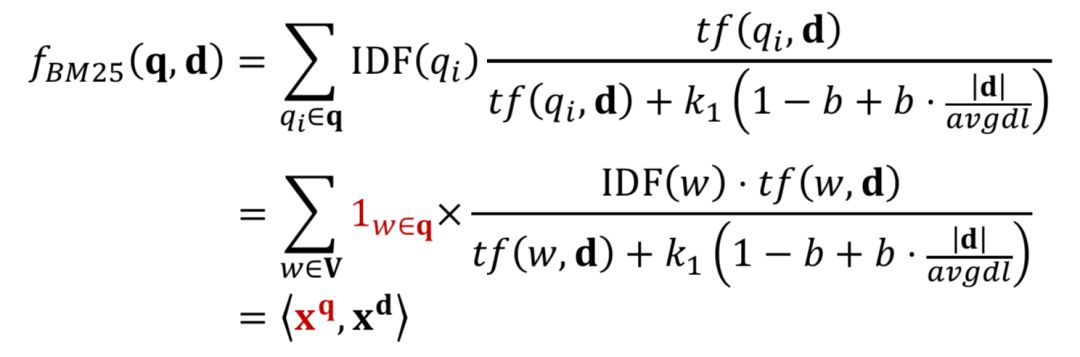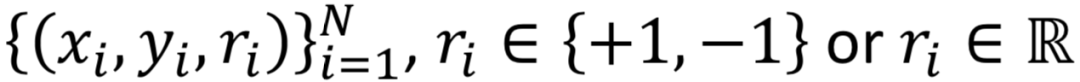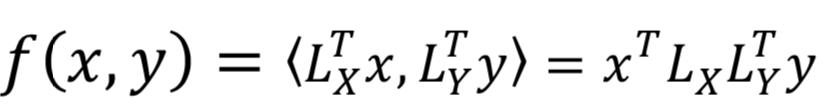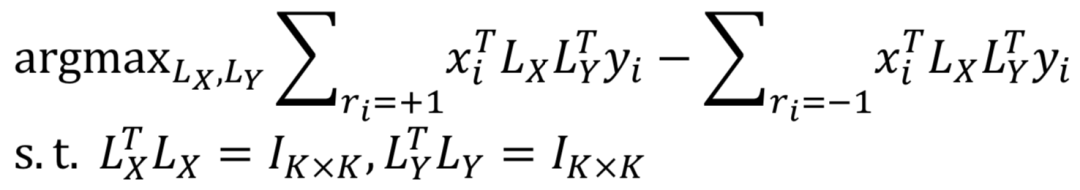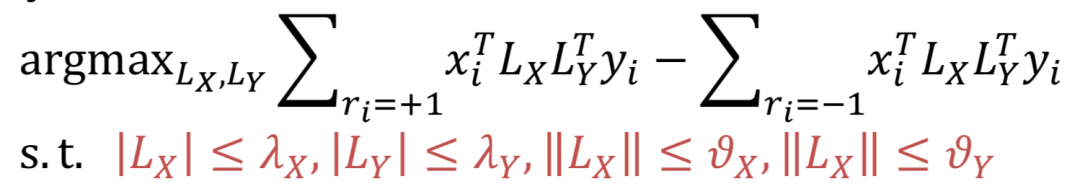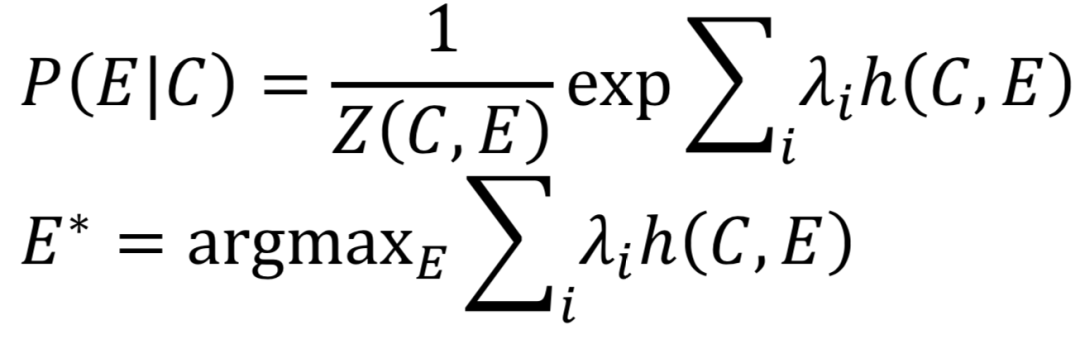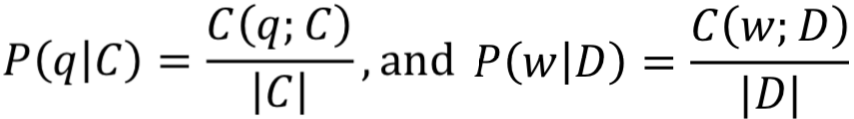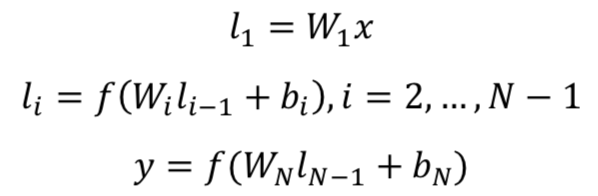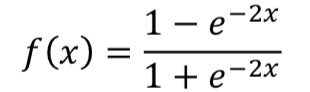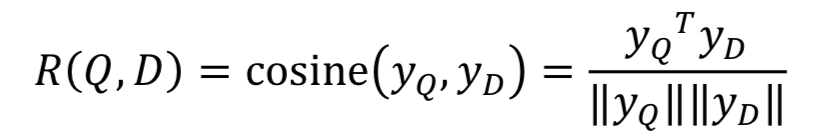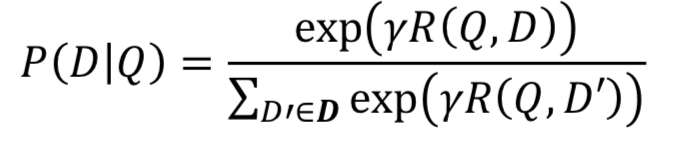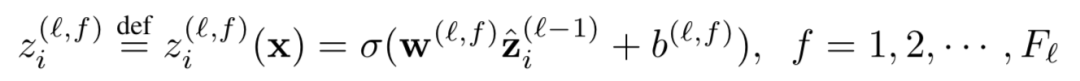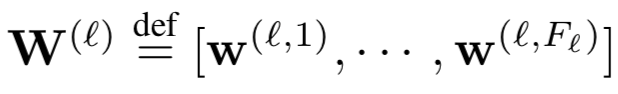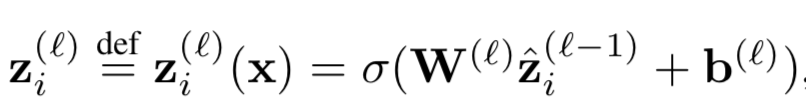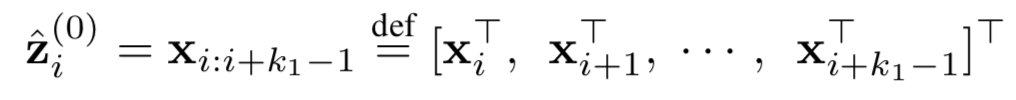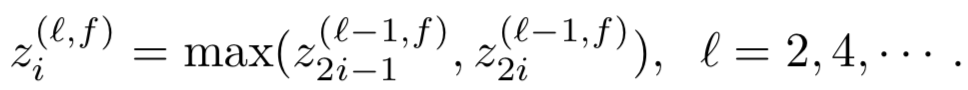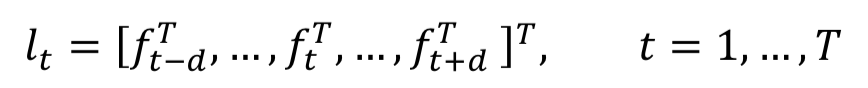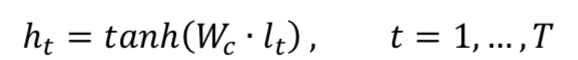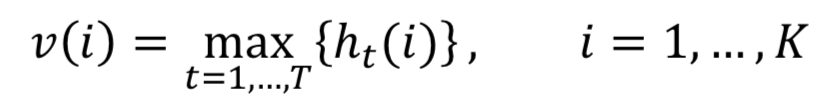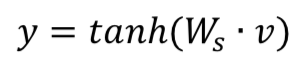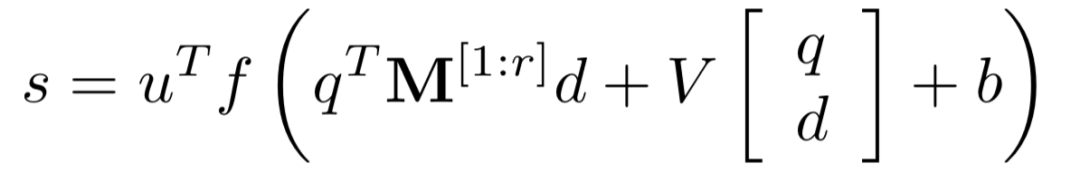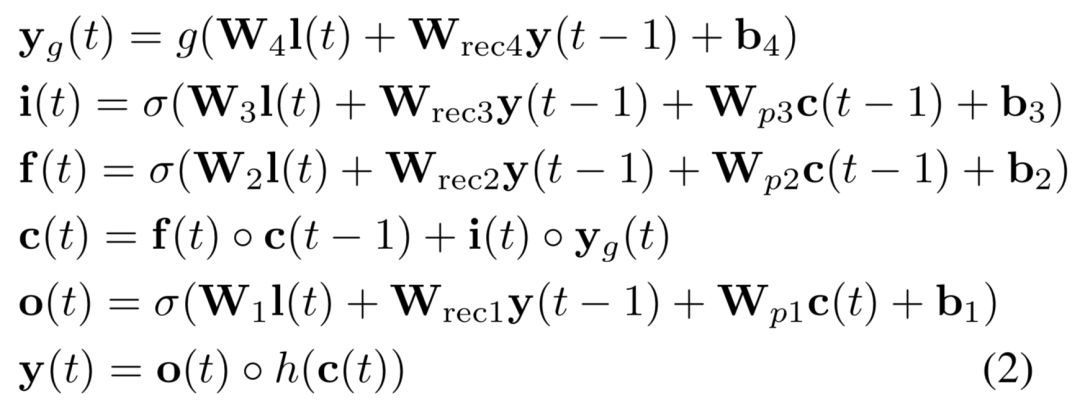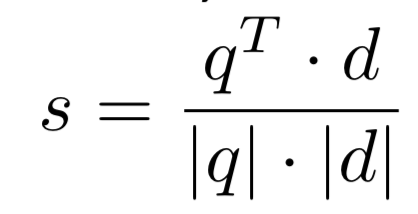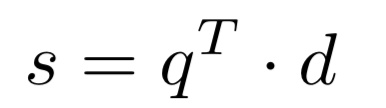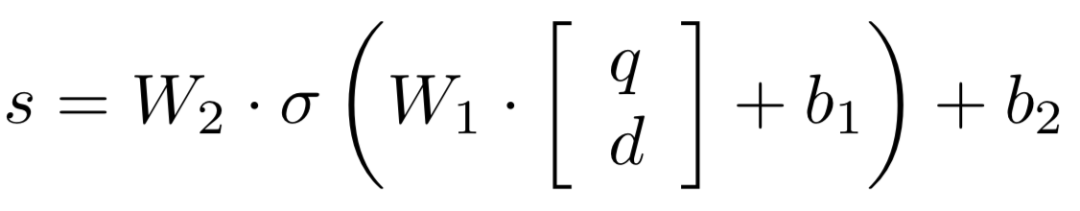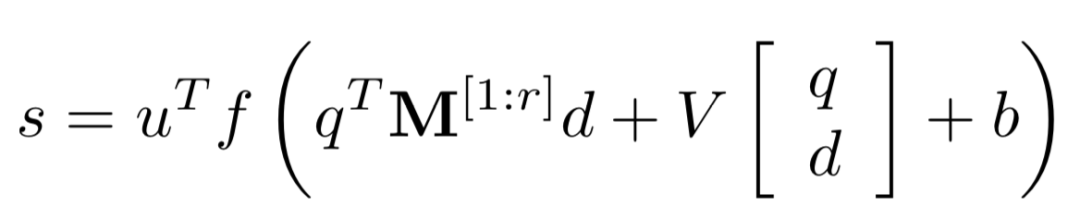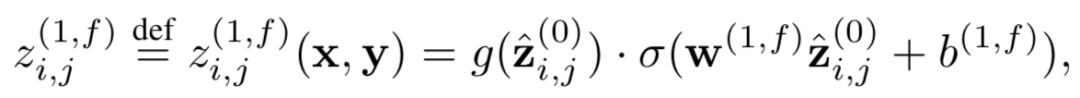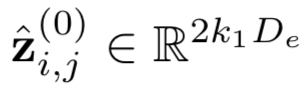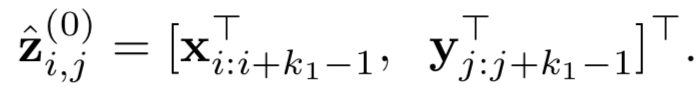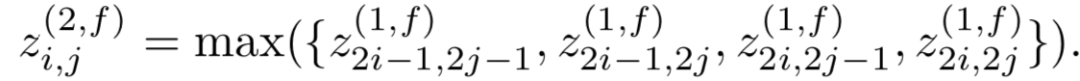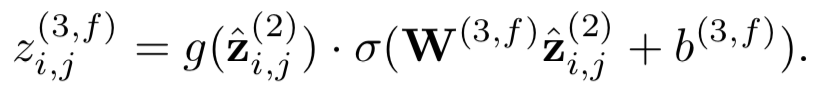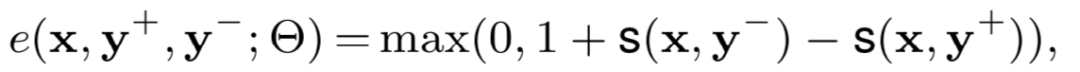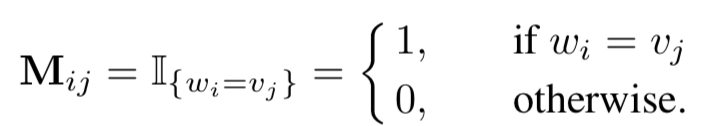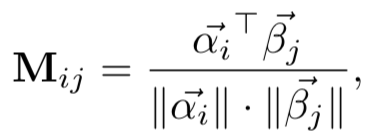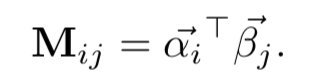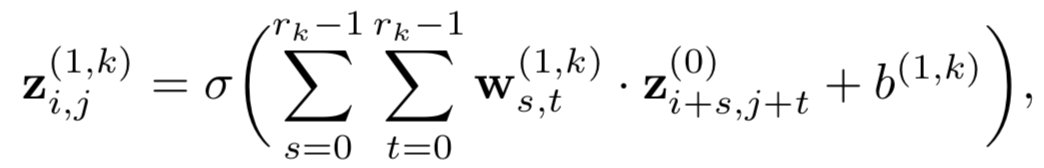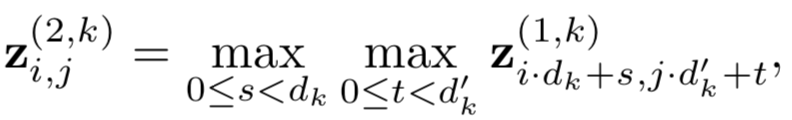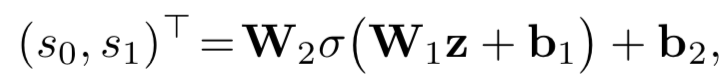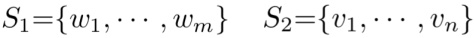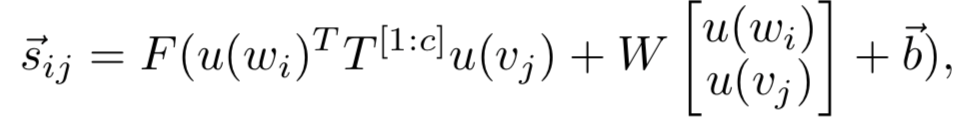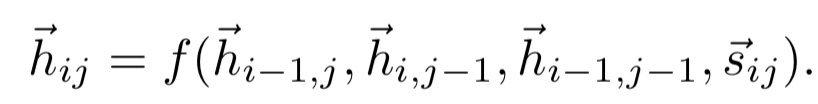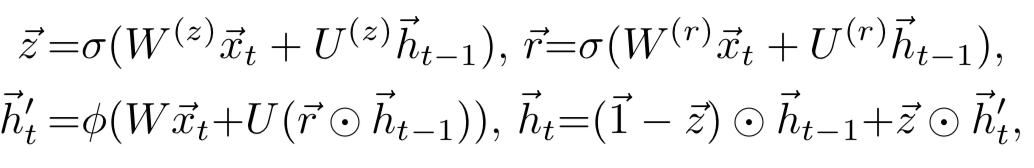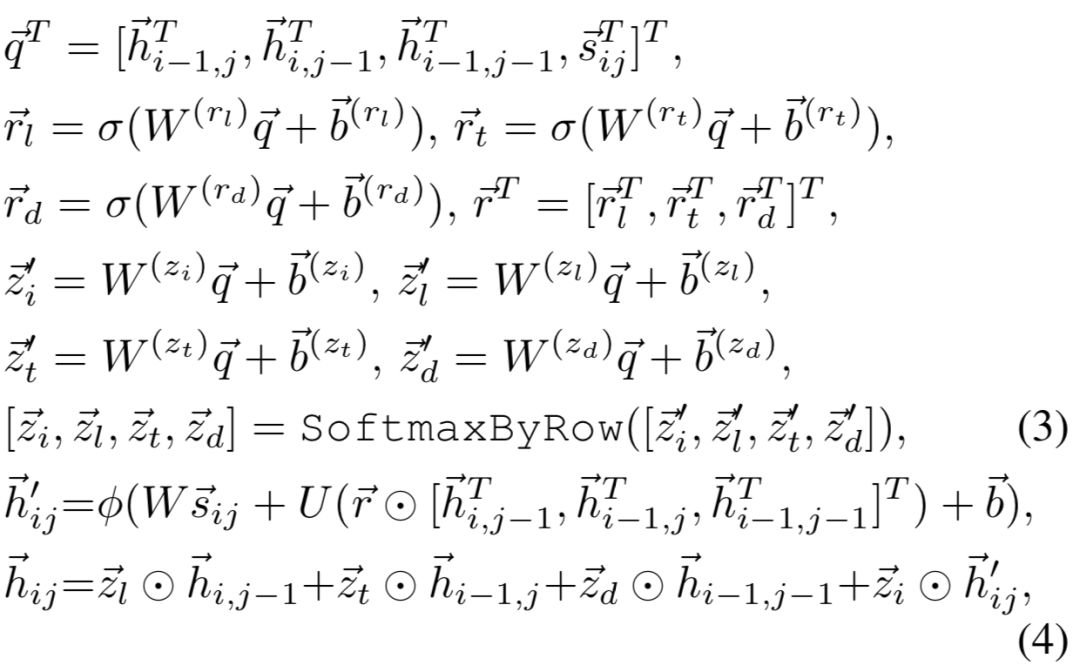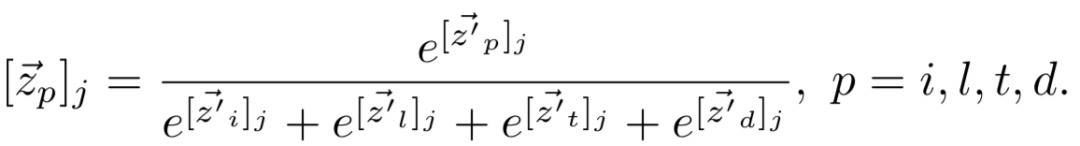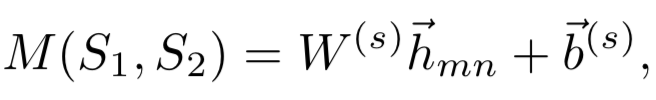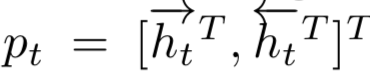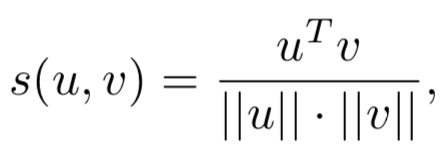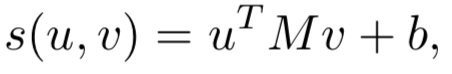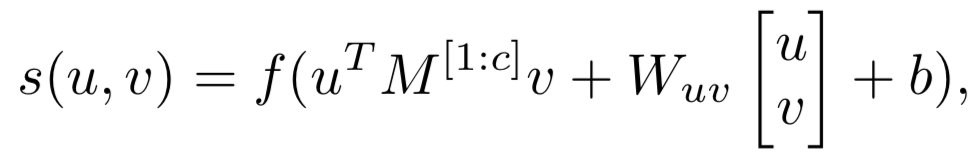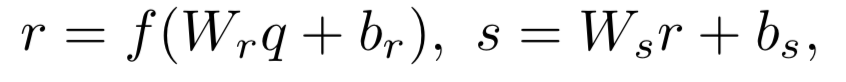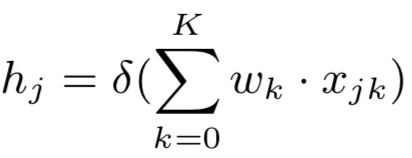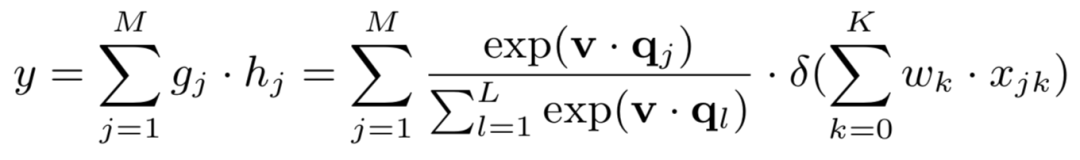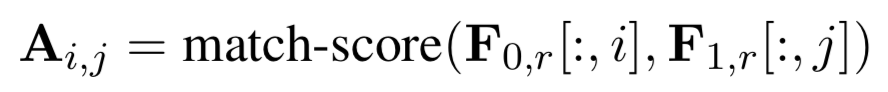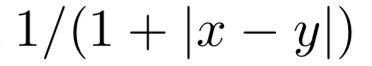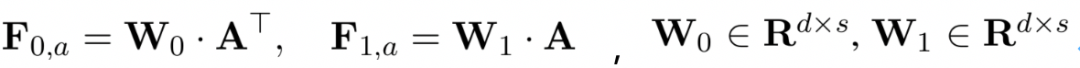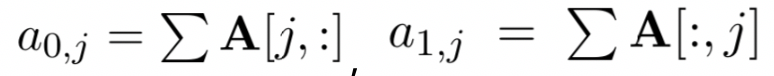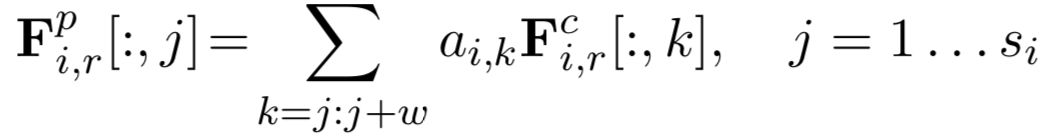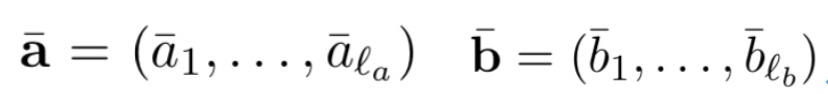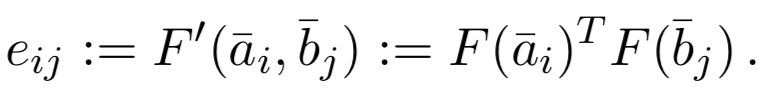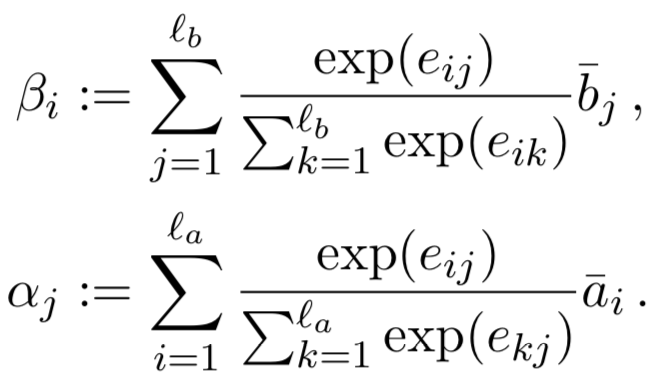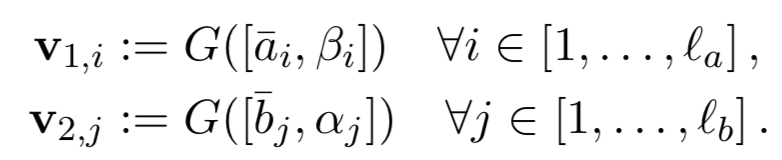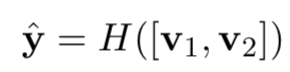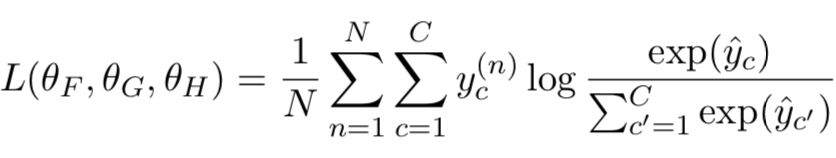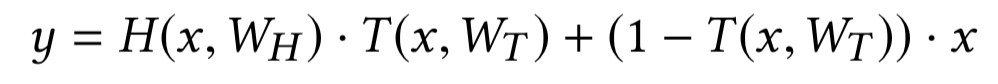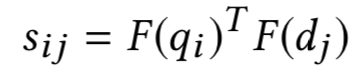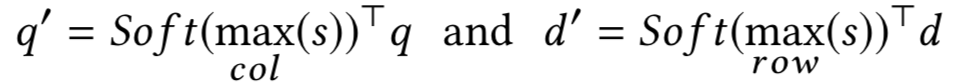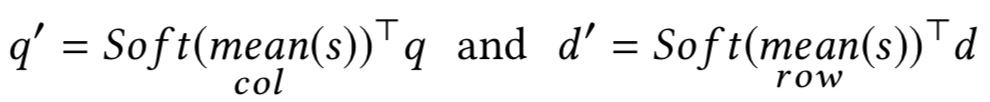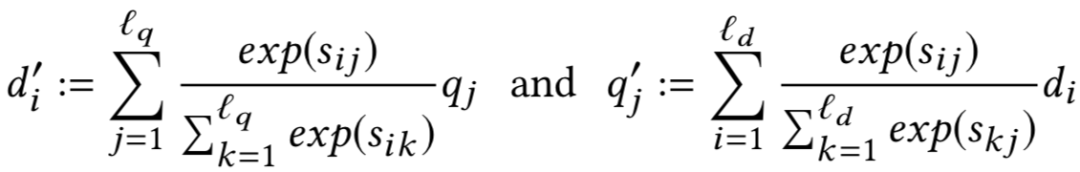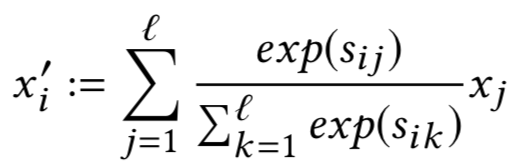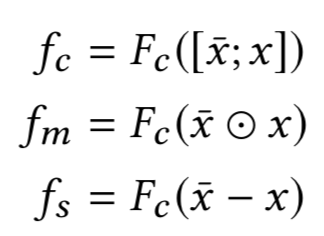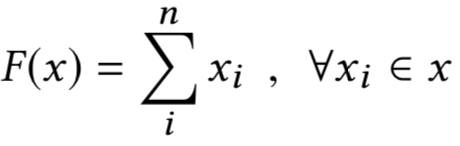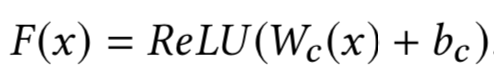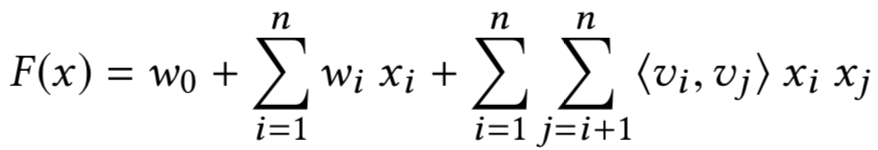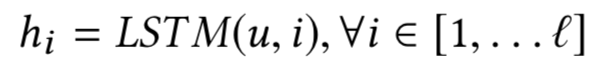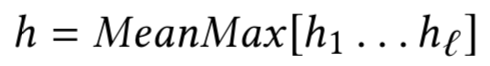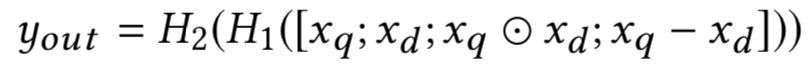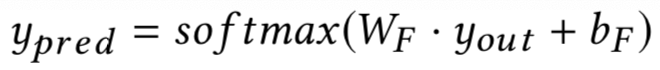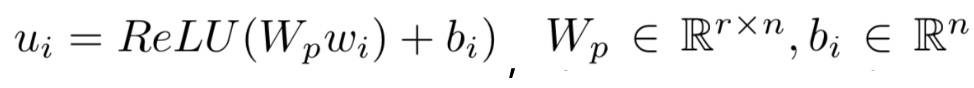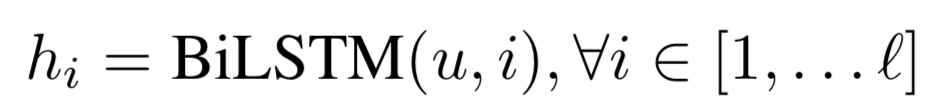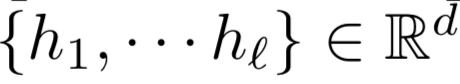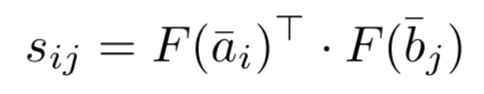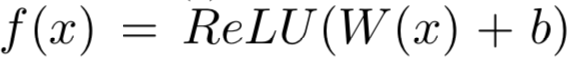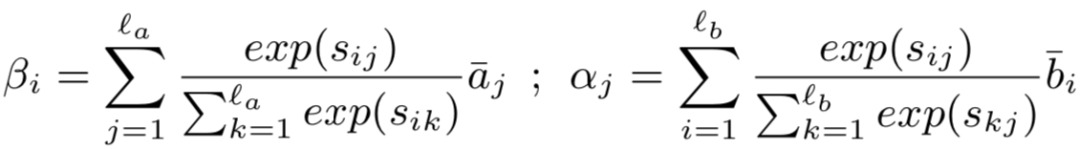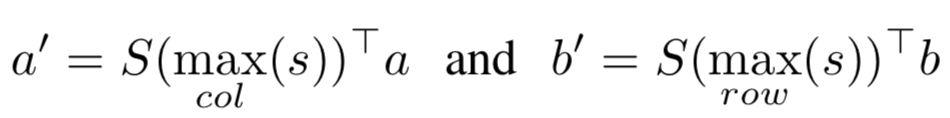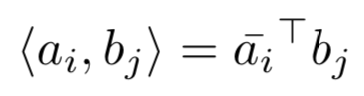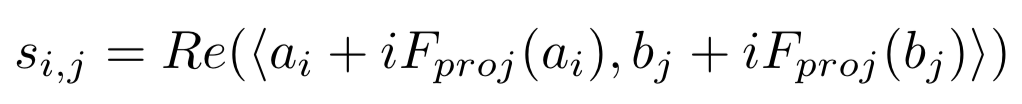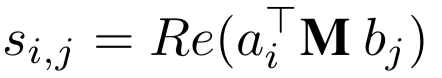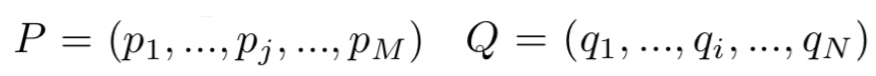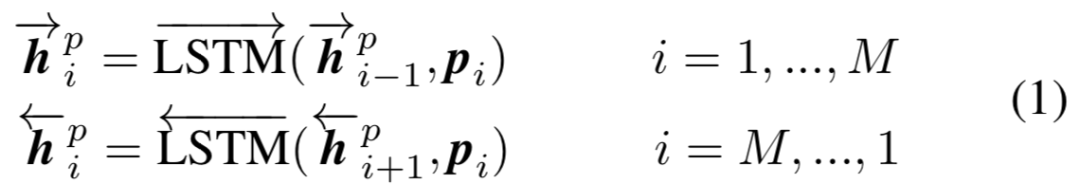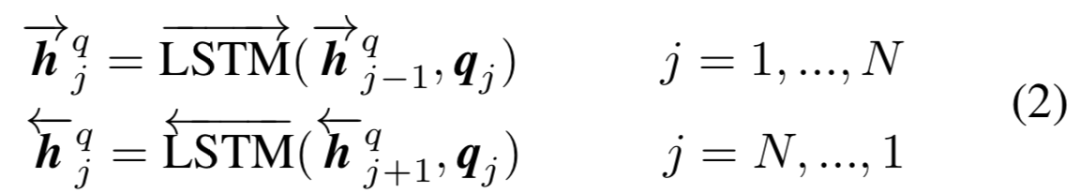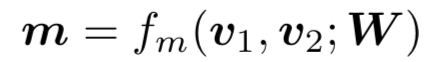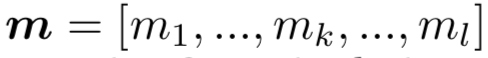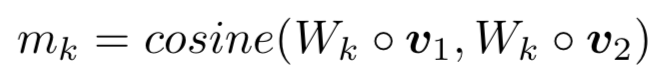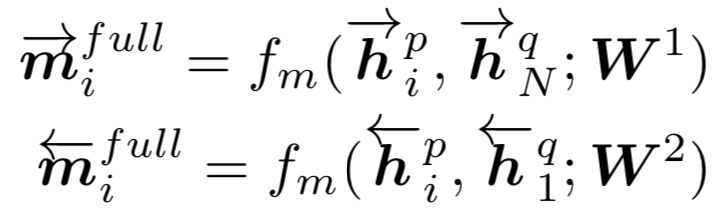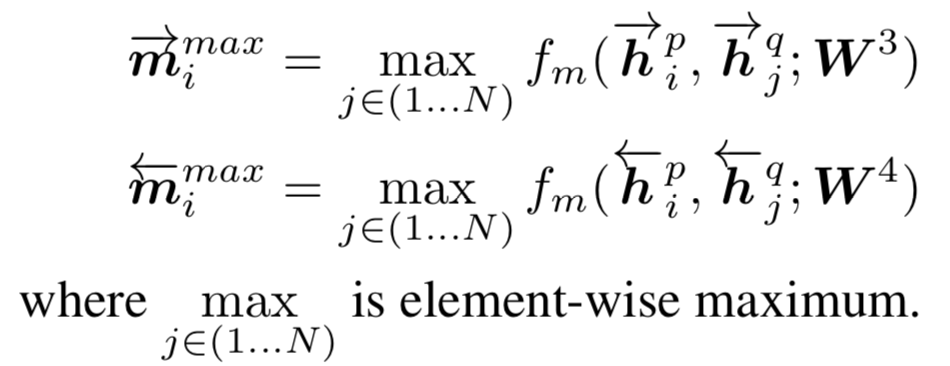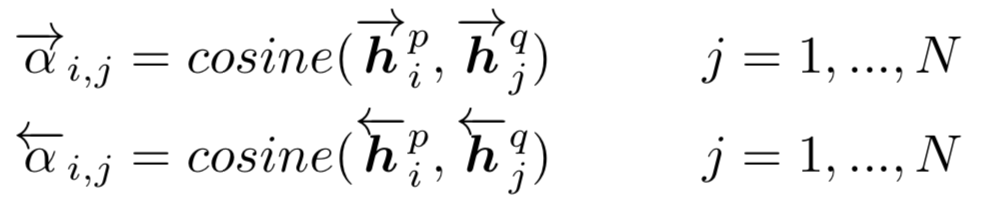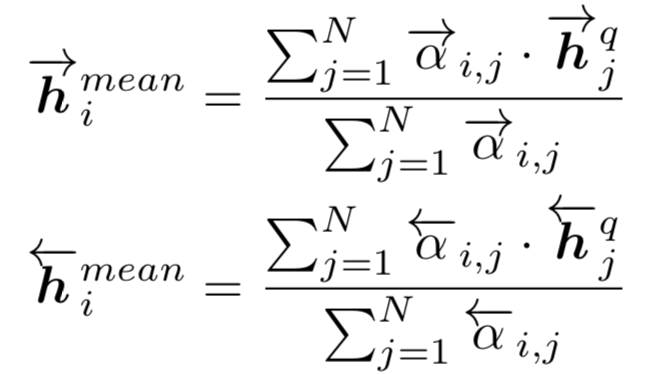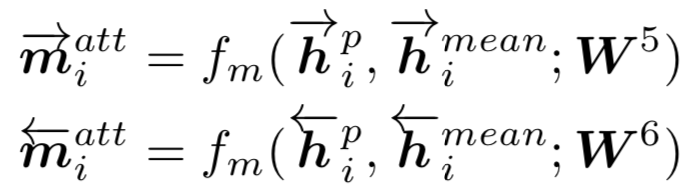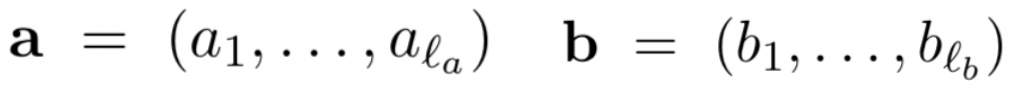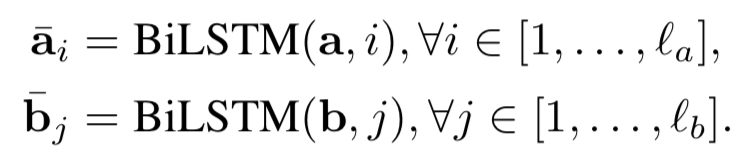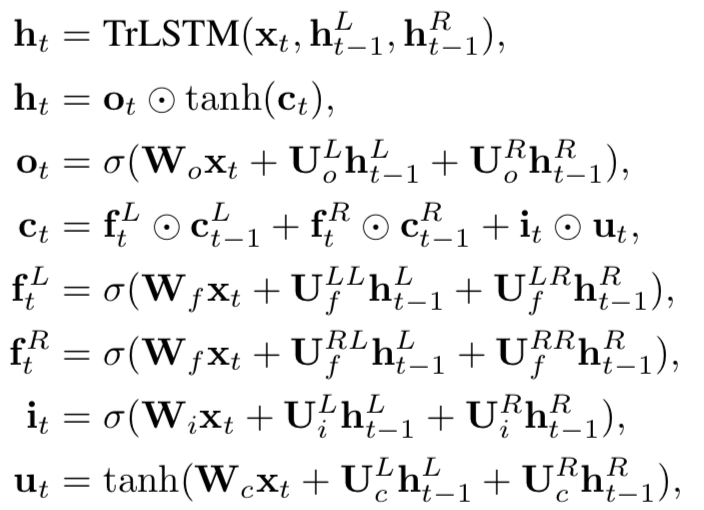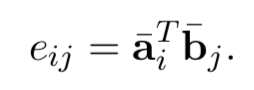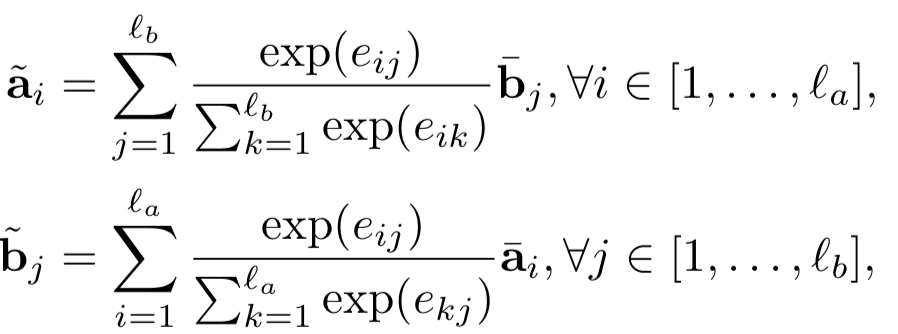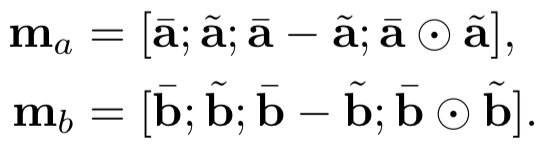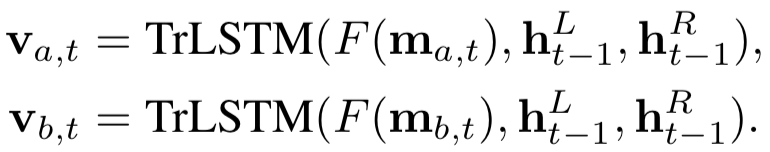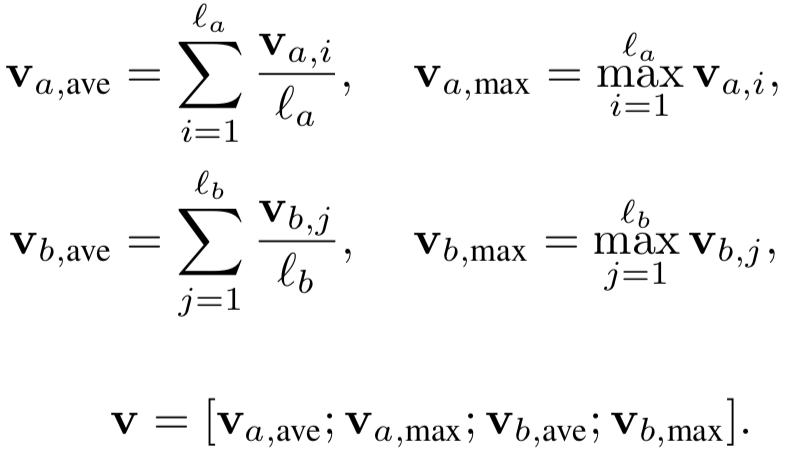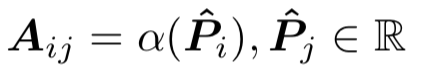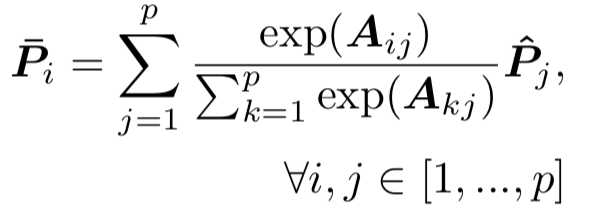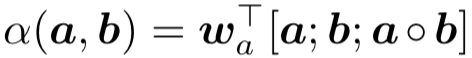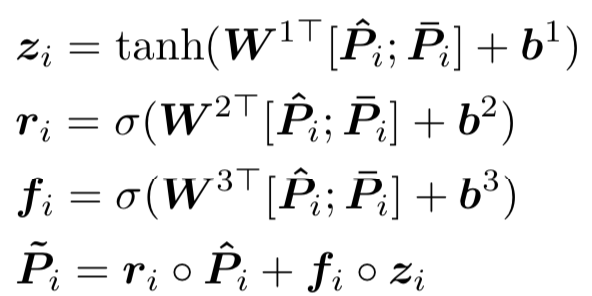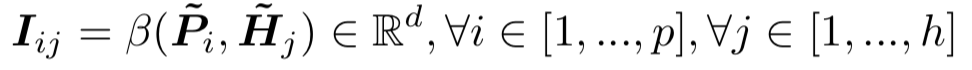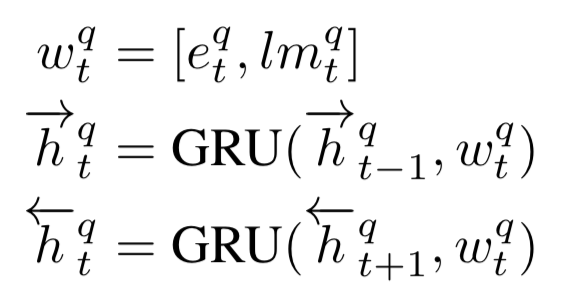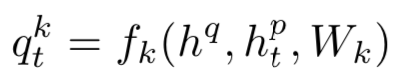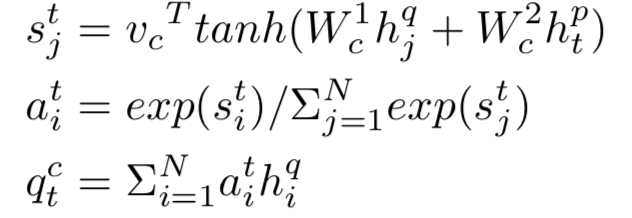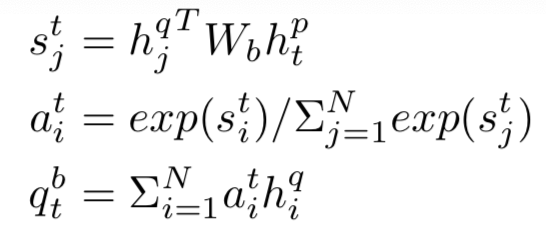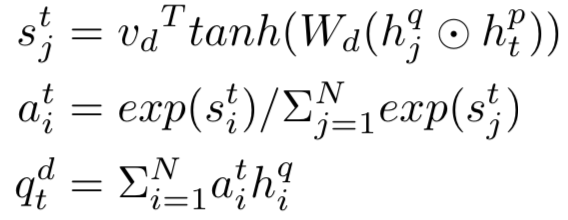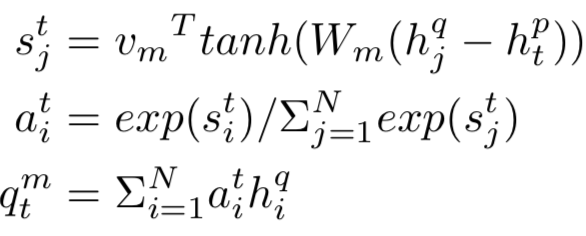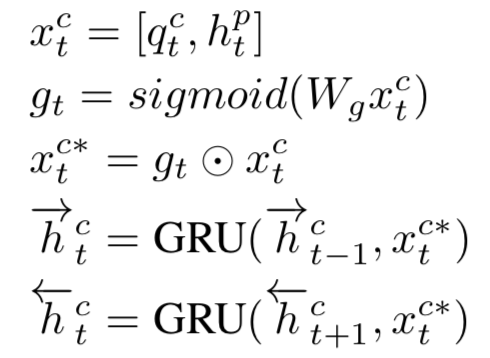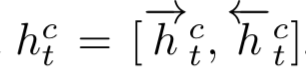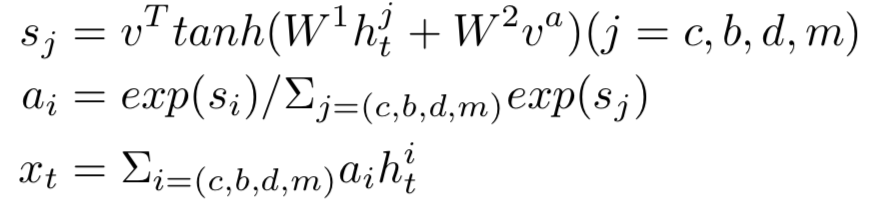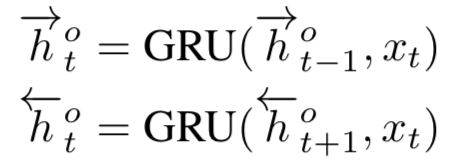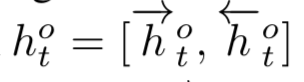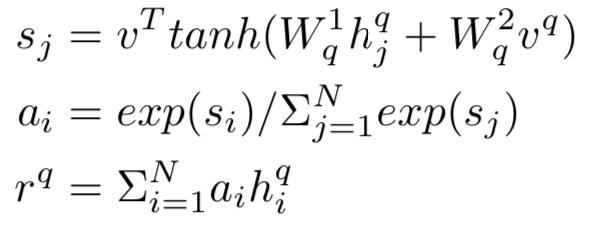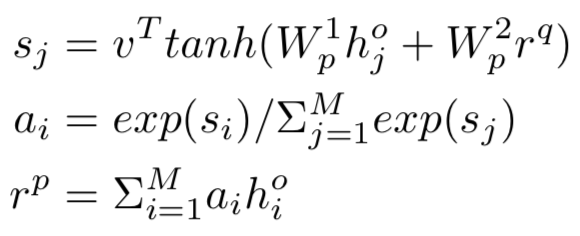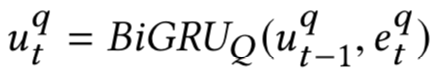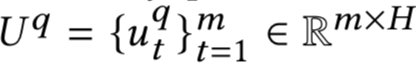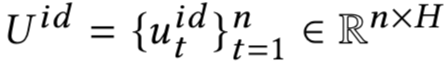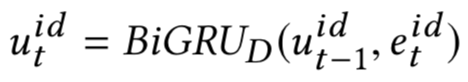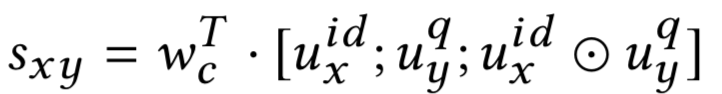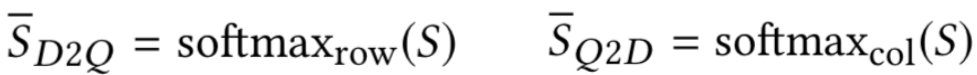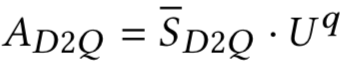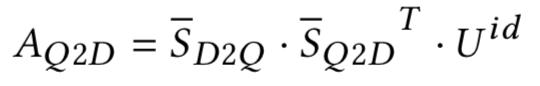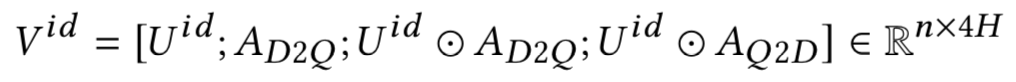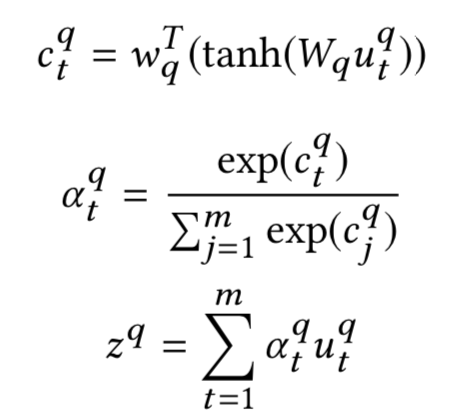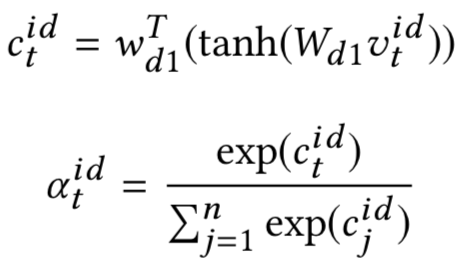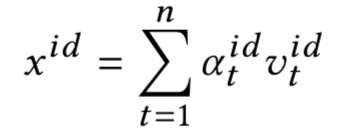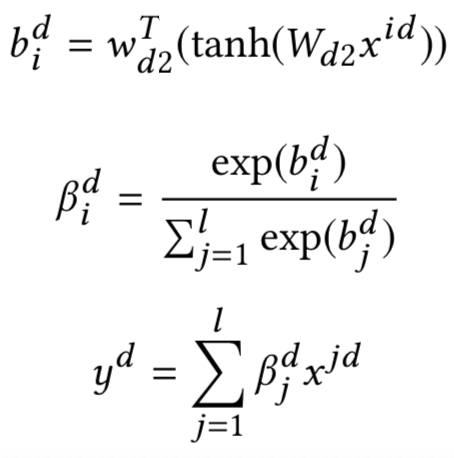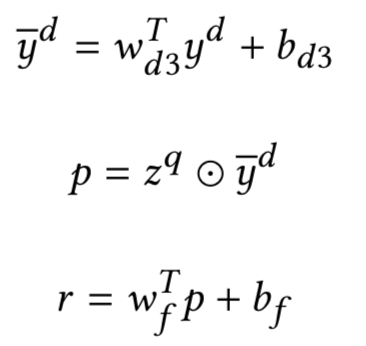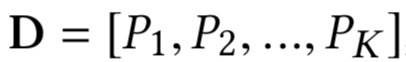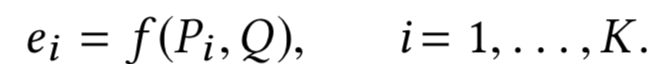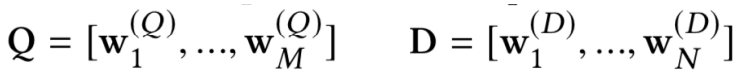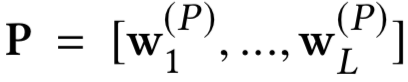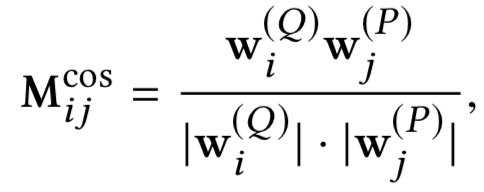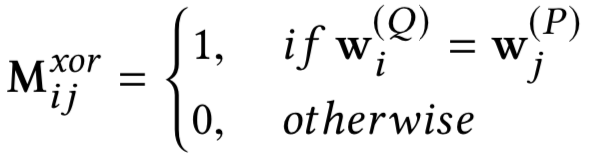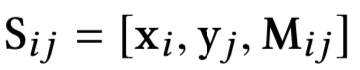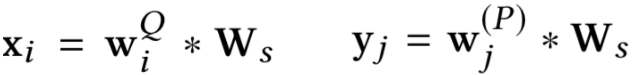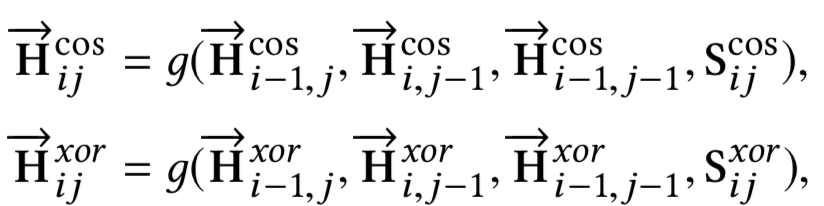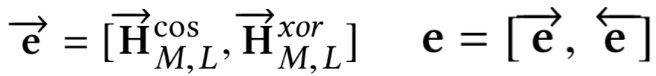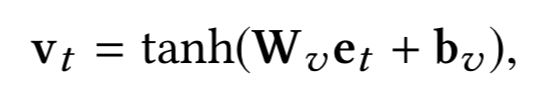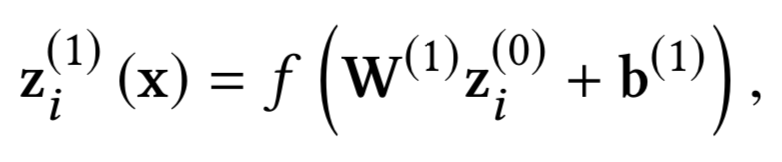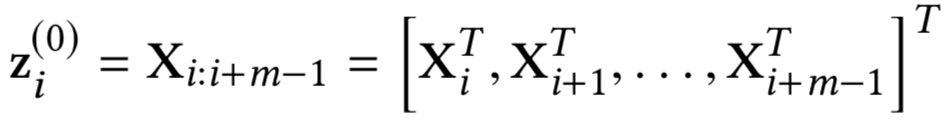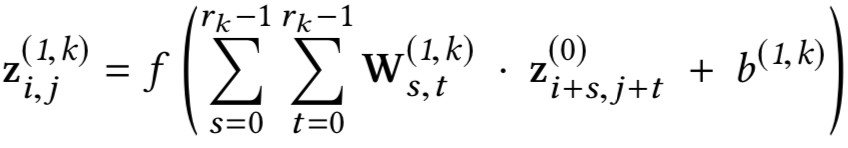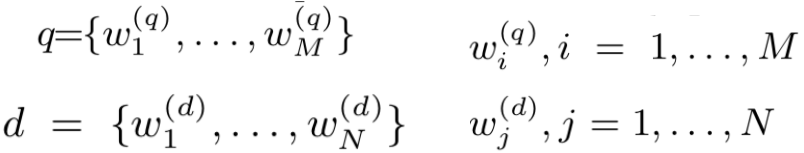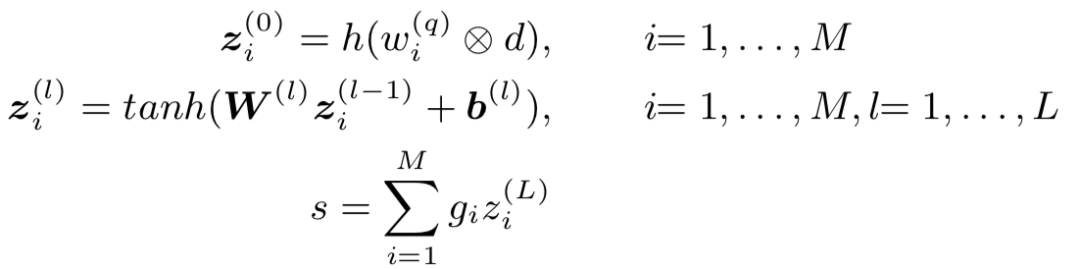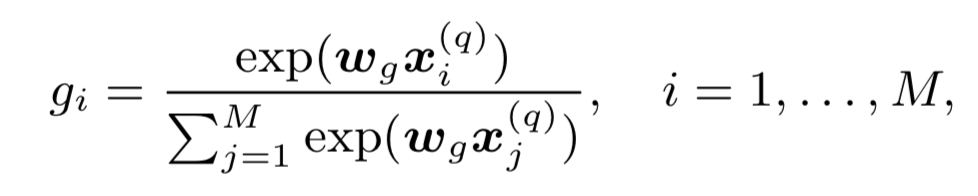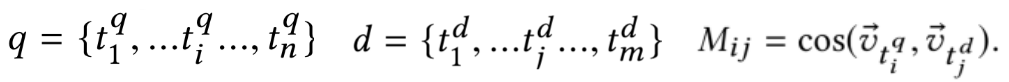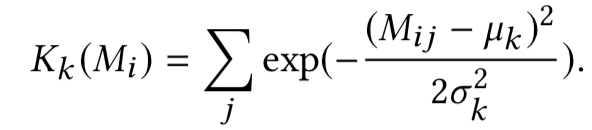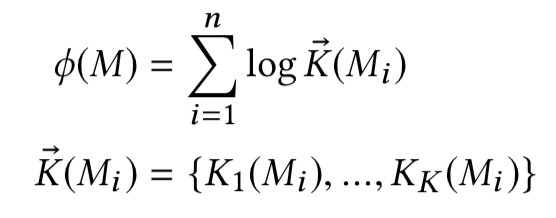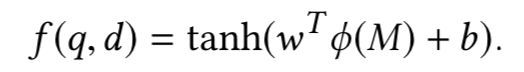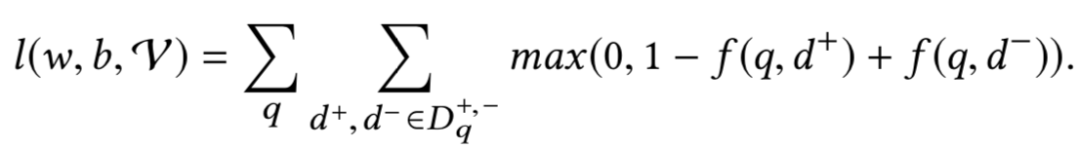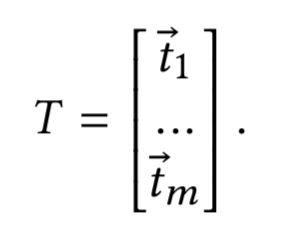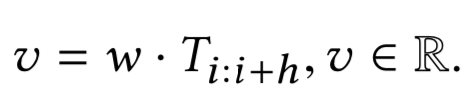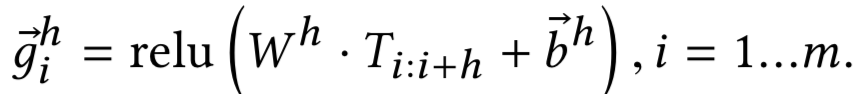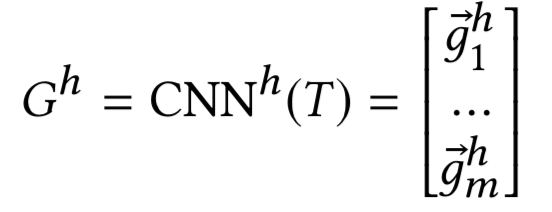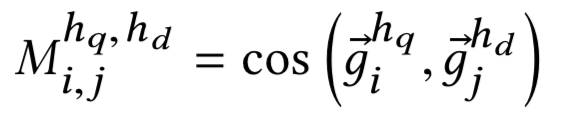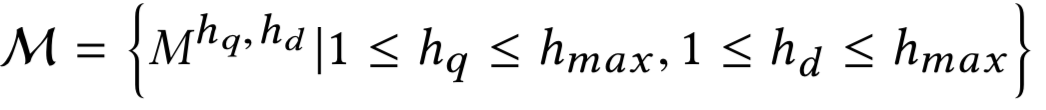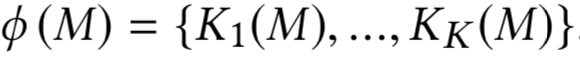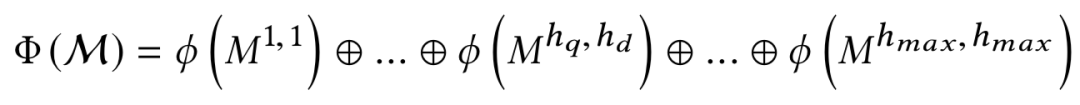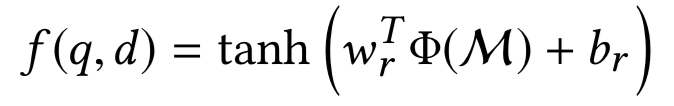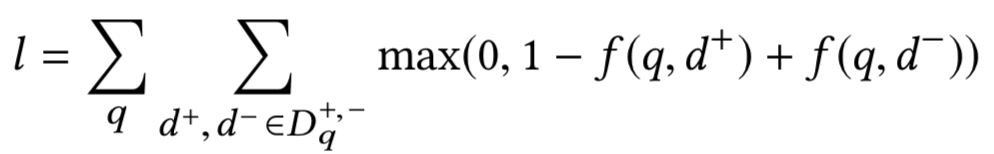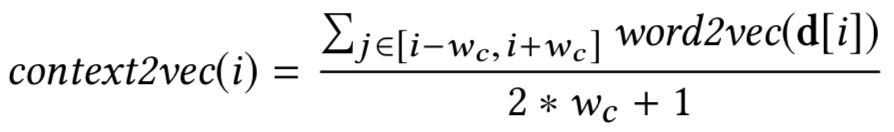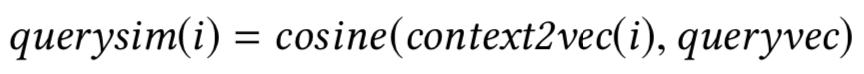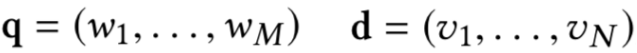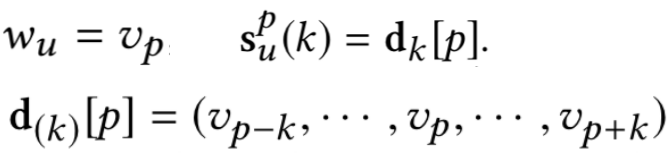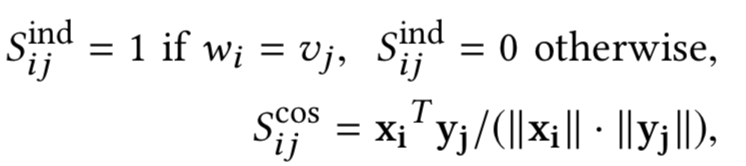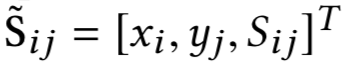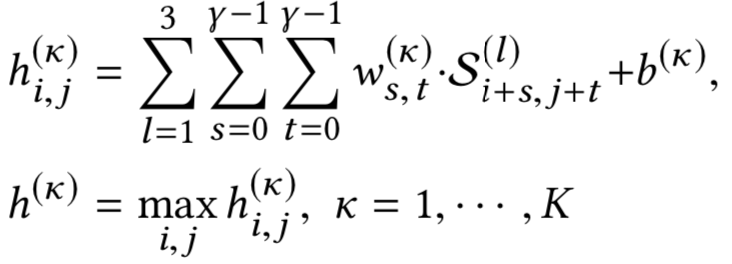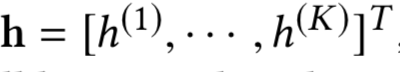文章作者:辛俊波 腾讯 高级研究员
