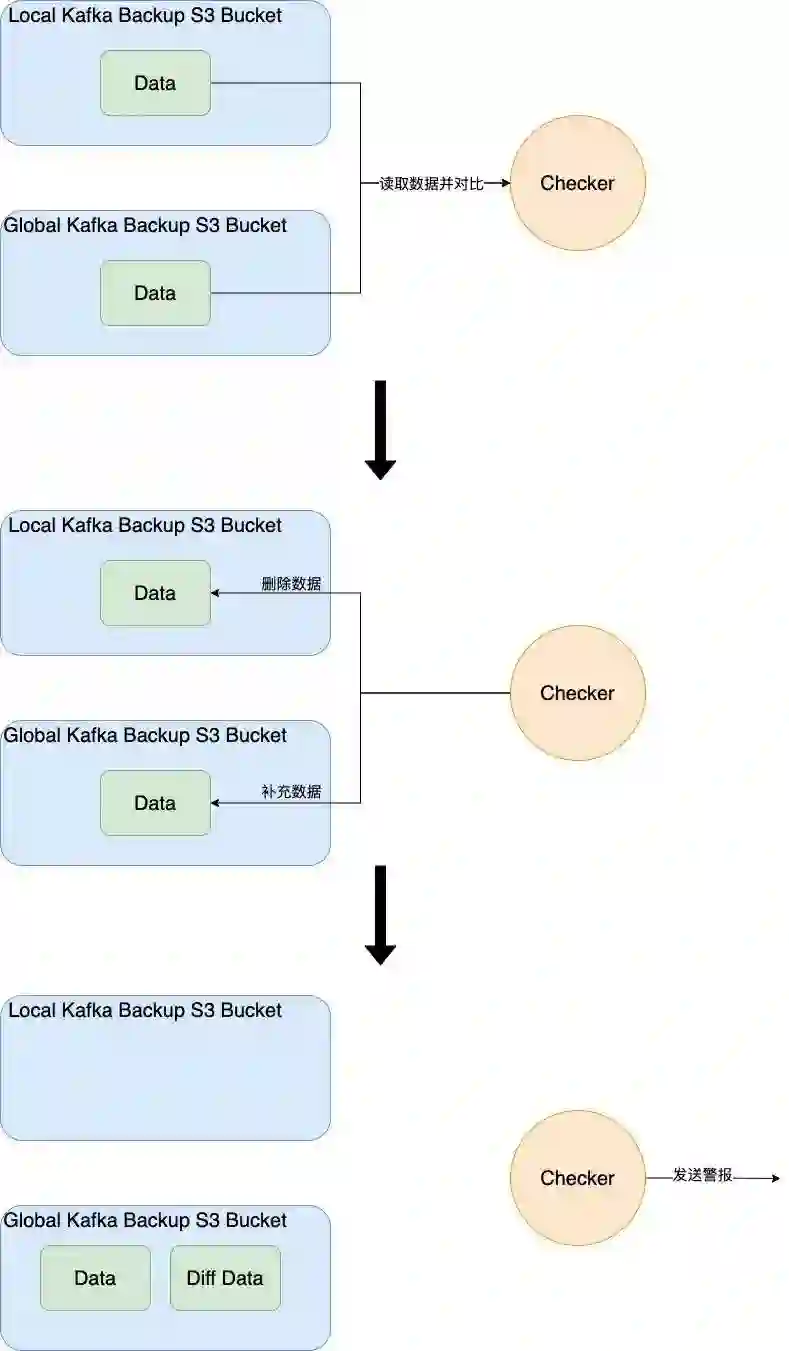
如下图所示,为了减少重复备份,我们每天会对比 Local Kafka 备份的数据和 Global Kafka 备份的数据,计算出它们的差集。然后我们会将这个差集转移到备份 Global Kafka 的 S3 中,再删除 Local Kafka 的备份数据。一旦出现差集,就说明 Mirrormaker 同步过程中丢失了数据。此时我们会发出报警。至于同步到其他 region 中 S3 的数据,我们会选用更便宜的 S3 存储等级,降低它的存储成本。
EBS(Amazon Elastic Block Store) 是 AWS 提供的硬盘类存储。因为 Kafka 的吞吐较大,我们使用了 gp3 类型的 EBS。一般 EBS 的 iops 和吞吐和它的容量成正比,而 EBS 的价格又和容量成正比。gp3 的 iops 和吞吐可以动态调整,那么相同的吞吐能力下,gp3 的价格比其他类型要便宜很多。
为了进一步降低磁盘占用,压缩使用成本,我们尝试引入了 ZSTD 压缩算法。该算法是 Facebook 开源的新型压缩算法,在 Kafka 2.1 版本后可用。在这之前,Kafka 提供的压缩率最高的算法是 Gzip。经过我们的测试,在消息大小超过 50Kb 时,ZSTD 的压缩比比 Gzip 的压缩比大 20%,同时压缩速度和解压速度更快。而我们当前磁盘占用最大的 topic 的平均消息大小已经超过 60Kb,所以我们将压缩算法换成了 ZSTD。
这里需要注意的是,Kafka 2.1 对 ZSTD 的支持并不好。
首先,适配该版本的其他语言客户端在解压/压缩 ZSTD 时可能有 bug。我们发现 Go 语言的 Sarama 客户端解压 ZSTD 时有严重的性能 bug。该 bug 的问题是在 ZSTD 解压过程中预分配了过多的内存,这会导致 GVM 产生大量 GC,使得 GVM 不断扩张直至耗尽服务器内存而崩溃。该问题在客户端更新至 1.28.0 之后才得以修复。
