替代 Kafka?Pinterest 推出云原生日志系统 MemQ

日志平台为 Pinterest 的所有数据摄入(data ingestion)和数据传输(Data transportation)提供了动力。Pinterest 日志平台的核心是一个分布式 PubSub 系统,它可以帮助用户进行数据的传输 / 缓冲和异步消费。
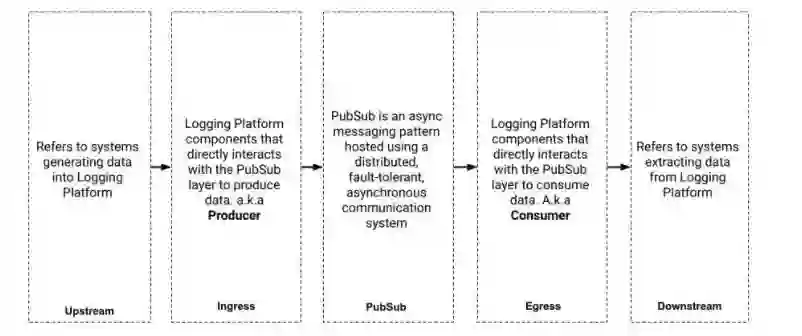
在这篇博客中,我们将会介绍 MemQ(发音为 mem - queue),它是一种用于 Pinterest 云端开发的高效可扩展 PubSub 系统,从 2020 年年中开始就为我们的近实时数据传输用例提供了支持,它是 Kafka 的一个补充,并且在成本效益方面高达 90% 。
近十年来,Pinterest 一直依赖 Apache Kafka 作为唯一的 PubSub 系统。由于 Pinterest 的发展,数据的数量也在不断增加,因此,在运行一个超大规模的分布式 PubSub 平台上所面临的挑战也与日俱增。Apache Kafka 的规模化经营使我们对构建可扩展的 PubSub 系统有了深刻的认识。在深入研究了 PubSub 的运营和可扩展性之后,我们得到了如下主要的结论:
并非所有的数据集都要求亚秒级的延迟,延迟和成本应该成反比(更低的延迟应该花费更多的成本)。
为了实现基于资源的独立可扩展性,必须将 PubSub 系统中的存储和服务组件分离。
根据读而非写来进行排序,为特定的消费者用例提供所需的灵活性(对于同一数据集,不同的应用程序可能会有不同的需求)。
在大多数情况下,严格的分区排序在 Pinterest 是没有必要的,并且常常会带来可扩展性方面的问题。
Kafka 中的再平衡成本很高,常常会造成性能的降低,并且会对已饱和的集群用户造成不利的影响。
在云环境中进行自定义复制会花费很大。
2018 年,我们对一个能够原生利用云计算的全新 PubSub 系统进行了测试。2019 年,我们开始正式探讨各种方案,以应对 Pinterest 的可扩展性,并基于运营成本以及现有技术的再设计成本,对各种 PubSub 技术进行了评估。最后得出的结论是,我们必须要有一个基于 Apache Kafka、Apache Pulsar 和 Facebook Logdevice 的 PubSub 技术,它是为了云计算而创建的。

MemQ 是一个新的 PubSub 系统,它加强了 Pinterest 的 Kafka。该系统采用了与 Apache Pulsar 和 Facebook Logdevice 相类似的解耦存储与服务架构;但是,其主要依靠可插入式复制存储层,也就是对象存储 /DFS/NFS 来存储数据。最后的结果就是一个 PubSub 系统:
处理 GB/s 流量
独立地扩展、写入和读取
不需要昂贵的再平衡来处理流处理的增长
比我们的 Kafka 足迹高出 90% 的成本效益
MemQ 的秘诀是,它通过微批处理和不可更改的写入来创建一个架构,在这种架构中,存储层所需的每秒输入 / 输出操作数(IOPS)会大幅降低,从而使得像 Amazon s3 这样的云本地对象存储的使用具有成本效益。该方法类似于网络的分组交换(与电路交换相比,即单一的大型连续存储数据,例如 Kafka 分区)。