编辑整理:Hoh Xil
内容来源:作者授权
出品平台:DataFunTalk
注:欢迎转载,转载请在留言区留言。
导读:在上一篇文章"推荐系统中的深度匹配模型"中介绍的推荐系统里的模型,大部分是对于各种神经网络的结构改造,基本不太涉及文本本身。而在本文接下来要介绍的搜索引擎中的模型里,可以发现由于query和doc本身都是由文本组成,模型的扩展性上有了大大的提升,在文本领域大放异彩的各种网络结构组合成了各种模型。
全文约45,000字,主要包括:
❹ 搜索中的相关性匹配。关于语义匹配和相关性匹配的区别,会重点展开介绍
01
▬
搜索引擎概述
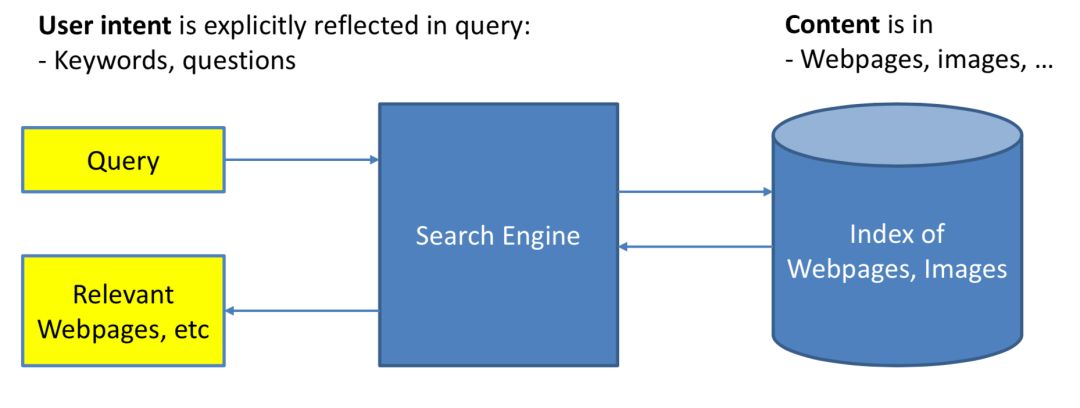
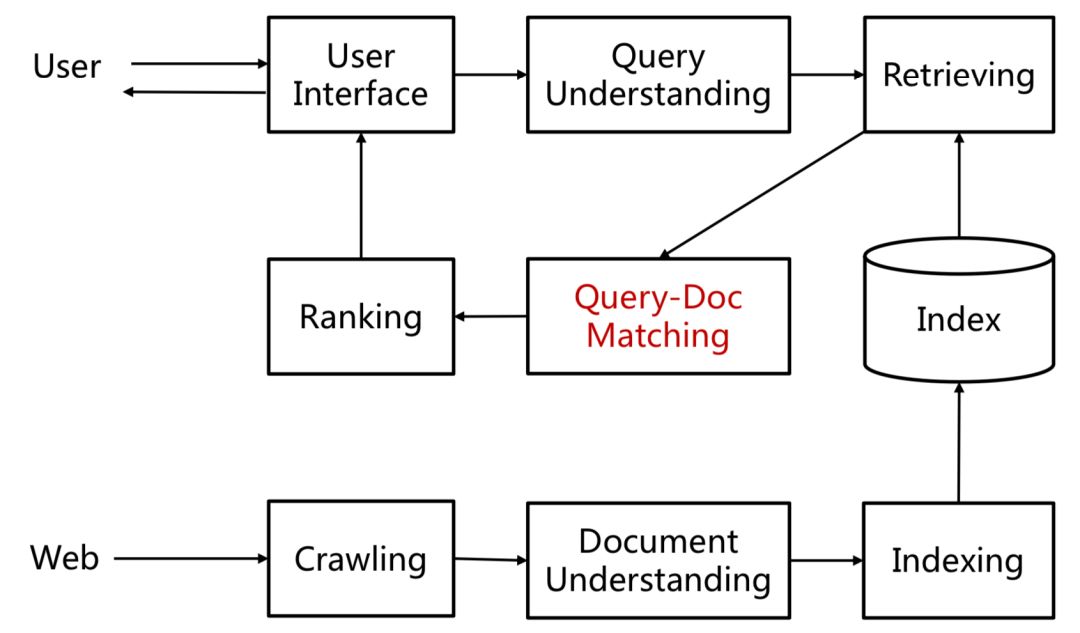
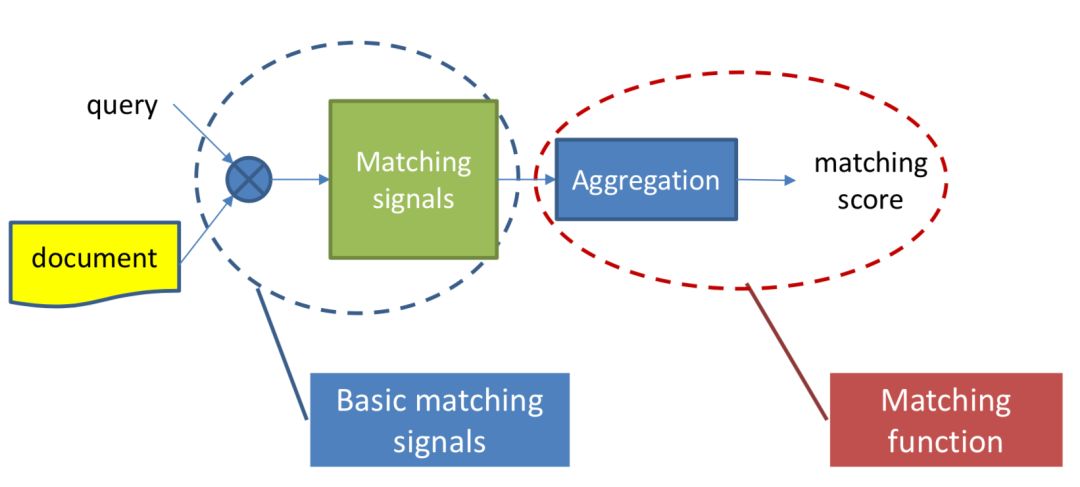
对于搜索来说,搜索引擎的本质是对于用户给定query,搜索引擎通过query-doc的match匹配,返回用户最可能点击的文档的过程。从某种意义上来说,query代表的是一类用户,就是对于给定的query,搜索引擎要解决的就是query和doc的match,如图1.1所示。
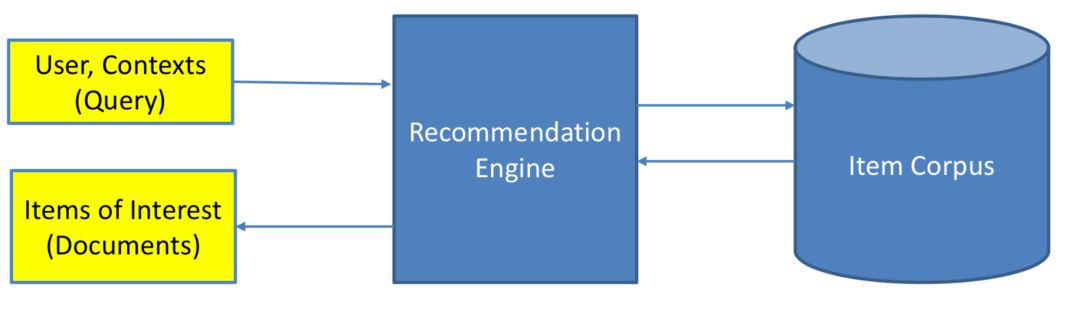
对于推荐来说,推荐系统就是系统根据用户的属性 ( 如性别、年龄、学历等 ),用户在系统里过去的行为 ( 例如浏览、点击、搜索、收藏等 ),以及当前上下文环境 ( 如网络、手机设备等 ),从而给用户推荐用户可能感兴趣的物品 ( 如电商的商品、feeds推荐的新闻、应用商店推荐的app等 ),从这个过程来看,推荐系统要解决的就是user和item的match,如图1.2所示。
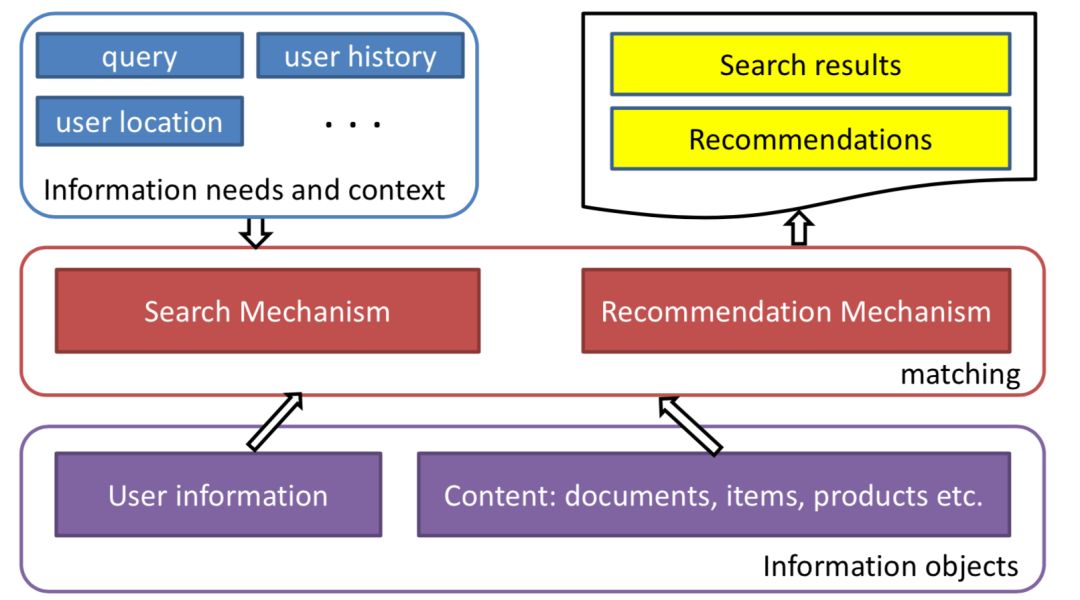
关于搜索和推荐更多的细节在"
推荐系统中的深度匹配模型
"一文中已经给出了详细的对比,本文不再赘述。在目前工业界的大多数主流系统里,推荐系统和搜索引擎一般分为召回和排序两个过程,这个两阶段过程称呼较多,召回也会叫粗排、触发、matching;排序过程也会叫精排、打分、ranking。
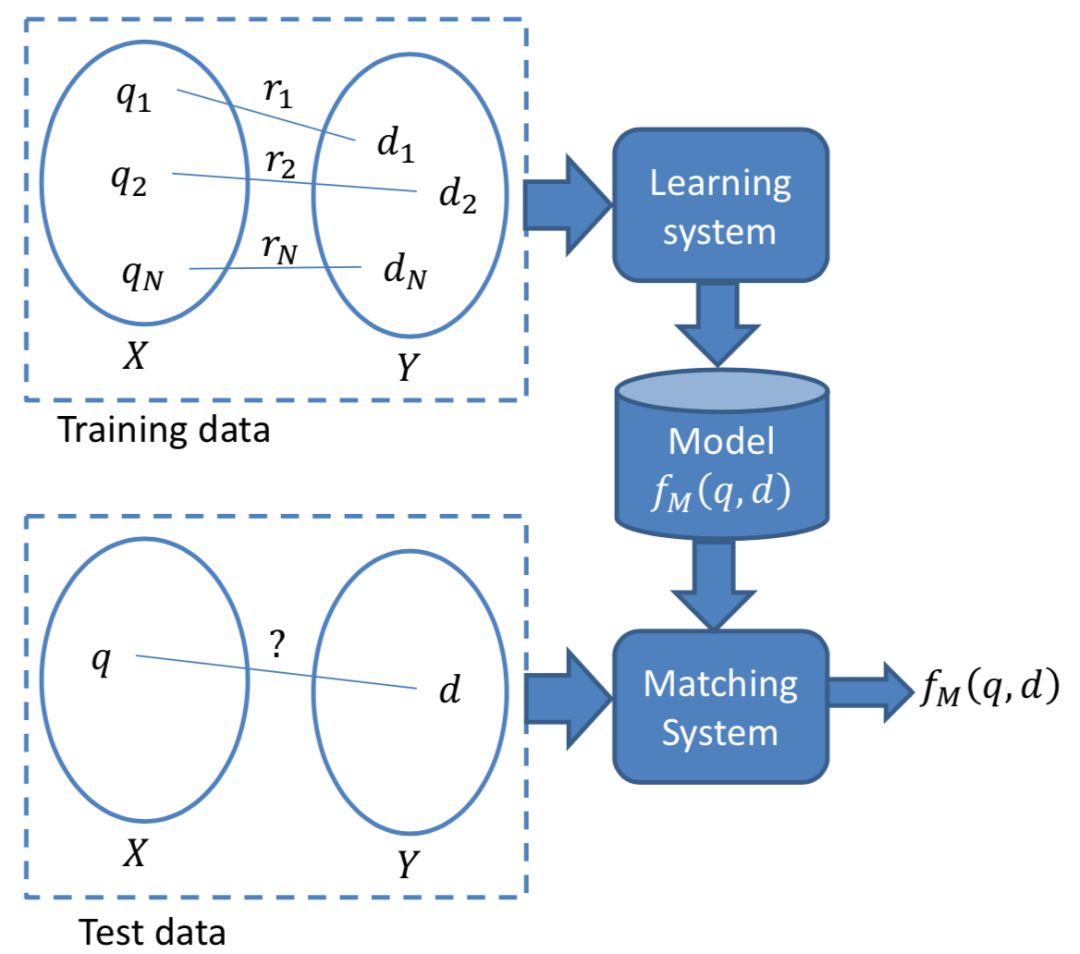
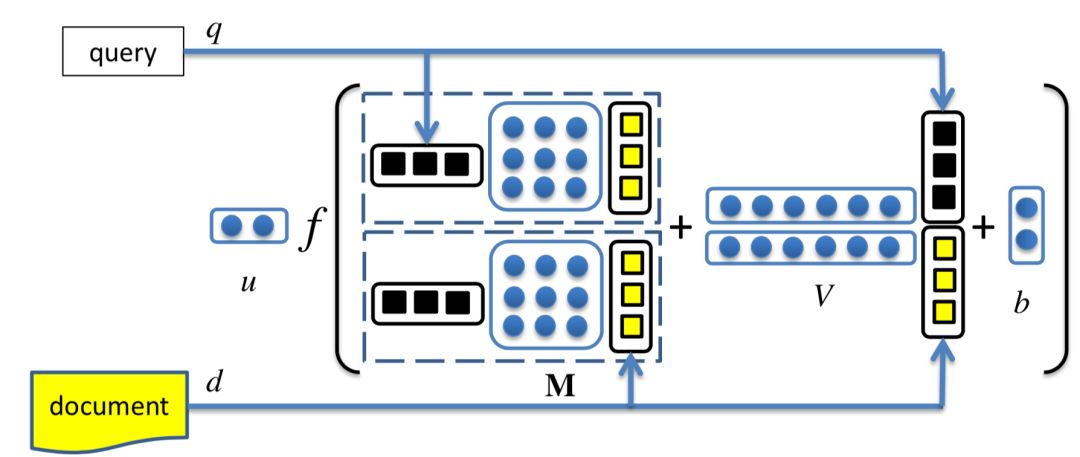
而在本文要讲到的匹配,并不仅仅指的是第一阶段这个matching的过程,而是泛指整个query和doc的匹配。图1.4可以表示本文要讲的query和doc的匹配表示,通过给定的training data,通过learning system,学习得到query和doc的匹配模型f
M
(q, d)。然后对于test data,也就是给定的需要预测的q和d,便可以通过这个模型,预测得到q和d的匹配分数f
M
(q, d)。
图1.4 query-doc匹配过程的机器学习本质
由于query和doc本身都是文本表示,所以本质上来说,这篇文章要讲的东西也是文本的深度匹配模型。大部分自然语言处理的任务基本都可以抽象成文本匹配的任务。
① 信息检索 ( Ad-hoc Information Retrieval ):也就是本文要介绍的主体,在搜索引擎里,用户搜索的query以及网页doc是一个文本匹配的过程
② 自动问答 (
Community Questi
on Answer ):对于给定的问题question,从候选的问题库或者答案库中进行匹配的过程
③ 释义识别 ( Paraphrase Identification ):判断两段文本string1和string2说的到底是不是一个事儿
④ 自然语言推断 ( Natural Language Inference ):给定前提文本 ( premise ),根据该premise去推断假说文本 ( hypothesis ) 与premise的关系,一般分为蕴含关系和矛盾关系,蕴含关系表示从premise中可以推断出hypothesis;矛盾关系即hypothesis与premise矛盾。
02
▬
搜索中的传统匹配模型
图2.1表示的是query-doc的匹配在整个搜索引擎流程中的流程。在讲整个搜索的深度匹配模型之前,我们依然先来看下传统的匹配模型。
图2.1 query-doc的匹配在搜索引擎中的作用
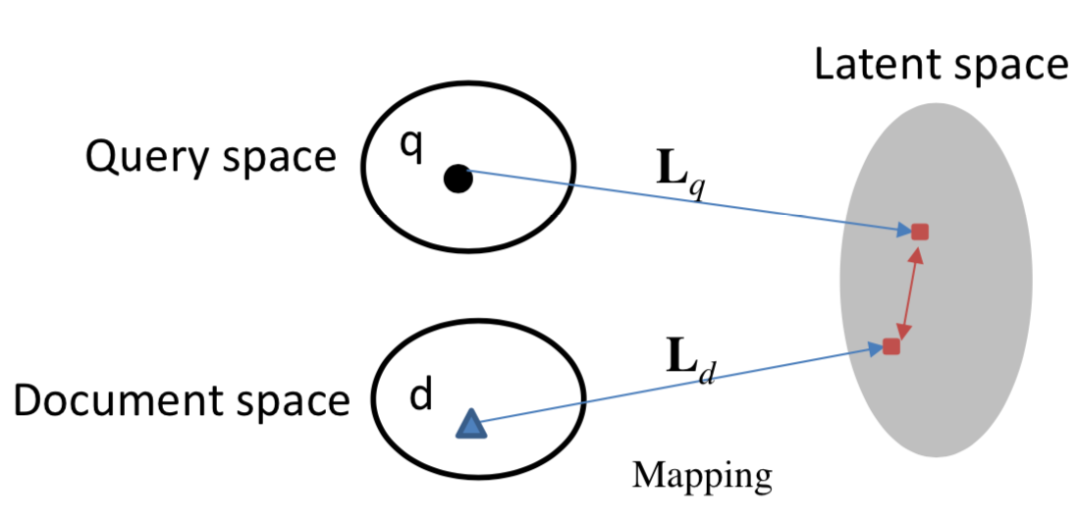
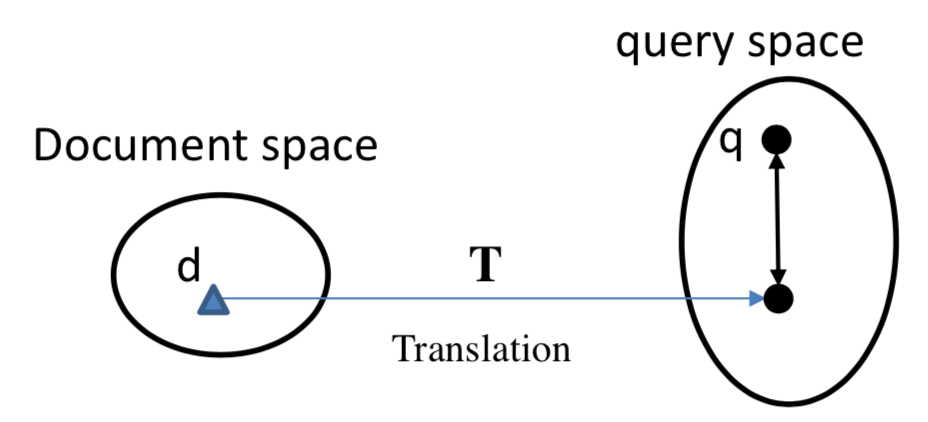
更早之前有基于term的统计方法,例如TF-IDF等,而从match的角度,按照query和doc是否映射到同一个空间,可以分为两大类,一类是基于隐空间的match,将query和doc都映射到同一个latent space,如图2.2所示;第二种是基于翻译空间的match,将doc映射到query的空间,然后学习两者的匹配,如图2.3所示:
图2.2 搜索中基于latent space的匹配
图2.3 搜索中基于translation的match
2.1 基于latent space的传统匹配方法
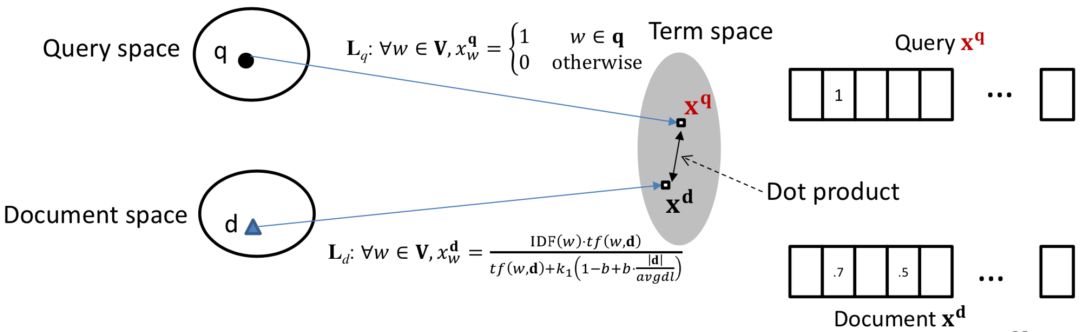
对于第一种方法,基于隐空间的匹配,重点是将query和doc都同时映射到同一空间,经典的模型有BM25。BM25方法核心思想是,对于query中每个term,计算与当前文档doc的相关性得分,然后对query中所有term和doc的相关得分进行加权求和,可以得到最终的BM25,整体框架如图2.4所示
对于query的表示采用的是布尔模型表达,也就是term出现为1,否则为0;
图2.5的BM25公式为query中所有term的加权求和表达,可以分为两部分,第一部分是每个term q
i
的权重,用IDF表示,也就是一个term在所有doc中出现次数越多,说明该q
i
对文档的区分度越低,权重越低。
公式中第二部分计算的是当前term q
i
与doc d的相关得分,分子表示的是q
i
在doc中出现的频率;分母中dl为文档长度,avgdl表示所有文档的平均长度,|d|为当前文档长度,k
1
和b为超参数。直观理解,如果当前文档长度|d|比平均文档长度avgdl大,包含当前query中的term q
i
概率也越高,对结果的贡献也应该越小。
PLS方法全称是Partial Least Square,用偏最小二乘的方法,将query和doc通过两个正交映射矩阵L
X
和L
Y
映射到同一个空间后得到向量点积,然后通过最大化正样本和负样本的点积之差,使得映射后的latent space两者的距离尽可能靠近。
用两个线性映射矩阵L
X
和L
Y
分别将query和doc的原始空间x和y映射后的点积作为匹配分数,并且要求两个转化矩阵都必须是正交的。
上述用映射后的空间的向量点积作为匹配分数,在求最优化时,目标就是最大化正样本query-doc的pair对,以及负样本query-doc的pair对的向量点击差异,并且满足两个转化矩阵L
X
和L
Y
都是正交的约束条件,如下公式所示:
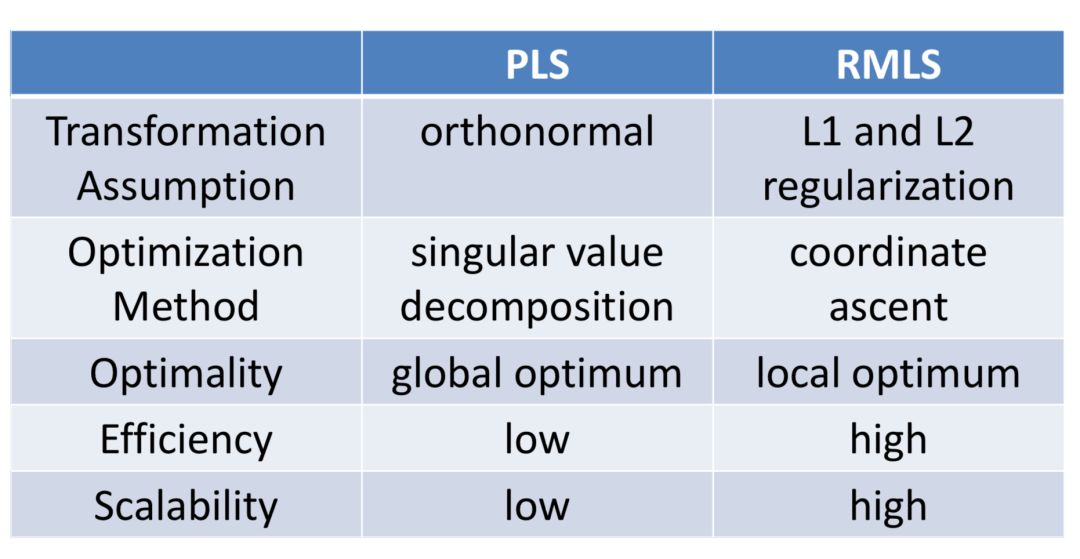
Regularized Mapping to Latent Space和PLS在空间表示、训练数据以及优化目标表示上都一致,区别在于转化矩阵L
X
和L
Y
上,PLS模型的基本假设要求两个矩阵是正定的;而RMLS模型在此基础上加入了正则限制,整体优化目标下公式所示:
query和doc的匹配过程,就是将原本属于不同空间的两段文本映射到一个空间后进行匹配。基于translation的方法把这个过程类比于机器翻译过程:query看成是目标语言E,把doc看成是源语言C,目的是为了得到源语言到目标语言的概率P(E|C)最大化,也就是P(query|doc)最大化。
Baseline方法的基于统计机器翻译的方法,给定源语言C(document),以及目标语言E(query),从源语言到目标语言的翻译过程,就是将doc映射到query的过程。
其中,h(C,E)是关于C和E的特征函数。整个求解过程看成是特征函数的线性组合。
Word-base Translation Model,简称WTM模型,把doc和query的关系看成是概率模型,也就是给定doc,最大化当前的query的概率。Doc生成query的过程可以看成两部分组成,第一项p(q|w)是概率模型,也就是doc中的单词w,翻译到当前query的单词q的概率,称为translation probability;p(w|
d
)注意doc是加粗表示整个文档,也就是doc生成每个单词w的概率,称为document language model。
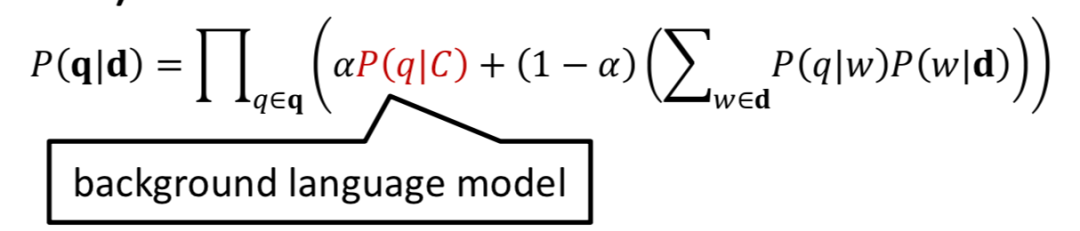
上述公式将doc->query的翻译过程拆成了两个模型的连乘,对于很多稀疏的term,一旦出现某个概率为0,最终结果也将变为0。为了防止这种情况就需要做平滑,下述公式通过引入background language model的p(q|C),并且用参数alpha进行线性组合来做平滑。C代表的是整个collection。
图2.8 加入了background language model平滑的WTM模型
从贝叶斯公式,可以得到p(q|C)以及p(w|D)的表达;C(q;C)表示的是当前query的单词q在整个collection出现的次数;C(w;D)表示的是单词w在文档D中出现的次数
但是这种方法也存在问题,就是self-translation问题。原本这个问题是在机器翻译过程中,但是在query和doc过程中,源语言和目标语言都是同一种语言,也就是doc中的每个term都有可能映射到query中相同的term,即p(q=w|w)>0。因此,CIKM2010年引入了unsmoothed document language model,也就是p(q|
d
)来解决这种问题
图2.9 加入unsmoothed document 的WTM表示
03
▬
基于representation learning的深度匹配模型
在搜索的深度模型匹配中,我们发现这一步和推荐系统的深度匹配模型一样,也可以分为两类模型,分别是基于representation learning的模型以及match function learning的模型。
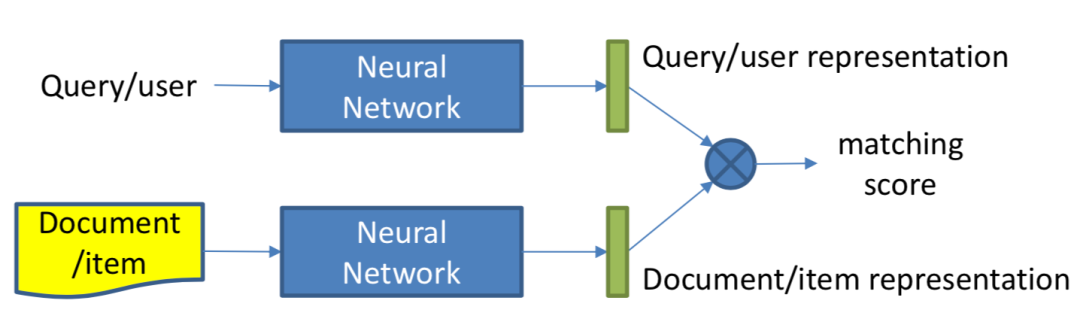
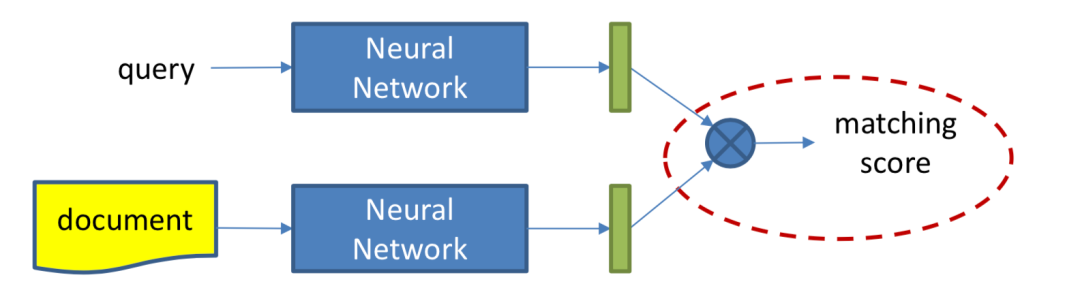
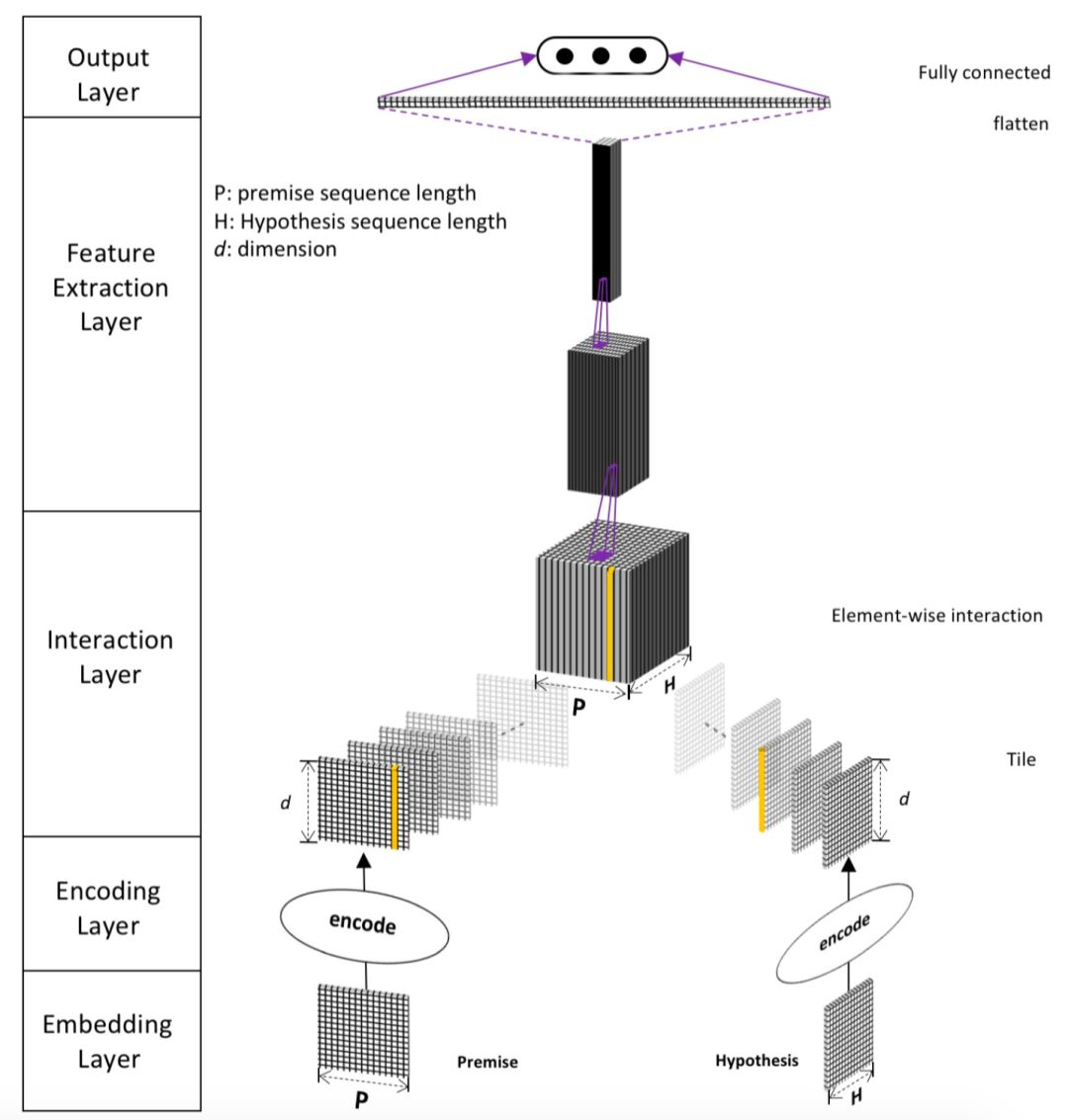
本章主要讲述第一种方法,representation learning,也就是基于表示学习的方法,这种方法会分别学习query和doc ( 放在推荐里就是user和item ) 的representation表示,然后通过定义matching score函数,例如简单点的做法有向量点积、cosine距离等来得到query和doc两者的匹配,整个representation learning的框架如图3.1所示,是个经典的双塔结构:
图3.1 搜索中基于representation learning的深度匹配模型
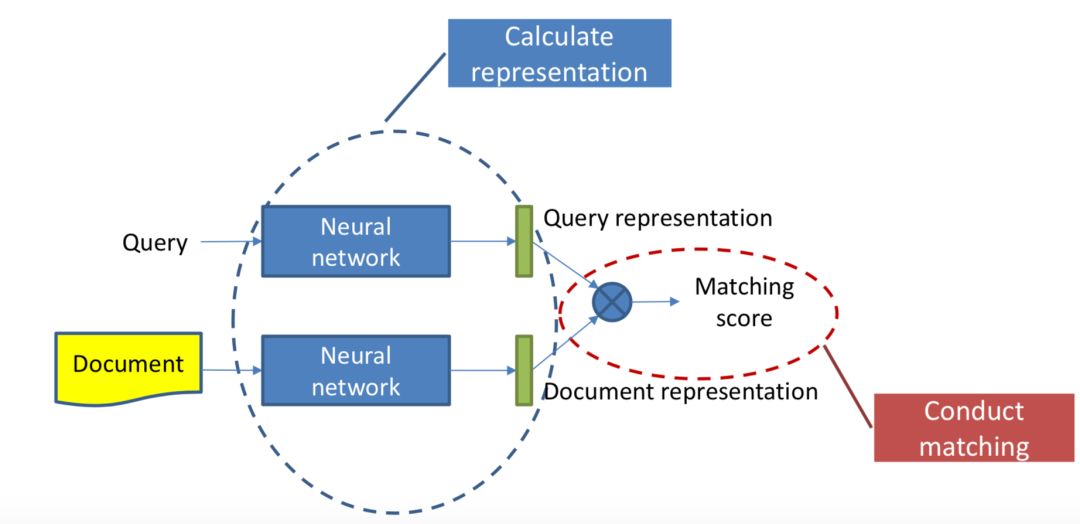
① 表示层:计算query和doc各自的representation,如图3.2中蓝色圈所示。
② 匹配层:根据上一步得到的representation,计算query-doc的匹配分数,如图3.2中红色圈所示。
图3.2 基于representation learning的模型流程
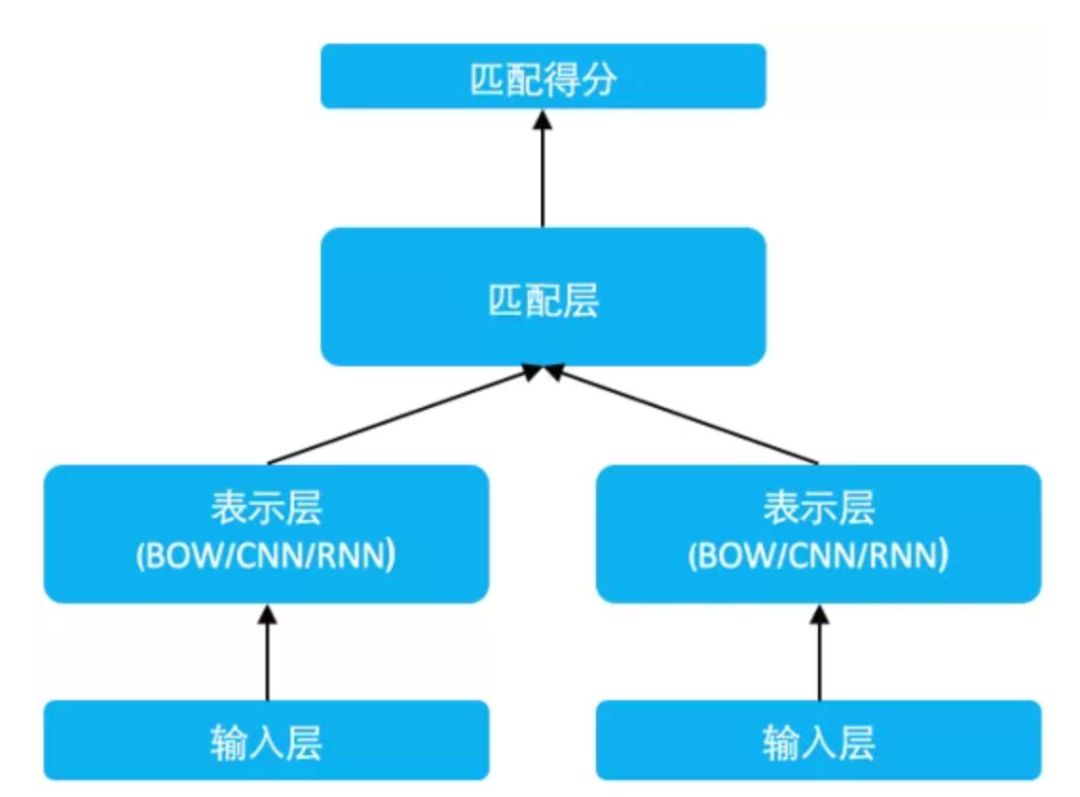
因此,基于representation learning的深度匹配模型,无外乎围绕着表示层和匹配层进行模型结构的改造,其中大部分工作都集中在表示层部分。表示层的目的是为了得到query和doc的向量,在这里可以套用常用的一些网络框架,如DNN、CNN或者RNN等,本章也将沿着这3种框架进行表述。
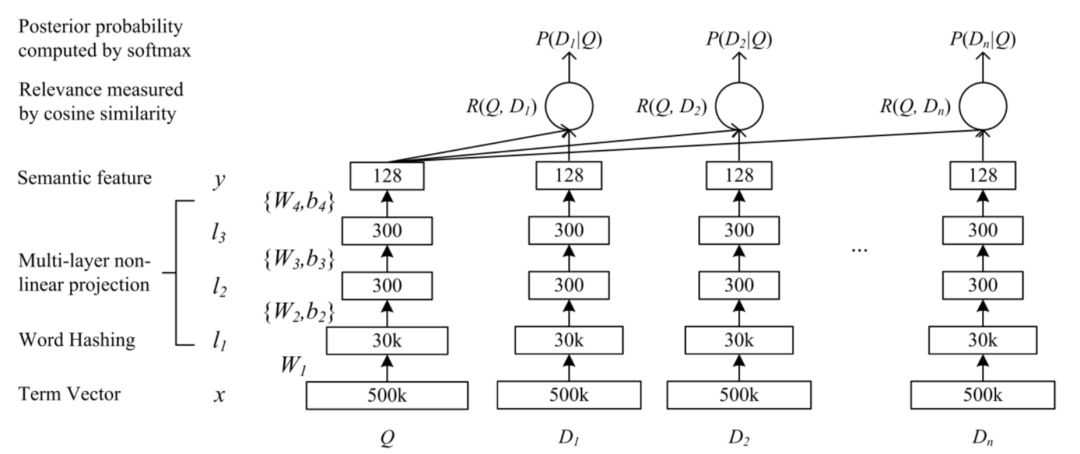
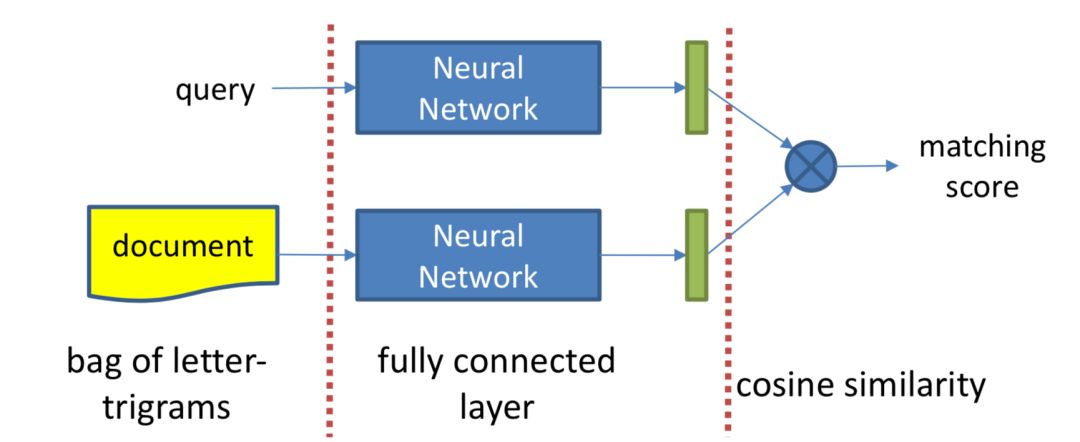
DSSM模型全称是deep struct semantic model,是微软在2013年提出来的深度匹配模型,后续一举成为表示学习的框架鼻祖。同年百度NLP团队也提出了神经网络语义匹配模型simnet,本质上两者在模型框架上是一致的,如图3.3所示,都是典型的双塔模型,通过搜索引擎里query和doc的海量用户曝光点击日志,用DNN把query和doc通过表示层,表示为低维的embedding向量,然后通过匹配层来计算query和doc的embedding向量距离,最终得到匹配分数。
图3.3 百度simnet框架,经典的双塔representation learning
DSSM作为框架型的模型得到大范围应用,除了其简洁经典的三段式结构:输入层-表示层-匹配层来得到最终的匹配得分,还有个很重要的原因:通过表示层得到的query和doc的向量是个非常重要的产物,可以在后续很多任务如召回层等地方继续使用。
输入层做的事情是把原始的句子 ( query或者doc ) 映射到一个向量空间并进入表示层。这里由于中文和英文本身的构造不同,在处理方式上也有所不同。
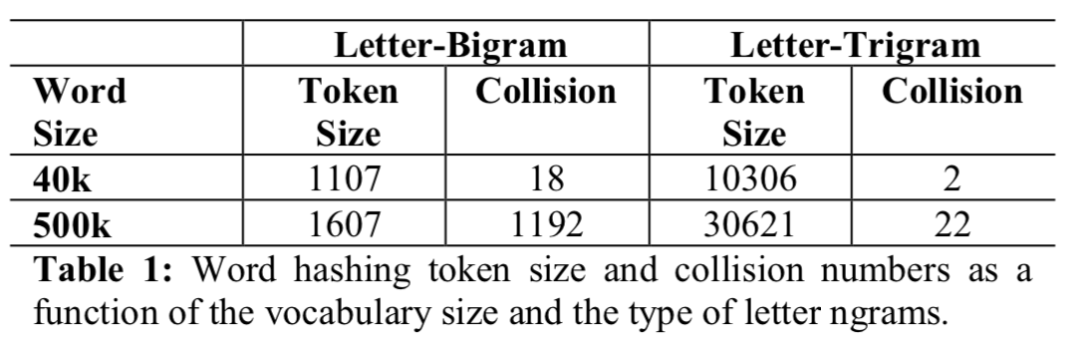
DSSM论文里对英文的处理方式是word hashing,对于每个单词前后都用#表示作为开始符和结束符。例如对于单词boy,采用n-gram方式表达,以trigram为例 ( n=3 ),将表示为#bo, boy, boy# 这三个trigram。由于这种切分方法是在letter字符级别的,因此称为letter-trigram,目的是为了区分后面会提到的其他trigram方法。
这种方法可能存在的一个问题就是单词冲突问题。举个例子,god和dog采用原始的one-hot是两个不同单词,但是用trigram的话这两个词的输入将是一个向量,因此产生了冲突。
通过word hash的方式有两个好处,第一是可以大大减少原始输入空间。以4万单词为例,采用trigram的hash方法以后,将压缩到1万左右的输入空间。而对于一个50万单词的词表的话,将压缩到3万,与此同时trigram的冲突率只有22/50w=0.0044%。
图3.5 bigram和trigram的冲突率区别
