多媒体顶会ACMMM2019@法国尼斯,Snap获最佳论文,新加坡国立获最佳学生论文,OpenVSLAM最佳开源软件
【导读】第27届ACM国际多媒体会议(ACM MM)于2019年10月21日至25日在法国尼斯隆重举行。ACM MM属于CCF-A类顶会,在昨天,包括最佳论文,最佳学生论文,最佳demo, 最佳开源软件在内的所有多媒体领域大奖都已出炉。

最佳论文

标题:所见即所听 Audiovisual Zooming: What You See Is What You Hear
作者:Arun Asokan Nair, Austin Reiter, Changxi Zheng, Shree Nayar
摘要:在移动平台上拍摄视频时,往往会受到周围环境的污染。为了减少视觉上的不相关性,摄像机的平移和缩放提供了分离所需视场(FOV)的方法。然而,捕获的音频仍然受到FOV外部信号的污染。这种效果是不自然的——对于人类的感知来说,视觉和听觉的线索必须同时出现。我们提出了视听缩放的概念,即形成一个听觉FOV来匹配视觉。我们的框架是围绕波束形成的经典思想构建的,这是一种使用麦克风阵列从单一方向增强声音的计算方法。然而,波束形成本身不能包含听觉FOV,因为FOV可能包含任意数量的定向源。我们将视听缩放问题转化为广义特征值问题,提出了一种基于移动平台的高效计算算法。为了了解算法和物理实现,我们对算法组件进行了理论分析,并进行了数值研究,以了解麦克风阵列的各种设计选择。最后,我们演示了视听缩放在两个不同的移动平台:一个移动智能手机和一个360◦球面成像系统的视频会议设置。