MemQ 将连续的日志流分解成块(对象),与 Pulsar 中的分类账相似,只是它们是以对象形式写入的,而且是不能改变的。在 MEMQ 中,“数据包”/“对象”的大小被称作批处理(Batch),它在确定端到端(End-to-End,E2E)的延迟方面起着重要的作用。数据包越小,它们的写速率就越高,但是 IOPS 的成本也会增加。这样,MemQ 就可以将端到端的延迟调节到更高的 IOPS。这种架构的一个重要性能优点是,它实现了对底层存储层读写硬件的分离,使得写入和读取能够在跨存储层传播的数据包独立地进行扩展。
这也消除了 Kafka 中所面临的限制,即,要想恢复一个副本,就得从头再复制一个分区。在 MemQ 中,底层的复制存储只需要求恢复特定的批处理,如果发生存储失败,则会降低复制的数量。但是,因为 Pinterest 的 MemQ 是在 Amazon S3 上运行的,所以存储的恢复、分片和扩充都是由亚马逊云科技来完成的,没有 Pinterest 的人为干涉。
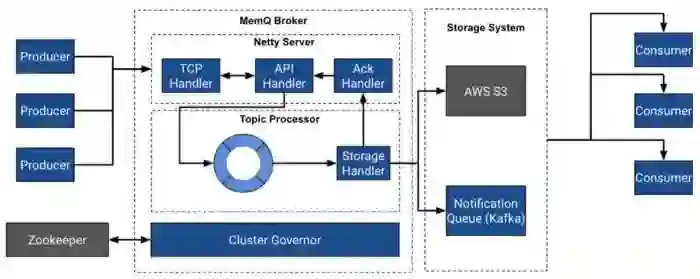
MemQ 客户端(Client)使用种子节点发现集群,并与该种子节点相连,从而发现元数据和托管给定主题的主题处理器(TopicProcessors)的代理(Broker),或者,对于消费者,托管通知队列的地址。
与其他 PubSub 系统类似,MemQ 也有代理的概念。MemQ Broker 是集群的一部分,主要负责处理元数据和写入请求。
注意:MemQ 的读请求可以直接由存储层处理,除非使用了读取代理。
调控器(Governor)是 MemQ 集群的领导者,它负责自动再平衡和主题处理器的分配。集群中的任何代理都可以被选为调控器,它通过 Zookeeper 与代理进行通信,Zookeeper 也是在调控器的选举中使用的。
调控器使用一个可插入式的分配算法来作出分配决策。预设的方式是通过对代理中的可用能力进行评估来作出分配决策。调控器还利用这个功能来处理代理失败和恢复主题的容量。
MemQ 与其他 PubSub 系统类似,使用主题的逻辑概念。代理上的 MemQ 主题是通过一个叫做主题处理器的模块来处理的。一个代理可以承载一个或多个主题处理器,每一个主题处理器实例处理一个主题。主题有写和读的分区。写分区用于创建主题处理器(1:1 的关系),而读分区用于确定需要多大的并行程度来处理消费者的数据。读分区的数量等于通知队列的分区数量。
MemQ 存储(Storage)由两部分组成:
Replicated Storage(Object Store / DFS)
Notification Queue(Kafka, Pulsar 等)
MemQ 支持可插入的存储处理程序。现在,我们已经完成了 Amazon S3 的存储处理器。Amazon S3 为容错、按需存储提供了一种性价比高的解决方案。MemQ 在 S3 中采用了下面的前缀格式,从而创建了高吞吐量和可扩展的存储层:
s3:///<(a) 2 byte hash of first client request id in batch>/<(b) cluster>/topics/(a) = 用于在 S3 内部进行分区,以便在需要时处理更高的请求率。
