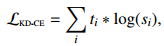![]()
作者 | Mr Bear
2018 年 10月,Bert 问世。从此,一波 NLP 迁移学习的研究热潮向我们袭来。
当下,全球研究人员已经在此领域做出了大量的工作,并取得了丰硕的成果。
你知道 BERT 的掩码语言模型由来已久吗?
你知道注意力机制的时间复杂度不一定是输入的二次方量级吗?
你知道你可以反向实现谷歌提出的相关模型吗?
本文
不对 NLP 迁移学习的
基本理论进行过多展开
,而是通过
21 个
问题
测试下大家对 NLP 迁移学习
最新进展以及一些常见问题的熟悉程度如何
。
毕竟,从某种程度上来说,你对 NLP 迁移学习的掌握度和熟悉度,也决定着你后续在该研究方向上开展工作的宽度和深度。
Q1:NLP 预训练模型(PTM,Pre-trained models)的最新进展如何?
参考论文:Pre-trained Models for Natural Language Processing: A Survey,https://arxiv.org/pdf/2003.08271.pdf
近年来,大量的研究工作表明,大规模语料库上的预训练模型可以学习到通用的语言表征,这有助于下游的 NLP 任务,可以避免从头开始训练一个新的模型。随着算力的发展,各种深度学习模型(例如 Transformer)层出不穷。
随着网络训练技巧的发展,PTM 的架构也逐渐从浅层向深层发展:
-
「第一代 PTM」旨在学习优秀的词嵌入。由于在下游任务中,这些第一代 PTM 方法自身并不被需要,出于对计算效率的考虑,它们往往层数很浅(例如,Skip-Gram 和 GloVe)。尽管这些预训练的嵌入可以捕获单词的语义,但是它们是上下文无关的,不能捕获文本中更高级的概念(例如,词义排歧、句法结构、语义角色、指代)。
-
「第二代 PTM」重点关注学习上下文相关的词嵌入(例如,CoVe,ELMo、OpenAI GPT,以及 BERT)。在下游任务中,仍然需要这些学习到的编码器来表征上下文中的单词。此外,针对于不同的目的,研究人员也提出了各种各样的预训练任务来学习 PTM。
将单词表征为稠密的向量由来已久。「现代的」词嵌入技术首先在神经网络语言模型(NNLM)中被提出。Collobert 等人说明在未标记数据上预训练的词嵌入可以显著地改进许多 NLP 任务。为了解决计算复杂度的问题,他们并没有使用语言模型,而是通过 pairwise 的排序任务学习词嵌入。他们的工作首次尝试了使用未标记数据获取对于其它任务有用的通用词嵌入。
Mikolov 等人指出,深度神经网络没有必要构建良好的词嵌入。他们提出了两种浅层的架构:连续词袋(CBOW)和跳字(Skip-Gram)模型。尽管这些模型很简单,但是它们仍然可以学习到高质量的词嵌入,从而捕获潜在的单词之间的句法和语义相似性。
Word2vec 是一种最流行的这些模型的实现,它让 NLP 领域的各种任务都可以使用预训练的词嵌入。此外,GloVe 也是一种被广泛使用的获取预训练词嵌入的模型,它是根据一个大型语料库中全局词共现的统计量计算而来的。
尽管研究人员已经证实了预训练词嵌入在 NLP 任务中是有效的,但它们与上下文无关,并且大多数是通过浅层模型训练而来。当它们被用于下游任务时,仍然需要从头开始学习整体模型中的其余部分。
由于大多数 NLP 任务并不仅仅停留在单词层面上,研究人员自然而然地想到在句子或更高的层面上预训练神经编码器。由于神经编码器的输出向量表征了依赖于上下文的单词语义,它们也被称为「上下文相关的词嵌入」。
Dai 和 Le 提出了第一个成功的用于 NLP 领域的 PTM。他们通过一个语言模型(LM)或一个序列自编码器初始化 LSTM,发现预训练可以提升 LSTM 在很多文本分类任务上的训练和泛化能力。
Liu 等人通过 LM 预训练了一个共享的 LSTM 编码器,并且在多任务学习(MTL)的框架下对其进行了调优。他们发现预训练和调优可以在一些文本分类任务中进一步提升 MTL 的性能。
Ramachandran 等人发现可以通过无监督预训练显著提升 Seq2Seq 模型的性能。编码器和解码器的权值都是通过两个预训练语言模型的权值初始化,并且使用有标记数据调优的。
除了通过 LM 预训练上下文相关的编码器,McCann 等人还通过用于机器翻译(MT)任务的注意力序列到序列模型预训练了一个深度 LSTM 编码器。预训练的编码器输出的上下文向量(CoVe)可以提升模型在各种常见的 NLP 任务中的性能。
现代的 PTM 通常是在更大规模的语料库上,使用更强大或更深的架构(如 Transformer),通过新的预训练任务训练而来。
Peter 等人使用一个双向语言模型(BiLM)预训练了一个 2 层的 LSTM,这个 BiLM 由一个前向传播 LM 和一个反向传播 LM。上下文相关的表征是通过预训练 BiLM、ELMo(语言模型嵌入)得来的,研究人员已证实这种表征可以为多种 NLP 任务带来巨大的性能提升。