对于中文而言,没有英文输入这种char级别的语法构造,因此不适用word hash的方法。在NLP领域对中文的原始输入都会采用各种分词工具进行分词的预处理,而对于正常规模的汉字,单字规模1.5万左右,双字规模在百万左右,因此对于中文的输入,采用的是单字的输入
在DSSM中表示层采用的是词袋模型 ( bag of words ),也就是说不区分word的输入顺序,整个句子的所有单词都是无序输入的。这也为后面各种DSSM-based模型提供了很多优化工作。
在embedding层之后,对每个sentence使用的是MLP网络,经典的隐层参数是300->300>128,也就是说最后,每个句子都将表示成一个128维度的向量。
其中W
1
表示第一层的embedding矩阵,W
2
,W
3
,…W
N-1
表示MLP的隐层;最后一层的输出层采用tanh,输出一个128维的向量。
在原始的DSSM模型使用的是cosine作为两个向量的匹配分数:
DSSM模型能够work的原因是利用了用户的后验点击数据,给定一个query,在展示出来的doc里面,用户点击了的doc则认为这个doc和query是相关的,因此将query和doc的关系用softmax来表示其后验概率:
其中,γ是一个平滑因子,是个超参数。而D表示的是所有候选的doc,这里对于给定的query,所有被点击过的doc认为是正样本,而对于负样本,则从所有未点击的doc里随机采样4个,文章提出来使用不同的采样方法对结果影响并不大。模型的损失函数表达如下所示,注意到这里仅仅使用的是正样本的后验概率,和负样本无关。
图 3.6 DSSM中query和doc的匹配框架
-
框架鼻祖:提出了一个输入层->query和doc各自的表示层->匹配层的模型范式,和百度的simnet一样,更像匹配模型的框架范式,这里的每一层都可以针对性的做优化
-
word hash:输入层对于英文提出了word hash的方法,大大减少了原始one-hot输入空间
-
端到端学习:模型是个完全end-2-end的框架,包query和doc的embedding向量直接通过训练得到不需要经过预训练
-
表示层:使用原始的DNN全连接网络来得到query和doc的向量表示
-
匹配层:使用cosine表示query和doc的匹配分数
-
缺点:对query和doc的表示都是bow,丢失了序列信息和上下文信息
以DSSM为代表的基于DNN的表示学习匹配模型如3.2分析,无论是bow的表示还是DNN全连接网络结构的特点,都无法捕捉到原始词序和上下文的信息。因此,这里可以联想到图像里具有很强的local relation的CNN网络结构,典型代表有ARC-I模型,CNN-DSSM模型,以及CNTK模型。
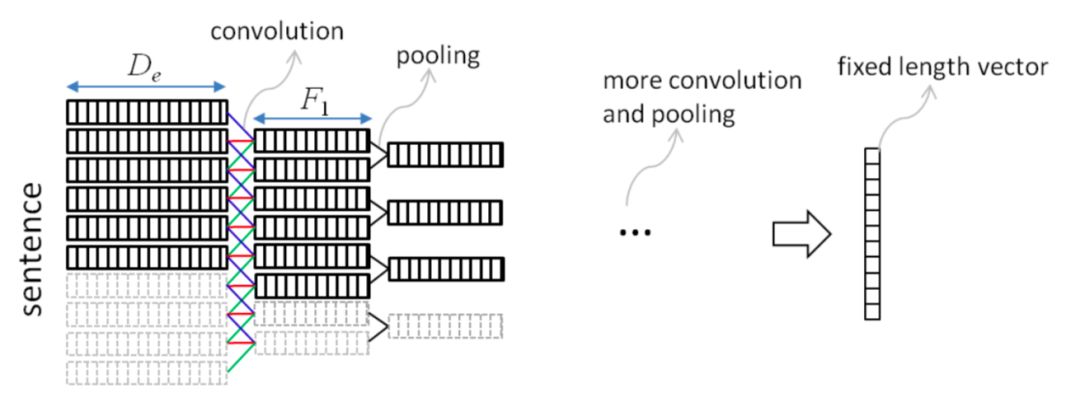
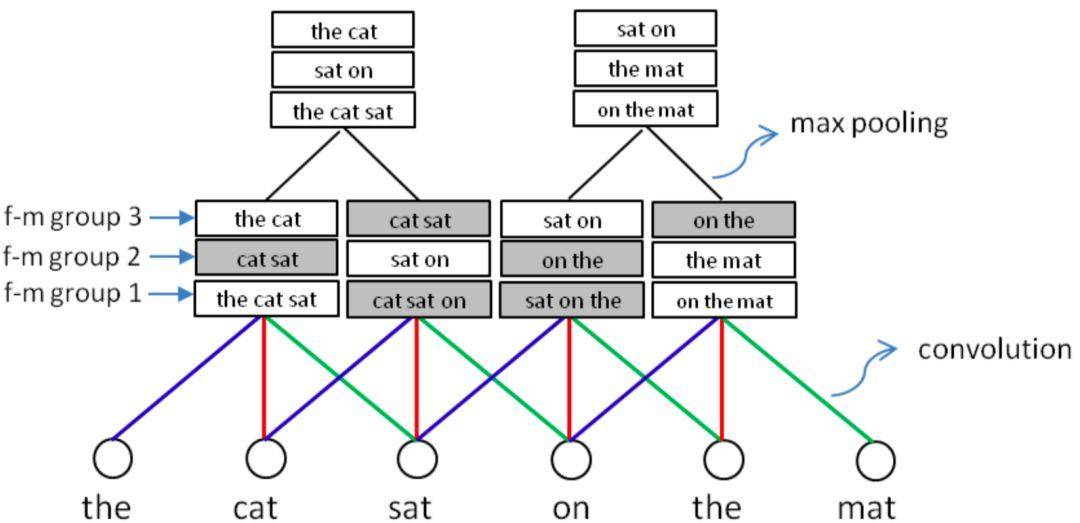
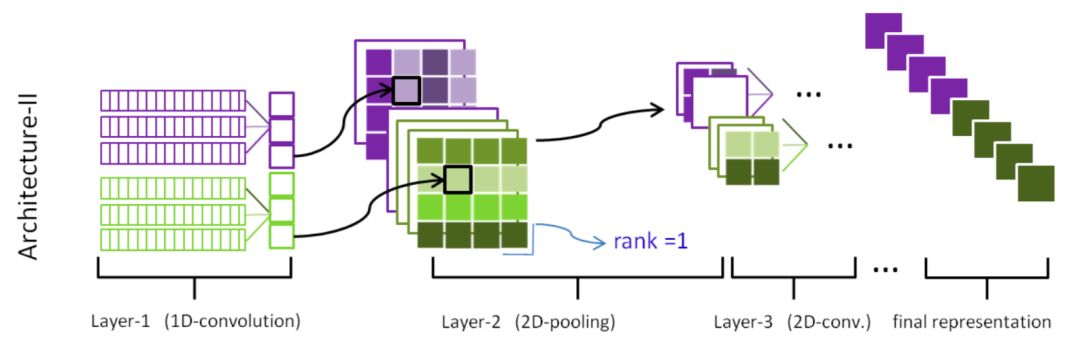
针对上述讲到的DSSM模型对query和doc序列和上下文信息捕捉能力的不足,华为诺亚方舟在2015年在DSSM的模型基础上加入了CNN模块,里面提到了两种模型ARC-I和ARC-II,前者是基于representation learning的模型,后者是基于match function learning的模型将在第三章讲到。两个模型对比原始的DSSM模型,最大的特点是引入了卷积和池化层来捕捉句子中的词序信息,ARC-I全称Architecture-I,框架如图3.7所示。
ARC-I模型引入了类似CNN模块的卷积层和池化层,整体框架如图3.8所示:
其中z
i(l,f)
表示的是第l层中第f个filter位置为i的word的卷积输出,word滑动窗口大小为k
1
( 图中k1=3 ),word embedding的大小为D
e
。这里不同的filter可以得到不同的feature map,通过w
(l,f)
和b
(l,f)
进行加权,表示的是第l层第f个filter的待学习参数。
其中z
i(l-1)
表示第l-1层第i个元素的向量,维度大小为F
l-1
。对于第一层卷积层,将连续的k
1
个word向量直接concat起来,如下所示,维度为k
1
*D
e
。
卷积层提取了相邻word的关系,不同的feature map提供了不同的word的组合,通过池化层进行选择。ARC-I选择的滑动窗口为2,用max-pooling提取相邻两个滑动窗口的最大值,用公式表示如下:
图 3.9 word-window表示,灰色表示置信度低
-
对于query和doc两段文本的匹配,相比DSSM引入了word-ngram网络
-
通过卷积层不同的feature map来得到相邻term之间的多种组合关系
-
通过池化层max pooling来提取这些组合关系中最重要的部分,进而得到query和doc各自的表示。
-
表示层:通过上述卷积层和池化层来强化相邻word的关系,因此得到的query和doc的表示比原始DSSM能捕捉到词序信息
-
缺点:卷积层虽然提取到了word-ngram的信息,但是池化层依然是在局部窗口进行pooling,因此一定程度上无法得到全局的信息
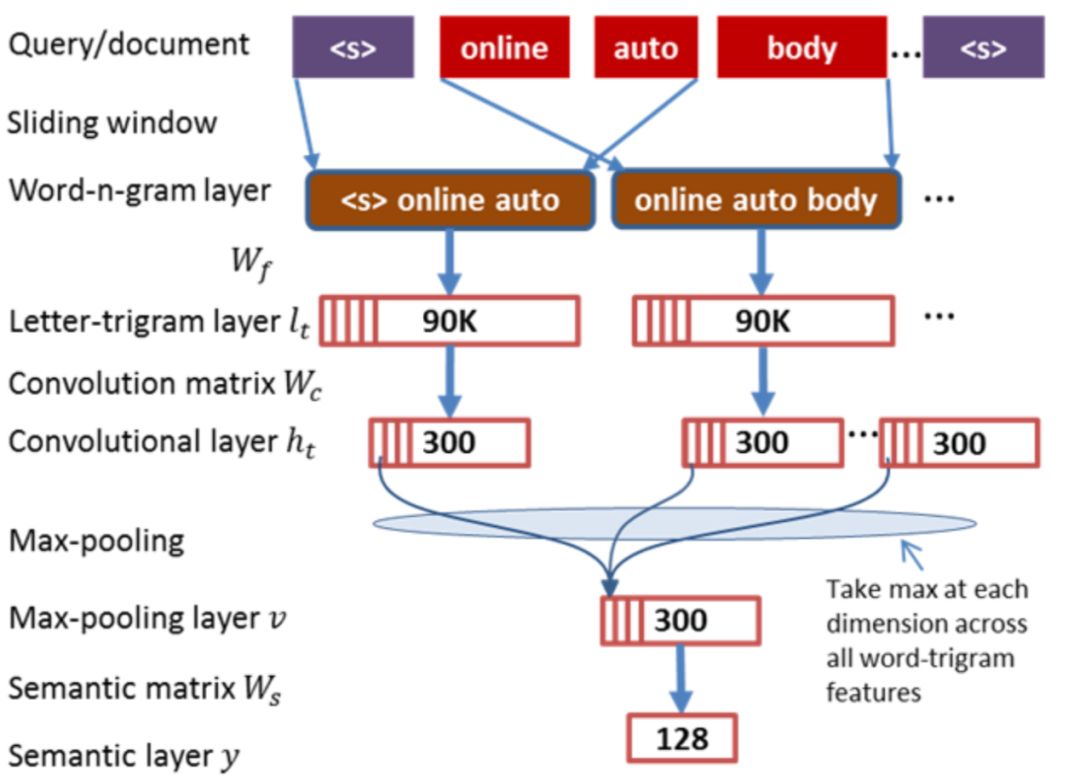
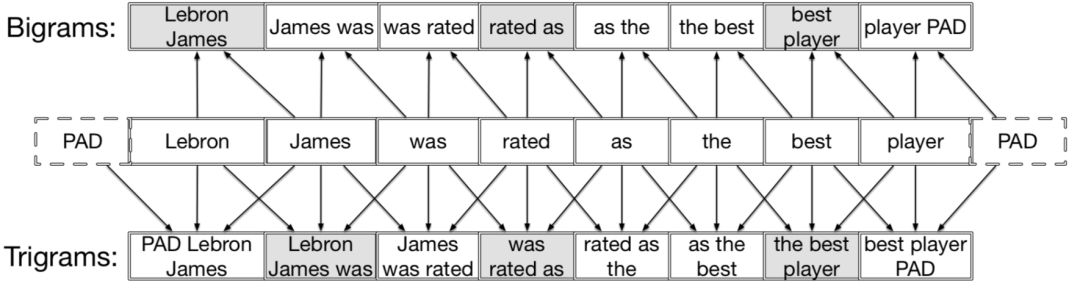
CNN-DSSM模型也称CLSM,是CIKM2014微软提出的基于CNN的DSSM模型,在DSSM框架上引入了CNN,整体来看可以分为输入层、表示层和匹配层,模型框架如图3.10所示
对比DSSM模型,在输入层除了做了word hash的letter-trigram,同时也捕捉了word级别的信息,称为word-trigram。Word-trigram同样采用的是n=3的上下文单词的滑动窗口,每个窗口包含3个单词。例如<s> online auto boy … <s>这句话,可以提取得到三组信息,第一组是<s> online auto,第二组是online auto boy,第三组是auto boy <s>。
通过word-trigram提取得到的3组句子都各有3个单词,对每个单词按照DSSM中的letter-trigram方法进行word hash后,映射到一个3万维的embedding里,因此每个句子都可以得到9万维的embedding向量。
上述公式f
t
表示第t个单词的word-n-gram表示, n=2d+1则为滑动窗口大小,d则表示用该单词前后单词个数,例如d=1,n=3表示word-trigram,使用当前word前后各1个单词以及自身进行表示。
对于中文,和DSSM模型一样,采用的是字级别的编码
通过输入层得到的每个句子是一个m*90k维的矩阵,其中m代表的是query或者doc的长度,为矩阵的行,而90k理解成每个word的embedding size,为矩阵的列。对于query和doc的句子不等长情况,可以通过padding方式进行补齐,确保所有句子都是等长的。论文中使用m=300,就是每个query和都需要pad到300维。
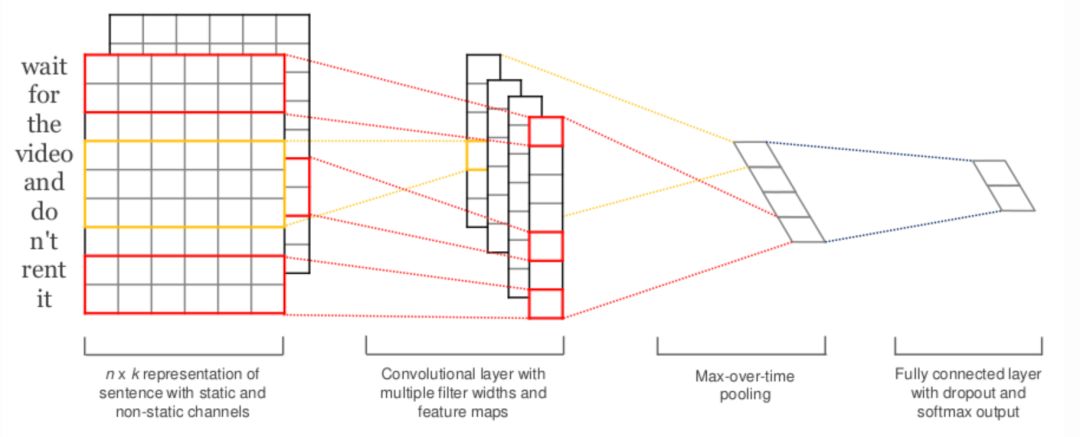
为了说明整个卷积过程,这里借用文本分类的经典模型textCNN模型来展示,如图3.11所示。卷积核W
c
大小为3*90k,3表示的是卷积高度,代表每次滑动进行卷积的词窗口大小为3,90k是为了和原始句子的embedding size保持一致,整个卷积过程从上到下进行卷积,最终每个卷积核得到一个m*1的特征向量 ( feature map )。
论文使用了300个卷积核,因此可以得到300*m的一个矩阵 ( 前300为filter个数,后300表示的是每个feature map的行数 )
前面卷积层每个filter得到的feature map维度是300,采用max pooling的方式选择最大的一个,总共有300个filter,因此max pooling可以得到一个300*1的定长特征向量:
通过一层MLP网络后,用tanh进行激活输出,从300维的向量映射到一个128维的特征向量
在原始的DSSM模型使用的是cosine作为两个向量的匹配分数:
训练和损失函数和原始DSSM论文一致,这里不再赘述。
总结下CNN-DSSM模型,对比原始DSSM模型主要区别如下:
-
输入层除了letter-trigram,增加了word-trigram,提取了词序局部信息
-
表示层的卷积层采用textCNN的方法,通过n=3的卷积滑动窗口捕获query和doc的上下文信息
-
表示层中的池化层通过max-pooling,得到卷积层提取的每个feature map的最大值,从而一定程度的捕获了全局上下文信息
-
表示层中的池化层的max-pooling对比ARC-I的max pooling不同之处在于ARC-I的池化层是在相邻的两个滑动窗口进行max pooling,得到的还是局部关系;而CNN-DSSM模型是在每个feature map整个句子进行max pooling,能得到全局的关系
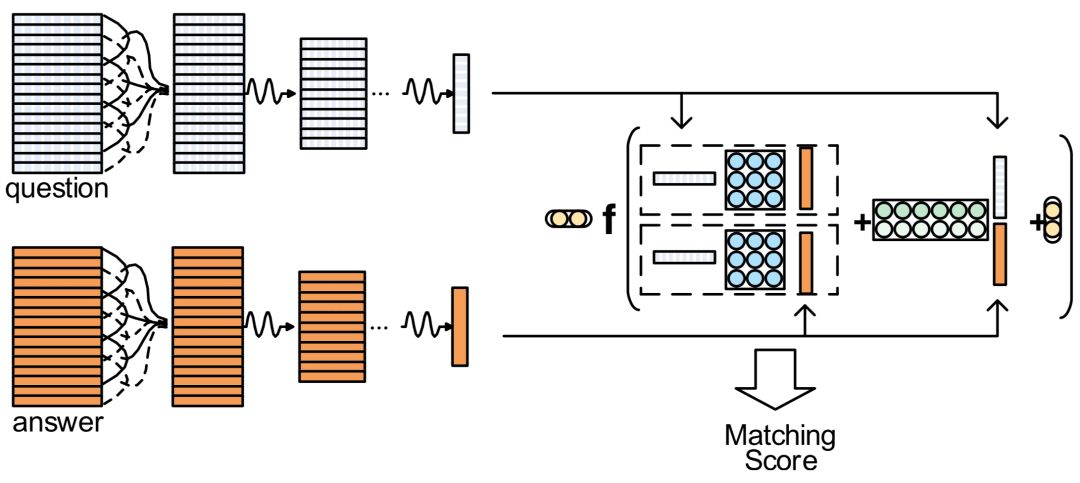
前面提到的两种基于CNN的模型ARC-I模型以及CNN-DSSM模型核心在于表示层上引入了CNN模型结构,对匹配层依然是沿用了DSSM的cosine来计算query和doc的匹配分数。而在IJCAI2015年提出的Convolutional Neural Tensor Network,简称CNTN模型,除了一样在表示层引入CNN学习query和doc的表示,另外也在匹配层做了改造,引入了Neural Tensor Network,整体框架表示如图3.12所示。
对于给定的query和doc,从表示层已经得到各自的表示q和d,在匹配层引入了neural tensor network,也就是更多的网络参数来学习q和d的匹配分数,用公式表示如下:
其中query和doc都各自由3个word组成,query 为图中的黑色部分,doc为黄色方块。M[1:r]中的每个r ( 图中等于2 ),是query和doc之间的一个3*3转换矩阵,因此,qTM[1:r]d产生的是一个r维度的向量,在图中就是2维向量。公式的第二部分,V是一个3*2的矩阵,乘以q和d两个向量concat一起的向量后,也得到一个2维向量,在加上一个维度为2的bias向量b。
通过中间括号的操作得到一个2维的向量后,引入了非线性函数f进行拟合,再通过左侧一个线性矩阵u的映射,最终得到匹配分数
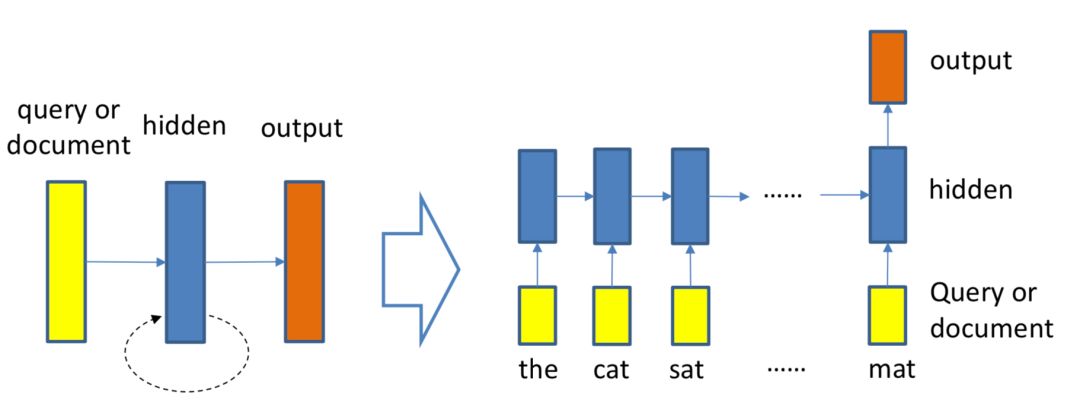
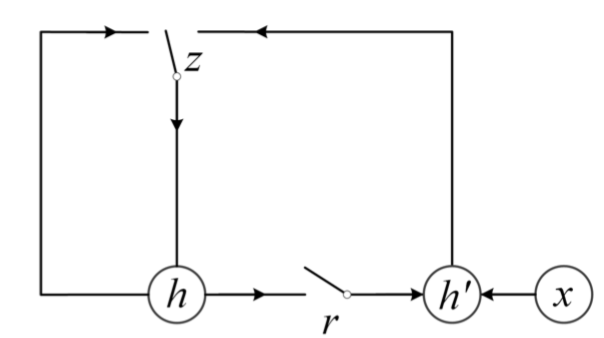
作为空间关系代表的CNN网络结构能够捕捉到query和doc的局部关系,RNN作为时间序列相关的网络结构,则能够捕捉到query和doc中前后词的依赖关系。因此,基于RNN的表示学习框架如图所示,query或者doc用黄色部分表示,通过RNN网络结构作为隐层来建模序列关系,最后一个word作为输出,从而学习得到query和doc的表示。对于RNN结构,可以使用业内经典的LSTM或者GRU网络结构,如图3.14所示。
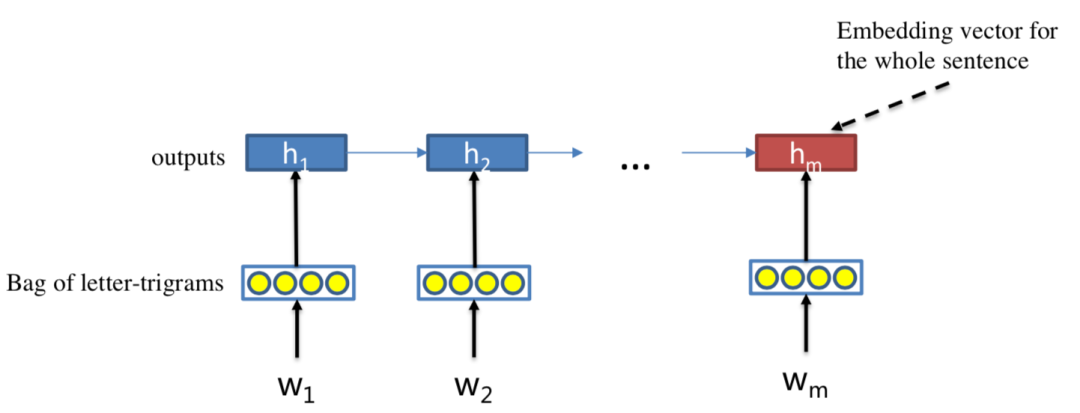
2016在TASLP上提出的LSTM-RNN模型,在DSSM的基础上提出了用LSTM来强化query和doc的representation。整个模型思想很简单,通过将原始query和doc的文本转换成embedding向量,然后通过LSTM-RNN的网络结构进行抽取转换。假设原始的query或者doc有m个word,得到的最后一个隐层的输出hm就是整个query或者doc的最终表达,框架如图3.15所示。
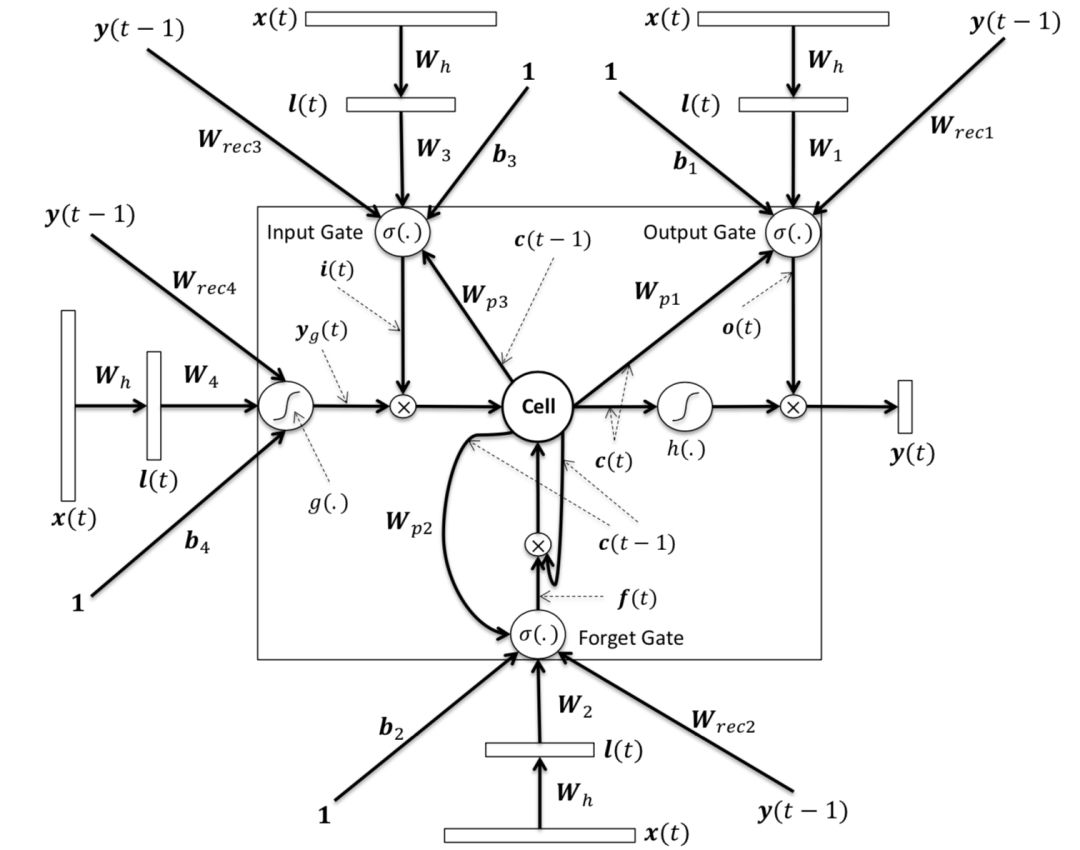
文中核心的改造在于表示层中使用了LSTM来捕捉序列关系,在LSTM的多种变体结构中,作者使用了peephole connection的变体,也就是说让门结构 ( 输入门、输出门、遗忘门 ) 也会接受前一时刻的细胞状态作为输入,具体表示如图3.16所示。
图3.16 peephole connection LSTM网络结构
-
相比于DSSM模型引入了LSTM网络结构来捕捉次序的关系
-
LSTM最后一个隐层的输出作为query和doc的representation
3.4 representation learning模型总结
总下基于representation learning的深度匹配模型框架,核心在于表示层和匹配层。
图3.17 表示层和匹配层是representation learnning框架的两大模块
② CNN框架:ARC-I模型、CNN-DSSM模型、CNTN模型
匹配函数有两大类,一种是直观无需学习的计算,如cosine、dot product,一种是引入了参数学习的网络结构,如MLP网络结构,或者CNTN模型。
① cosine函数:DSSM模型、CNN-DSSM模型、LSTM-RNN模型
④ Neural Tensor Network:CNTN模型
04
▬
基于match function learning的深度匹配模型
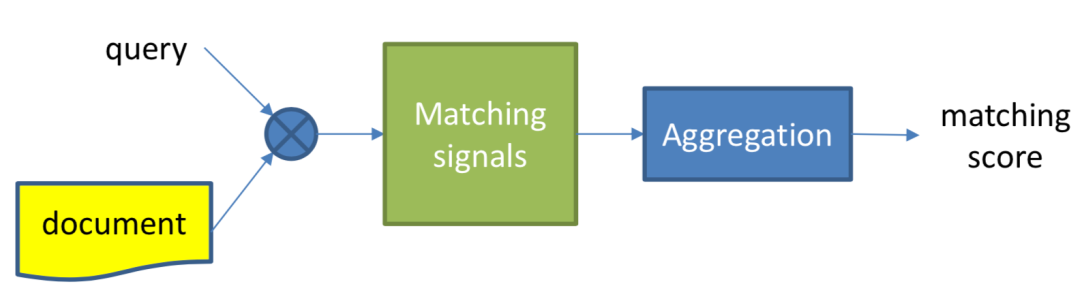
对比representation learning的深度匹配模型,match function learning方法的特点,是不直接学习query和doc的表示,而是一开始就让query和doc进行各种交互,通过两者交互的match signals进行特征提取,然后通过aggregation对提取到的match signals用各种网络结构进行学习得到最终的匹配分数,如图4.1所示。
图4.1 基于match function learning的深度匹配模型
和representation learning匹配模型一样,match function learning的匹配过程也一样可以分为两步:
① 基础匹配信号提取:让query和doc在这一步就开始进行交互,得到两者的基础匹配信号,如图4.2中的蓝色圆圈所示
② 信号聚合(aggregation):对应于representation learning中的匹配层,这里也叫匹配层,由于前一步已经进行了query和doc的交互,信号更加丰富,在后面介绍的模型中可以发现匹配层这里也会比表示学习的网络结构设计变化要丰富很多
由于从一开始就让query和doc进行交互。因此,基于match function learning的匹配模型也称为交互匹配模型。
基于match function learning的模型和representation learning的模型最大的区别是让query和doc提前进行交互,因此很多模型的工作就是关于如何设计query和doc的交互上。一种很直观的思路就是,让query和doc两段文本里面每个word两两进行交互,在word level级别建立匹配度矩阵。本章在原始slides上的基础上加了aNMM模型,虽然听名字是attention-based的,但其区别于CNN的position-aware提出的value-aware思路个人觉得还是值得研究下的。
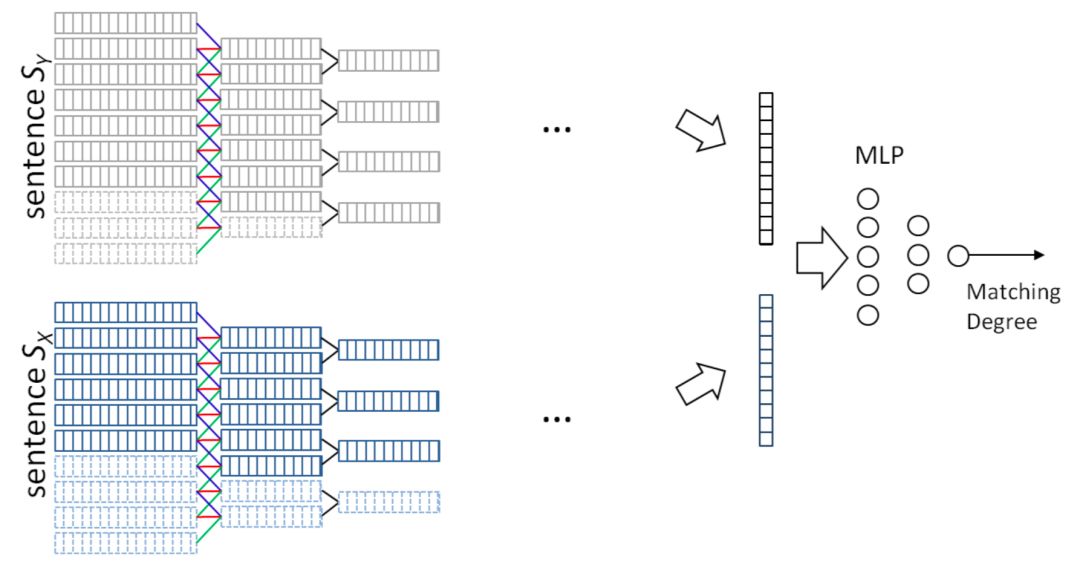
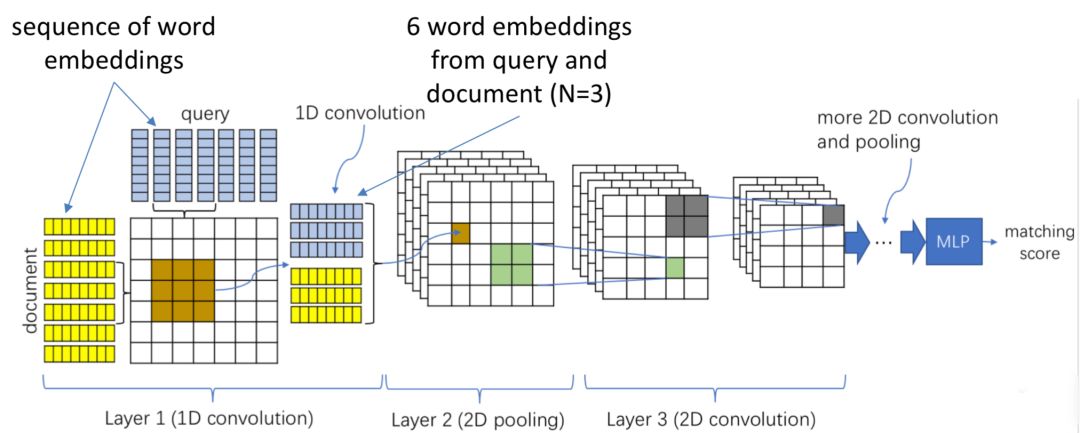