(b) = MemQ 集群的名称。
因为 S3 是一个高度可用的 Web 规模对象存储,MemQ 依靠其可用性作为第一道防线。MemQ 为满足 S3 未来的重新分区要求,在第一级前缀添加了两位数的十六进制哈希值,创建了 256 个基本前缀,这一点从理论上讲,可以通过独立的 S3 分区进行处理,只是为了让它能够经得起未来的考验。
MemQ 的一致性是由底层存储层的一致性所决定的。在 S3 的情形中,S3 标准的每一次写入(PUT)都保证在被确认之前被复制到至少三个可用性区域(Availability Zones,AZ)。
MemQ 使用通知系统将数据位置的指针传递给消费者。当前,我们使用了 Kafka 形式的外部通知队列(Notification Queue)。一旦数据被写入存储层,存储处理器就会生成一个通知消息,它会记录写入的属性,包括其位置、大小、主题等。消费者使用这个信息从存储层检索数据(批处理)。MenQ 代理也可以为消费者代理批处理,但需要以牺牲效率为代价。通知队列为消费者提供了集群 / 负载平衡。
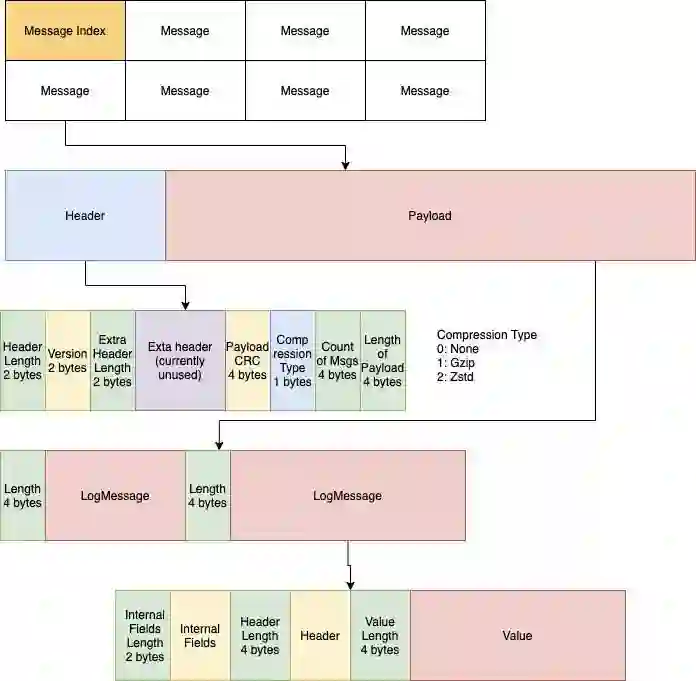
MemQ 对消息和批处理使用一种自定义的存储 / 网络传输格式。
MemQ 的最低传输单位被称为 LogMessage。这类似于 Pulsar Message 或 Kafka ProducerRecord。
LogMessage 的包装器可以让 MemQ 进行不同级别的批处理。单位的层次结构:
批处理(持久化的单位)
消息(生产者上传的单元)
LogMessage(应用程序与之交互的单元)

MemQ 生产者负责向代理发送数据。它使用异步调度模型,允许非阻塞的发送,而不需要等待确认。
这个模型对于在维护存储层确认的同时隐藏底层存储层的上传延迟至关重要。由于无法利用已有的 PubSub 协议,需要通过同步确认来实现自定义的 MemQ 协议和客户端。MemQ 支持三种类型的应答:ack=0(生产者触发和忘记),ack=1(代理接收)和 ack=all(存储接收)。在 ack=all 的情况下,复制因子(RF)由底层存储层决定(例如,在 S3 标准 RF=3[跨越三个 AZ])。如果确认失败,MemQ 生产者可以显式或隐式地触发重试。
MemQ 主题处理器在概念上是一个 RingBuffer。这个虚拟环被细分为批处理,这样可以简化写操作。当信息在通过网络到达时,将会被排进目前可用的批处理中,直至批处理被填满或者根据时间触发。当一个批处理完成后,它就被交给 StorageHandler,以便上传到存储层(如 S3)。如果上传成功,则通过通知队列发送通知,如果生产者请求确认,则使用 AckHandler 将批处理中的各个消息的确认(ack)发送给他们各自的生产者。
MemQ 消费者允许应用程序从 MemQ 读取数据。消费者使用代理元数据 API 来发现指向通知队列的指针。我们为应用程序提供了一个基于轮询的接口,每次轮询请求都会返回一个 LogMessages 的迭代器,以便读取一个批处理中的所有 LogMessages。这些批处理是使用通知队列发现的,并直接从存储层检索。
数据丢失检测: 当 Kafka 向 MemQ 迁移工作负载时,必须对数据丢失进行严格验证。所以,MemQ 拥有一个内置的审计系统,可以高效地跟踪每个消息的端到端交付,并且可以以近实时的方式发布指标。