Akbik 等人通过字符层面上的 LM 训练的上下文相关字符串嵌入捕获了单词语义。然而,这两种 PTM 往往被用作生成上下文相关词嵌入的特征提取器,生成的嵌入会被用作下游任务的主要模型的输入。BiLM 和 ELMo 的参数是固定的,主要模型中其它的参数也是从头开始训练的。
ULMFiT(通用语言模型调优)试图针对文本分类(TC)任务对预训练的 LM 进行调优,并且在 6 个被广为使用的 TC 数据集上取得了最先进的性能。ULMFiT 包含 3 个步骤:(1)在通用领域的数据上训练 LM(2)在目标数据上对 LM 进行调优(3)在目标任务上进行调优。ULMFiT 也研究了一些有效的调优策略,包括分层调优(discriminative fine-tuning)、斜三角学习率(slanted triangular learning rates )、逐层解冻(gradual unfreezing)。
最近,层数非常深的 PTM 已经在学习通用语言表征的任务中,例如 OpenAI GPT(生成式预训练),BERT(基于 Transformer 的双向编码器表征)。除了 LM 之外,研究人员还提出了越来越多的自监督任务,从而使 PTM 能从大型文本语料库中捕获更多的知识。
自从 ULMFiT 和 BERT 问世以来,调优已经成为了使 PTM 适应下游任务的主流方法。
参考论文:Pre-trained Models for Natural Language Processing: A Survey,https://arxiv.org/pdf/2003.08271.pdf
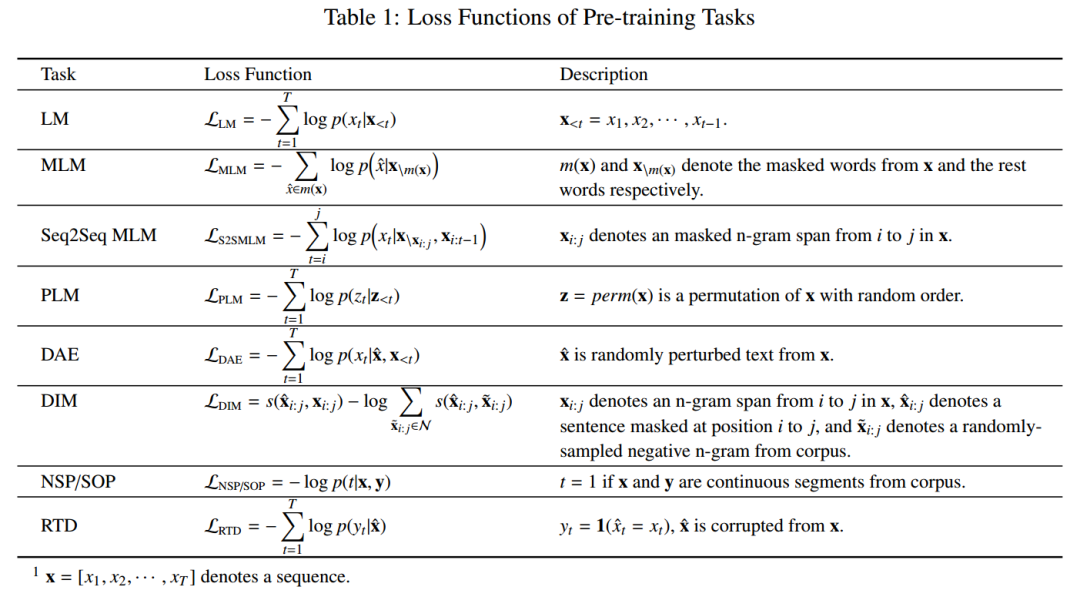
预训练任务对于学习语言的通用表征是非常重要的。通常,这些预训练任务应该是具有挑战性的,并且有大量的训练数据。我们将预训练任务总结为三类:监督学习、无监督学习、自监督学习。
监督学习(SL)是基于「输入-输出」对组成的训练数据,学习将输入映射到输出的函数。
无监督学习(UL)是从未标记的数据中发现一些内在的知识,如簇、密度(densities)、潜在表征。
自监督学习(SSL)是监督学习和无监督学习的折中。SSL 的学习范式与监督学习完全相同,但是训练数据的标签是自动生成的。SSL 的关键思想是以某种方式根据输入中的其它部分预测任一部分的输入。例如,掩模语言模型(MLM)是一种自监督任务,它尝试通过一个句子中其余的词去预测被掩模屏蔽的词。
![]()
NLP 领域中最常见的无监督任务是概率化的语言建模(LM),这是一个经典的概率密度估计问题。虽然 LM 是一个通用概念,但在实践中,LM通常特指自回归 LM 或单向 LM。
给定文本序列 x_(1:T) = [x_1, x_2,...,x_T],其联合概率 p(x1:T) 可被分解为:
条件概率 p(x_t|x_0:t−1) 可以通过给定语言上下文 x_0:t−1 的词汇集合上的概率分布来建模。通过神经编码器 fenc(.) 对上下文 x_0:t−1 建模,得到的条件概率为:
给定一个大型的语料库,我们可以通过最大似然估计训练整个网络。
掩模语言建模(MLM)最早由 Taylor 提出,他将其作为一个完形填空任务。Devlin 等人将此任务改造为一种新的预训练任务,从而克服标准单向 LM 的缺点。简而言之,MLM 首先对输入语句中的一些词例进行掩模处理,然后训练模型通过其它词例来预测被屏蔽的词例。但是,由于掩模词例在调优阶段并没有出现,这种预训练方法将造成预训练阶段和调优阶段之间的不匹配。根据经验,Devlin 等人在 80% 的情况下用 [MASK],10% 的情况下用随机的词例,10% 的情况下用原始词例来执行掩模操作。
1)序列到序列的掩模语言建模(Seq2Seq MLM)
研究人员通常将 MLM 作为分类问题来求解。我们将掩模处理后的序列输入给一个神经编码器,其输出向量进一步被进送入一个 softmax 分类器来预测被屏蔽的词例。或者,我们可以将编码-解码器架构用于 MLM,此时我们将掩模处理后的序列送入编码器,解码器以自回归的方式按照顺序产生掩模处理后的词例。我们将这种 MLM 称为序列到序列的 MLM(Seq2Seq MLM),该任务已被用于 MASS 和 T5。Seq2Seq MLM 有助于 Seq2Seq类的下游任务(例如问答、摘要和机器翻译)。
目前,有多个研究提出了不同的 MLM 的增强版本,从而进一步改进 BERT。RoBERTa 并没有使用静态掩模,而是通过动态掩模改进了 BERT。
UniLM 将掩模预测任务扩展到三类的语言建模任务上:单向、双向、序列到序列预测。XLM 在平行的双语句子对的串联上执行 MLM,这杯称为翻译语言建模(TLM)。SpanBERT 用随机连续字掩模(Random Contiguous Words Masking)和跨度边界目标(Span Boundary Objective,SBO)代替 MLM,将结构信息集成到预训练中,这要求系统基于跨度边界来预测经过了掩模处理的跨度区间中的内容。此外,StructBERT 还引入了跨度顺序恢复任务进一步引入语言结构。