ARC-II全称Architecture-II,和ARC-I出自2015年华为的同一篇paper,属于交互学习的模型。ARC-I直到最后的全连接层进行匹配之前,query和doc两段文本都是没有任何交互的,大家都在各自学习各自的表示。而ARC-II模型属于交互学习的模型,通过对query中的word进行n-gram的卷积提取,以及doc中的word进行卷积提取,然后各自卷积后得到的词向量进行pairwise计算,得到一个匹配度矩阵,整体框架如图4.3所示。
在提取匹配度矩阵过程中,核心有3层:一维卷积层、二维卷积层和二维池化层
假设query和doc的长度都是N,我们把整个过程想象类比层二维图像,让query和doc的每个word两两组成一个N*N的矩阵,query是列,doc是行。其中每个word的embedding维度是D
e
。
用一个3*3的卷积核在这个N*N的矩阵上进行扫描,每次横向扫描3个格子,纵向扫描3个格子,代表在query和doc上对应的3个相邻的词,总共取到6个词进行concat,可以得到一个6*D
e
的矩阵,卷积核大小也为6*D
e
,两者进行点乘相加得到一个值。这样扫描完整个N*N矩阵就可以得到一个二维的矩阵feature map。使用多个卷积核,就可以得到多个二维矩阵feature map。
通过这种trigram的方法 ( 每次取3个词 ) 的交互,可以得到query和doc中任意3个相邻的word组成的短语的交互关系,因此交互级别属于phrase级别的。
对于query句子S
X
中的第i个word,和doc句子S
Y
中的第j个word,卷积后的表示为:
注意到第一层的元素z
i,j
(0)相当于将输入x和y的向量concat了起来,embedding 维度为D
e
,n-gram的滑动窗口为k
1
( 在示意图中为3 )。
整个过程query和doc的信息都是独立计算后concat的,称为一维卷积。
一维卷积层保留了query和doc中每个词的原始信息。在2维的池化层作用是用一个2*2的卷积核,用max-pooling得到这4个二维空间的最大值。
前面通过一维卷积层和max pooling后得到的是2维的匹配矩阵,接着的操作可以类比于图像,在二维的平面上进行多层的卷积-池化-卷积-池化…的操作了。以第三层为例 ( 前面已经有两层:一维卷积-二维池化 ),在一个二维平面做卷积:
2维卷积层之后可以叠加多个卷积和池化的操作,最后再通过全连接MLP输出最终的匹配分数。损失函数使用pairwise loss:
在整个2维卷积和池化过程,可以发现word的顺序关系是有所保留的,如图4.4所示的2维度池化过程,max pooling选择的黄色方块保留了原始的order信息。
另外一个角度,我们可以看到其实ARC-I是ARC-II的特殊情况,如下图4.5所示:
图4.5 ARC-I本质上是ARC-II的特殊情况
-
对比ARC-I,在一开始就引入了query和doc两段文本的匹配矩阵,提前得到两者的交互信息,对信息匹配的捕捉能力更强,并且卷积和池化过程保留了次序的信息
-
虽然引入了query和doc的匹配矩阵,但是匹配矩阵的计算是按照每个句子的n-gram后的word embedding计算,只有phrase level的匹配信号而没有更细粒度的word level的匹配信号,因而丢失了原始精确匹配和泛化匹配的信息。
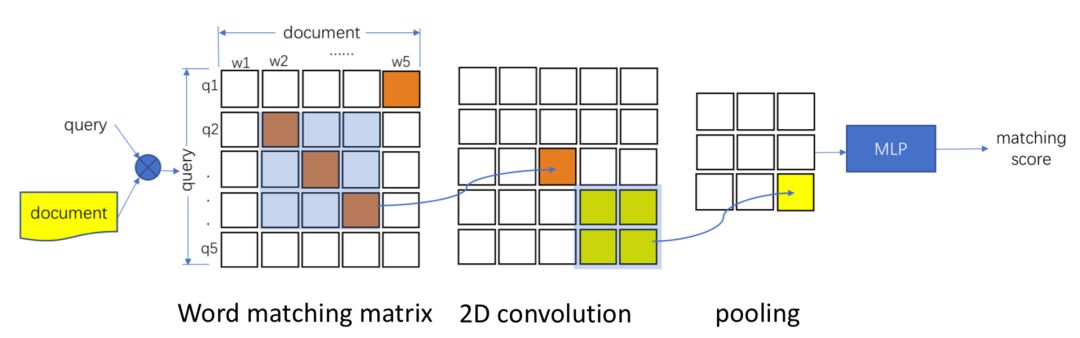
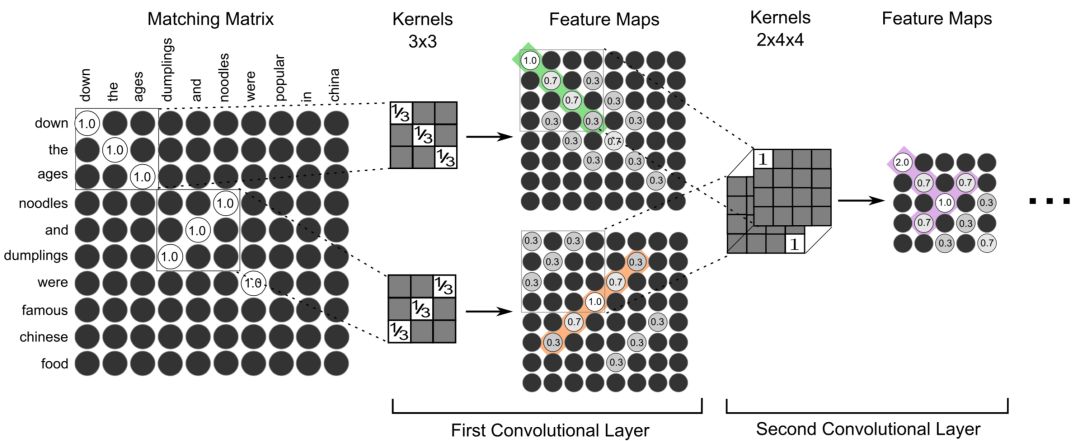
前面提到的ARC-II模型引入了匹配矩阵,但是匹配的粒度是n-gram后提取各自的word embedding进行计算,并不是word-level级别的。而MatchPyramid模型的提出灵感源于CV领域里的图像识别。在此之前,文本匹配的维度是一维的 ( TextCNN为代表的word embedding );而图像是二维平面的,显然信息更加丰富。2016年的AAAI上中科院提出了基于word-level级别交互的矩阵匹配思想,用一个二维矩阵来代表query和doc中每个word的交互,相比于更高level的匹配如ARC-II的phrase level(n-gram)信息能捕捉更精细的匹配信息,属于真正word level的匹配度矩阵,整体框架如图4.6所示:
图4.6 word-level的匹配矩阵模型示意图
以下图两个例子说明下word-level的匹配以及phrase-level的匹配的不同:
图4.7 word-level和phrase-level示例
对于word-level的匹配能捕捉到更细粒度的信息,例如橙色方框中能捕捉到famous对应popular以及Chinese对应China这样的匹配信息。
对于phrase-level的短语匹配又可以分为n-gram有序的短语,以及n-term无序的短语。图4.7显示的是trigram也就是3个词一个窗口,同颜色的方框是匹配的。对于n-term的匹配,方框中第一个句子中的"down the ages"和第二个句子中的"down the ages"是匹配的。对于n-gram的匹配,橙色方框中第一个句子中的"noodles and dumplings"和第二个句子中的"dumplings and noodles"通过3-gram后打乱了词序信息后是匹配的。
整个MatchPyramid模型框架如图4.8所示:
因此,文中的关键在于如何构建query和doc中word级别的匹配信息,整体框架可以分为3层,匹配矩阵层、2维卷积层、2维池化层,后续卷积和池化可以持续进行叠加。
匹配矩阵的构造是MatchPyramid模型的核心关键。用M矩阵代表query和doc的匹配,M
ij
为矩阵的第i行第j列,表示第一个句子query中第i个单词和第二个句子doc中第j个单词的交互。这里对于M
ij
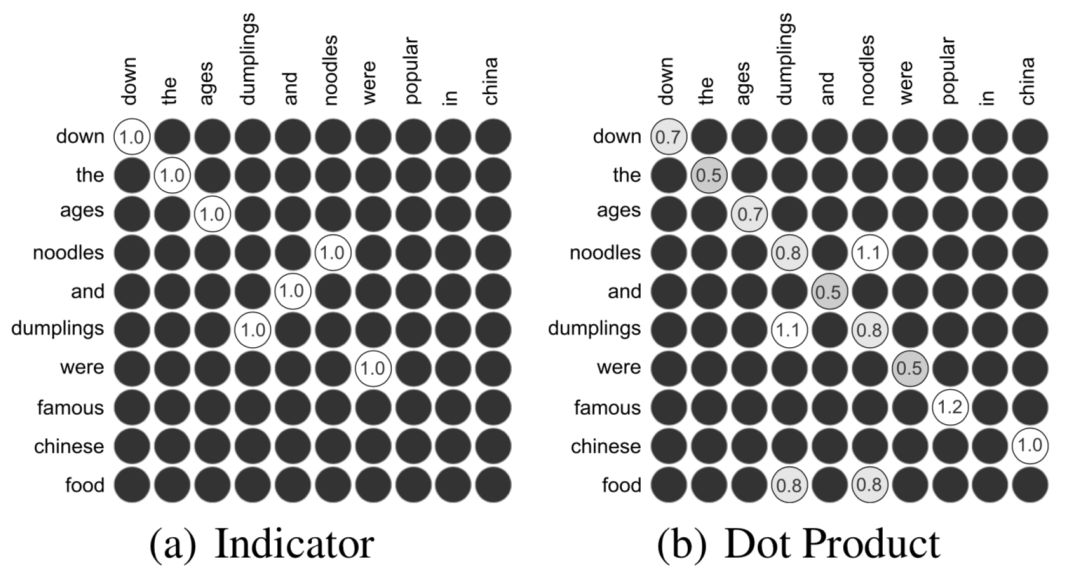
如何构造,有3种方法,indicator、cosine以及dot product,分别如下:
0-1匹配矩阵,只有两个word完全相同才等于1,否则为0,相当于是精确匹配:
将每个word用glove预训练得到的词向量,两两计算cosine相似度:
将每个word用glove预训练得到的词向量,两两计算向量点积:
图4.9显示了indicator和dot product两种,黑色部分是0;dot product或者cosine对比indicator能捕获到更多的泛化信息,例如在indicator对于famous和popular的匹配分数是0,而用dot product得到两者的匹配分数是1.2。
图4.9 indicator和dot product匹配计算方式
以第一层为例,通过一个r
k
* r
k
的卷积核提取二维匹配矩阵的信息,相当于是提取query和doc在各自连续r
k
个word的信息交互:
还是以第一层的池化层为例,在d
k
*d
k'
的kernel下用max-pooling求最大值:
以下这张图展示了MatchPyramid模型和图像识别中一些相似的匹配过程:
图4.10 MatchPyramid类比图像识别的匹配
图4.10左边用indicator match得到两个句子的相似匹配矩阵,相当于是精准匹配,第一层卷积层通过上下两个对角线以及反对角线的卷积核之后,可以得到两个feature map,第一个feature map的绿色部分和第二个feature map的橙色线条类似于图像识别中的边缘检测。通过第二层的卷积核之后,可以得到右侧的feature map中的紫色的“T-type”的part,这一部分类比于图像识别中的motifs(part)识别。
-
比起ARC-II模型通过n-gram得到的word embedding进行相似度计算,MatchPyramid模型在匹配矩阵的计算上做得更加精细,关注的是原始word级别的交互
-
对于query和doc之间每个word的两两交互提出了3中方法,包括精确匹配的indicator计算,两个word完全相同为1否则为0;以及语法相似度的匹配,包括cosine以及dot product,关注的是更泛化的匹配
-
整个过程和图像识别以及人类的认知一样,word-level的匹配信号,类比图像中的像素特征;phrase-level的匹配信号,包括n-gram有序的phrase以及n-term无序的phrase,类比图像中的边缘检测;到sentence-level的匹配信号,类比图像中的motifs检测
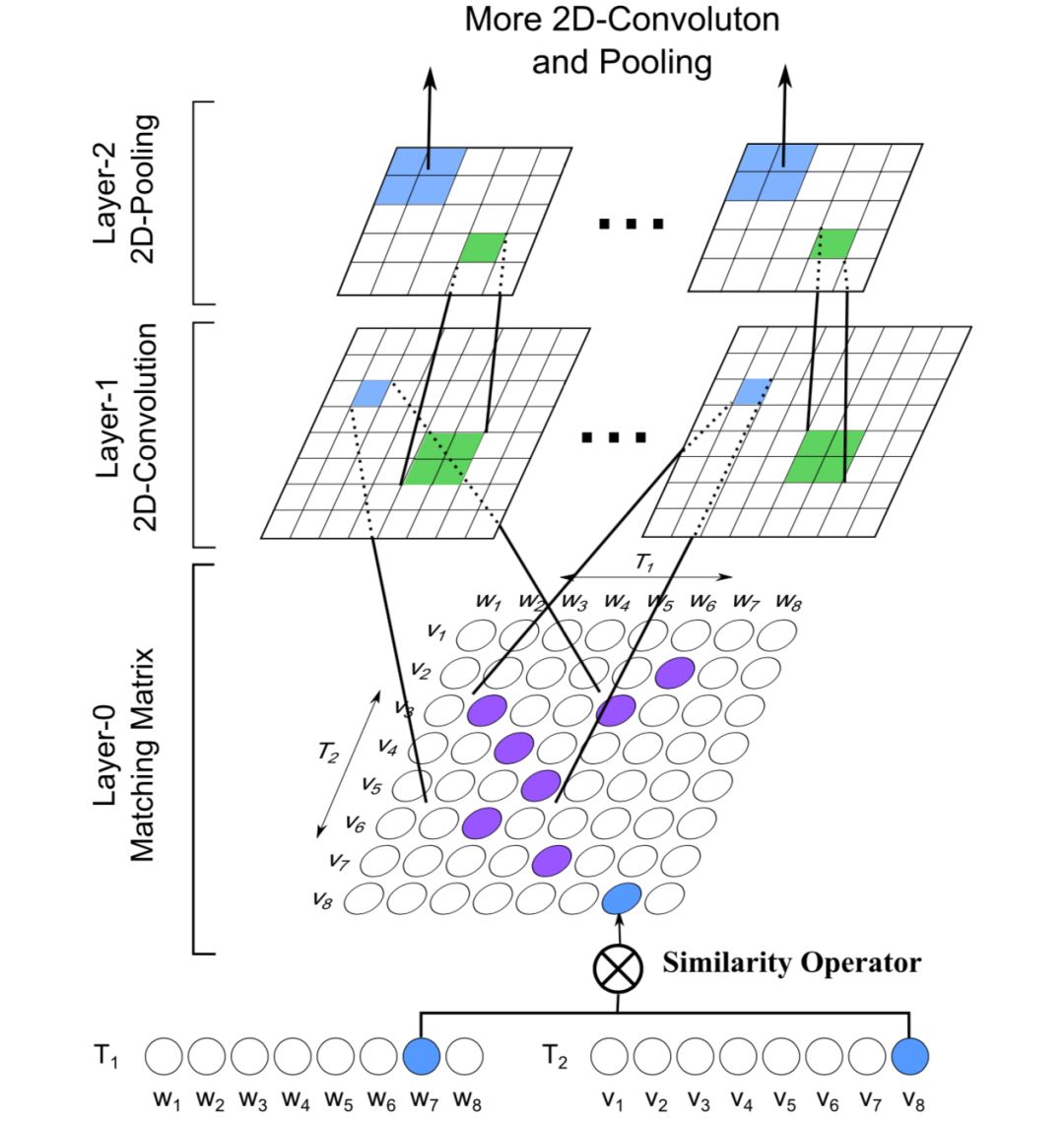
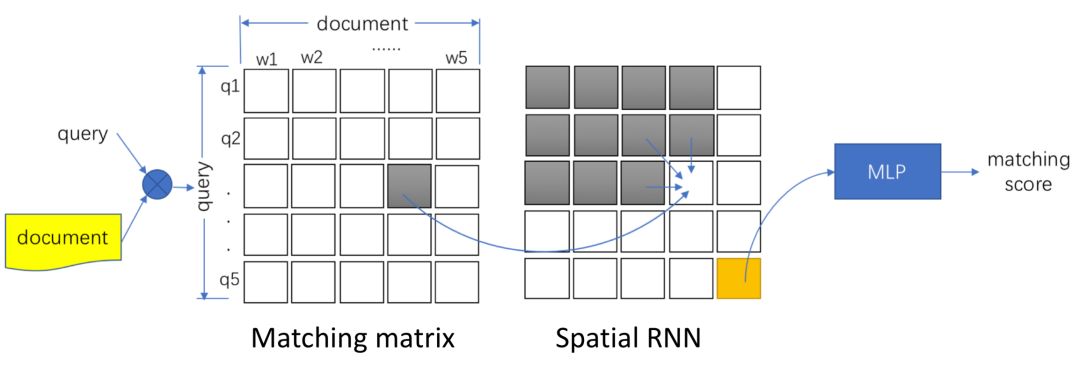
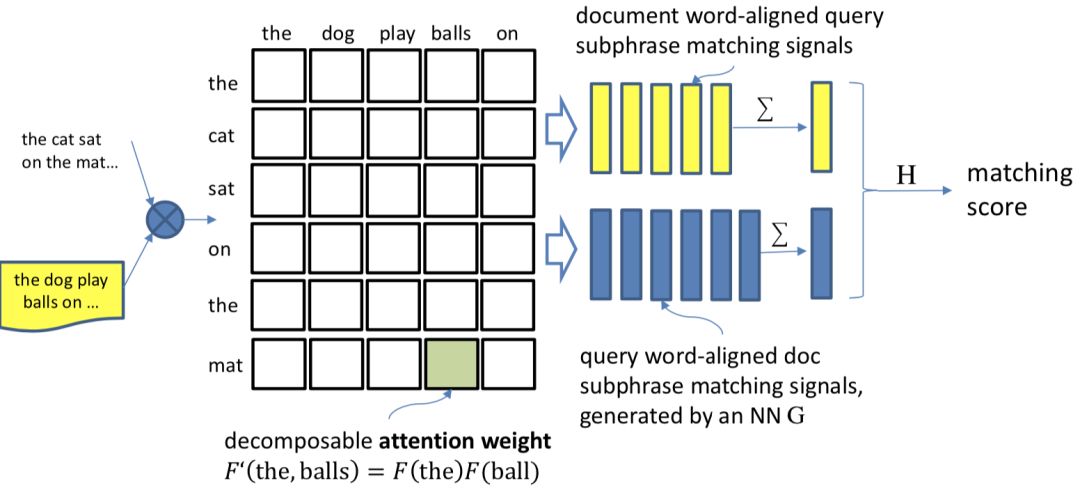
IJCAI2016上提出了一种空间相关RNN ( Spatial RNN ),全称Match-SRNN模型来拟合交互矩阵,类似于一种动态规划的思路,query和doc的交互矩阵中每个位置的值由不仅由当前两个word的交互值得到,还由其前面 ( 左、上、以及左上三个位置 ) 的值决定,模型整体框架如图4.12所示:
整个模型可以分为3个部分,分别是query和doc的匹配矩阵层、本文的核心Spatial RNN层以及最终的输出层。
首先,对于输入的两个文本query和doc的表示s
1
和s
2
,
分别由m和n个词组成的词向量组成。
对query中的m个term,以及doc中的n个term两两计算匹配分数得到初始的匹配矩阵,一般来说可以用cosine或者dot product来表达其匹配分数 ( MatchPyramid )。论文中作者提到为了更好的捕捉关系,引入了neural tensor network来拟合两者关系,具体有3个参数向量,T
[1:c]
代表的是层数为c的tensor向量,W为线型参数,维度和embedding size一致,而b为bias。
这一步其实对本文的核心模块是独立的,实际中也可以从简单的cosine、dot product甚至是indicator的直接先做计算,没有更多参数学习。
第一步得到了query和doc的原始匹配矩阵之后,作者使用了Spatial RNN的网络结构来进一步提取得到query和doc两段文本的关系。对于query中第i个term以及doc中的第j个term用s
ij
表示,它的值由其左边、上边、左上3个相邻的元素的函数所决定,表示如下:
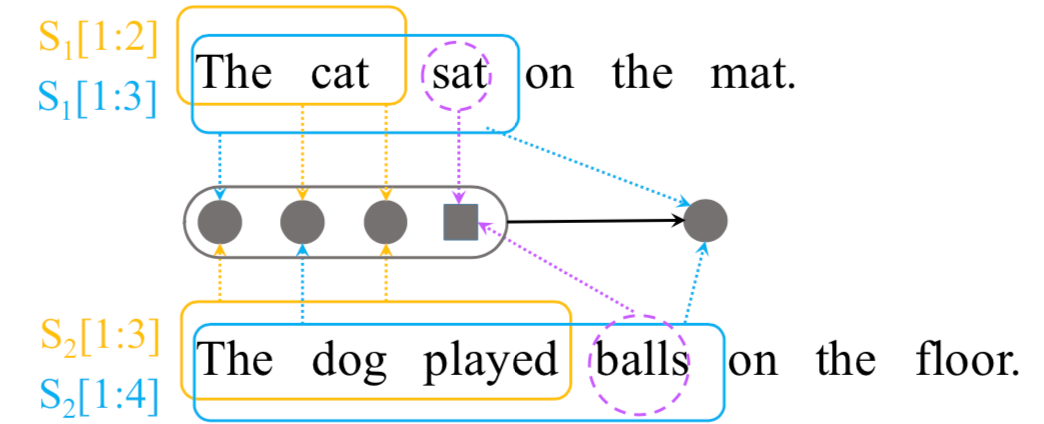
该公式是整个Spatial RNN的理解关键,结构和动态规划很像,以图4.13为例来直观理解整个过程。
给定两个句子s
1
="The cat sat on the mat.", s
2
="The dog played balls on the floor."
假设i=3,j=4,那么s
1
[1:3]={The cat sat},s
2
[1:4]={The dog played balls},那么,h
34
将由它的前缀h
24
,h
33
,h
23
这三项所决定。而s
1
中第3个词"sat"和s
2
中第4个词"balls"其中:
h
24
代表的是s
1
[1:2]={The cat}以及s
2
[1:4]={The dog played balls}
h
33
代表的是s
1
[1:3]={The cat sat}以及s
2
[1:3]={The dog played}
h
23
代表的是s
1
[1:2]={The cat}以及s
2
[1:3]={The dog played}
可以发现这三项中,h
33
其中占比应该最高,语义相关性也最强,和直觉认知也是符合的。这种递归的方式,也可以更好的捕捉两个句子之间的长依赖关系。
公式中的f是拟合的函数,可以采用多种时序相关的模型去拟合,比如RNN, LSTM,GRU等,作者在文中提到最终用的是GRU。在原始的GRU公式中,关键的是两个门reset gate z以及 update gate r,表达如图所示:
其中h
t-1
表示句子中第t-1个单词的隐层输出,z表示的是update gate,控制h
t-1
中有多少比例能够更新当前时刻的信息;r表示的是reset gate,控制着储存在cell中的信息;W(z),U(r),W(r), U(r),W,U为GRU中学要学习的模型参数。
可以发现原始的GRU的更新门z只有一个。而在Match-SRNN模型中,匹配矩阵是二维的,每个元素(i,j)的表达式是由3项组成的,分别是 (i-1,j),(I,j-1),(i-1,j-1),因此,论文中用了4个更新门z,分别表示为z
l
,z
t
,z
d
以及z
i
。三个reset门r
i
,
r
l
,r
d
示意图如图4.15所示:
4个update gate以及3个reset gate最终的表达如下:
从上一层SRNN层提取得到query s
1
和doc s
2
的交互矩阵后,要得到最终的match score就简单了,论文使用了简单的线性函数去拟合:
其中W和b为待学习的线性参数,通过训练得到。因为是相关性的rank问题,论文使用的是pairwise loss:
-
对比MatchPyramid模型,query和doc的匹配分数,使用neural tensor network结构,引入了参数得到初始匹配矩阵,更复杂的结构捕捉信息更精准
-
引入了Spatial RNN来进一步得到匹配矩阵,每个元素(i, j)的值除了当前的匹配s
ij
值,还由其左(i-1, j)、上(i, j-1)、左上(i-1, j-1)三个元素决定,通过网络结构f进行拟合
-
上述的网络结构f采用的2D-GRU,对比常规的1D-GRU,最大的特点是有4个update gate以及3个reset gate
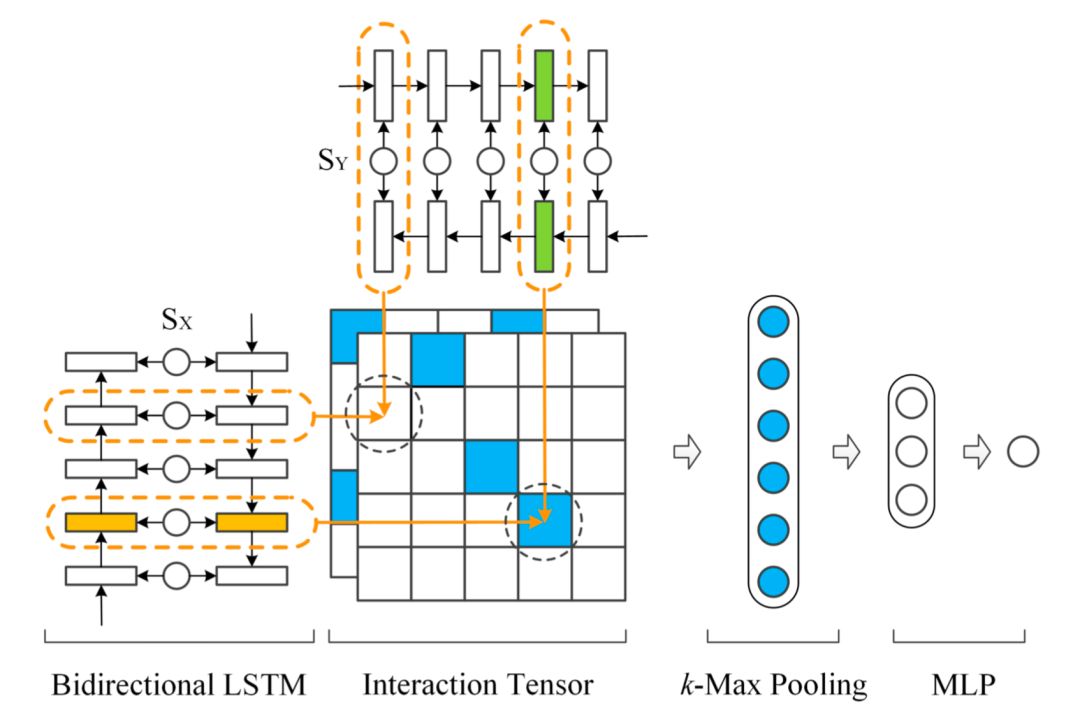
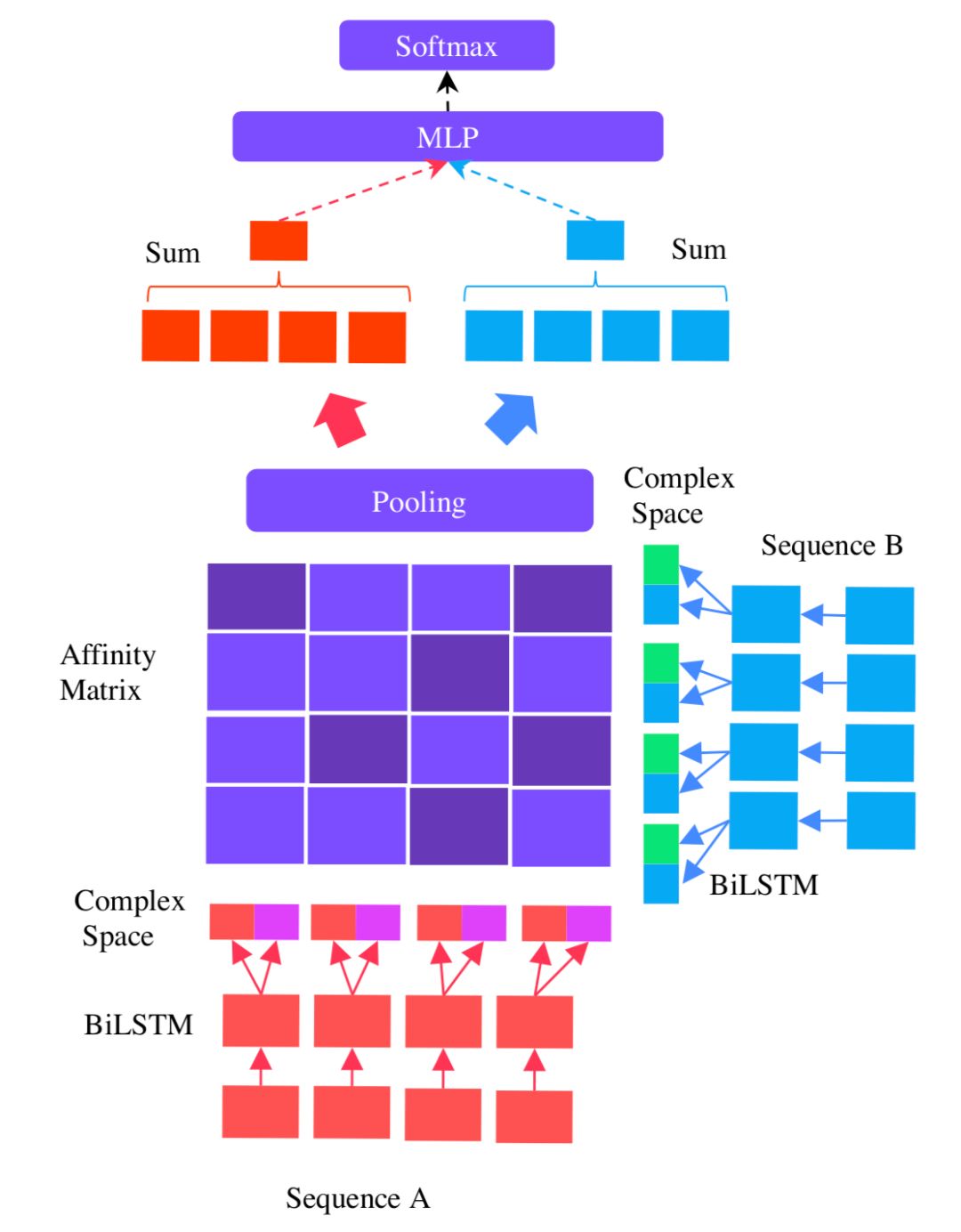
AAAI2016年提出的MV-LSTM模型,用双向LSTM来对两段文本query和doc进行编码,然后将LSTM的每个隐层输出进行归一化后作为query和doc每个term的输出,并对这些term计算得到不同维度的匹配度矩阵。由于采用双向LSTM的编码,以及不同的匹配度矩阵计算方法,作者认为这是个Multi-View的过程,能够捕捉到每个term在不同的语境下的表示,整体过程如图4.16所示:
整个模型可以分为3部分:① query和doc各自的LSTM编码;② query和doc的匹配矩阵;③ 匹配信号融合
对于给定的句子S=(x
0
,x
1
,x
2
,…,x
T
),MV-LSTM模型使用双向的LSTM进行编码,对于每个单词x
t
( 在query或者doc中的第t个term ),用LSTM隐层的输出h
t
作为其表示,由于是双向,因此将两个方向的输出进行concat:
上一步通过Bi-LSTM得到query和doc的表示S
X
和S
Y
,对于S
X
中每个term,以及S
Y
中每个term的交互可以得到匹配度矩阵。同样的,在这里作者提出了3种不同的计算方法:
query中的term u以及doc中的term v,计算cosine相似度
从上一步可以得到query和doc的匹配度矩阵,在这一步对匹配信号进行融合得到最终的匹配分数。
在计算两段文本的匹配过程中,一般来说整个匹配分都是由匹配矩阵中的特定匹配信号决定的,在论文中作者使用了k-max pooling进行这种匹配信号的提取。假设k=1代表的是最佳匹配信号,也就是整个匹配信号中最大的值才会被选择;对于k>1,代表的是选择匹配信号最大值的top k。
通过k-max pooling提取匹配信号后接着就是用简单的全连接网络f后得到r,再经过线性映射得到最终的匹配分数s:
-