批处理和流处理的统一: 由于 MemQ 使用一个外部存储系统,所以无需将 MemQ 的数据转换成其他格式,就可以在原始 MemQ 数据中直接进行批处理操作。这样,用户就可以对 MemQ 进行特别检查,无需为查找性能而担忧,只要存储层可以单独扩展读取和写入。MemQ 消费者可以使用存储引擎进行并发检索,从而在特定的流处理中实现更快速地回填。
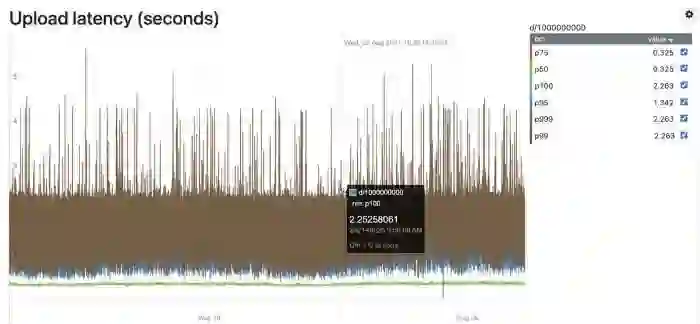
MemQ 支持基于大小和时间的刷新到存储层,除了一些优化来抑制抖动外,还能对最大的尾部延迟进行了硬限制。到目前为止,我们能够通过亚马逊云科技 S3 存储实现 30 秒钟的 p99 E2E 延迟,而且我们还在积极地改进 MemQ 的延迟,从而提高了从 Kafka 向 MemQ 迁移的用例数量。
事实证明,与使用 i3 实例的三个 AZ 上的三个副本的同等 Kafka 部署相比,S3 标准上的 MemQ 最多可以节省 90%(平均约 80%)。这些节约源于以下几个因素,例如:
减少 IOPS
取消排序限制
计算和存储的解耦
由于消除了计算硬件,减少了复制成本
放宽延时限制
带有 S3 的 MemQ 按需扩展,这取决于写入和读取的吞吐量要求。MemQ 调控器会进行实时再平衡,保证在能够提供计算的情况下,有充足的写入能力。代理增加了附加的代理并更新了流量需求,从而实现了线性扩展。如果消费者在处理数据时需要额外的并行性那么就手工更新读分区。
在 Pinterest 上,我们将 MemQ 直接用于 ec2,直接在 ec2 上运行 MemQ,并根据流量和新用例需求扩展集群。
我们在下列方面作出了积极的承诺:
减少 MemQ 的 E2E 延迟(<5 秒),以支持更多的使用案例
实现与流处理和批处理系统的本地集成
读取时的关键排序
MemQ 为 PubSub 提供了一种灵活、低成本、云原生的方式。如今,MemQ 可以在 Pinterest 上收集和传输所有的机器学习训练数据。我们正在积极研究将其扩展到其他数据集,并对延迟进行更好的优化。除了解决 PubSub 问题之外,MemQ 存储还可以提供使用 PubSub 数据进行批处理的能力,而不会对性能造成很大的影响,并且能够实现低延迟的批处理。
原文链接:
https://medium.com/pinterest-engineering/memq-an-efficient-scalable-cloud-native-pubsub-system-4402695dd4e7
点击底部阅读原文访问 InfoQ 官网,获取更多精彩内容!
今日好文推荐
流量超过谷歌的Tiktok,在扩张过程中被质疑“偷窃”OBS代码
Log4j 持续爆雷,啥时候是个头?
从混合包开发到100%纯鸿蒙应用还有多远?优酷鸿蒙版的开发实践与思考 | 卓越技术团队访谈录
数千个数据库、遍布全国的物理机,京东物流全量上云实录 | 卓越技术团队访谈录
2021 InfoQ 写作平台年度优质创作者评选火热进行中,2021 年度优质创作者、年度社区荣誉共建者、年度影响力作者即将揭晓!2021 年 12 月入驻并发布文章还有机会获得“失之交臂奖”~

点个在看少个 bug 👇