尽管 MLM 任务在预训练中被广泛使用,但 Yang 等人认为,当模型被用于下游任务时,MLM 的预训练过程中使用的一些特殊词例(如[MASK])并不存在。这导致了预训练和调优阶段之间存在差异性。为了克服这个问题,研究人员提出用 PLM 作为预训练目标来替代 MLM。简而言之,PLM 是一种在输入序列的随机排列上进行的语言建模任务。每种排列(permutation)是从所有可能的排列中随机抽取得来的。然后,我们将序列的排列中的一些词例选取为目标,并训练模型根据其它的词例以及目标的自然位置,来预测目标词例。注意,这种排列并不影响序列的自然位置,只定义词例预测的顺序。实际上,由于收敛较慢,我们只能预测排列后的序列中的最后几个词例。针对面向目标的表征,研究人员还引入了双流自注意力机制。
DAE 接收部分被损坏的输入,旨在恢复出原始的无损输入。在 NLP 领域中,研究人员使用序列到序列模型(如标准的 Transformer)来重建原始文本。损坏文本的方式包含:
1)词例屏蔽(token masking):从输入中随机采样词例并用 [MASK] 元素替换它们。
2)词例删除:从输入中随机删除词例。与词例屏蔽的不同之处在于,模型需要确定删除后的输入的位置。
3)文本填充:类似于 SpanBERT ,对一些文本跨度区间进行采样,将其替换为一个 [MASK]。每个跨度区间的长度服从泊松分布(λ= 3)。模型需要预测在一个跨度区间中删除了多少个词例。
4)句子排列:根据句号将一个文档互粉成若干个句子,并将这些句子按照随机顺序排列。
5)文档旋转:随机均匀地选择一个词例,并旋转文档,使其以该token开始。模型需要识别文档的实际开始位置。
对比学习假设一些观测到的文本对之间的语义相似度要高于随机采样得到的文本对。通过最小化下面的目标函数来学习文本对 (x, y) 的得分函数 s(x, y):
其中 (x, y+) 代表相似的文本对,y- 可能与 x 不相似。y+ 和 y- 通常被称为正样本和负样本。得分函数 s(x, y) 通常由一个可学习的神经编码器以两种方式计算:
![]() 或
或
![]() CTL 背后的指导思想是「通过比较学习」。与 LM 相比,CTL 的计算复杂度往往更低,因此对于 PTM 来说是另一种理想的训练标准。
近年来,研究人员提出的 CTL 任务包括:Deep InfoMax(DIM)、替换词例探测(RTD)、CBOW-NS、ELECTRA、后续句子预测(NSP)、据此顺序预测(SOP)等。
除了上述任务,研究人员还设计了许多其它的辅助预训练任务,它们被用于引入事实知、提升在跨语言任务上的性能、多模态应用,或其它的特定任务。
CTL 背后的指导思想是「通过比较学习」。与 LM 相比,CTL 的计算复杂度往往更低,因此对于 PTM 来说是另一种理想的训练标准。
近年来,研究人员提出的 CTL 任务包括:Deep InfoMax(DIM)、替换词例探测(RTD)、CBOW-NS、ELECTRA、后续句子预测(NSP)、据此顺序预测(SOP)等。
除了上述任务,研究人员还设计了许多其它的辅助预训练任务,它们被用于引入事实知、提升在跨语言任务上的性能、多模态应用,或其它的特定任务。
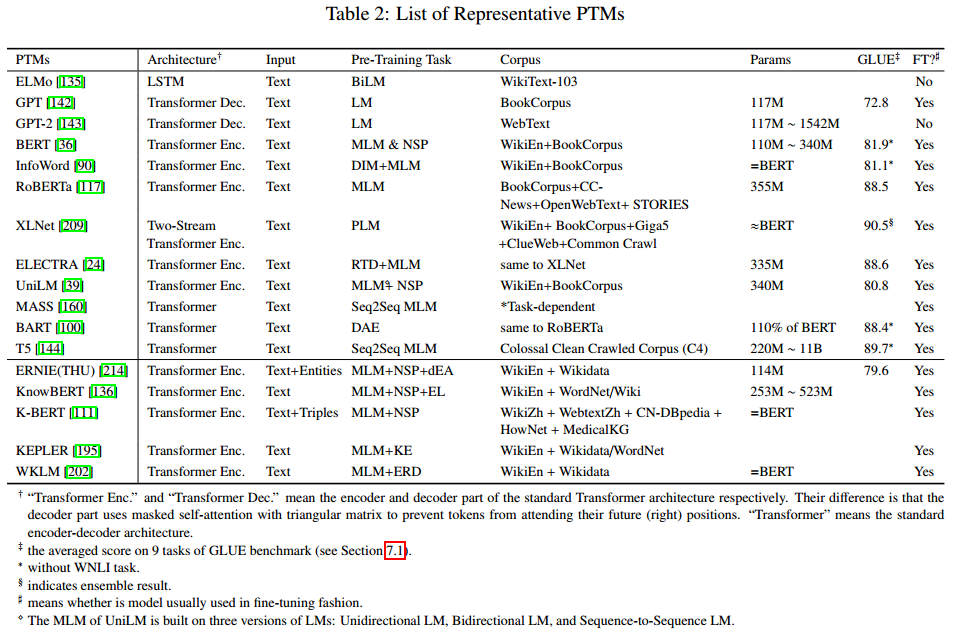
Q3:PTM 在 GLUE 对比基准上的最新进展如何?
参考论文:Pre-trained Models for Natural Language Processing: A Survey,https://arxiv.org/pdf/2003.08271.pdf
通用语言理解评价(GLUE)基准是 9 个自然语言理解任务的集合,包括单句分类任务(CoLA 和 SST-2)、成对文本分类任务(MNLI、RTE、WNLI、QQP 和 MRPC)、文本相似度任务(STSB)和相关性排序任务(QNLI)。GLUE 对比基准被设计用来评估模型的鲁棒性和泛化能力,它不为测试集提供标签,而是设置了一种评估器。
一些具有代表性的模型在 GLUE 对比基准上的性能如下:
在上图中,Transformer Enc 和 Transformer Dec 分别代表标准 Transformer 架构的编码器和解码器。它们的区别在于解码器部分使用经过三角矩阵掩模处理的自注意力,从而防止词例注意未来出现的(右侧的)位置上的词例。Transformer 指标准的编码器-解码器架构。
GLUE 是在 9 个 GLUE 对比基准上的平均得分。
「*」代表不包含 WNLI 任务。
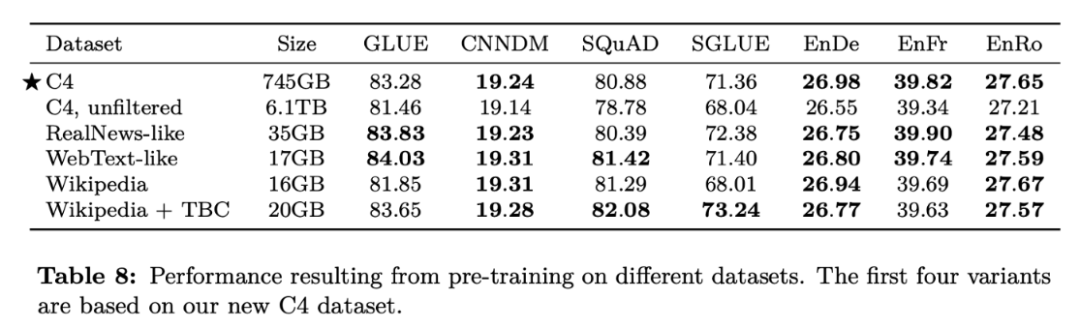
Q4:使用更多的数据是否总是能够得到更好的语言模型?
