韩家炜课题组重磅发文:文本分类只需标签名称,不需要任何标注数据!

文 | JayLou娄杰
源 | 高能AI
文本分类的一个大型“真香现场”来了:昨天JayJay的推文《超强文本半监督MixText》中告诉大家不要浪费没有标注过的数据,但还是需要有标注数据的!但今天介绍的这篇paper,文本分类居然不需要任何标注数据啦!哇,真香!
当前的文本分类任务需要利用众多标注数据,标注成本是昂贵的。而半监督文本分类虽然减少了对标注数据的依赖,但还是需要领域专家手动进行标注,特别是在类别数目很大的情况下。
试想一下,我们人类是如何对新闻文本进行分类的?其实,我们不要任何标注样本,只需要利用和分类类别相关的少数词汇就可以啦,这些词汇也就是我们常说的关键词。
BUT!我们之前获取分类关键词的方式,大多还是需要靠人工标注数据、或者人工积累关键词表的;而就算积累了某些关键词,关键词在不同上下文中也会代表不同类别。
那么,有没有一种方式,可以让文本分类不再需要任何标注数据呢?
本文JayJay就介绍一篇来自「伊利诺伊大学香槟分校韩家炜老师课题组」的EMNLP20论文《Text Classification Using Label Names Only: A Language Model Self-Training Approach》。
这篇论文的最大亮点就是:不需要任何标注数据,只需利用标签名称,就在四个分类数据上获得了近90%的准确率!
为此,论文提出一种LOTClass模型,即Label-name-Only Text Classification,LOTClass模型的主要亮点有:
-
不需要任何标注数据,只需要标签名称! 只依赖预训练语言模型( LM),不需要其他依赖! -
提出了 类别指示词汇获取方法和 基于上下文的单词类别预测任务,经过如此训练的LM进一步对未标注语料进行自训练后,可以很好泛化! -
在四个分类数据集上, LOTClass明显优于各弱监督模型,并具有与强半监督和监督模型相当的性能。
论文下载:https://arxiv.org/pdf/2010.07245.pdf
代码开源:https://github.com/yumeng5/LOTClass
本文的组织结构为:
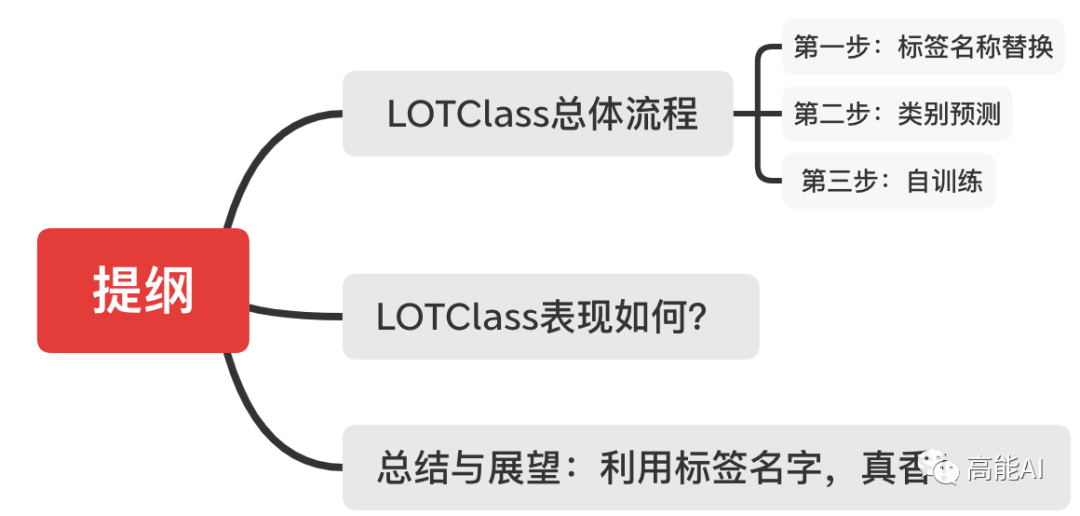
LOTClass总体流程
LOTClass将BERT作为其backbone模型,其总体实施流程分为以下三个步骤:
-
标签名称替换:利用并理解标签名称,通过MLM生成类别词汇; -
类别预测:通过MLM获取类别指示词汇集合,并构建基于上下文的单词类别预测任务,训练LM模型; -
自训练:基于上述LM模型,进一步对未标注语料进行自训练后,以更好泛化!