论文地址:
最佳学生论文

标题:隐私保护- Human-imperceptible Privacy Protection Against Machines
作者:Zhiqi Shen, Shaojing Fan, Yongkang Wong, Tian-Tsong Ng
摘要:由于社交网络平台上发生了多起用户数据泄露事件,社交媒体的隐私问题近来备受关注。随着当前机器学习和大数据的发展,计算机算法通常充当隐私泄露的第一步过滤器,自动选择包含敏感信息的内容,比如包含人脸或车牌的照片。在本文中,我们提出了一种新的算法来保护敏感属性不受机器的影响,同时又能使这些变化不被人类察觉。特别是,我们首先进行了一系列的人体研究,以调查影响人类对视觉变化敏感性的多种因素。我们发现人类的敏感性受多种因素的影响,从低层次的特征如光照、纹理,到高层次的属性如对象情感和语义。基于我们的人类数据,我们首次提出了人类敏感性地图的概念。利用灵敏度图,我们设计了一个具有人的灵敏度感知的图像扰动模型,该模型能够修改敏感属性的计算分类结果,同时保留其余属性。在真实数据上的实验表明,该模型在人的感知隐私保护方面具有较好的性能。
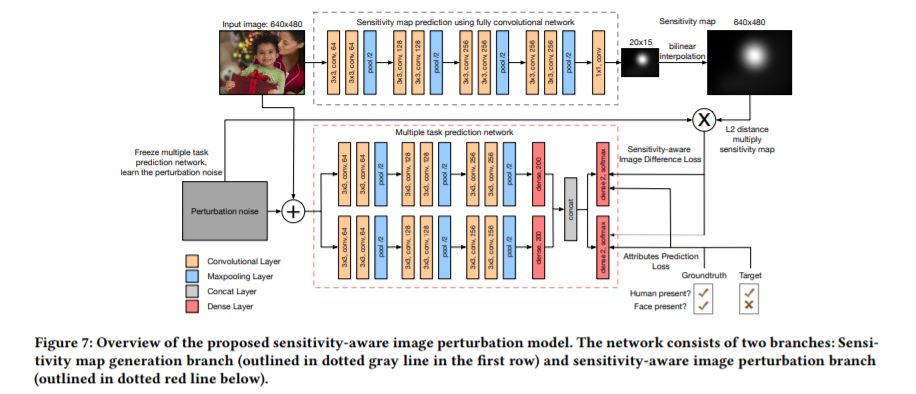
论文地址:
https://dl.acm.org/citation.cfm?id=3350963
最佳论文候选
标题:可解释医疗问答 Multi-modal Knowledge-aware Hierarchical Attention Network for Explainable Medical Question Answering
作者:Yingying Zhang, Shengsheng Qian, Quan Fang, Changsheng Xu
摘要:在线医疗服务可以为公众提供无处不在的获取医疗知识的途径,特别是随着医疗问题回答网站的出现,病人可以在不去医院的情况下与医生取得联系。可解释性和准确性是医学问题回答的两个主要关注点。然而,现有的方法主要侧重于准确性,无法很好地解释检索到的医学答案。提出了一种新的多模态知识感知层次注意网络(MKHAN),有效地利用多模态知识图(MKG)进行可解释的医学问题回答。MKHAN可以通过组合实体的结构、语言学和可视化信息来生成路径表示,并通过利用MKG中的路径中的顺序依赖关系来推断问答交互的基本原理。在此基础上,提出了一种新的层次注意网络来区分路径的显著性,使我们的模型具有可解释性。我们建立了一个大型的多模态医学知识图和两个真实的医学问题回答数据集,实验结果表明,我们的方法比目前最先进的方法有更好的性能。
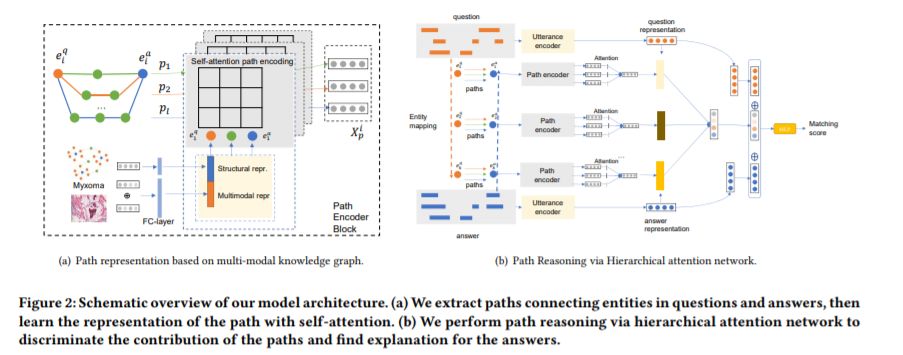
本篇论文来自中科院自动化所模式国重多媒体计算组专知
论文地址:
https://dl.acm.org/citation.cfm?id=3351033
标题:Multimodal Dialog System: Generating Responses via Adaptive Decoders
作者:Liqiang Nie, Wenjie Wang, Richang Hong, Meng Wang, Qi Tian
摘要:站在文本对话系统的肩膀上,多模态对话系统最近引起了越来越多的关注,尤其是在零售领域。尽管多模式对话系统具有商业价值,但它们仍面临以下挑战:1)以适当的媒体形式自动生成正确的回复;2)在选择产品图片时,共同考虑视觉提示和辅助信息;3)利用多方面的异构知识指导响应的产生。为了解决上述问题,我们提出了一种具有适应解码器的多模态对话系统,简称为MAGIC。尤其,MAGIC首先通过理解给定多模态上下文的意图来判断响应类型和相应的媒体形式。此后,它采用自适应解码器来生成所需的响应:简单的递归神经网络(RNN)用于生成一般响应,然后一种考虑知识的RNN解码器被用来编码多形式的领域知识以丰富响应,多模态响应解码器使用了一个神经图像推荐模型,该推荐模型同时考虑了文本属性和图像视觉信息,该模型是使用max-margin损失进行优化的。我们在基准数据集上通过对比验证了MAGIC的合理性。实验结果表明,MAGIC的性能优于现有方法,并达到了最先进的性能。
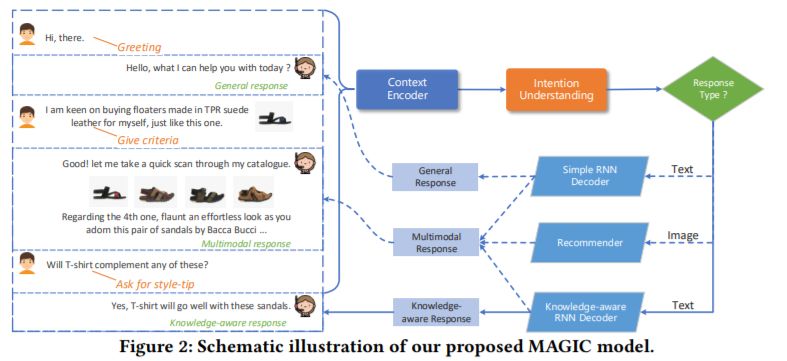
论文地址:
https://dl.acm.org/citation.cfm?id=3350923
标题:Flexible Online Multi-modal Hashing for Large-scale Multimedia Retrieval
作者:Xu Lu, Lei Zhu, Zhiyong Cheng, Jingjing Li, Xiushan Nie, Huaxiang Zhang
摘要:多模态哈希融合了离线训练和在线查询阶段的多模态特征,实现了紧凑的二进制哈希学习。高效大规模多媒体检索的研究已引起了人们的广泛关注。但现有的学习方法多采用批量学习模式或无监督学习模式。它们不能有效地处理非常常见的在线流多模态数据(用于批处理学习方法),也不能有效地学习对各种流数据(用于现有的在线多模态哈希方法)具有有限鉴别能力和较少灵活性的哈希码。本文提出了一种监督式的柔性在线多模态哈希(FOMH)方法,该方法可自适应地融合异构模式,并可灵活地学习新数据的判别哈希码,即使其中的一部分模式缺失。该算法不采用固定权值,而是采用灵活的多模态二值投影自动学习模态权值,及时捕获流化样本的变化。此外,我们设计了一种有效的非对称在线监督哈希策略,以提高哈希码的识别能力,同时避免对称语义矩阵分解和存储开销。此外,为了支持快速哈希更新和避免在线学习过程中二进制量化错误的传播,我们提出了直接更新哈希码的有效离散在线优化方法。在多个公共多媒体检索数据集上的实验从多个方面验证了该方法的优越性。
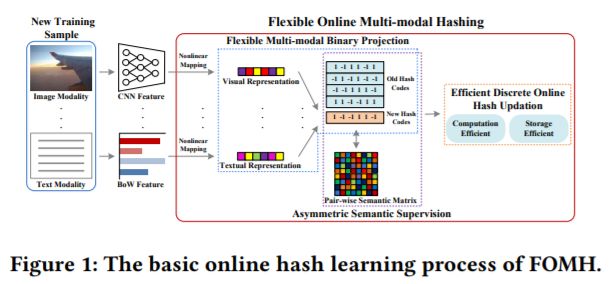
论文地址:
https://dl.acm.org/citation.cfm?id=3350999
开源软件竞赛冠军

Visual SLAM“OpenVSLAM”在ACM多媒体2019开源软件大赛中获得第一名。
软件地址:
https://github.com/xdspacelab/openvslam
论文地址:https://www.zhuanzhi.ai/paper/975dd0cb7a0144fbfee61d2d9c920509
视频地址:
https://www.youtube.com/watch?v=Ro_s3Lbx5ms
最佳演示Demo奖
使用GANs的移动设备上实时提高视频质量,获得了最佳演示奖