参考论文:Explorin
g the Limits of Transfer Learning with a Unified Text-to-Text Transformer,https
://arxiv.org/pdf/1910.10683.pdf
这篇论文指出,当数据量达到一定规模时,数据的质量比数据的数量对于模型性能的提升更加重要。如下图所示,未过滤的 C4 数据集规模达到了 6.1 TB,过滤后的 C4 数据集规模则为 745GB。然而,在过滤后的 C4 数据集上,预训练模型的各项指标均优于未过滤的情况。
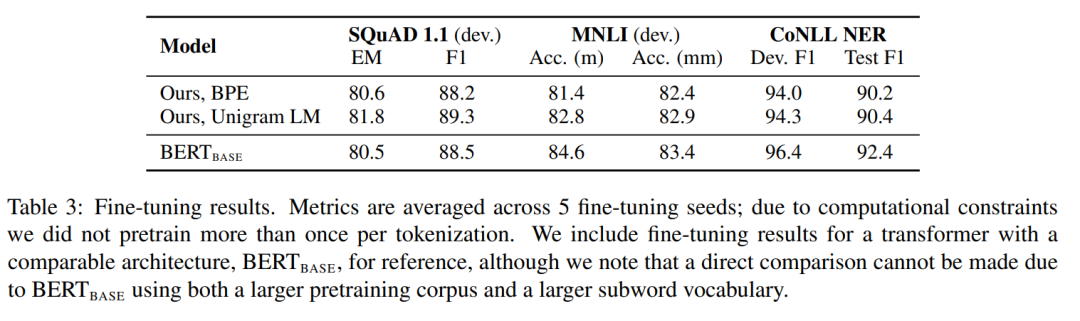
Q5:对预训练语言模型来说,使用哪种分词方法是最好的?
参考论文:Byte Pair Encoding is Suboptimal for Language Model Pretraining,https://arxiv.org/pdf/2004.03720.pdf
论文指出,一种新的 Unigram 语言建模方法比BPE(字节对编码)和 WordPiece 方法更好。
Unigram LM 方法可以恢复出更好地与底层词法相匹配的子词单元,并且避免 BPE 词干提取的贪心构造过程中的一些缺点。作者还对比了使用 Unigram、BPE 等分词方法的相同的 Transformer 掩模语言模型的调优性能。
他们发现,在下游任务中,Unigram LM 分词方法的性能始终优于 BPE。在各种调优任务上的实验结果如下图所示。
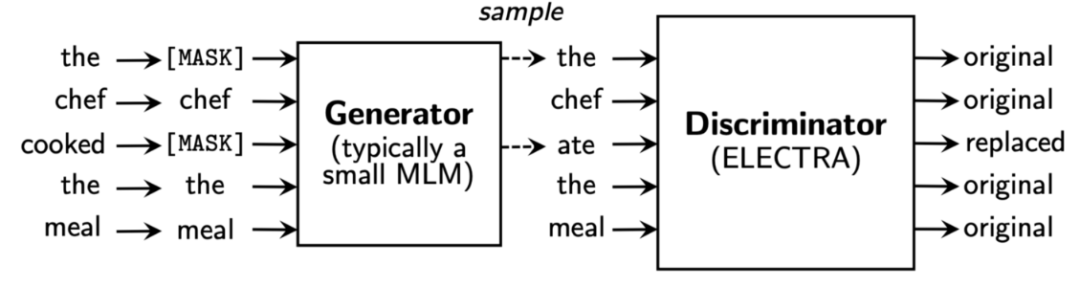
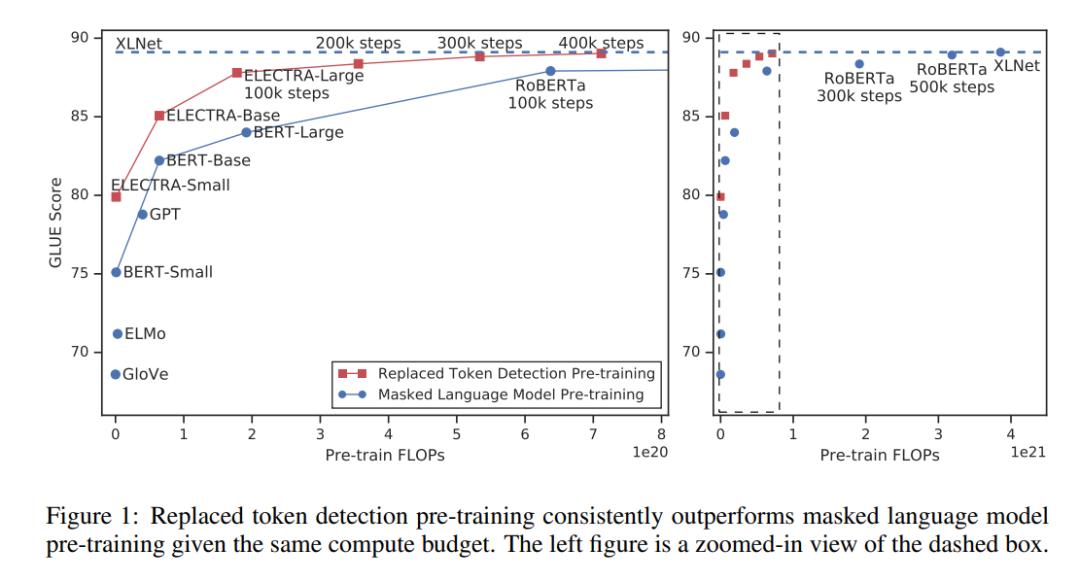
目前最佳的方法是 ELECTRA,该方法使用一个生成器替换输入序列中的词例,然后使用一个判别器预测哪个词例被替换了。
参考论文:ELECTRA: PRE-TRAINING TEXT ENCODERS AS DISCRIMINATORS RATHER THAN GENERATORS,https://arxiv.org/pdf/2003.10555.pdf
在论文中,作者在 GLUE 自然语言理解对比基准和 SQuAD 问答对比基准上对各种替换词例探测(RTD)任务和掩模语言模型(MLM)任务进行了实验分析。实验结果表明,在给定相同的模型规模的情况下,ELECTRA 的性能始终优于基于 MLM 的方法(例如,BERT、XLNet)。