用双向LSTM对query和doc进行编码,得到的每个term的隐层前向和后向输出concat起来,作为该term的表示
-
对query和doc上一步得到的每个term两两计算匹配分数,文中提到了cosine、双线性以及tensor layer这3种计算方法,由于网络参数的不断加大,拟合精确度和复杂度也依次提升
-
对前一步得到的匹配度矩阵,先是用k-max pooling提取,然后用MLP后输出最终的匹配分数
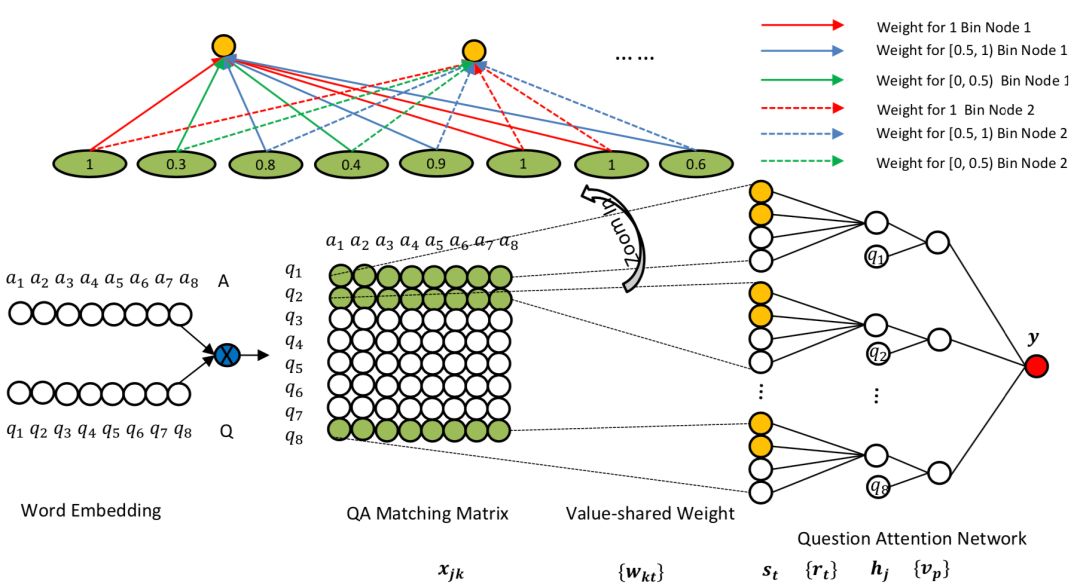
CIKM2016年提出的attention based Neural Matching Model,简称aNMM模型,原文主要解决QA匹配问题,模型同样可以应用在query和doc中两段文本的匹配关系设计中。前面讲到的ARC-II模型以及MatchPyramid在匹配矩阵后,都用到CNN的卷积层做n-gram的提取。而CNN卷积的基本思想,是不同位置的word是共享权重。而在aNMM模型中,作者认为不同位置的word在卷积核中共享权重是不合理的,因此提出了基于value的共享权重方法。根据共享权重的组数不同,论文提出了两种模型,aNMM-1模型和aNMM-2模型。
按照模型结构可以分为3层,输入层、value share层以及attention层
对于给定的问题query q,以及对应的文档a,q由m个word组成,a由n个word组成,通过word embedding得到q和a各自的embedding矩阵。让q和a的word两两求cosine相似度,可以得到一个M*N的匹配矩阵P,里面的每个元素P
j,i
代表的是q中的第j个term,以及a中第i个term的相似度。
从匹配矩阵中P提取到的不同q和a的匹配分数存在一个问题,就是给定一个query,不同doc长度是不同的,得到的匹配矩阵的大小也不同。因此需要有个机制将其映射到定长的维度中去方便后续网络处理。
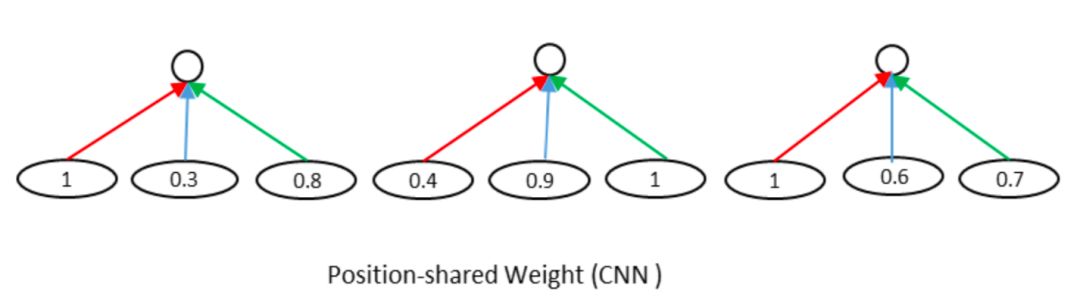
这里很容易想到CV领域里的CNN网络结构,通过卷积和池化的方法进行维度的压缩。在图像领域CNN之所以能够奏效,很大程度在于图像本身的局部关系,也就是CNN的权重是position-shared的。如图4.17所示是个3*1的卷积核,相同颜色的边共享权重,所有同个位置的边共享相同的权重,在途中分别是红色、蓝色和绿色。
图4.17 position-share权重的CNN
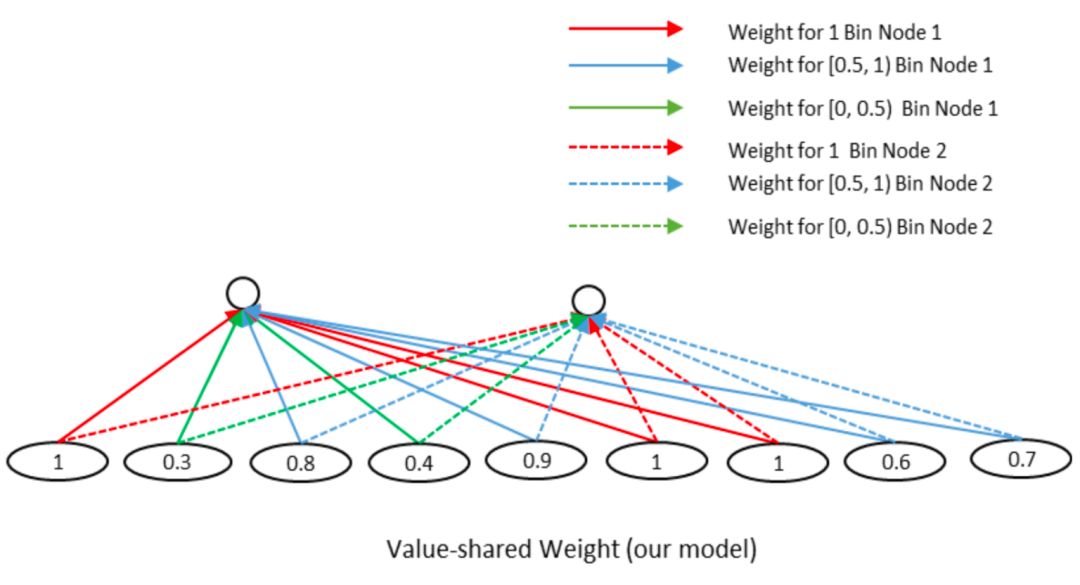
但是在NLP领域的文本匹配问题上,query和doc的匹配term可能出现在任意位置上,并不一定是强位置关联的。在前面得到的query-doc匹配矩阵P中,不同的匹配分数值对最终结果的共享程度是不同的,相同权重的对结果的共享应该一致,因此作者提出了一种value-shared的权重方法,如图4.18所示。
图4.18 value-share weight示意图
为了方便说明,在图中将区间分成3个桶,[0,0.5],[0.5,1],[1,1]。其中实线部分表示上面第一个结点node1的参数,虚数部分表示第二个结点node2的参数。同样的,相同线型和颜色的表示共享权重。权重等于1的3个结点用红色共享权重,权重小于0.5的两个结点0.3和0.4用绿色共享权重,权重大于等于0.5小于1的4个节点 ( 0.8、0.9、0.6、0.7 ) 共享权重。
由于匹配矩阵P中每个元素的值都是在-1到1之间 ( cosine取之范围 )。因此在实际模型中作者将取值范围区间按照0.1进行分桶,总共有21个分桶,落到相同的分桶区间的value是共享权重的。通过这样的方式,可以将匹配矩阵转为相同的维度,不管输入矩阵的维度大小,隐层节点的个数都是固定的。
假设后续隐层的维度为K+1,另x
jk
表示问题q中第j个term,在第k个分桶节点上的所有匹配信号值,那么隐层第j个节点则为这K+1个分桶的加权求和:
经过前面两层网络,对于每个query-doc对,都可以计算得到一个M*1的向量,向量的每个元素都表示doc与当前query中M个term中每个term的相似度。
作者在论文中引入了参数向量v,维度和P一致,来对问题中的每个term求点积映射得到每个term的权重并做softmax归一化,然后和前面得到的每个隐层节点h
j
相乘,得到最总的匹配分数y:
相比于anmm-1的改进在于,对于value-share权重网络,anmm-1只有一个。而类比于CNN的卷积层有多个filter,anmm-2提出来可以有k个value-share权重网络,表示权重网络的组数,整体网络结构如图4.19所示。
-
借鉴了CNN模型中相同位置共享权重 ( position-shared weight ) 的思想,认为QA匹配问题 ( 可以扩展到其他的query和doc的两段文本匹配问题 ) 不应该是同位置共享,而应该是相同的匹配值共享权重 ( value-shared weight ),从而起到pooling的作用,保证隐层个数都相同
-
类比CNN的多个filter思路,共享权值网络也可以有多层
基于word level的匹配度矩阵可以说是整个基于match function learning模型的标配组件,而这有这种low level的匹配矩阵信息基本是不够的,在当前attention机制在整个NLP领域随处可见的情况下,attention也基本成了后续众多模型的标配组件之一。除了徐君老师的slides里的DecAtt模型,本章也加入了近两年在各大主会&文本比赛里比较流行的十几个模型,如BiMPM、ESIM、DIIN等。
前面讲的基于CNN的匹配模型如ARC-II,CNN-DSSM模型在匹配的时候使用了在图像和文本领域都大放异彩的CNN模块,2015年的ACL上在此基础上又加入了近年来在CV和NLP也同样无处不在的attention模块,Attention-Based CNN模型,简称ABCNN用来做query和doc的文本匹配。
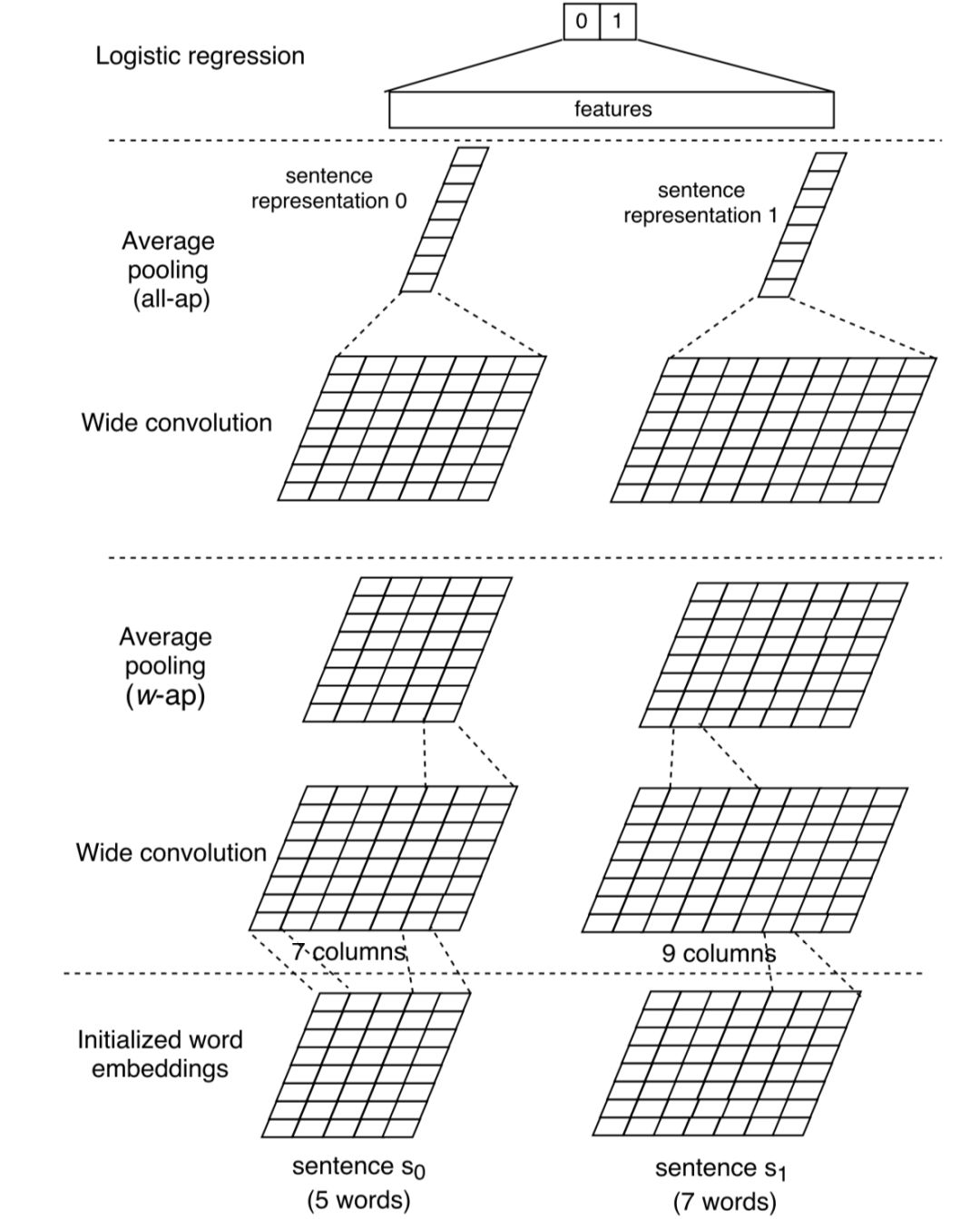
在加入attention之前,先看下没有attention的Basic CNN模型,简称BCNN模型,如图4.20所示:
对于query和doc两个输入的文本表示为s
0
和s
1
,长度分别为s
0
和s
1
( 实际操作需要用 0补齐到一样的长度s ),为了方便进行说明,在图中没有pad的这一步。
两个句子的embedding向量,embed维度为d
0
( 图中等于8 ),输入均为d
0
*s
通过维度大小为w*d
0
的卷积核,分别沿着词的方向做卷积,d
0
高度方向和词的embedding维度保持一致,w表示卷积的宽度。论文使用的是wide convolution,也就是对原始输入需要左右长度为w-1的方向分别补0,这样,经过宽卷积的feature map为 s+w-1,在图中,左边s=5, w=3,因此卷积后feature map为7*d
0
;右边s=7,w=3,卷积后feature map维度为9*d
0
。卷积核个数为d
1
。
-
Average pooling(w-ap):如图4.20所示,使用滑动窗口的方式,滑动窗口大小为w,这样经过宽卷积列数为s+w-1的feature map经过w-ap后,列数重新变为s列。这样的好处是可以根据情况叠加任意多层的wide convolution +average pooling
-
All pooling (ap):最后一层的pooling使用的是在整个句子维度s的pooling,最终得到一个列向量。最终的原始句子s
0
和s
1
经过这些网络结构后变为左右两个列向量concat后输入到MLP网络中
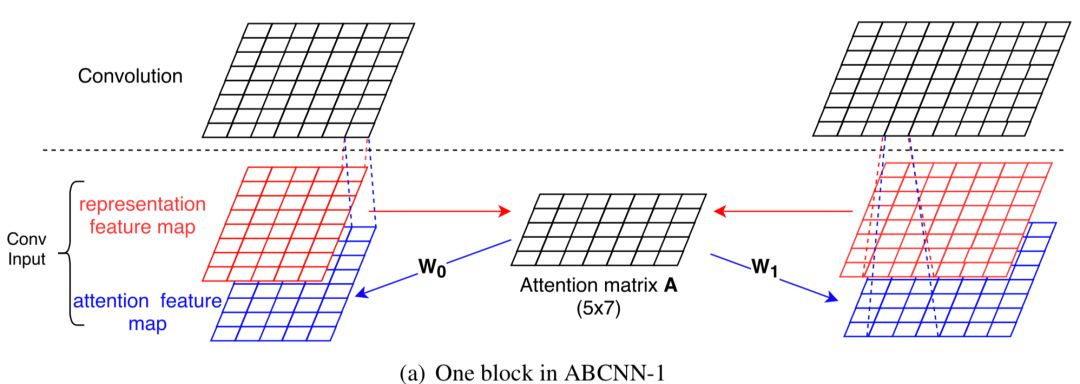
论文提出的第一种attention-based的CNN结构为ABCNN-1,如图4.21所示:
对比前面没有attention的BCNN,最大特点是两段文本query和doc s
0
和s
1
的卷积表示,不再只是自身的表达,而是引入了s
0
和s
1
的交互矩阵A。用F
0,r
,F
1,r
表示原始句子的向量表达,大小均为s*d,表达如下:
这里F
i,j
表示的是query s
0
的第i个term和doc s
1
的第j个term的match score,match score,大小为s*s,可以采用多种衡量距离的方式,论文文中使用如下的表达发现效果不错,简单来说,如果x和y越接近,匹配分数越接近于1:
通过引入attention矩阵W
0
和W
1
,得到两段文本query和doc的最终加权特征向量F
0,a
和F
1,a
:
将原始的句子向量F
0,r
,F
1,r
以及attention特征向量F
0,a
和F
1,a
concat一起后作为最终MLP的输出。
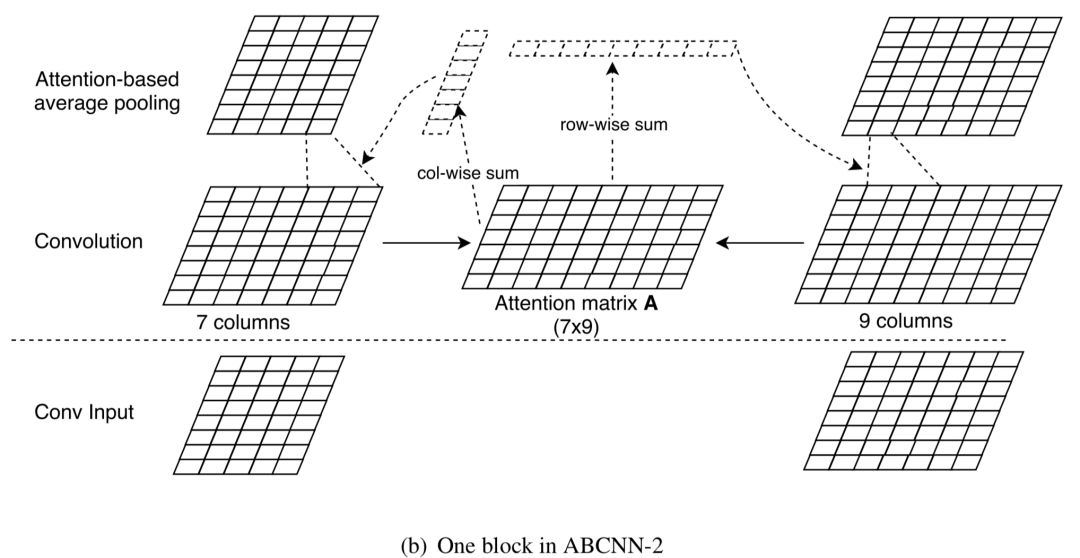
ABCNN-1的attention机制发生在卷积操作之前,而ABCNN-2是在卷积输出之后进行attention。原始的句子向量经过卷积后,得到7*d和9*d的表示。因此query s
0
以及doc s
1
的交互attention矩阵A是个7*9的矩阵(实际中也会用0补齐),如图4.22所示。
其中a
0,j
表示的是第0个句子query s
0
的第j个单词,它的权重为attention矩阵中第j行的和;a
1,j
表示的是第1个句子doc s
1
的第 j个单词。
用F
i,r,c
表示的是第i个句子中卷积层的输出,F
i,r,p
表示第i个句子池化层的输出,通过一个w的滑动窗口,池化层第j列 ( 每一列长度为d ) 为卷积层第j列到第j+w列以及attention矩阵A相乘得到。
总结来说,ABCNN-1和ABCNN-2有几个不同的地方在于:
-
ABCNN-1方法中的attention是作用在卷积层,而ABCNN-2是发生在池化层,也就是已经过了卷积层。
-
ABCNN-1方法需要两个额外的转换矩阵W
0
和W
1
得到attention特征向量,从而比ABCNN-2需要更多的参数。因此作者认为更容易过拟合。
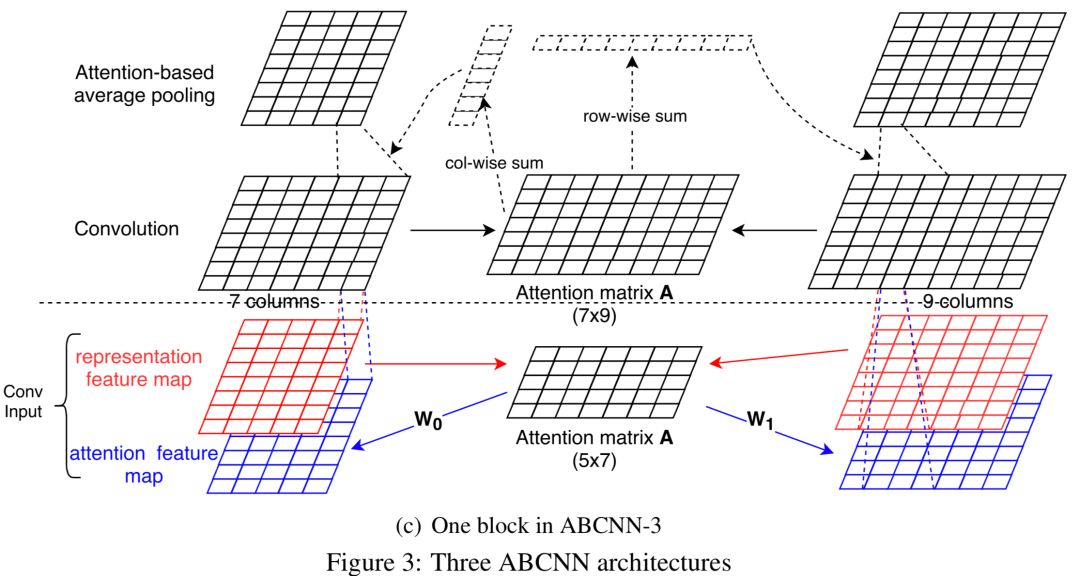
ABCNN-3做的是同时结合ABCNN-1和ABCNN-2方法,如图4.23所示:
-
ABCNN-1模型的attention机制发生在卷积层之前,也就是两段文本交互计算之前。query和doc原始向量表示为F
0,r
,F
1,r
,通过参数矩阵W
0
和W1得到加权表示F
0,a
和F
1,a
,四个向量concat后进行卷积。额外引入参数W
0
和W1,作者认为容易发生过拟合。
-
ABCNN-2模型的attention机制发生在卷积之后,也就是两段文本已经交互计算之后。通过计算query和doc的attention矩阵A,然后对query和doc的卷积进行加权滑动得到池化的输出。
-
ABCNN-3同时将ABCNN-1和ABCNN-2两个模型做融合。
EMNLP 2016提出的Decomposable Attention Model,简称DecAtt模型,是较早在query和doc的关系建模上引入attention机制的。该模型将两个句子通过分解 ( decompose ) 成每个word的软对齐机制,来计算当前文本query ( doc ) 中每个word与另一段文本doc ( query ) 的attention得到每个word的加权向量,然后通过当前word的原始向量与attention加权向量的compare,最终对交互得到的向量进行aggregate得到最终的匹配分数,整体框架如图4.24所示:
query和doc各自由l
a
和l
b
个term组成,每个term是个定长的embedding向量:
整个模型可以分为3步、attend、compare以及aggregate
对于query向量a的第i个term和doc向量b的第j个term的权重用如下公式表示:
其中F用的是普通的神经网络并经过RELU激活。如果使用F'函数,复杂度为l
a
*l
b
。而先用F函数拟合query和doc各自的表达,则F只需要计算次数为l
a
+l
b
。原始的复杂度从l
a
*l
b
变成了l
a
+l
b
。
除此之外,论文中将attention机制看成一种软对齐机制(soft-align),将query中第i个word与doc中每个word分别求权重,然后加权求和,就可以得到第i个word的权重β
i
;同理可以得到doc向量b中第j个word的权重α
j
:
从①可以得到query向量a和doc向量b中每个word的权重β
i
和α
j
,通过函数G就可以得到各自的加权 ( soft-align ) 表达,这里G用的是MLP全连接网络:
得到每个word的加权表达后,最终的句子为每个word直接sum得到:
由于NLI是个分类问题,因此后面使用一个线性分类器进行分类:
总结DecAtt模型,整体可以用如下图4.25所示:
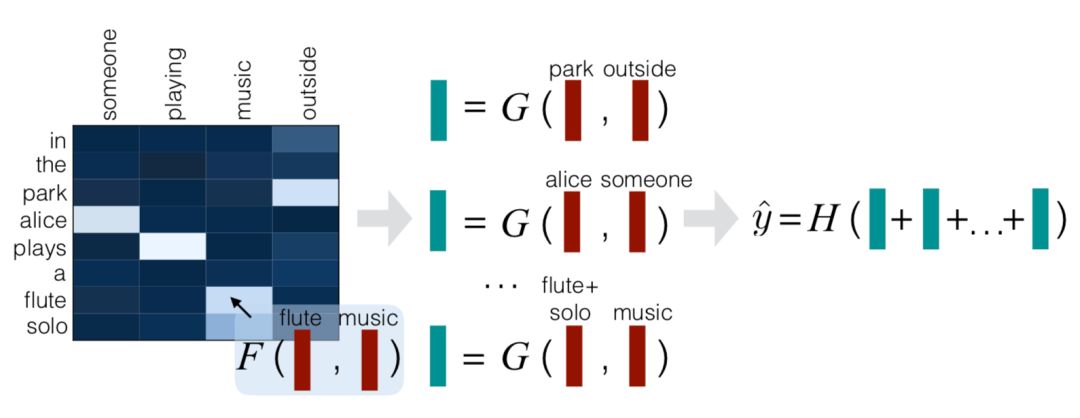
① attend:用attention机制看成soft-align对齐过程,得到query和document中每个word的加权向量 ( subphrase )
② compare:把每个word的加权向量subphrase,与原始的向量进行compare通过一个前向网络拟合,作为query的最终向量以及doc的最终向量
③ aggregate:通过一个神经网络H去捕捉query和doc的向量,得到匹配分数。在该paper中是个分类问题,因此使用的是交叉熵作为损失函数
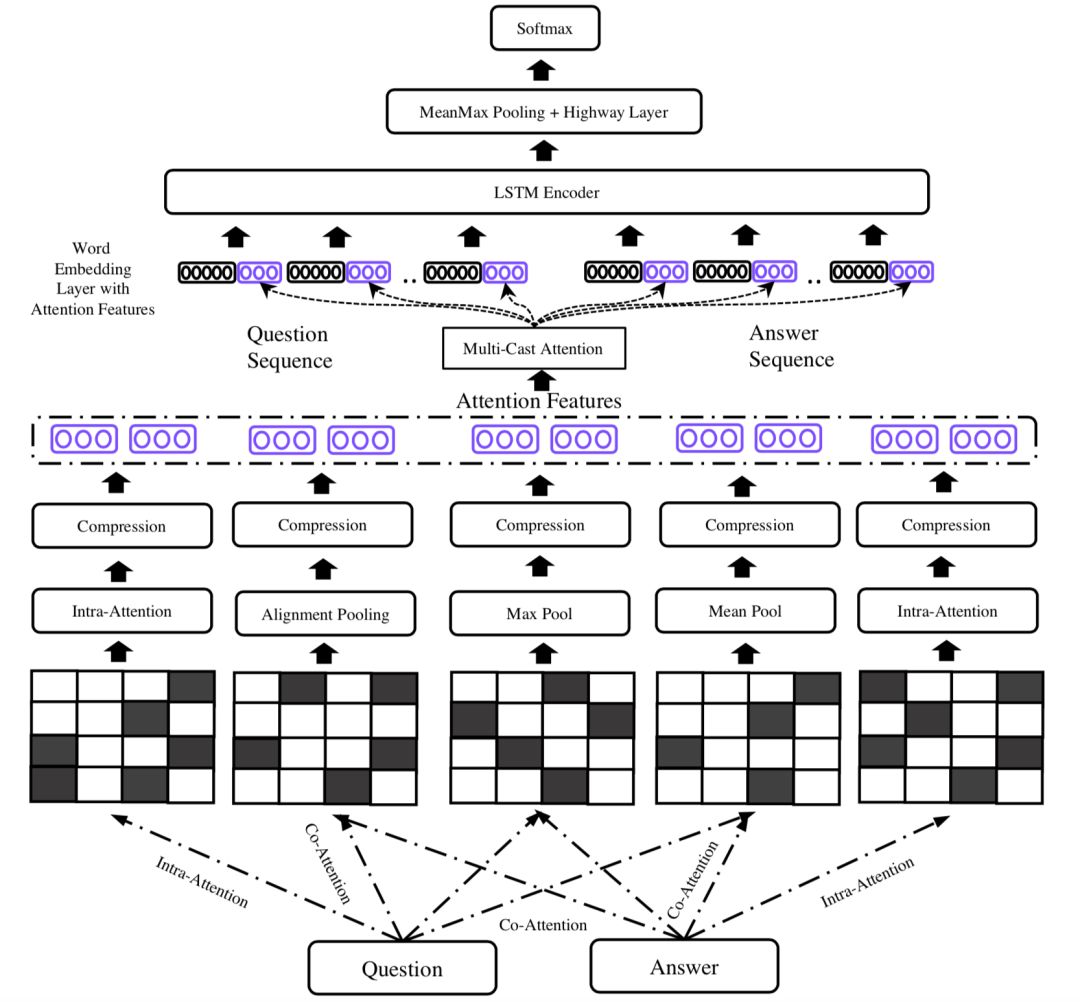
在文本匹配的很多模型中,现有的很多基于attention的模型通常都把attention看成一种特征提取的工具,但是缺陷是常常仅受限于一种attention的变体,如果要使用多个attention,通常是使用concat的方式,整个模型结构将会成倍变大。在2018KDD上,南洋理工大学提出了一种Multi-Cast Attention Network,简称MCAN模型,论文面对的问题是QA,一样可以扩展到query和doc的文本匹配中。模型通过多视角的attention新框架来解决这个问题,如图4.26所示:
从整个模型框架来看可以分成5层:① input encoder层;② co-attention层;③ multi-cast attention层;④ LSTM encoder层;⑤ 输出层
首先,将两段文本query和doc分别通过预训练得到的word embedding进行映射后,得到各自的embedding向量,每个term的embedding size为d。然后通过highway encoder进行映射。这里的highway encoder类似于一种门机制,用来控制当前输入的每个term流入到下一层的信息多少。
比较经典的一个highway表达如下,给定x,得到的Highway encoder输出y:
其中H为RELU,T为sigmoid函数,W
H
和W
T
为待训练的参数,维度为r*d。
对于query中第i个term以及doc中第j个term的匹配分数s
ij
,论文中使用经过F映射后的向量点积如下:
其中F(.)可以采用简单MLP网络,另外这里也可以采用双线性映射或者concat的方式得到s
ij
的值。对query中的l
q
个word和doc中的l
d
个term两两进行上述计算,可以得到一个l
q
*l
d
的匹配矩阵。