下面我们就详细介绍上述过程。
第一步:标签名称替换
在做文本分类的时候,我们可以根据标签名称联想到与之相关联的其他关键词,这些关键词代表其类别。当然,这就需要我们从一个蕴含常识的模型去理解每个标签的语义。很明显,BERT等预训练LM模型就是一个首选!
论文采取的方法很直接:对于含标签名称的文本,通过MLM来预测其可以替换的其他相似词汇。

如上图展示了AG新闻语料(体育新闻)中,对于标签名称“sports”,可通过MLM预测出替换「sports」的相似词汇。
具体地,每一个标签名称位置通过MLM预测出TOP-50最相似的替换词,然后再整体对每一个类别的标签名称(Label Name)根据词频大小、结合停用词共选取TOP-100,最终构建类型词汇表(Category Vocabulary)。
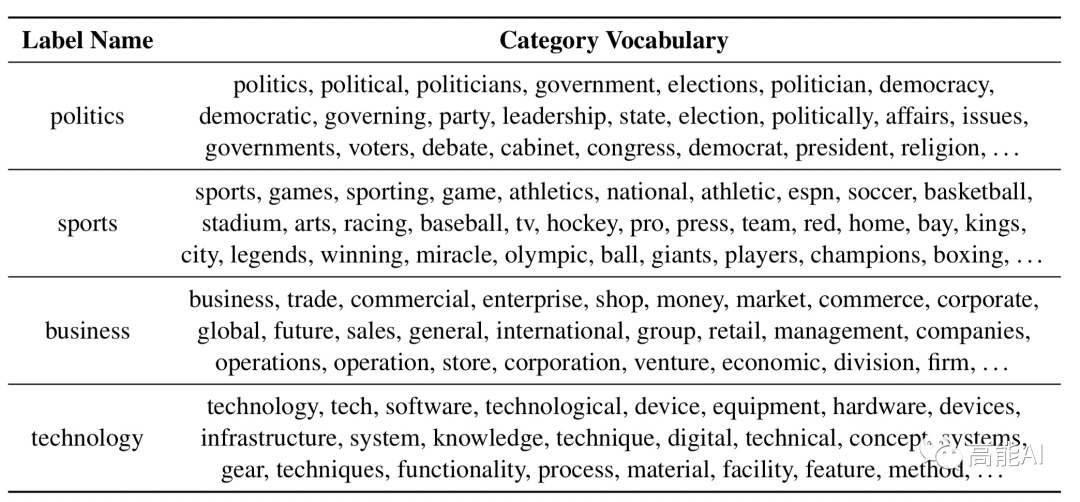
通过上述方式找出了AG新闻语料每一个类别-标签名称对应的类别词汇表,如上图所示。
第二步:类别预测
像人类如何进行分类一样,一种直接的方法是:利用上述得到的类型词汇表,然后统计语料中类别词汇出现的次数。但这种方式存在2个缺陷:
-
不同词汇在不同的上下文中代表不同意思,不是所有在语料中出现的 类型词汇都指示该类型。在第一幅图中,我们就可以清晰发现:单词「sports」在第2个句子并不代表体育主题。 -
类型词汇表的覆盖范围有限:在特定上下文中,某些词汇与类别关键词具有相似的含义,但不包含在类别词汇表中。
为了解决上述缺陷,论文构建了一个新的MCP任务——基于MASK的类别预测任务(Masked Category Prediction,MCP),如下图所示:
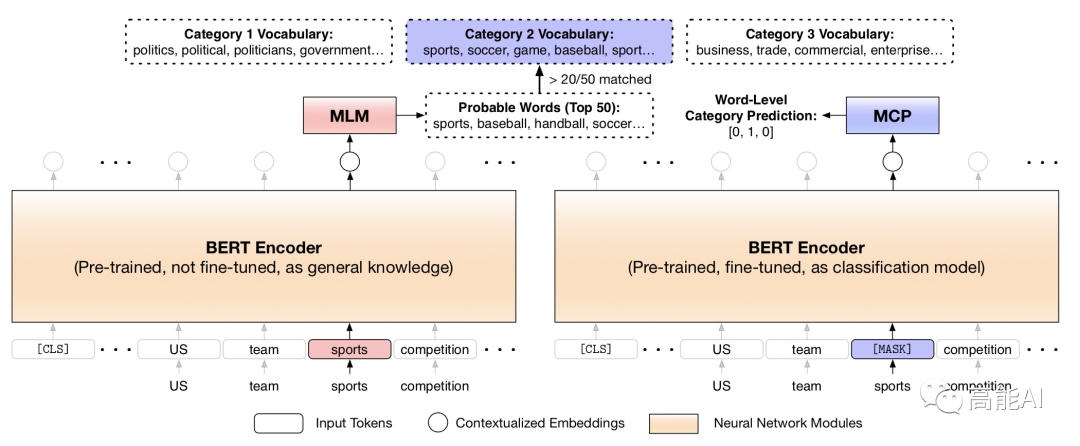
MCP任务共分为两步:
-