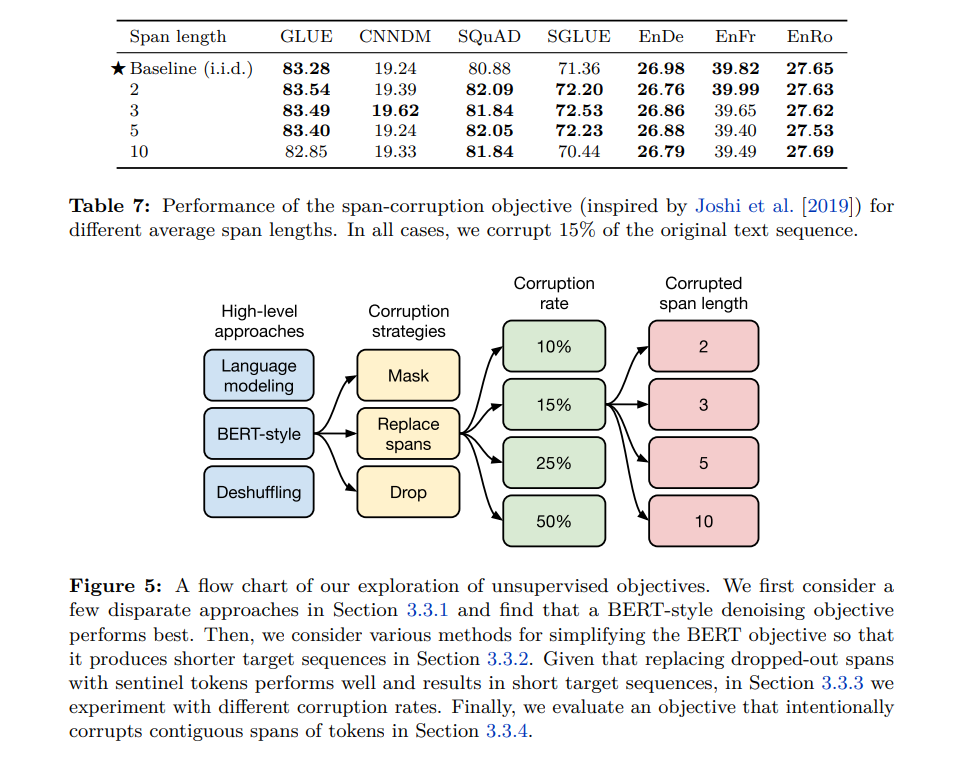
针对任务的目标序列长度,论文「Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer」进一步指出,将丢弃的跨度区间长度选择为 3 是较为合适的。具体而言,作者将平均跨度区间设置为 3,原始序列的丢弃率设置为 15%。他们发现这种目标可以得到较好的性能,此时由于目标序列长度较短使得计算效率较高。
论文地址:https://arxiv.org/pdf/1910.10683.pdf
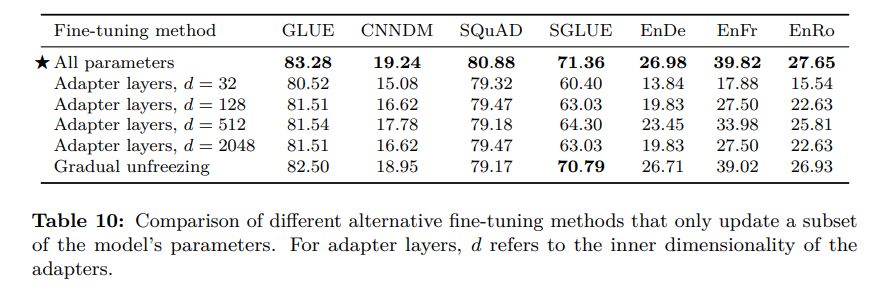
Q7:对于训练 Transformer 的任务来说,逐层解冻(gradual unfreezing)是否有必要?
参考论文:Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer,https://arxiv.org/pdf/1910.10683.pdf
作者发现,在所有的对比基准任务上,尽管逐层解冻确实在调优阶段带来了一定的速度提升,但是它会造成少许的性能下降。
下图为使用不同的模型参数子集的情况下,不同调优方法的对比。对于适配器层来说,d 代表适配器的内部维度。
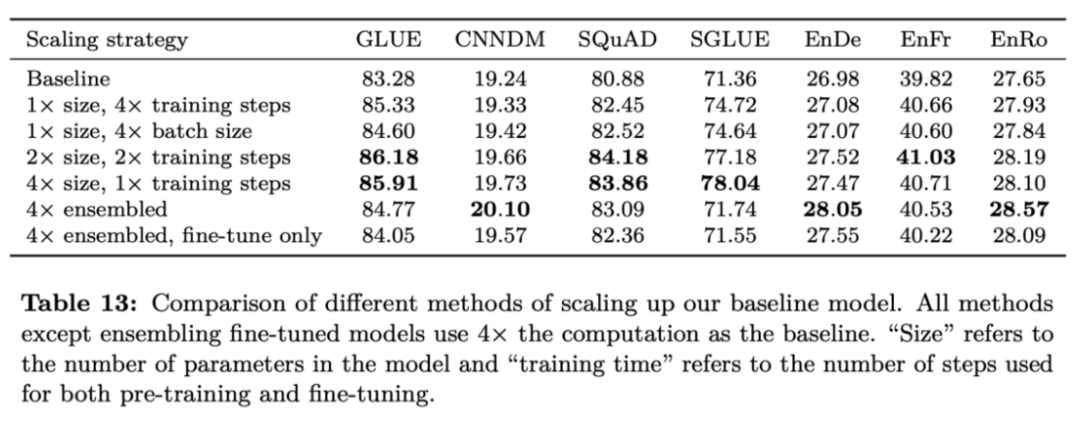
Q8:如果你的训练资源预算有限,为了得到更好的语言模型,你会选择做出什么改变?
参考论文:Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer,https://arxiv.org/pdf/1910.10683.pdf
这篇论文中,作者建议我们同时增大模型参数的规模和训练步数。
下图为不同的扩展基线模型的方法的对比。除了集成调优模型之外, 所有的方法都以 4 倍的计算量为对比基线。「Size」代表模型中的参数量,「Training time」代表预训练和调优阶段使用的步数。
一般来说,相较于仅仅增大训练训练时间或批处理规模来说,同时增大模型参数的规模会得到显著的性能提升。
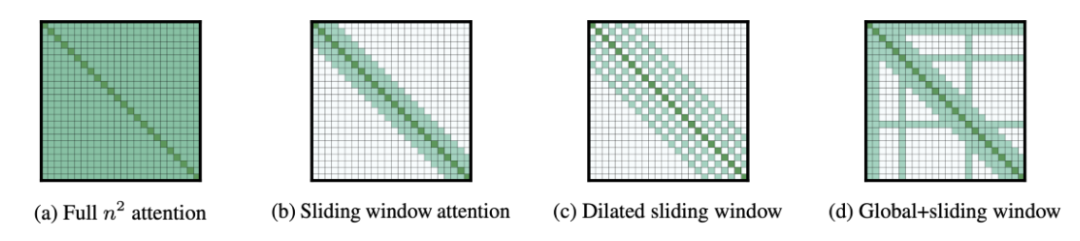
Q9:如果你的序列长度长于 512 个词例,你会使用哪种模型?