由于每个query和doc的输入长度都不一致,因此需要通过attention pooling机制做映射,论文提出了4种不同的attention方法
对于query的第i个term,选择和doc中所有l
b
个word在交互矩阵中最大的值来代表其重要性,相当于是在第i行选择最大的值,所以是col-wise的max pooling;同理对于doc来说是row-wise操作:
对于query的第i个term,选择和doc中所有l
b
个word在交互矩阵中的平均值来代表其重要性,因此是col-wise的mean pooling:
c.
alignment pooling
对齐池化
把attention机制看成是一种软对齐 ( soft align ),思想和4.2.2讲到的DecAtt模型一致,将query中第i个term与doc中每个term ( 一共l
b
个 )分别求权重,然后加权求和,就可以得到第i个term的加权向量d
i
';同理可以得到doc向量b中第j个term的加权向量q
j
'。
对于query里的每个term都计算与query里所有term的交叉权重并做归一化,最终每个term都是query里所有term的加权向量表达;同理,对于doc里的每个term也做同样的操作,得到每个term的加权向量表达。由于该步骤都是在query和doc内部计算,因此也称为self-attention。
③ mu
lti-cast-attention
层
对于co-attention层得到的不同表示侧重点不同,因此在这一层为了是为了将不同的attention进行融合,同时控制参数复杂度。该层也是整个模型MCAN ( Multi-Cast-Attention Network ) 的核心所在。
对于query和doc的表示用
x
表示,通过前一层co-attention得到的表示用x表示,对两个向量的编码,分别用concat、哈达码积、以及minus不同的方法表示,分别得到f
c
、f
m
和f
s
如下所示:
对于前面讲到的F
c
,目的是为了将不同的两个向量进行压缩表示,具体有三种表达方式如下:
Ⅲ. Factorization Machines(FM)
对于不同的attention casts之间,由于捕捉的是不同的是attention,模型之间并不共享权重。
对于每个query-doc的pair对,都分别计算max pooling、mean pooling以及alignment pooling。对于query和doc本身则使用intra attention,如图所示。每种attention机制都可以得到一个3维的向量 ( 代表concat、点积和minus的3个输出值f
c
、f
m
和f
s
),并且和原始的word embedding concat后进入下一层。
前一层得到的的表示再经过一层LSTM来学习得到序列之间的关系:
注意这里对query和doc都应用上述的LSTM公式,且LSTM的模型参数在query和doc之间是共享的。LSTM的每个隐层的输出h
1
,h
2
,h
3
,…,h
l
之后得到的是不定长的输出,作者使用了mean pooling和max pooling并把结果concat起来,称为Mean-Max操作,对query和doc都得到一个固定维度的输出向量x
q
和x
d
。
前面得到query和doc的最终表示x
q
和x
d
后,经过向量点积、相减并且经过两层的highway network H
1
和H
2
后得到prediction 的输出:
-
输入层通过highway encoder将原始的embedding经过编码输入下一层
-
attention层分为两部分co-attention以及multi-cast attention。对于co-attention层对于每个query-doc的pair对,使用max pooling、mean pooling以及alignment pooling三种attention机制,对query和doc本身则使用intra-attention(self-attention)
-
通过前一层的co-attention,query和doc可以得到3种attention:alignment-pooling,max-pooling以及mean-pooling。对于query和doc则各自得到intra-pooling,一共有5个attention,每个attention可以得到原始向量与attention交互后的向量,通过concat、哈达码积和minus后,经过压缩函数进入下一层
-
前面5种attention得到的网络经过LSTM编码,并经过mean-max池化后得到固定维度向量,经过两层的high way网络后套上softmax输出
IJCAI2018年新加坡南洋理工大学提出的HCRN模型,提出了一种复数向量。该模型和4.2.3介绍的模型MCAN模型是同一个团队,可以发现HCAN模型里很多网络结构都和MCAN都有相同的地方,整个框架如图4.27所示。
对于给定的两个句子a和b,每个句子由l个term组成,通过W
e
矩阵将每个term映射到维度为r的embedding空间:
每个term w
i
通过W
p
映射并经过RELU激活输出,得到新空间下的向量u
i
,维度从d变成了n:
接着,通过一个双向的LSTM,得到句子中每个时刻的隐层输出h
i
:
其中,每个隐层的输出为d维的向量,由于是双向LSTM,每个隐层的输出包含前向向量和后向向量,因此d=2n。
② v
anilla
co
-attention
机制
对于BiLSTM层的输出,可以得到两个句子的向量a和b,接着得到两个向量的匹配矩阵s,维度为l
a
*l
b
,第一个句子第i个term和第二个句子第j个term通过F函数求向量点积匹配分:
把attention机制看成是一种软对齐 ( soft align ),思想和DecAtt模型一致,将query中第i个term与doc中每个word ( 一共l
b
个 ) 分别求权重,然后加权求和,就可以得到第i个word的权重β
i
;同理可以得到doc向量b中第j个word的权重α
j
:
对于query和doc,分别采在column-wise和row-wise维度上进行max pooling,取最大值得到query和doc新的表示a'和b':
其中S函数为softmax函数。也就是说,对于query的l
a
个word中的第i个word,选择和doc中所有l
b
个word交互矩阵中最大的值来代表其重要性,相当于是在第i行选择最大的值,所以是col-wise;同理对于doc来说是row-wise操作。
③
He
rmitian Co-Attention
这一步个人认为是主要区别于MCAN模型的地方。论文提出了将原始的向量映射到复数向量的方法,对于两个复数向量的乘积,也称为Hermitian Inner product,定义如下:
其中a
i
=Re(a
i
)+Im(a
i
),左边Re(a
i
)代表的是复数向量的实数部分,第二项IM(a
i
)代表的是复数向量a
i
的虚数部分,这里i是虚数单位,是-1的平方根。
a
i
是a
i
的共轭复数 ( 两个复数a和b,实数部分相等,虚数部分互为相反数称为共轭复数 ),也就是a
i
= Re(a
i
)-Im(a
i
)。
通过上一层得到的query和doc的embedding都是实数向量,为了得到虚数部分向量,论文里提到试过对虚数向量进行随机初始化,或者直接用原始的word embedding,效果都不好,最终模型使用的是个非线性映射得到映射,对于query和doc分别得到F
proj
(a
i
)以及F
proj
(b
j
)。
得到query第i个term虚数向量F
proj
(a
i
),以及doc第j个term的虚数向量F
proj
(b
j
)后,匹配分数通过计算两者的Hermitian inner product,并取实数部分得到:
论文里同样也利用一个d*d维度的M矩阵来进行双线性的复数向量计算:
总结来说,HCRN模型和MCAN模型均出自同一团队,有许多的地方是相似的:
-
第一层的input encoding,HCRN模型的word embedding经过线性映射然后通过双向LSTM编码得到表示;而MCAN是通过high way 网络结构对word embedding进行编码表示
-
第二层都是co-attention,HCRN模型用了两种attention机制:alignment pooling以及extractive pooling ( max pooling );而MCAN模型用的是4种:alignment pooling、max pooling、mean pooling以及self-attention。可以看出,HCRN模型少了mean pooling以及self-attention
-
第三层开始HCRAN提出了复数向量化的概念,并计算复数向量化的Hermitian内积得到匹配分数,然后通过M矩阵映射后得到最终的匹配分数
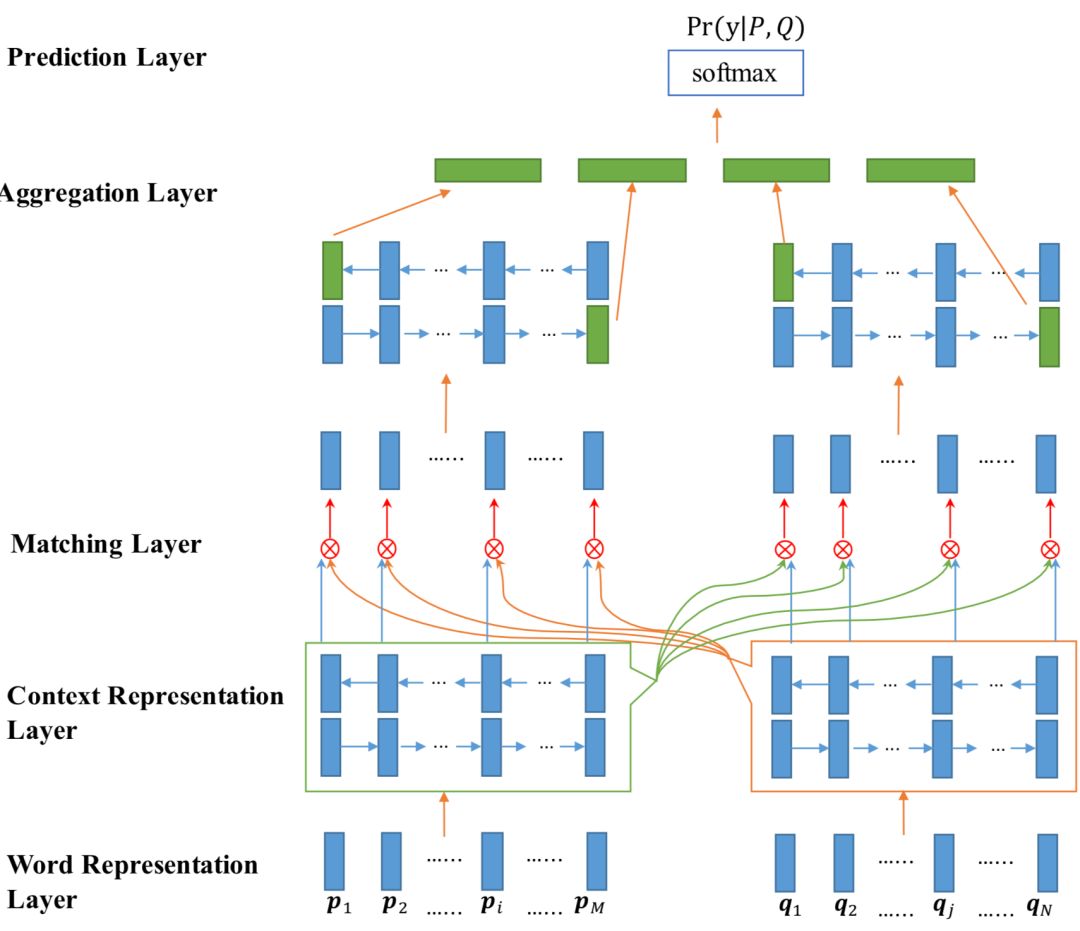
IJCAI2017年提出的双向多角度匹配模型Bilateral Multi-Perspective Matching模型,简称BiMPM模型,在关于文本匹配的很多任务上都取得了些不错的成绩。该模型最大的创新点在于,对于给定的query和doc,作者认为在匹配过程中,不仅需要考虑query到doc,也应该考虑从doc到query的倒推关系,因此这是个双边 ( Bilateral ) 的关系。对于多角度,则是在考虑两个句子query和doc的关系的时候,用了4种不同的方法,体现了多角度 ( Multi-Perspective ) 的思想。整个模型结构如图4.28所示:
如上图所示,整个模型可以分为5层:① 词表示层;② 上下文表示层;③ 匹配层;④ 聚合层;⑤ 输出层
①
词表示层 ( wo
rd representation layer )
这一层的主要目的是将原始的两个句子P和Q中每个词,映射成一个维度为d的embedding向量。
其中P由M个word组成,Q由N个word组成其。对于P和Q中的每个word,由两部分embedding构成,第一部分是word本身经过预训练得到的embedding向量,第二部分是字符集别的embedding向量 ( character-composed embedding ),是由组成word的每一个字符向量经过LSTM编码得到,取LSTM中最后一个隐层的输出作为字符向量。
② 上下文表示层 (
context representation layer )
这一层的目的是将上下文信息融入到句子P和句子Q的每一个time step中去,文中采用双向LSTM对上下文进行编码。对于第一个句子P(query),其前向和后向编码表示如下:
其中p
i
表示句子P中第i个word的embedding输入,h
i
表示i时刻 ( 第i个word ) 的隐层输出,h
i-1
和h
i+1
分别表示前一时刻i-1和后一时刻i+1的隐层输出。
对于第二个句子Q(doc),同样采用双向LSTM来表示:
其中q
j
表示句子Q中第j个word的embedding输入,h
j
表示j时刻 ( 第j个word ) 的隐层输出,h
j-1
和h
j+1
分别表示前一时刻j-1和后一时刻j+1的隐层输出。
③
匹配层 ( mat
ching layer )
这一步是整个BiMPM模型的核心创新,该层的目的是,在前一步提取了P和Q两个方向的隐层输出embedding表示后,在匹配层需要找到两者的匹配关系。模型分别从P-Q以及Q->P两个方向进行匹配。
首先,对于给定的两个向量v
1
和v
2
为了得到其匹配关系 ( 相似度、相关度 ),简单的无参数做法是求向量点积,或者cosine相似度。为了更好拟合两者关系,论文引入了新参数W,其中v
1
和v
2
是d维向量,W是一个l*d的参数矩阵,通过训练得到,其中l是视角 ( perspective ) 的数量,类似CNN中的filters概念。
通过参数W以及拟合函数f
m
( 后续会讲到如何设计 ),将原始的两个向量从d维映射得到一个l维的向量m:
其中m中的每一个元素m
k
(k=1,2,3…,l)由v
1
和v
2
经过W
k
矩阵的映射向量求cosine得到其余弦匹配分数如下:
对于f
m
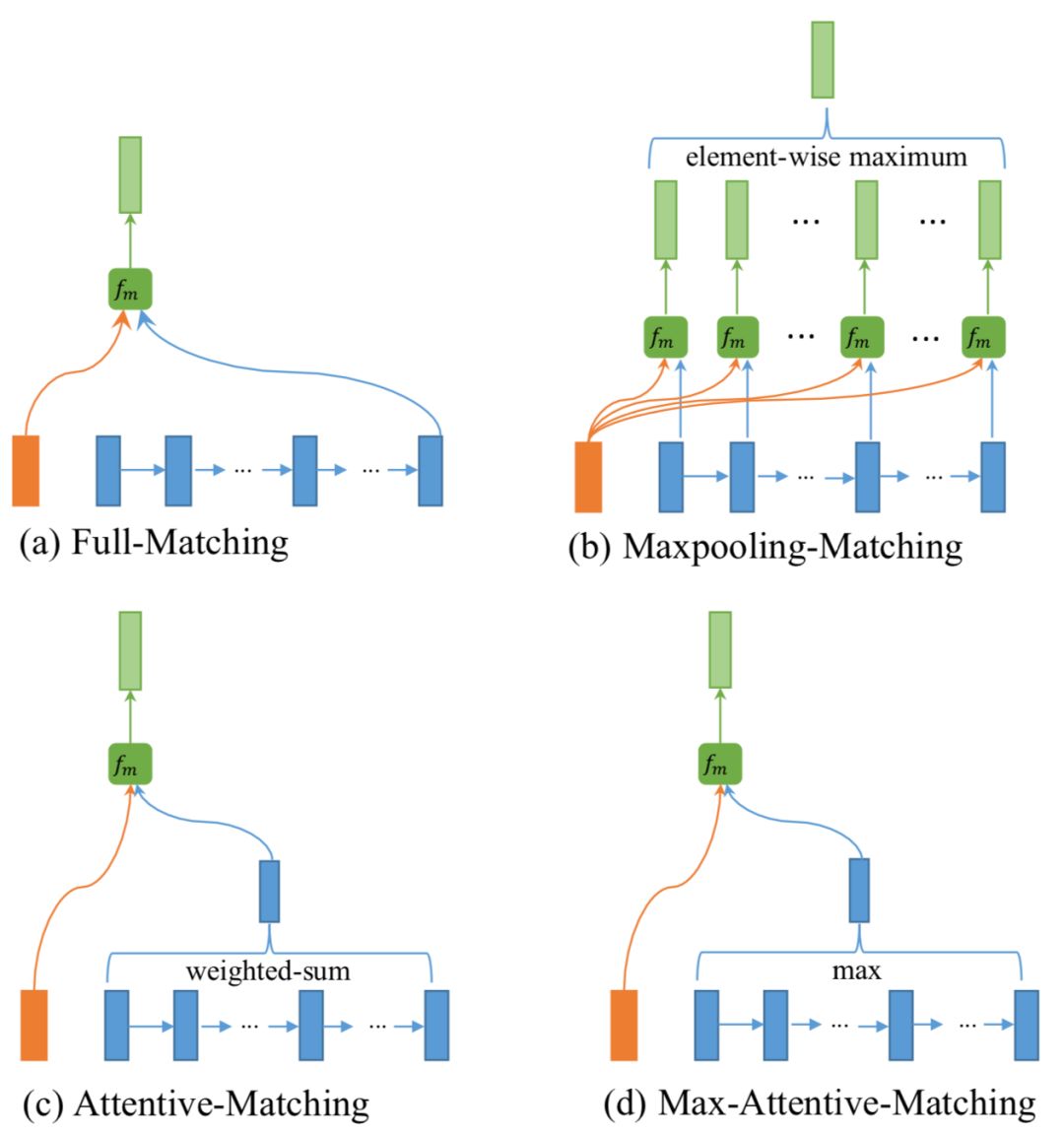
函数,在该文中给出了四种匹配策略,分别为Full-Matching,Maxpooling-Matching,Attentive-Matching,Max-Attentive-Matching,如图所示:
图4.29 BiMPM 4种不同的matching方法
以第一个句子P为例,如图a中左边的橙色条框,对于P中的每个前向单词
h
ip
( 对于后向单词则为
h
ip
),都和Q中所有N个隐层的最后一个隐层输出
h
Nq
( 对于后向则为
h
1q
) 进行匹配,通过f
m
网络拟合得到前向和后向两个维度为l的向量m
ifull
。如图a中a最右侧的蓝色条框为前向最后一个隐层的输出:
同理的,对于Q中的每个单词,也依次得到和P中前向LSTM中最后一个以及后向LSTM中第一个隐层输出的匹配向量。
总结来说,full-matching方法在计算当前匹配的时候,只用到后向LSTM隐层中的最后一个隐层以及前向LSTM隐层中的第一个隐层,中间的隐层信息并未利用。对于P和Q中的每个word都需要和对方进行两次计算,因此时间复杂度为O(2*M+2*N)。
以第一个句子P为例,对于P中的每个前向单词
h
ip
(对于后向单词则为
h
ip
),如图b中最左边的橙色条框,都和Q中所有N个隐层输出一一计算,每个向量对通过f
m
映射后可以得到N个l维度的匹配向量后,对这N个匹配向量进行element-wise 的最大值,也就是在l个维度中的每个维度,从N个向量当前这个维度选择最大值,相当于是对N个隐层的max-pooling操作,最终得到前向和后向两个维度为l的向量m
imax
。
同理,对于Q中的每个单词,也依次得到和P中的前向LSTM中M个word通过element-wise 最大池化得到的前向匹配向量,以及和P中的后向LSTM中M个word通过element-wise最大池化得到的后向匹配向量。
总结来说,max-pooling matching在计算当前匹配的时候,利用到了所有隐层的所有信息,然后对向量中每个维度,从所有的word中的最大值作为匹配分数。除了最大值的隐层信息,其他隐层信息也是没有利用到。由于是P和Q每个word两两都需要计算,时间复杂度是k*M*N,k为常数项。
以第一个句子P为例,对于P中的每个前向单词
h
ip
( 对于后向单词则为
h
ip
),依次和Q中的所有单词计算cosine余弦相似度从而得到一个M*N的相似度矩阵。以P中第i个word和Q中第j个word为例 ( 矩阵的第i行j列 ),其权重表达如下所示:
这里得到的
α
i,j
和
α
i,j
分别为
h
jq
和
h
jq
的前向和后向权重,整个句子Q的注意力向量为其权重的加权表达:
分母对权重求和是为了保证权重的归一化。最终,将P中第i个word,与句子Q的注意力向量通过f
m
函数得到前向和后向两个维度为l的匹配向量m
iatt
。
同理,对于Q中的每个单词,也依次通过计算P中各个word的权重,得到对应的P中每个词的权重后,通过P中每个词的 weight-sum可以得到P的注意力向量。最终计算Q中每个单词与P中对应的注意力向量,得到前向和后向两个维度为l的匹配向量。
总结来说,attentive-matching方法充分利用了每个隐层的输出计算权重进行weight-sum。
d.