获取类别指示词:上述已经提到, 类别词汇表中不同的词汇在不同上下文会指代不同类别。论文建立了一种获取 类别词汇指示的方法(如上图左边所示):对于当前词汇,首先通过BERT的MLM任务预测当前词汇可替代的TOP50相似词,然后TOP50相似词与每个 类别词汇表进行比对,如果有超过20个词在当前 类别词汇表中,则选取 当前词汇作为该类别下的「 类别指示词」。 -
进行遮蔽类别预测:通过上一步,遍历语料中的每一个词汇,我们就可得到 类别指示词集合和词汇所对应的标签。对于 类别指示词集合中每一个的单词,我们将其替换为「MASK」然后对当前位置进行标签分类训练。
值得注意的是:MASK类别指示词、进行类别预测至关重要,因为这会迫使模型根据单词上下文来推断类别,而不是简单地记住无上下文的类别关键字。通过MCP任务,BERT将更好编码类别判断信息。
第三步:自训练
论文将通过MCP任务训练好的BERT模型,又对未标注语料进行了自训练。这样做的原因为:
-
仍有大规模语料未被MCP任务利用,毕竟不是每一个语料样本含有类别指示词。 -
MCP任务进行类别预测不是在「CLS」位置,「CLS」位置更利于编码全局信息并进行分类任务。

论文采取的自训练方式很简单,如上图所示,每50个batch通过软标签方式更新一次标签类别。
LOTClass表现如何?
为了验证LOTClass的效果,论文在4个分类数据集上与监督、半监督和弱监督进行了对比。
对于弱监督方法,则将整个训练集作为未标注数据;对于半监督方法,每个类别选举10个样本作为标注数据;对于监督方法,则全部训练集就是标注数据。
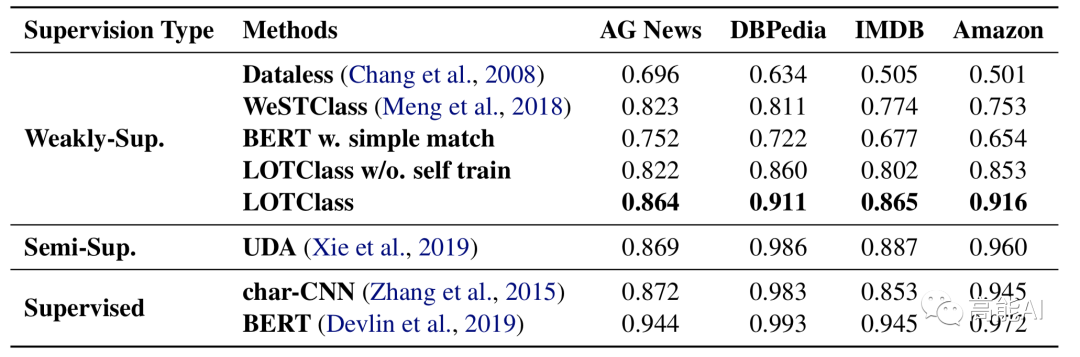
如上图所示,没有自训练的LOTClass方法就超过了一众弱监督方法,而利用自训练方法后LOTClass甚至在AG-News上可以与半监督学习的SOTA——谷歌提出的UDA相媲美了,与有监督的char-CNN方法也相差不多啦!自训练self-trainng为何如此强大?我们将在接下来的推文中会进一步介绍。
也许你还会问:LOTClass相当于使用多少标注数据呢?