众所周知,多头注意力机制 (Multi-Head Self-Attention) 的计算开销很大。在处理长度为 n 的序列时,其
![]() 的时间复杂度会使得原始的 Transformer 模型难以处理长文本序列。
目前,较为流行的做法是使用 Transformer-XL(将先前「段落」的隐藏状态作为循环段落层的输入,并且使用使这种策略容易实现的相对位置编码方案)或 Longformer(详见雷锋网AI科技评论文章:这六大方法,如何让 Transformer 轻松应对高难度长文本序列?)
的时间复杂度会使得原始的 Transformer 模型难以处理长文本序列。
目前,较为流行的做法是使用 Transformer-XL(将先前「段落」的隐藏状态作为循环段落层的输入,并且使用使这种策略容易实现的相对位置编码方案)或 Longformer(详见雷锋网AI科技评论文章:这六大方法,如何让 Transformer 轻松应对高难度长文本序列?)
Q10:随着序列的长度增长,Transformer 的时间复杂度将如何增长?
由于自注意力机制在运算的过程中每两个词例之间将形成一对注意力,此时时间复杂度的增长速率是
![]() 的。
的。
Q11:由于 Transformer 的计算时间复杂度是序列长度的二次函数,如何降低其在处理长文本时的运算时间?
近年来,许多研究工作都着眼于提升 Transformer 在长序列上的计算效率。它们主要关注自回归的语言建模,然而在迁移学习环境中将长文本 Transformer 应用于文本级的 NLP 任务仍然是一个急需解决的问题。
Longformer 使用了一种计算时间可以线性地随着序列长度增长而增长的注意力机制(窗口化的局部上下文的自注意力和由终端任务激活的全局注意力)。
Longformer 在语义搜索任务上,有很好的编码长文本的能力。下图展示了目前该领域的研究进展。
Q12:BERT 是因为其注意力层才取得了优秀的性能吗?
参考论文:Attention is not Explanation,https://www.aclweb.org/anthology/N19-1357.pdf
该论文认为,尽管研究人员往往声称注意力机制为模型提供了透明度(使用注意力机制的模型给出了对于输入单元的注意力分布),但是注意力权重和模型的输出之间存在怎样的关系还不明确。
作者在各种各样的 NLP 上进行了大量的实验,发现注意力机制并不能恰当地与输出相关联。例如,学习到的注意力权重往往与基于梯度的特征重要性度量无关,我们可以发现有些差异非常大的注意力分布可以产生相同的预测结果。因此我们不能认为模型是由于注意力机制才取得了优秀的性能。
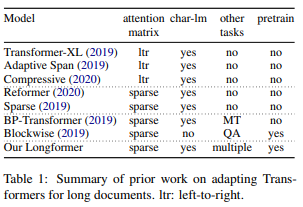
Q13:如果我们去掉一个注意力头,BERT 的性能会显著下降吗?
在论文「Revealing the Dark Secrets of BERT」中,作者使用了一部分 GLUE 任务,以及一些手动收集的特征,提出了一些研究方法并且对 BERT 的注意力头编码的信息进行了定量和定性的分析。
论文地址:https://arxiv.org/pdf/1908.08593.pdf
实验结果表明,不同的注意力头会重复一些特定的注意力模式,这说明模型存在过参数化的现象。尽管不同的注意力头会使用相同的注意力模式,但是他们在不同的任务上对性能有不同的影响。作者指出,手动去掉某些注意力头的注意力,一般会使得条右后的 BERT 模型获得性能的提升。
具体而言,由于 BERT 在很大程度上依赖于学习到的注意力权重,作者将去除一个注意力头定义为将某个注意力头对于输入句子中的每个词例的注意力值修改为一个常量 a=1/L(其中 L 是句子的长度)。因此,每个词例都会得到相同的注意力,这样做可以有效地去除注意力模式,同时保留原始模型的信息流。请注意,通过使用这种框架,作者可以去除任意数目的注意力头(从去除每个模型中的单个注意力头到整个一层注意力,或者多层注意力)。
实验结果表明,某些注意力头对 BERT 的整体表现有负面的影响,这一趋势适用于所有选择到的任务。令人意想不到的是,去除一些注意力头并没有如人们预期的那样导致准确率的下降,而是提升了性能。如下图所示,这种影响因任务和数据集而异。
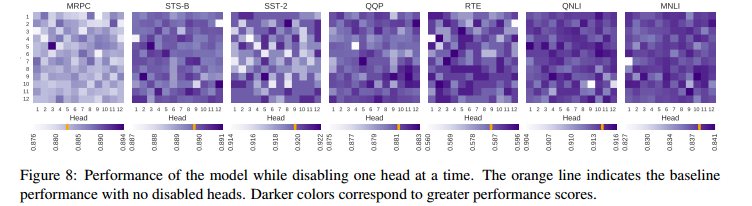
Q14:如果我们去掉一个网络层,BERT 的性能会显著下降吗?
在论文「Revealing the Dark Secrets of BERT」中,作者指出,去掉整个一层的注意力(即给顶层中的 12 个注意力头),也会提升模型的性能。如下图所示,当去除不同的层时,在识别文本蕴含(RTE) 的任务中,去掉第一层注意力会取得极其显著的性能提升(3.2%)。
论文地址:https://arxiv.org/pdf/1908.08593.pdf
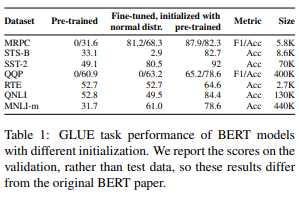
Q15:如果我们随机初始化BERT,BERT 的性能会显著下降吗?