ma
x-attentive matching
该方法和attentive-matching前面计算权重的方法一致,不一样的地方在于,attentive-matching是用weight-sum得到注意力向量,而max-attentive matching方法是用权重里最高的那个向量来得到注意力向量。
还是以第一个句子P为例,对于P中的每个前向单词
h
ip
( 对于后向单词则为
h
ip
),依次和Q中的所有单词计算cosine余弦相似度,最终得到的相似度矩阵(M*N)中,第i行j列元素表达如下:
这一步之前和attentive-matching是一致的。不同地方在于,对于i所匹配的N个权重,选择权重最大的作为注意力向量。
以上4种不同的匹配策略捕捉到的信息各自不同,在论文中为了提升模型拟合精度,在实际应用中是4种attention策略的叠加,每个策略中每个word得到一个l维的向量,最终得到4个匹配向量concat起来
对于句子P,得到一个M*4l的矩阵 ( M个time-step,每个time-step是一个4*l维度的向量 ),对于句子Q,得到一个N*4l的矩阵 ( N个time-step,每个time-step是一个4*l维度的向量 )。
④
聚合层 ( a
ggregation layer )
这一层的目的,是将两个句子P和Q匹配得到的向量,聚合成一个固定长度的匹配向量。文中依然使用了双向LSTM网络去拟合,如图2中aggregation layer中的4个绿色向量所示。从P->Q前向和双向得到两个向量,从Q->P双向和前向各自得到一个向量,最终4个向量concat起来作为下一层的输入。
⑤
预测层 ( p
rediction layer )
文中使用两层MLP后,最后softmax作为概率输出。
-
输入层embedding对比大多数的word embedding,引入了character embedding,每个word的embedding表达是预训练的embedding和字符embedding经过LSTM编码后得到的表示组合而成
-
引入了上下文表示层:用双向的LSTM来对P和Q的每个word进行编码,每个word可以得到前向和后向的两个隐层输出表示
-
多视角关系:对于给定的两个d维向量v
1
和v
2
,通过l*d的参数W通过网络f
m
进行映射,各自得到l维的向量,l类似于CNN中的filter,l的维度就代表了多视角的维度。
-
双向计算关系:所有的计算都是对称的,从P对Q的各种网络结构,一定能看到Q对P也会有,因此是个双向关系
-
多种注意力匹配关系:对于两个句子P和Q的关系,提出了4种不同的attention计算方法,分别是:
a. Full-Matching:以P->Q计算为例,对P中每个word,和Q中最后一个 ( 前向LSTM ) 和第一个 ( 后向LSTM ) 隐层的word分别通过f
m
网络计算后,得到该word对于Q的两个维度为l的前向和后向匹配向量
b. Maxpooling-Matching:以P->Q计算为例,对P中每个word,和Q中每个word经过f
m
网络映射后得到N个维度为l的前向和后向向量,对l维度的每一维选择最大 ( element-wise max-pooling ) 值,得到该word对于Q的两个维度为l的前向和后向匹配向量
c. Attentive-Matching:以P->Q计算为例,对P中每个word,和Q中的每个word计算前向和后向cosine相似度,然后计算该word对于句子Q的注意力向量后,两个向量通过f
m
网络映射计算,可以得到两个维度为l的前向和后向匹配向量
d. Max-Attentive-Matching:以P->Q计算为例,对P中每个word,和Q中的每个word计算前向和后向cosine相似度,然后用相似度中的最大值作为Q的注意力向量,这两个向量通过f
m
网络映射计算,可以得到两位维度为l的前向和后向匹配向量
-
计算复杂度高:如此复杂的网络结构,很多计算之间又是串行的,可想而知,对于大规模的文本匹配计算速度很慢
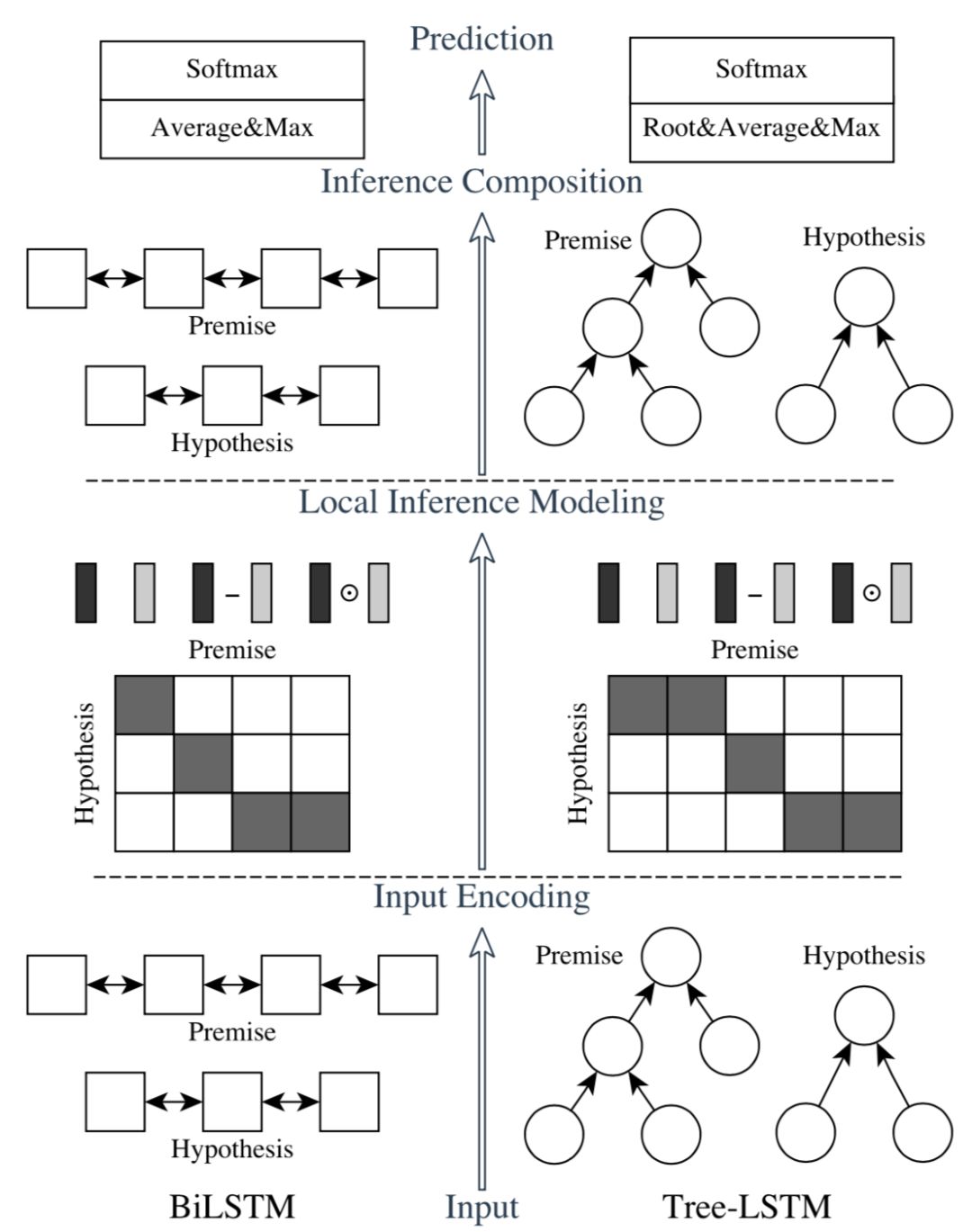
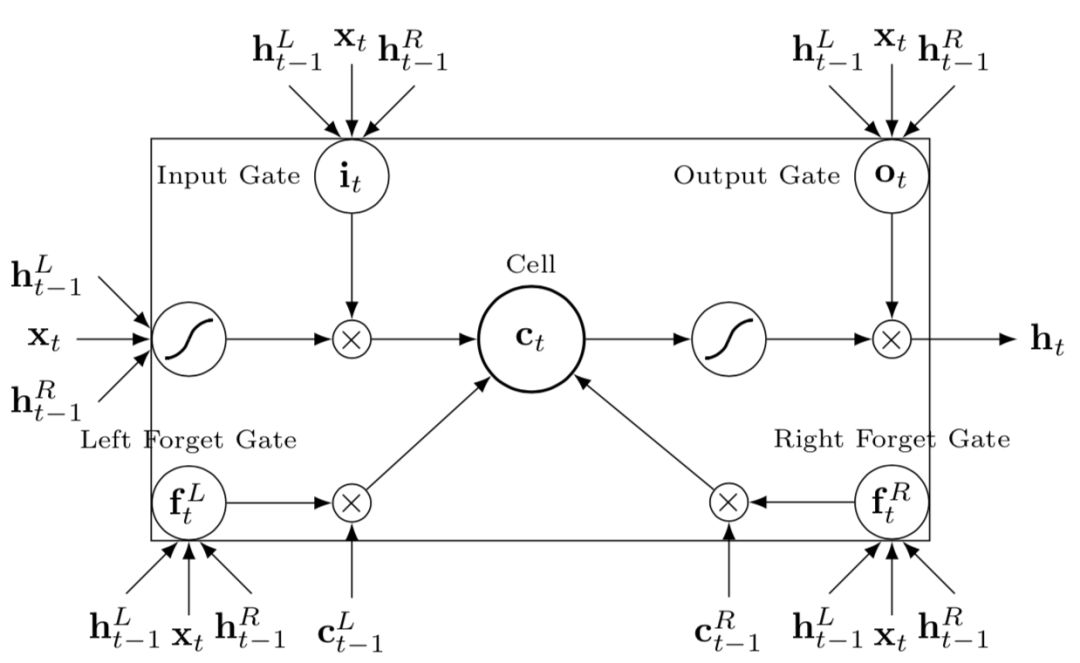
ESIM模型在众多短文本匹配比赛中大杀四方,表现十分出色。ESIM模型全称为"Enhanced Sequential Inference Model",增强序列推断模型,是加强版的LSTM。论文中解决的虽然是premise和hypothesis的关系,但是我们可以应用到query和doc或者其他两段文本关系之中。对比以往传统的LSTM模型非常复杂的网络设计,ESIM模型通过精细的序列式网络设计,以及同时考虑局部推断和全局推断的方法来达到更好的效果。整体框架如图4.30所示。
整个模型结构主要有3部分:① input encoding层;② 局部推理层;③ 推理组合层。
对于给定的两个句子a和b ( 代表前提premise和假设hypothesis ),分别由l
a
和l
b
个word组成,其中每个word为维度为l的embedding向量,一般由预训练得到:
作者使用双向LSTM作为基础模块,用
a
i
表示句子a中第i个时刻的隐藏层输出,用
b
j
表示句子b中第j个时刻的隐藏层输出,表示如下:
除了常规的Bi-LSTM之外,文中还使用了Tree-LSTM来捕捉序列关系。在每个t时刻,具体结构如下:
-
当前输入除了x
t
,还有前一时刻的隐层输入h
t-1
的左右叶子结点h
t-1L
以及h
t-1R
。
-
输入门input gate 以及输出门output gate依然只有一个,两个门的输入都包括当前输入x
t
、前一时刻隐层h
t-1
的两个叶子结点h
t-1L
和h
t-1R
。
-
遗忘门forget gate:和传统的LSTM不同,有两个,分别是left forget gate和right forget gate,输入和前面两个门一样,分别是当前输入x
t
、前一时h
t-1L
和h
t-1R
。
-
细胞状态:输入来自前一时刻细胞状态左右两个节点c
t-1L
和c
t-1R
,而左右两个遗忘门forget gate分别控制需要左右两个细胞状态需要保留的信息
。
其中W
f
,W
i
,W
c
,W
o
是一个d*l的待训练参数;U是d*d的待训练参数矩阵。这样,原始的两个句子输入通过word embedding之后,通过左边一个BiLSTM,右边一个tree-LSTM编码之后输入到下一层网络
②
局部推理层local
inference modeling
在很多相关性模型中,都使用硬对齐或者软对齐的方式来建立query和doc的关系。在前面4.2.2中的DecAtt模型中就是用attention机制来建立soft-align软对齐。而在ESIM模型中,作者延续使用了DecAtt的软对齐方式,对于给定的query句 a,以及doc句b,建立两个句子之间每个word两两的向量点积作为相似度:
在原始的DecAtt模型中,作者使用的是例如MLP来计算F(a
i
) 以及F(b
j
)进而计算相似度;而在ESIM模型中,使用的是LSTM和tree-LSTM得到两个句子的表示后再计算相似度矩阵。得到e
ij
后,query中第i个word的表示为doc中每个单词的weight-sum;也就是说
a
i
表示b中每个词与
a
i
的相关程度。同理,假设句子b中第j个word的表示为句子a中每个单词的weight-sum表示,
b
j
表示a中每个词与
b
j
的相关程度。
得到局部推断后,为了增强信息,分别使用了向量相减、向量点积、最终4个向量concat起来,m
a
和m
b
分别表示增强后的premise和hypothesis。
通过前一层局部推理建模之后得到的向量m
a
和m
b
进入当前的推理组合之后,作者依然使用了Bi-LSTM和Tree-LSTM来捕捉两者关系。对于Bi-LSTM,公式和第一层input encoding的一致,而对于Tree-LSTM来说,表示如下:
这里使用了函数F来控制模型复杂度,F函数在文章中作者使用了一层的前向神经网络并且经过RELU激活输出。
通过前面的composition layer两个LSTM网络编码得到的向量是变长的,query句子a得到一个长度为l
a
的向量,doc句子b得到一个长度为l
b
的向量,在这层pooling层目的是为了得到一个固定长度的向量。
为了最大程度捕捉信息,论文中同时使用了average pooling和max pooling,并将两种pooling得到的向量concat起来,在实验中证明比单纯的sum pooling效果要好,公式如下:
注意到上述最后一个公式,其实论文作者也用到了在Tree-LSTM中根节点的隐层状态一起concat起来,只是在上述公式中没有体现。
最终得到的向量v再经过全连接网络后,最后接一个softmax输出,训练过程使用多分类的cross-entropy损失函数。
-
引入了Tree-LSTM,是加强版的LSTM。输入门和输出门都只有一个,输入包括当前输入,以及前一时刻隐层的左右叶子结点;遗忘门有左右两个,每个遗忘门的输入都包括当前输入以及前一时刻隐层的左右叶子结点;细胞状态有一个,输入为前一时刻的左右两个细胞状态
-
局部推理层中对于匹配矩阵的做法区别于DecAtt模型使用MLP去提取query和doc两个句子的做法;而是用两种LSTM提取编码后计算加权向量表达。得到加权向量表达后,和原始向量进行乘积和相减后,总共4个向量concat起来,相当于是丰富了提取到的信息,作为下一层的输入
DIIN模型是在ICLR2018上提出的要用于自然语言推理任务的模型,解决的是premise和hypothesis的关系,同理我们可以应用到query和doc或者其他两段文本关系之中。作者在这篇论文中引入了一种新的网络-交互推理网络 ( interactive inference network,IIN ),而通过用attention更密集的交互矩阵可以得到更丰富的语义信息,因此该模型名称为密集交互推理网络 ( Densely Interactive Inference Network,简称DIIN )。
模型可以分为5个部分,分别是嵌入层、编码层、交互层、特征抽取层以及输出层,整个网络如图4.32所示:
在embedding层中,论文中同时将单词级别embedding、字符级别特征的embedding以及句法级别的特征embedding信息concat起来作为每个词的embedding。
使用的是glove预训练得到词向量进行初始化,并在模型训练过程中允许更新。
引入character embedding的目的,是为了解决未登录词无法得到word embedding的时候,字符级别的embedding能够提供一些额外的信息。这里的方法是先经过1维的卷积核进行卷积之后,再通过Max pooling得到character embedding。其中卷积核对与P和H是共享的。
c. 语法特征syntactical feature
对于语法的特征,包含了两个方面的信息,一个是词性特征 ( POS ),另一个是二进制精确匹配特征 ( EM )。
通过上述4种embedding ( 语法特征有pos和em两种embedding ),最终的维度:
d=dword+dchar+dpos+dem,对于query和doc来说维度一致。
最终,query的表示P是一个维度为p*d的矩阵 ( p为query的单词个数 );而doc的表示H是一个维度为h*d的矩阵 ( h为doc的单词个数 ),d为隐层的维度。
编码层的主要作用是将第一层embedding layer得到的特征进行融合编码得到新特征。对于前面得到的P和H,经过两层的highway network后,得到
P
和
H
。
为了进一步提取信息,论文中使用self-attention机制,同时利用词序和上下文信息进行编码。以query句子P的第i个term为例,得到的加权向量表达
P
i
如下:
其中第一个公式A
ij
个人觉得原文应该有误,括号应该包含
P
j
,求的是
P
i
和
P
j
两者的关系,论文中使用如下公式表达:通过将两个向量以及向量的点积三个向量concat后,变成一个维度为3d的向量,并通过一个简单的线性变化得到两个向量的匹配分数,也即attention分数,表示如下:
其中w
a
是一个3d的参数向量,通过训练得到。而上述第二个公式得到的是P中第i个term的加权表达,分母做了归一化。同理,我们也可以得到关于doc句子H的加权表达。
这样,P中第i个term的原始向量
P
i
,以及经过self-attention的注意力向量
P
i
,两个向量一起concat起来,作为fuse gate的输入。这里fuse gate作用类似于dense net:
其中W
1
,W
2
,W
3
位一个2d*d的参数矩阵,b
1
,b
2
,b
3
都是d维的参数向量,W和b都通过训练得到。
同理的方法可以得到doc句子的表示。不过论文认为P和H的fuse gate权重是不共享的,目的是为了学习到P和H语法信息中的不同点。
本层对于前一层得到的两个向量中每个term,两两求匹配分数:
这里beta函数学习的是两个向量的交互匹配分数,可以有多种表达,如cosine,点积,MLP网络等,论文中用的是简单的向量点积:
④
特征抽取层
feature extraction layer
本层在论文中没有太详尽到公式的介绍,大体意思是对于前一层得到的交互矩阵I,利用resnet进行特征提取,个人感觉也不是太关键,实际在使用中该层可以考虑不用。
输出层使用简单的一个线性层以及softmax多分类进行分类。
-
嵌入层对embedding的处理较为精细,除了预训练的word embedding,还包括字符级别的embedding,以及语法层面的词性特征 ( POS ) 和二进制精确匹配特征 ( EM )
-
编码层先是用high way网络分别提取query和doc中每个word的向量后,再通过self-attention,提取每个word的加权向量,然后两个向量通过resnet的思路,引入fuse gate,分别提取原始向量的一部分,以及加权向量的一部分作为最终每个word的表达
-
前两层都还只是query和doc各自的信息表示,特征交互层通过query中每个word和doc中每个word的向量点积得到交互矩阵,然后通过特征提取层的dense net进行特征提取,最终通过输出层的线性网络并利用softmax输出概率
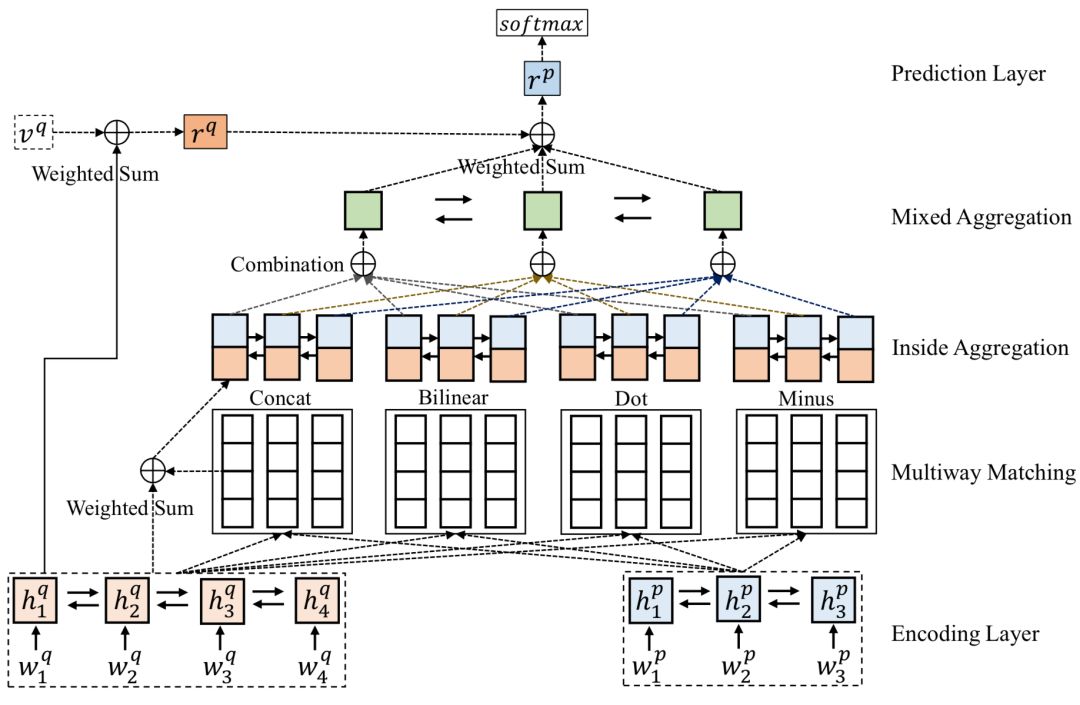
2018年IJCAI提出了的Multiway Attention Network,简称MwAN模型,模型利用多种attention方式进行融合,整体框架如图4.33所示:
从图可以看出,整个模型分为:① encoding layer;② multiway matching;③ inside aggregation;④ mixed aggregation;⑤ prediction layer
给定两个句子Q和P,分别由N个term和M个term组成,首先通过预训练得到的embedding得到Q和P各自的word embedding表示。接着,使用双向的GRU模型,得到Q和P的各个时刻隐层输出:
上一层编码层得到Q和P的GRU隐层输出后,需要进行信号的匹配,整个表示如下所示:
其中h
tp
表示P中第t个word的表示,h
q
表示Q的所有M个word的表示,f
k
为使用的匹配网络结构,q
tk
为最终得到的P中第t个word与Q匹配后分数。
对于f
k
的设计,在该论文中作者提出了4种不同的方法,因此该层称为multiway matching,分别为concat, bilinear, dot和minus,每种计算attention的公式整体范式如下:第一步,P中第i个word与Q中的每个word,以第j个为例,两个向量,挨个计算原始的权重,这里两个向量的交互分为concat、bilinear、doc和minus,得到第j个word的原始权重s
jt
;第二步,对于Q中的所有N个word进行归一化,得到每个word的归一化权重;第三步,通过前一步得到的Q的每个word的归一化权重,乘以该word本身的向量表示,得到最终P中第i个word的加权向量表达。
通过concat的方式,将h
jq
经过W
c1
矩阵映射后的向量,以及h
tp
经过W
c2
矩阵映射后的向量concat一起。为了保证非线性进行tanh非线性变化后,再通过v
c
向量进行映射得到原始权重s
jt
,最终得到P
i
关于Q的归一化加权向量表达q
tc
。这里待学习参数为W
c1
, W
c2
和v
c
。
通过一个W
b
矩阵,对两个向量h
jq
和h
tp
进行双线性变化得到原始权重s
jt
,最终得到P
i
关于Q的归一化加权向量表达q
tb
。这里待学习参数为W
b
。
通过两个向量 h
jq
和 h
tp
的点积 ( 哈达码积 ),维度和原始维度保持一致,然后通过非线性变化tanh映射后,再经过v
d
的线性变化后得到原始权重s
jt
,最终得到P
i
关于Q的归一化加权向量表达q
td
。
通过两个向量h
jq
和h
tp
的向量相减,维度和原始维度保持一致,然后通过非线性变化tanh映射后,再经过v
m
的线性变化后得到原始权重s
jt
,最终得到P
i
关于Q的归一化加权向量表达q
tm
。
在aggregation层分为两层,第一层是对于前面matching layer讲到的4种不同的attention方法,求各自内部的aggregation,因此称为inside aggregation。还是以P中第t个word为例,输入是将P中第t个word本身的表达 ( 双向GRU的输出 ) h
tp
,以及前一层matching layer得到的关于Q的加权向量表达,以concat attention的输出q
tc
为例 ( bilinear、dot和minus分别为q
tb
, q
td
, q
tm
),两个向量concat起来得到x
tc
。
第二个公式为了得到x
tc
的重要性,通过W
g
的映射再经过非线性sigmoid输出其重要性,相当于是gate的作用,然后通过第三个公式得到重要性表达的x
tc*
。接着通过一个双向GRU得到前向和后向的表达:
最终,对于P的第t个word,以concat attention为例,可以得到其输出为:
同理,当用bilinear、doc和minus attention,分别可以得到h
tb
,h
td
,h
tm
。
将上述4种不同的attention计算得到的输出h
tc
,h
tb
,h
td
,h
tm
在这一层融合,称为mixed aggregation。首先通过两个矩阵W
1
进行映射,下述公式第一个式子的v
a
可以认为是bias。第二和第三个式子通过计算4种attention各自的归一化权重,得到4种不同attention的加权向量表达如下:
注意这里的attention针对的是上述concat、bilinear、dot和minus4种不同计算方式的。然后继续通过一个双向GRU进行拟合,得到每个时刻t在在前向和后向GRU隐层时刻的输出:
接着将前向和后向的输出进行concat得到P中t时刻的隐层输出h
to
:
这一层的目的,是为了将原始的不定长P转换成定长的向量。论文中首先得到关于Q的归一化加权向量表达:
注意这里的attention pooling针对的是Q中的N个word。利用得到的r
q
向量可以得到P向量的最终表达:
注意这里的attention pooling针对的是P中的M个word。最终,将r
p
后面介入一个MLP全连接网络后得到输出概率p
i
,通过cross entropy损失函数进行求解。
-
第一层的编码层通过双向GRU,对query和doc中的每个word进行编码,每个word可以得到前向和后向GRU中每个隐层的输出表示
-
第二层的Multiway Matching是MwAN模型的核心所在,对于query中每个word,和doc中的每个word都进行不同attention计算,分别有concat、bilinear、minus以及dot product,然后进行attention归一化,可以得到query中每个word关于doc的注意力向量;同理也可以得到doc中每个word关于query的注意力向量
-
第三层的inside aggregation是对于query和doc在第二步得到的4种注意力向量,每种attention向量,与各自在第一步得到的原始向量表示进行内部融合,最终得到4种attention的向量表示
-
第四层的mixed aggregation对第三层得到的4种不同的attention向量进行融合,通过线性变化,tanh非线性映射,以及归一化加权后,再通过双向GRU,得到前向和后向的两个融合向量
-
第五层将前面得到的不定长向量进行pooling操作变成定长的向量输出最终概率
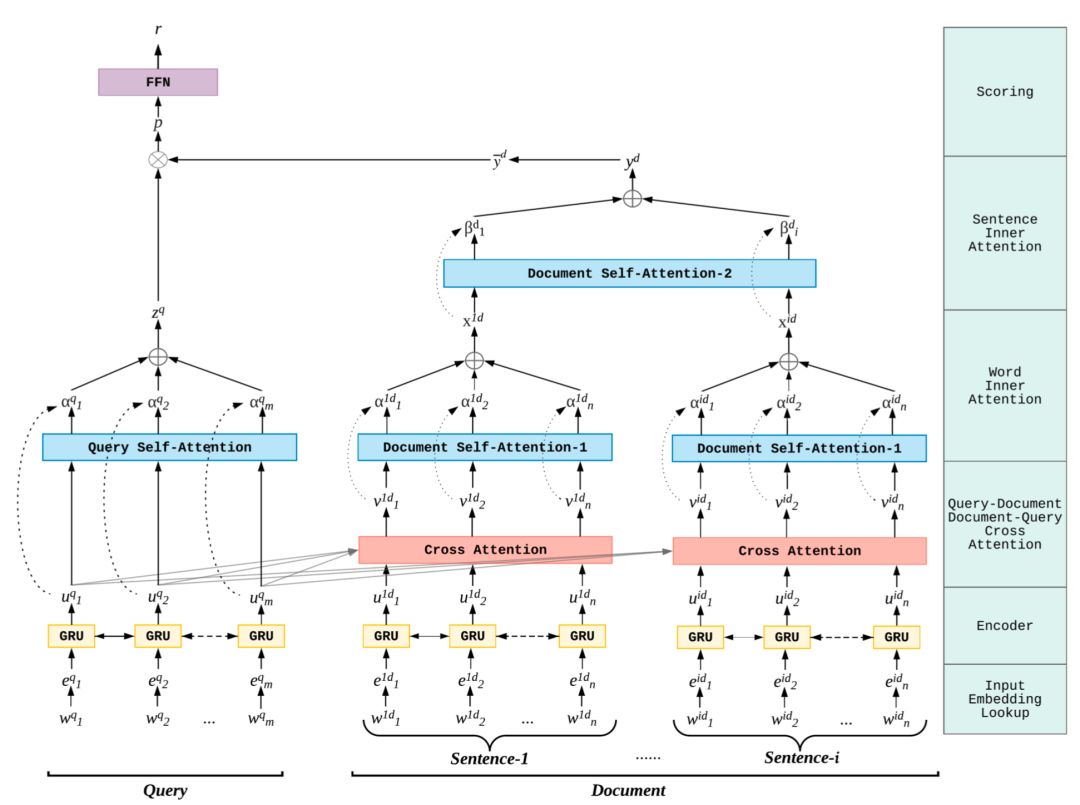
WWW2019提出的层次注意力检索模型 ( Hierarchical Attention Retrieval ),简称HAR模型。在搜索和信息检索中,一般query和doc是不等长的,作者将query看成多个word组成,而doc由多个句子组成,每个句子又有多个word。论文中因此在query内部的word之间的attention、doc内部每个句子中每个word之间的attention、doc内部句子和句子之间的attention、以及query和doc之间的attention,由此构建了许多不同层次的attention交互,因此是层次注意力的检索模型,整体模型框架如图4.34所示:
HAR模型按照结构可以分为5层:① word embedding层:② encoder层;③ query-doc交叉attention层;④ query内部attention层;⑤ doc内部不同sentence的attention层;⑥ 输出层。
输入层的作用是将query和doc中的每个word都映射成embedding。对于query由m个word组成,表示如下左;doc由l个句子表示,每个句子由n个word组成,表示如下右公式 :
encoder编码层作用是将第一层输入层通过该层进行信息的编码,文中使用的是双向RNN ( bi-RNN ) 进行信息提取,对比原始RNN,GRU能解决长依赖导致的梯度下降,而一般来说doc都是一些短句子不需要用到LSTM,因此论文中用的是双向GRU。
第t个时刻 ( query中第t个word ) 的隐层输出u
tq
由上一时刻隐层输出u
qt-1
和当前输入e
tq
表示,可以得到一个m*H的向量,H为隐层的维度:
对于doc一般来说都比query长,由多个句子组成,所以论文中使用了句子层级的双向bi-GRU encoder进行表示。对于doc中给定的一个句子i,将该句子的word embedding作为输入,可以得到该句子一个n*H的向量,H为隐层的维度:
③
qu
ery
和
doc
的交叉
attention
层
通过前面query和doc的encoder编码提取信息后,交互层这里需要做query和doc的交互信息提取。由于query和doc各自信息不同,论文中分别使用了query到doc的交互信息Q2D,以及doc到query的交互信息D2Q。
首先计算query和doc的相似度矩阵S,维度为n*m。对于给定的doc中第i个句子,query输入U
q
,则S矩阵中第x行 ( 第i个句子中第x个word ),第y列 ( query中第y个word ) 的表示如下:
对S矩阵的每一行进行softmax,以第x行为例,相当于求doc中第i个句子每个word对于当前query第x个word的权重,可以得到D2Q的相似度矩阵。同理,对S矩阵的每一列进行softmax,以第y列为例,相当于求query中每个word对于doc中第i个句子中第y个word的权重,可以得到Q2D的相似度矩阵:
最终doc->query以及query->doc的表达为其相似度矩阵的加权向量表示:
通过cross attention之后,doc中的每个句子得到的是一个n*4H的矩阵V
id
,其中n为每个句子的word个数,4H为每个word的embedding维度。
为了将不等长的query维度映射到固定维度,论文中使用了的self-attention机制,通过计算query中m个word中每个word不同的权重进行加权求和,表达如下:
其中第一个公式中,c
tq
为第t个word的原始注意力权重,第二个公式中a
tq
通过softmax得到归一化后的注意力权重,第三个公式对m个word的向量进行加权求和,得到最终query的向量表达,维度为H。
doc中有l个句子,因此doc的attention设计分为两部分,分别是每个句子内部各个word级别的attention,以及每个句子级别的attention。
对于③中得到的cross attention,doc中每个word的维度变成了4H。对于word之间的attention,和query的公式一致,以第i个sentence为例:
最后一个公式x
id
为第i个sentence中n个term的加权注意力向量,维度为4H。
b.