其次,Kafka 的 Java client 对 ZSTD 的压缩和解压缩支持也有缺陷。我们使用的 client 版本是 2.4.1,它在压缩 ZSTD 文件的时候会产生大量 GC。为解决这个问题,社区建立了相关的 issue,希望用一个可复用的 buffer 来减少对象的数量,进而降低 GC 次数。ZSTD 官方也在更新中提供了类似的 buffer。这个feature 以及 ZSTD 包的升级在 Kafka 2.8.0 版本中已经生效。因此,如果希望使用 ZSTD,建议将Java客户端升级至 2.8.0,同时对非 Java 客户端进行充分测试。
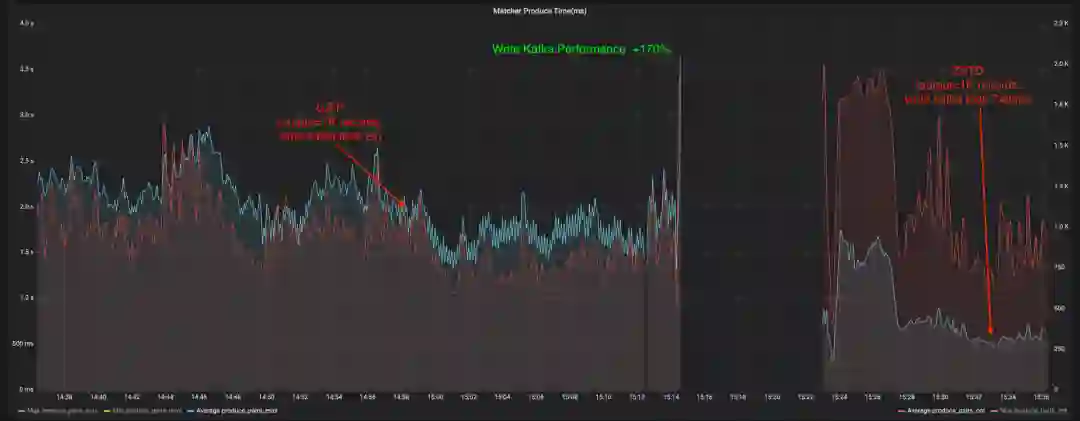
使用 ZSTD 压缩后,该 Topic 的数据平均每条大小减少了 25%,上游的 Producer 写 Kafka 时间减少了 63%。下图展示了 Producer 在使用 ZSTD 前后的性能变化。红线是每秒写入的数据量,蓝线是写入时间,可以观察到在修改前后,红线的变化不大,但是蓝线下降了很多,这反映出 Producer 的写入性能有巨大提升。
本文以 Kafka 上云为例,回顾和总结了 Kafka 向 AWS 迁移部署实践方面的经验。
FreeWheel 大数据团队从 2018 年开始向 AWS 上迁移服务,在迁移到 AWS 上之后,Kafka 的部署和运维变得更加容易,团队享受到了弹性计算带来的便捷,容灾能力得到提升,也为公司业务带来了更好的支持。
最后,非常感谢每一位为此辛劳工作的同事,是数据团队的共同努力完成了这项任务。值得一提的是 AWS 的 service 团队为我们提供了很多技术支持和指导,在此对他们付出的汗水与努力表示感谢,将来我们还会持续推进数据团队在 AWS 上的技术演进。
作者简介
袁艺,Apache Druid Committer,现任 FreeWheel 大数据基础架构团队高级工程师,主要负责公司 Kafka 的维护和开发工作。
今日好文推荐
阿里云回应被工信部处罚;“告别996”元年,超40%职场人加班更多;雷军称小米高端手机对标苹果 | Q资讯
新项目别一上来就用微服务
流量超过谷歌的Tiktok,在扩张过程中被质疑“偷窃”OBS代码
Log4j 持续爆雷,啥时候是个头?
2021 InfoQ 写作平台年度优质创作者评选火热进行中,2021 年度优质创作者、年度社区荣誉共建者、年度影响力作者即将揭晓!2021 年 12 月入驻并发布文章还有机会获得“失之交臂奖”~

点个在看少个 bug 👇