在论文「Revealing the Dark Secrets of BERT」中,为了评价预训练 BERT 对于整体
性能的影响,作者考虑了两种权值初始化方式:预训练 BERT 权值,以及从正态分布中随机采样得到的权值。
论文地址:https://arxiv.org/pdf/1908.08593.pdf
如下表所示,对使用正太分布中随机采样得到的权值初始化的 BERT 进行调优,其性能得分始终低于使用预训练权值初始化的 BERT。然而,在某些任务(如 MRPC )上,性能的下降并不太显著。
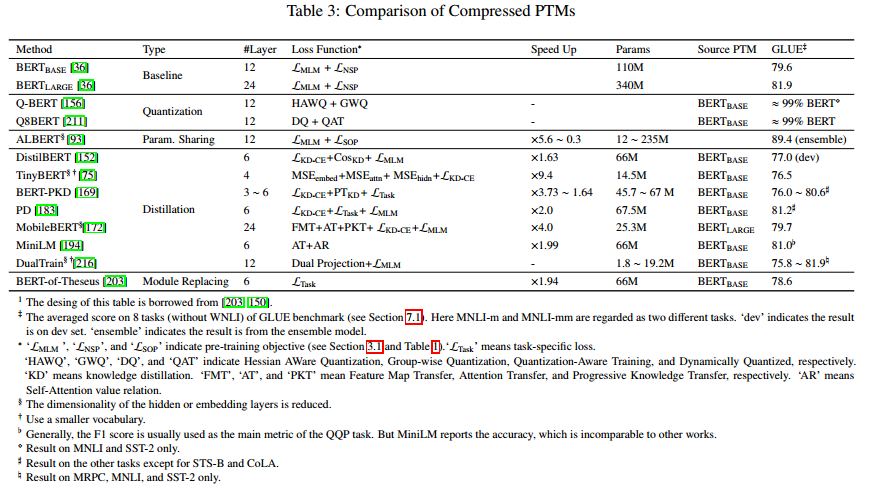
模型压缩是一种收缩训练好的神经网络的技术。压缩后的模型通常与原始模型相似,而它只使用一小部分计算资源。然而,在许多应用中的瓶颈是在压缩之前训练原来的大型神经网络。
博文「Do We Really Need Model Compression?」指出,模型压缩技术说明了过参数化的模型趋向于收敛到哪些类型的解上,从而提示我们如何训练适当参数化的模型。目前有许多类型的模型压缩方法,每一种都利用了训练好的神经网络中易于发现的不同类型的「朴素特性」:
博文地址:http://mitchgordon.me/machine/learning/2020/01/13/do-we-really-need-model-compression.html
Q17:如果一个模型的 API 暴露出来,我们能否反向实现出这个模型?
参考论文:Thieves on Sesame Street! Model Extraction of BERT-based APIs,https://arxiv.org/abs/1910.12366
作者在这篇 ICLR2020 论文中展示了,在不使用任何真实输入训练数据的情况下反向实现出基于 BERT 的自然语言处理模型是可能的。攻击者向被攻击的模型输入了无意义的随机采样得到的词序列,然后根据被攻击模型预测的标签对他们自己的 BERT 进行调优。
该方法的有效性指出了:如果通过调优训练公共托管的 NLP 推理 API,这些模型存在被反向实现的风险。恶意用户可以通过随机查询向 API 发送垃圾信息,然后使用输出重建模型的副本,从而发起模型提取攻击。
知识蒸馏是一种压缩技术,它通过训练一个被称为学生模型的小型模型来复现一个被称为教师模型的大模型。在这里,教师模型可以是许多模型的集合,它们通常都被预训练好了。与模型压缩不同,知识蒸馏技术通过一些优化目标根据一个固定的教师模型学习一个小型的学生模型,而压缩技术旨在搜索一个更稀疏的模型架构。
一般来说,知识蒸馏机制可以被分为三类:(1)从软目标概率(soft target probabilities)中蒸馏;(2)从其它知识中蒸馏;(3)蒸馏成其它的结构。
(1)从软目标概率(soft target probabilities)中蒸馏:Bucilua 等人指出,让学生模型近似教师模型可以从教师模型向学生模型迁移知识。通常的方法是近似教师模型的 logit。DistilBERT 用教师模型的软目标概率作为蒸馏损失训练学生模型:
其中 t_i 和 s_i 分别是教师模型和学生模型估计出的概率。
从软目标概率中蒸馏出的知识也可以被用于特定任务的模型中(如信息检索和序列标记)。
(2)从其他知识中提炼:从软目标概率中蒸馏模型将教师模型视为黑盒,只关注其输出。此外,分解教师模型,正流出更多的知识,可以提升学生模型的性能。
TinyBERT 使用嵌入输出、隐藏状态,以及自注意力分布进行层到层的蒸馏。MobileBERT 也使用软目标概率、隐藏状态,以及自注意力分布进行层到层的蒸馏。MiniLM 从教师模型中正流出自注意力分布以及自注意力值关系。
此外,其它模型也通过许多不同的方法蒸馏知识。Sun 等人提出了一种「patient」教师-学生机制,Liu 等人利用知识蒸馏改进了预训练的多任务深度神经网络。
(3)蒸馏成其他结构:一般来说,学生模型的结构和教师模型是一样的,只是学生网络中层的规模更小,隐层的规模也更小。然而,减少参数,以及将模型从 Transformer 简化为 RNN 或 CNN 结构,可以降低计算复杂度。
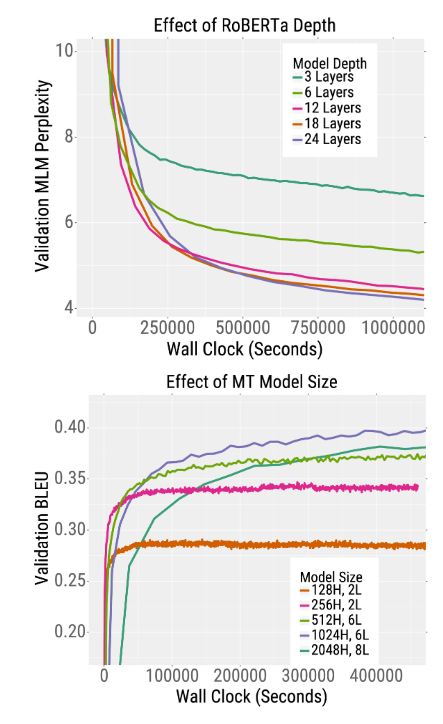
Q19:更大的 Transformer 模型训练的更快,还是更小的 Transformer 模型训练的更快?