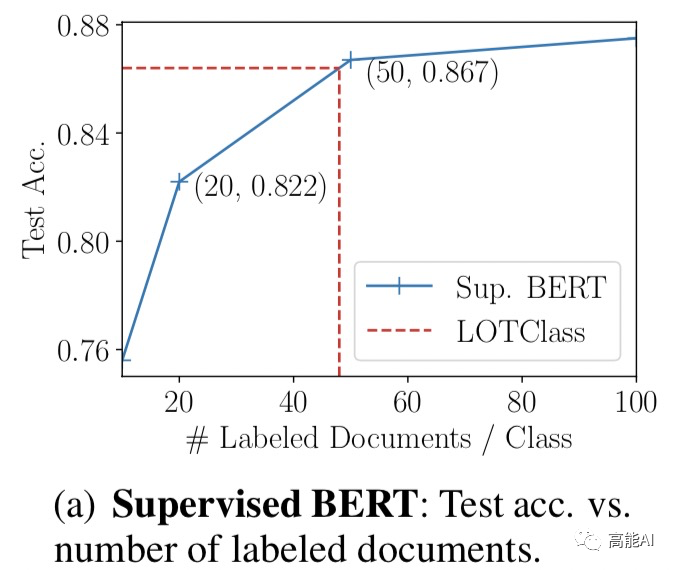
如上图,论文给出了答案,那就是:LOTClass效果相当于 每个类别使用48个标注文档的有监督BERT模型!
总结与展望:利用标签名称,真香!
首先对本文总结一下:本文提出的LOTClass模型仅仅利用标签名称,无需任务标注数据!在四个分类数据上获得了近90%的准确率,与相关半监督、有监督方法相媲美!LOTClass模型总体实施流程分三个步骤:标签名称替换,MASK类别预测,自训练。
本文提出的LOTClass模型只是基于BERT,并没有采取更NB的LM模型,每个类别最多使用3个单词作为标签名称,没有依赖其他工具(如回译方式)。我们可以预测:随着LM模型的升级,数据增强技术的使用,指标性能会更好!
利用标签名称,我们是不是还可以畅想一些“真香现场”呢?例如:
-
应用于NER任务:发现实体类别下的更多指示词,如「PERSON」类别;嗯嗯,再好好想象怎么把那套MCP任务嵌入到NER任务中吧~ -
与半监督学习更好协作:1)没有标注数据时,可以通过LOTClass构建初始标注数据再进行半监督流程;2)将MCP任务设为半监督学习的辅助任务。
由于微信平台算法改版,公号内容将不再以时间排序展示,如果大家想第一时间看到我们的推送,强烈建议星标我们和给我们多点点【在看】。星标具体步骤为:
(1)点击页面最上方“深度学习自然语言处理”,进入公众号主页。
(2)点击右上角的小点点,在弹出页面点击“设为星标”,就可以啦。
感谢支持,比心
投稿或交流学习,备注:昵称-学校(公司)-方向,进入DL&NLP交流群。
方向有很多:机器学习、深度学习,python,情感分析、意见挖掘、句法分析、机器翻译、人机对话、知识图谱、语音识别等。

记得备注呦
整理不易,还望给个在看!