博文「Speeding Up Transformer Training and Inference By Increasing Model Size」指出,较大的模型可以更快地获得更高的准确率。对于预训练 RoBERTa,增加模型宽度和 / 或深度都会导致训练地更快。对于机器翻译任务,更宽模型比更深的模型更有效。
博文地址:https://bair.berkeley.edu/blog/2020/03/05/compress/
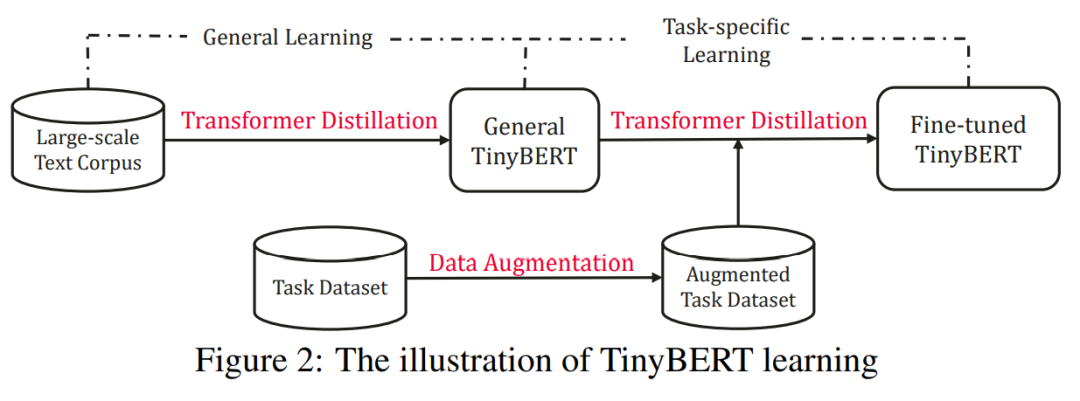
参考论文:TINYBERT: DISTILLING BERT FOR NATURAL LANGUAGE UNDERSTANDING,https://arxiv.org/pdf/1909.10351.pdf
论文中,作者为了加速模型推理并且提升模型在资源有限的设备上的执行效率,提出了一种 Transformer 蒸馏方法。通过使用这种方法,大量的「教师」BERT 中被编码的知识可以被很好地迁移到小型的「学生」网络 TinyBERT 中。
此外,作者还引入了一种新的两阶段学习框架:在预训练和特定任务学习阶段都执行 Transformer 蒸馏。这种框架保证了 TinyBERT 可以同时捕获 BERT中通用领域中和特定任务的知识。
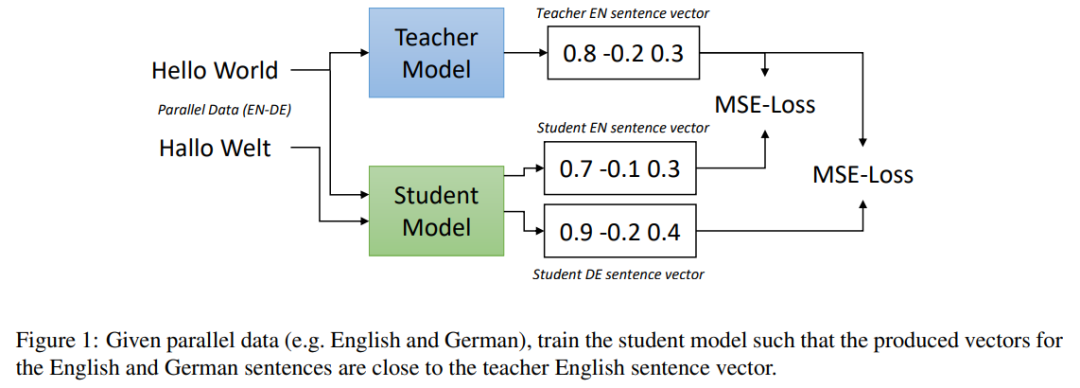
在论文「Scaling Laws for Neural Language Models」中,作者提出了一种简单高效的方法将现有的句子嵌入模型扩展到新的语言上,从而为不同的语言生成相似的句子嵌入。作者使用原始的单语言模型为源语言生成句子嵌入,然后根据翻译后的句子训练了一个新的系统来模仿原始模型。
论文地址:https://arxiv.org/pdf/2004.09813v1.pdf
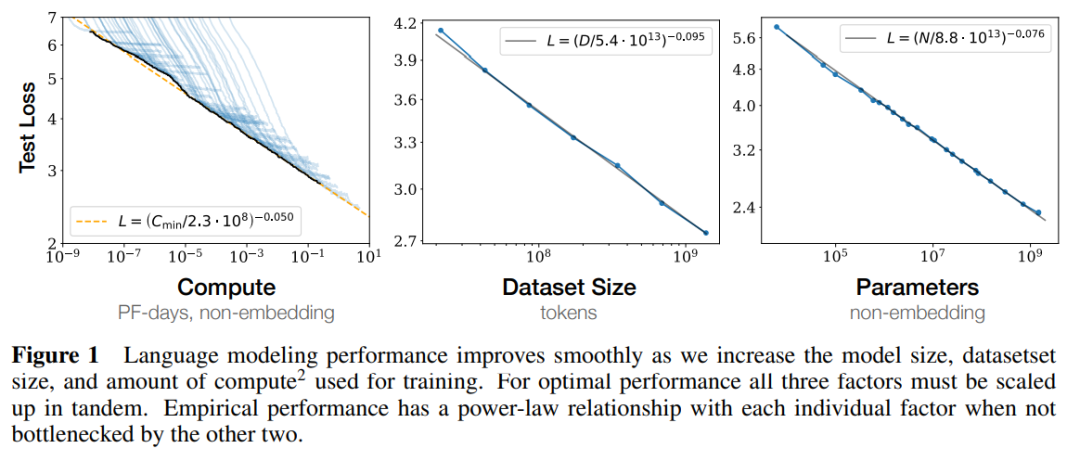
论文「Scaling Laws for Neural Language Models」对这个问题进行了说明,它向我们揭示了以下几种关系:
想要设计并训练一个模型,我们首先要决定其架构,然后决定参数的数目。接着,你才能够计算损失,并最后选择数据的规模以及需要的计算开销。
论文地址:https://arxiv.org/pdf/2001.08361.pdf
https://medium.com/modern-nlp/20-questions-to-test-your-skills-in-transfer-learning-for-nlp-7d9f6c5f8fdc
![]()
ACL 2020原定于2020年7月5日至10日在美国华盛顿西雅图举行,因新冠肺炎疫情改为线上会议。为促进学术交流,方便国内师生提早了解自然语言处理(NLP)前沿研究,AI 科技评论将推出「ACL 实验室系列论文解读」内容,同时欢迎更多实验室参与分享,敬请期待!
点击"阅读原文",直达“ACL 交流小组”了解更多会议信息。

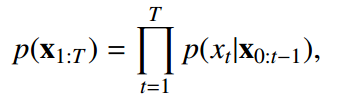
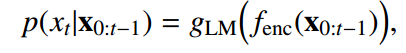
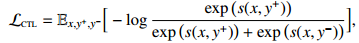
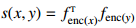 或
或
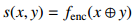
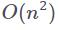 的时间复杂度会使得原始的 Transformer 模型难以处理长文本序列。
的时间复杂度会使得原始的 Transformer 模型难以处理长文本序列。