sen
tence
层级的
attention
直观理解,doc中的l个句子中,每个句子对doc的最终共享应该是不同的,因此文中引入了第二层的attention,句子级别的attention,表达如下:
其中最后一个句子得到的是doc中l个句子的加权表达,维度为4H。
通过4和5得到的query和doc各自的输出向量维度分别为H和4H,维度不同,因此文中先经过一层的神经网络对doc进行降维到H后,再通过query和doc的向量点积得到其匹配分数,最终再通过一层的神经网络得到最终的恶匹配分数:
-
输入层和编码层用双向GRU提取query以及doc中每个word的隐层编码
-
query内部的attention比较简单,对自身m个word使用self-attention,得到每个word的归一化权重后,对m个word进行加权得到加权注意力向量,维度为H
-
把doc看成是多个句子组成,在得到doc的attention之前,先计算query和doc的匹配。分别计算query->doc的矩阵以及doc->query的矩阵,然后doc的每个句子由本身的向量, D2Q的向量,本身向量和D2Q以及Q2D分别乘积后,这4个向量concat起来作为doc中每个句子的表达,维度为4H
-
有了前一步doc中每个句子的表达后,doc内部的attention分成两种,一种是句子内部每个word的self-attention,这一步和query的计算是一致的,可以得到每个句子的表达;另一种是每个句子的self-attention,把每个sentence看成前一种的每个word,计算方式是一致的,最终可以得到维度为4H的doc的表达
-
在输出层通过一层先行网络对doc进行降维到H后,和query进行哈达码积后再通过一层神经网络输出最终的匹配分数
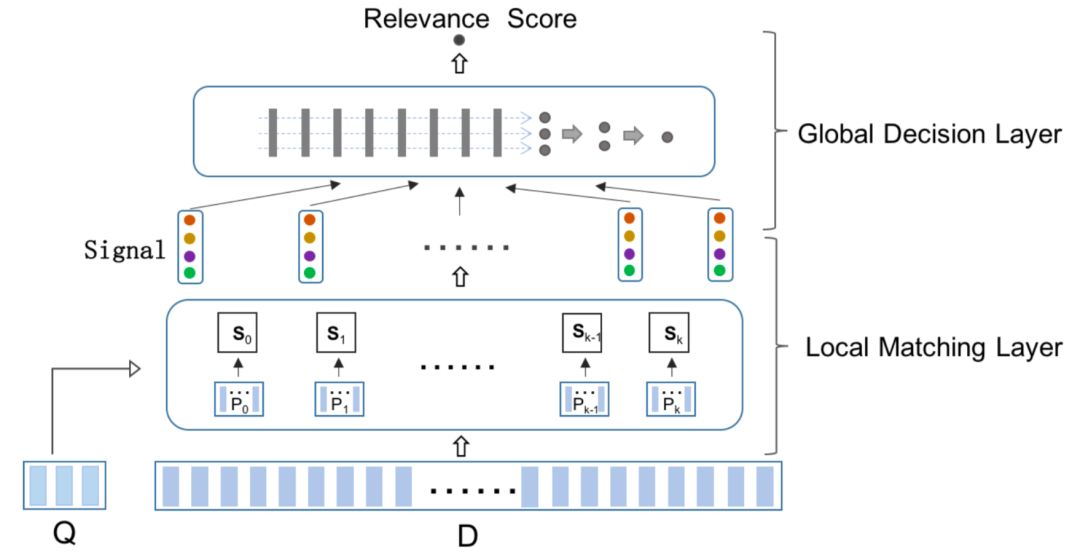
2018SIGIR上中科院提出的HINT模型,全称Hierarchical Neural maTching model,和HAR模型大体思路一致,把doc看成多个段落 ( passage ) 组成,每个段落又有多个word组成,因此在word和word之间,passage之间,passage之间的word的attention又构成了多层次的关系,因此成为多层次的神经网络匹配模型,整体框架如图4.35所示:
整个模型结构核心可以分为两层,局部匹配层以及全局决策层。
①
局部匹配层loca
l matching layer
对于给定的query和doc,doc可以看成由K个段落 ( passage ) 组成的,每个段落用P
i
进行表示:
因此,给定query Q,doc中每个段落和query的匹配分数用函数f来拟合:
核心问题在于如何表示P
i
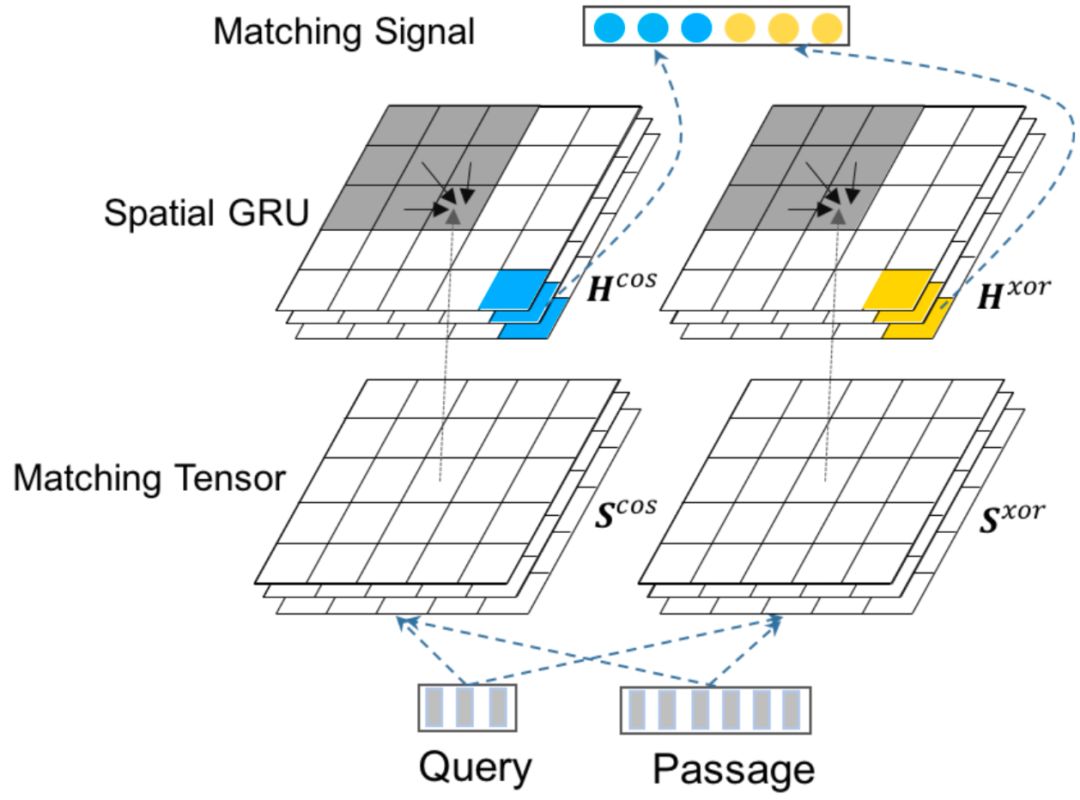
,以及匹配函数f该如何设计。对于第二个问题匹配函数f的设计可以有多种选择,比如基于统计的,或者基于神经网络的等。为了尽可能表示语法匹配以及term的重要性,论文中作者选择了固定窗口来表示doc中的段落,并且采用空间GRU模型来拟合query和doc的匹配关系,如图4.36所示:
图4.36 spatial-GRU对query和passage的捕捉
对于给定的query和doc,query由M个term组成,doc由N个term组成:
其中,doc由多个passage组成,而每个passage也被分成了固定窗口大小为L的表示:
对于给定的query和doc中给定的每个passage,将其表示为term vector,为了得到query和passage的相似度矩阵,文章提出了两种计算方法,分别是cosine以及xor方法,可以发现其实和4.1.2提到的MatchPyramid模型里的匹配方法是一致的。
第一种方法cosine相似度,对于query中第i个term,passage中第j个term计算其cosine相似度如下:
第二种方法精确匹配,相当于是个indicator,对于query中第i个term和passage中第j个term,只有两者完全相同,也就是精确匹配才等于1,表达如下:
因此,query和passage可以学习得到cos以及xor两个相似度矩阵,在论文中称为matching tensor,如图所示。为了学习得到term重要性,作者把原始query和passage中对应的term表达也加了进来,concat到一起如下:
这里的x
i
和y
j
是query中原始的第i个term向量w
iQ
,以及passage中第j个term向量w
j(P)
经过一个转换矩阵W
s
转换得到,其中W
s
通过训练得到:
注意到这里x
i
和y
j
是共享W
s
的。因此,对于k个passage,和query构成了k个pair对,分别可以得到k个sxor的匹配tensor以及k个scos的匹配tensor。
从前面学习得到的匹配tensor:scos和sxor后,论文使用了spatial GRU,也就是2维的GRU来拟合学习query和passage的关系,可以发现和4.1.3里的Match-SRNN模型是一致的:
其中,第(i,j)个隐层状态,分别由左、上、左上三个隐层状态(i-1,j)、(i,j-1)、(i-1,j-1),以及当前匹配分数S
ij
组成。最后一个隐层的状态H
M,L
作为匹配层的输出。cos和xor两个匹配向量concat后,以及两个方向的GRU concat一起作为最终的输出:
② 全局决策层
global decision layer
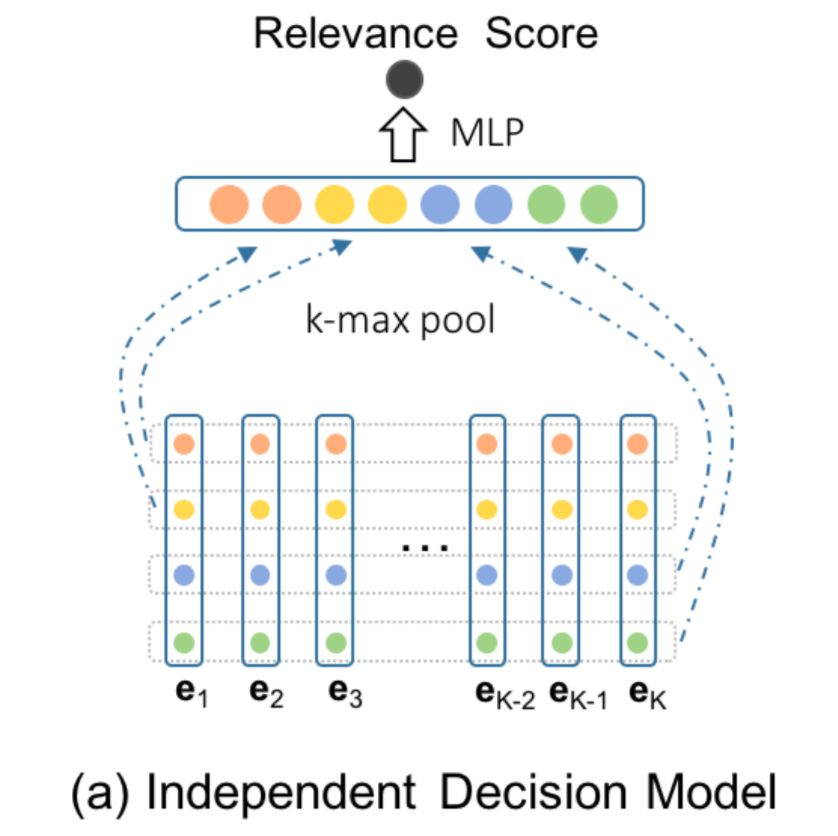
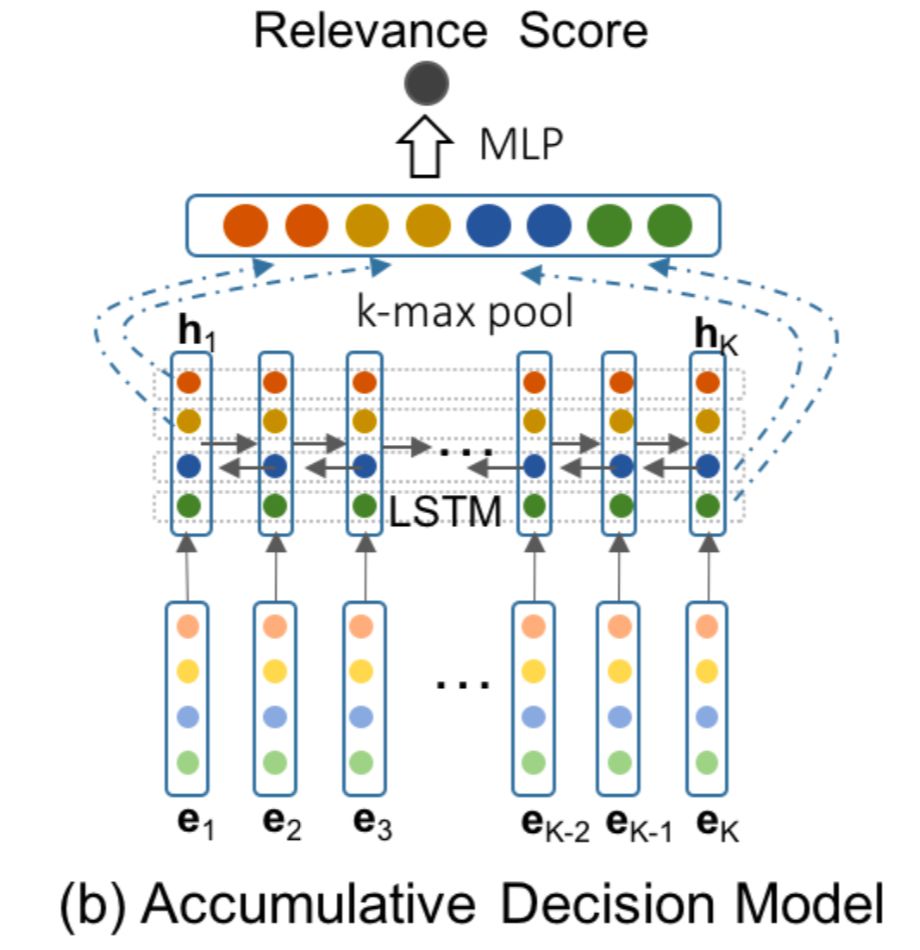
从局部匹配层得到的向量后经过全局决策层进一步捕捉交互信息。论文中提出了3种不同的模型,分别是独立决策 ( ID ) 模型、累积决策 ( AD ) 模型、以及决策和累积模型联合的模型。
a.
独立决策模型 ( In
dependent Decision Model )
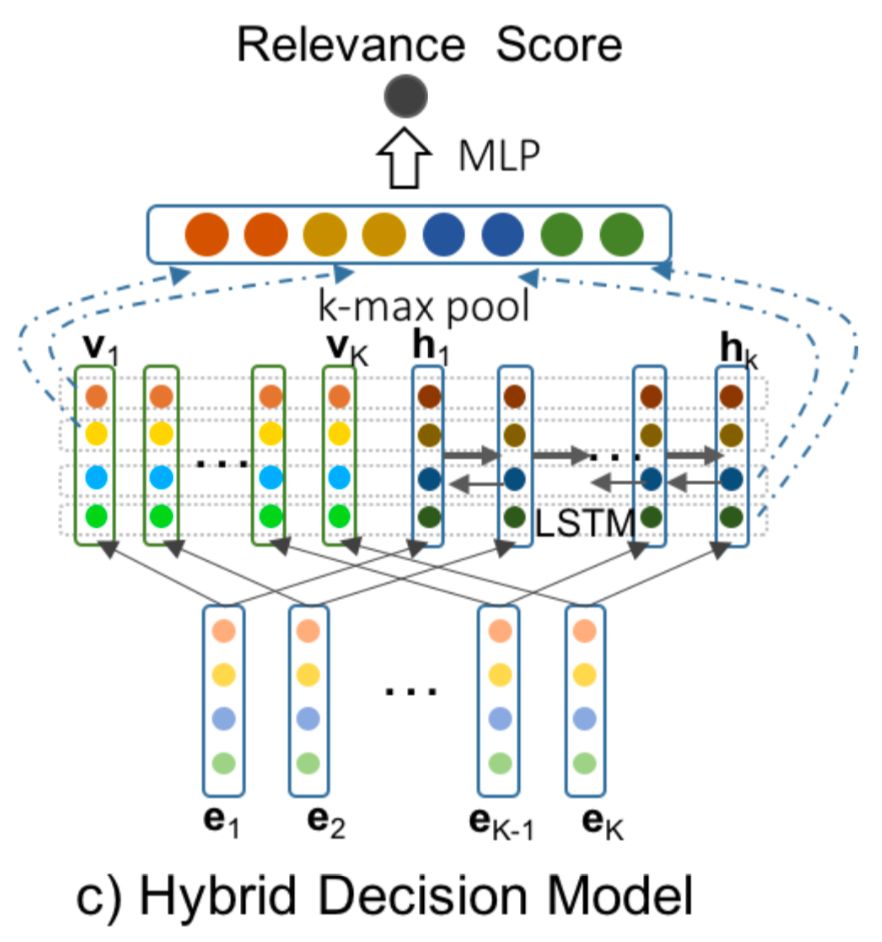
从最终的k个embedding向量中,用k-max pooling的方式,对于K个向量的每个维度,从中选择最大的k个值。以图3为例,隐层维度d=4,k=2,从隐层4个维度中,各选择最大的2个值,如橙色、黄色、蓝色、绿色各2个,然后concat到一起作为下一层的输入,如图4.37所示。
b.
累积决策模型 (
A
cc
umulative Decision Model )
和ID model最大的不同,是在k-max pooling之前,引入了序列模型来捕捉K个输入的embedding向量的关系,论文使用了双向LSTM来拟合这种关系,如图4.38所示。
c.
混合决策模型
Hybrid Decision Model
HD模型同时使用了a和b中提到的模型,AD是直接提取K个math tensor向量e
K
的k-max pooling,CD是在e
K
后接了双向LSTM后提取k-max pooling,在混合使用时,由于后者经过了LSTM映射,为了保证公平,在原始的e
K
向量后也通过一个非线性映射tanh得到v
t
。最终从非线性映射的v
1
, v
2
, v
3
,…,v
K
向量,以及LSTM之后的隐层输出h
1
,h
2
,…,h
K
通过k-max pooling提取得到固定维度的向量,再通过MLP映射得到匹配分数。
-
query看成M个word组成,doc看成K个passage ( 可以理解成句子 ) 组成,每个passage又由L个word组成。
-
-
在局部匹配层中,对query以及doc中的K个passage两两进行计算,可以得到K个m*L个矩阵,作者分别用了xor和cosine两种计算方法,分别代表精确匹配,以及一般的匹配。然后作者使用spatial-GRU对这2K个匹配度矩阵,GRU的最后一层输出作为局部匹配层最终的输出匹配信号
-
全局决策层对于局部匹配层,提出了3种模型,AD模型的k-max pooling、ID模型接入了LSTM后的k-max pooling,以及HD模型同时混合了AD和ID模型。
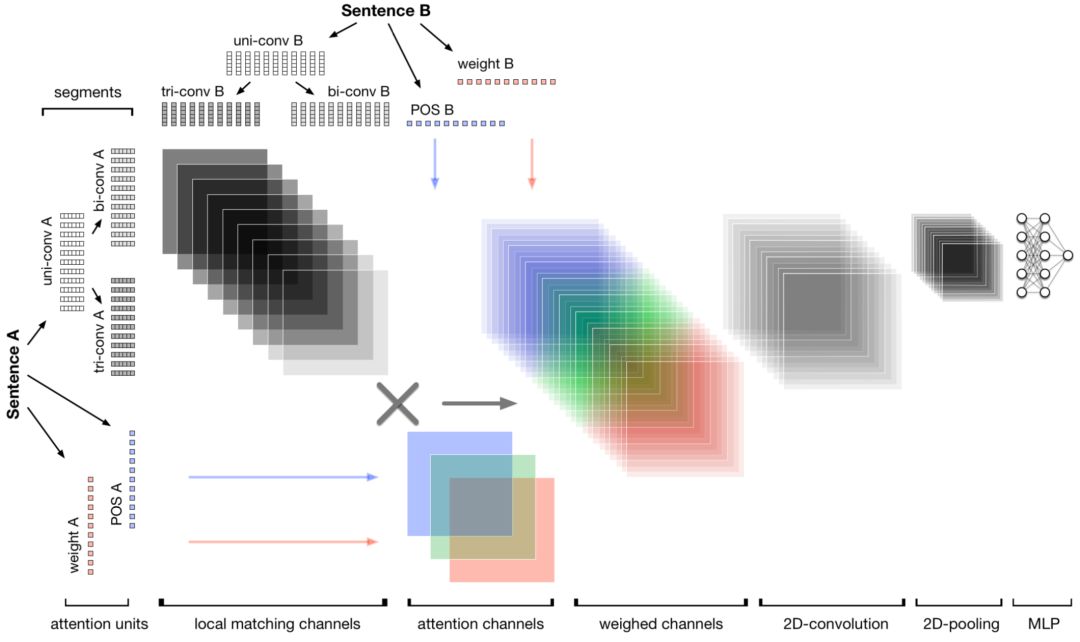
KDD2018上腾讯MIG提出了一种混合通道的文本匹配方法,Multichannel Information Crossing, 简称MIX,对于两个句子之间的全局匹配,以及句子中语素级别的局部匹配,论文分别进行精确的信息提取和融合来提升整体的匹配,整体框架如图4.40所示:
整个模型框架可以分为3部分:局部匹配、局部和全局匹配,以及匹配信息的融合
在大多数文本匹配工作中,对于两段文本的匹配,大多数都是先基于文本的term做word embedding,然后在word embedding的基础上,比较两段文本不同word之间embedding的相似度。文中指出这种方法通常来说只是语法层面的表示,无法表示更高层级的匹配。
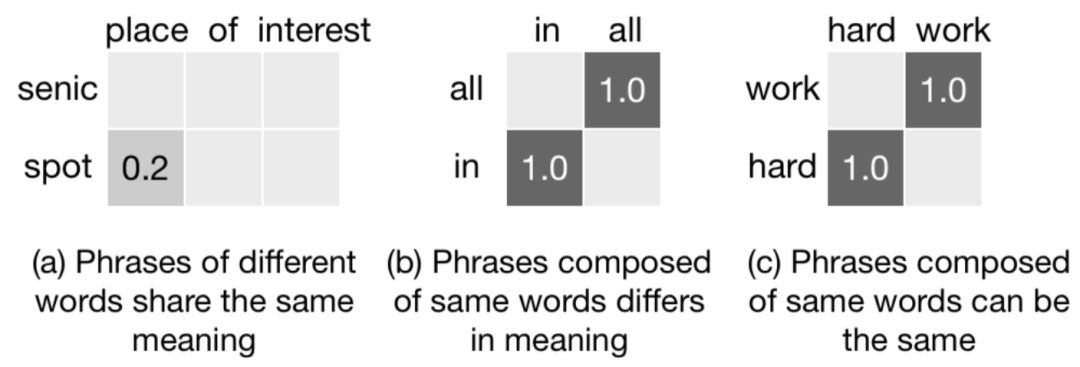
图4.41 word embedding的匹配度矩阵case
以图4.41为例,对于"place of interest"以及"senic spot"语法上是很相近的,但是如果从word embedding的相似度矩阵来看,两者匹配度却非常低。"all in"和"in all"字面上虽然包含的词相同,但意思完全不同,如果简单计算相似度矩阵如图4.41中b所示。另外一个例子hard work和work hard语义也是同个意思,但是相似度矩阵也不同。
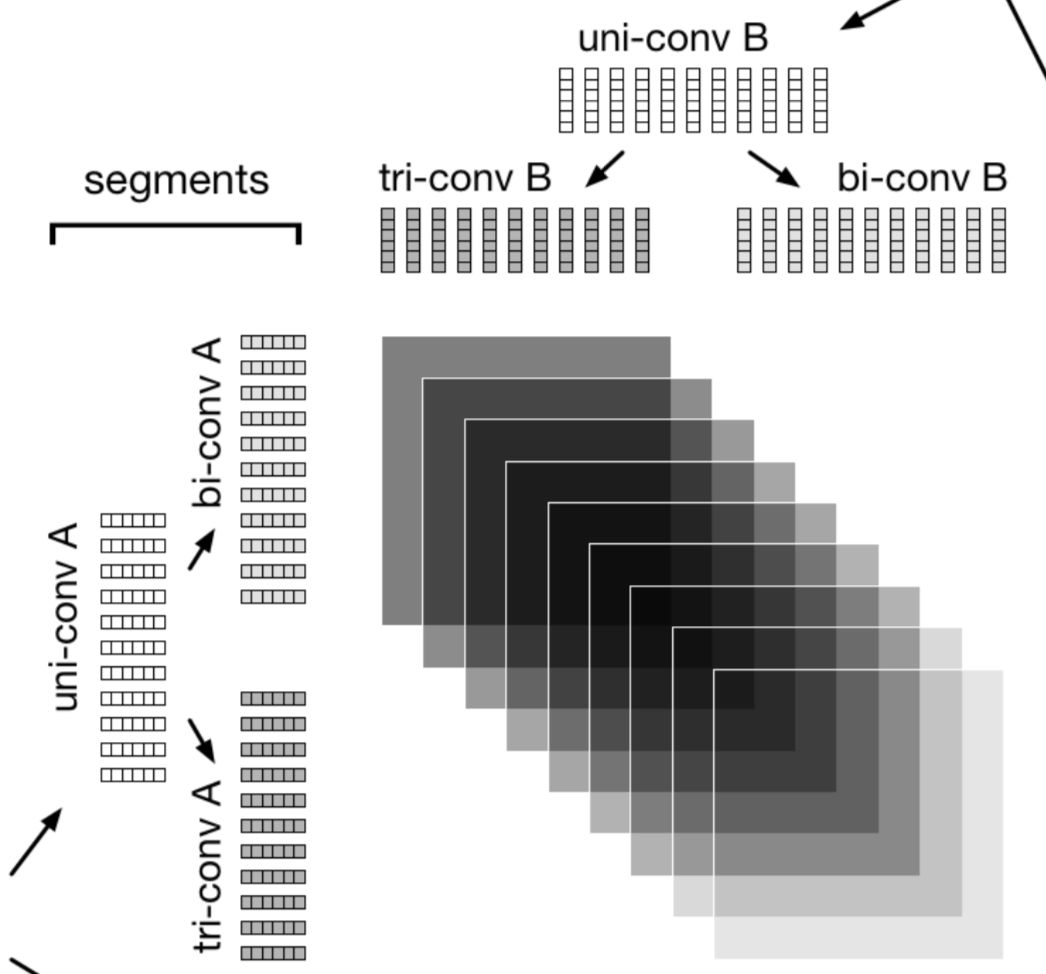
以上3个例子如果在原始的word embedding匹配阶段就存在着这种鸿沟,后续再复杂的MLP网络也是无法拟合好两者的匹配关系的。因此,作者提出了将句子解析成不同粒度的文本片度,如一元分词、二元分词、三元分词等,通过这种方法来找到文本中最适合表达语义的语义表征。如图4.42所示,两段文本a和b分别切分成uni-convA、bi-convA、tri-convA;以及uni-convB、bi-convB、tri-convB。
图4.42 文本A和B分别通过一元、二元和三元进行语义表示
在英文中,一般最小语法结构包含1-3个单词,因此MIX模型使用了1维到3维不同的卷积来提取短语信息,如图4.43所示:
对于两段文本text1和text2,分别使用卷积窗口大小为m和n的卷积核。图4.43显示了使用2维的bigrams和3维的trigrams,灰色部分表示组成一个短语的概率更高。
其中z
i(0)
表示在embedding layer中第i个位置的unigram信息,z
i(1)
表示位置i的卷积输出,其中m表示卷积核的滑动窗口大小。
全局匹配需要依赖于局部匹配,而不同局部匹配对最终结果的影响不同,因此全局匹配在局部匹配的基础上增加不同维度的attention机制。论文分别在term weight、词性以及词位置3个不同维度进行attention权重提取。
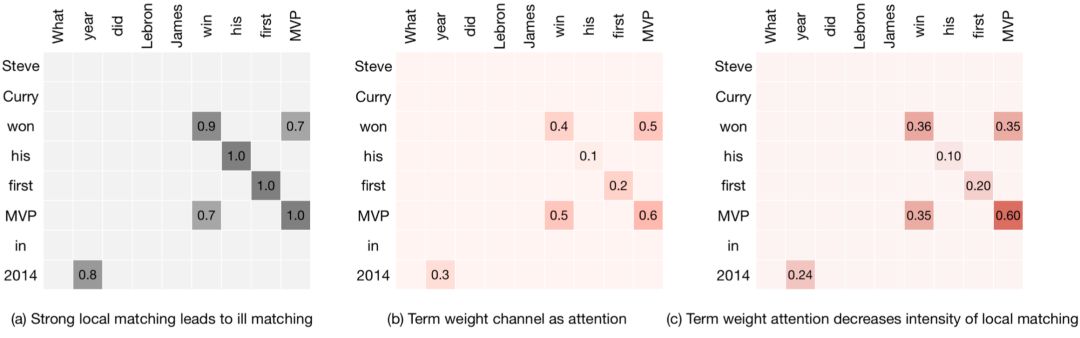
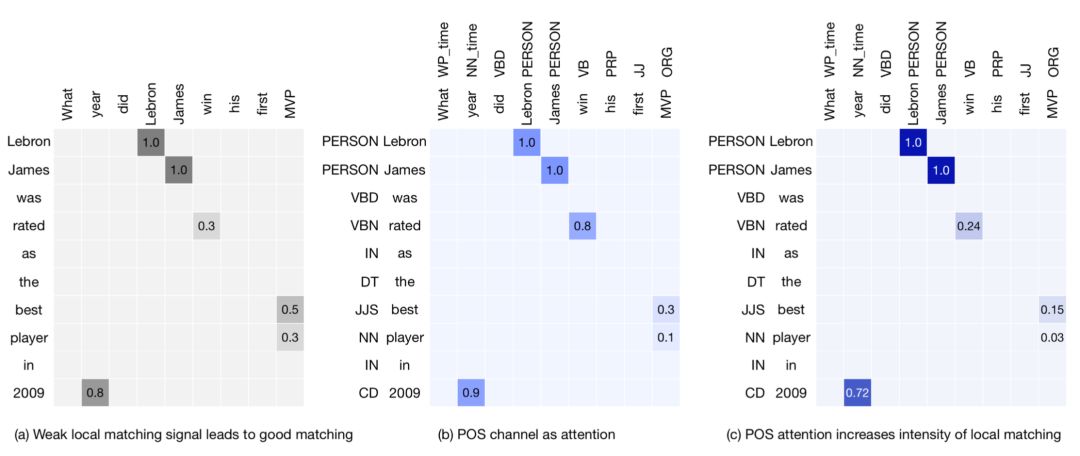
在原始的匹配矩阵中没有考虑到句子中不同term的权重重要性。以QA匹配为例,问题"What year did Lebron James win his first MVP",答案"Steven curry win his first MVP in 2014",明显是bad case。但是在QA匹配矩阵中,由于是基于word embedding进行相似度计算,两者大多数词匹配度都很高,显然是不make sense的。
因此作者第一种attention使用的是term weight,用每个term的IDF做为attention权重,这里不用TF-IDF是因为在短语匹配中,大多数term的词频都是1。
图4.44 term weight做attention表现
图4.44中的a为原始QA匹配相似度矩阵,b为用IDF作为term权重,c为叠加了term weight后的匹配度矩阵,可以发现例如his-his,first-first,year-2014等term pair的相似度都比较低,从而体现不同term对结果的不同贡献。
除了term weight,词性part-of-speech ( pos ) 特征也是能体现不同term交互重要性的特征。比如名字实体和名字实体的匹配权重,比普通的名词和名词以及形容词和形容词之间的权重要高。
图4.45 part-of-speech特征attention表现
以图4.45为例,b图表示的是不同的pos tag权重,可以发现人名-人名权重>动词-动词权重,引入pos特征attention能帮助让对匹配度更有效的实体权重拿到更大的权重。
除了1和2的term weight以及pos feature能够反映不同匹配部分的重要性,词的位置对结果的贡献也是不同的。直观的理解,位置靠前的词的权重要高于位置靠后的词。如图4.46表示的是不同匹配位置的权重大小,颜色越深则权重越大,可以发现句首的权重要高于句尾。
图4.46 词语位置attention的表现:越靠前越重要
通过上述3种不同通道的attention权重,分别表示为Att
tw
,Att
pos
,Att
spatial
,每个通道得到一个M*N的layer。
在第一层的局部匹配中,论文使用了多层的匹配;在第二层的全局和局部匹配中,论文构建了term weight、词性特征、词位置3种通道的attention,在这一层中则是对前面提取的信息进行最后的融合。这部分在论文中没有太多公式描述,作者论证卷积神经网络的优点后,最终使用了卷积网络,用滑动窗口形式进行融合。
-
在局部匹配阶段,不是直接使用原始word embedding的相似度矩阵,而是通过不同粒度的词语切分方法,如unigram,bigram,trigram,分别组成一元、二元和三元的短语信息提取,从而建立多层次的匹配
-
在局部和全局匹配阶段,提出了3种不同的attention方式,第一种attention是认为不同的term的权重不同;第二种attention认为是pos特征也就是词性特征重要程度不同,比如人名实体应该大于动词的权重;第三种attention认为词的位置重要程度也不同,例如句首权重一般要高于句尾。三种不同的attention方式可以看成是三种不同的channel
-
对于最后的匹配融合,论文使用了卷积神经网络进行提取,通过卷积-池化->卷积->池化的方式可以得到最终的匹配信号
本章讲到的基于match function的匹配模型对比第三章讲到的基于representation learning的匹配模型,让query和doc在一开始就提前交互,可以类比图中的图像匹配,是个二维匹配的过程,如图4.47所示。
对于query和doc,核心思想是如何构建query中的term以及doc的term的交互矩阵。4.1介绍的基于word level的匹配度矩阵的模型,大致可以用诺亚方舟2013年nips这篇文章的图4.48来表示。对于query中 ( Y轴 ) 的所有term,以及doc中 ( X轴 ) 中的所有term,两两计算得到匹配分数,可以得到一个10*10的匹配度矩阵。具体的匹配计算方式,在4.1.2的MatchPyramid中提出了3种不同的计算方法,有直接代表精确匹配的indicator,有计算两个word的向量点击的dot product,也有计算两个word的cosine相似度方法。
图4.48 基于match function learning匹配模型的通用范式
得到匹配句矩阵后,简单的做法是如下图所示直接连接全连接网络,更多的做法,这里就可以用各种常见的神经网络了。如4.1.2的MatchPyramid模型用卷积和池化进行信息提取,4.1.3的Match-SRNN模型用二维也就是空间层级的GRU来提取信息。
更多的,在4.2这一节,则介绍了各种attention结构的变化,名词千变万化,我个人按照论文本身的网络结构出发,大体分成以下几类模型:
① Baseline的attention模型:如4.2.1的ABCNN,以及4.2.2的DecAtt模型都是比较早提出attention的模型,整体结构相对后续其他变种来说相对简单
a. ABCNN模型:主要是用卷积和池化的思路提取匹配度矩阵的attention。根据attention在卷积之前和卷积之后又分为ABCNN-1和ABCNN-2
b. DecAtt模型:较早使用self-attention的匹配模型,把attention看成是soft-align机制。
② 多视角维度:如4.2.3的MCAN模型、4.2.4的HCRN模型、4.2.5的BiMPM模型、4.2.8的MwAN模型、4.2.11的MIX模型都属于多种attention的组合。这里的attention可以有多种角度进行区分
a. MCAN模型:将attention分为query和doc之间的max pooling、mean pooling、alignment pooling以及query和doc各自内部的self-attention。最终各种attention进行组合,从而体现Multi-Cast-Attention的思想
b. HCRAN模型:将attention分为alignment pooling,以及extractive pooling,其中后者又分为max pooling和mean pooling。
c. BiMPM模型:整个计算过程都是对称的,query->doc的所有计算,在doc->query也都需要计算一遍,体现了双向(Bidirectional)的思想。对于匹配方式,则提出了full-matching、max-pooling-matching、attentive-matching、max-attentive-matching这4种不同的匹配方式,体现了Multi-Perspective的思想。
d. MwAN模型:对于两个word的embedding计算方式,按照concat、minus、dot product以及cosine进行划分计算,然后concat组合,从而体现了Multiway-Attention的思想
e. MIX模型:对于两个句子之间的匹配,提出了3种不同的channel匹配:term weight attention、POS attention以及词位置的attention,体现了多通道信息交叉的思想,即Multichannel Information Crossing
③ 多层次维度:如4.2.9的HAR模型、4.2.10的HiNT模型。多层次大致可以理解成query内部的word之间、doc内部的句子之间,doc内部句子的word之间,这里就有不同层级的交互了,因此归类为多层次。
a. HAR模型:query看成一个句子,内部使用word级别的self-attention;把doc看成多个句子,句子之间色self-attention,doc内部每个句子内部word之间的self-attention。从而体现了多层次注意力Hierarchical Attention的思想
b. HiNT模型:和HAR模型不同,将doc看成是多个passage;对于query和doc中的每个passage分别计算attention,体现层次神经匹配Hierarchical Neural maTching的关系
05
▬
搜索中query和doc的相关性匹配模型
前2章讲的是语义匹配 ( semantic matching ) 里的深度模型,本章要讲的是相关性匹配 ( relevance matching ) 里的深度模型。语义匹配可以说是相关性匹配的基础。
语义匹配通常更关注的是相似性,一般来说两段文本通常结构相似,主要有以下特点:
① 代表性任务:自动问答QA任务、同义句子识别Paraphrase identification
② 语义匹配判断的是同质的两段文本:比如自动问答的QA问题,问题和答案一般来说讲的都是一个意思,长度和属性都相近;同义句子识别Paraphrase identification讲的是两段文本string1和string2是否是一个意思,这两段文本也都是同质的
③ 全局匹配:语义匹配通常将两段文本的片段作为一个整体,来推理他们之间的语义关系
相关性匹配更关注document文档和搜索query是否相关,特点如下:
② 两段文本一般不同质:query长度一般较短,doc的长度较长
③ 多样化匹配:相关性匹配可能发生在对应文档的任何部分,不需要把doc看作整体去和query进行匹配
对于相关性匹配,可以分成两个方向,第一种是基于global distribution的模型,第二种是基于local context的模型。
5.1 基于global distribution的模型
对于global distribution的模型来说,计算步骤分为两步:
注意到对于这种global distribution的模型,会丢失掉词序信息
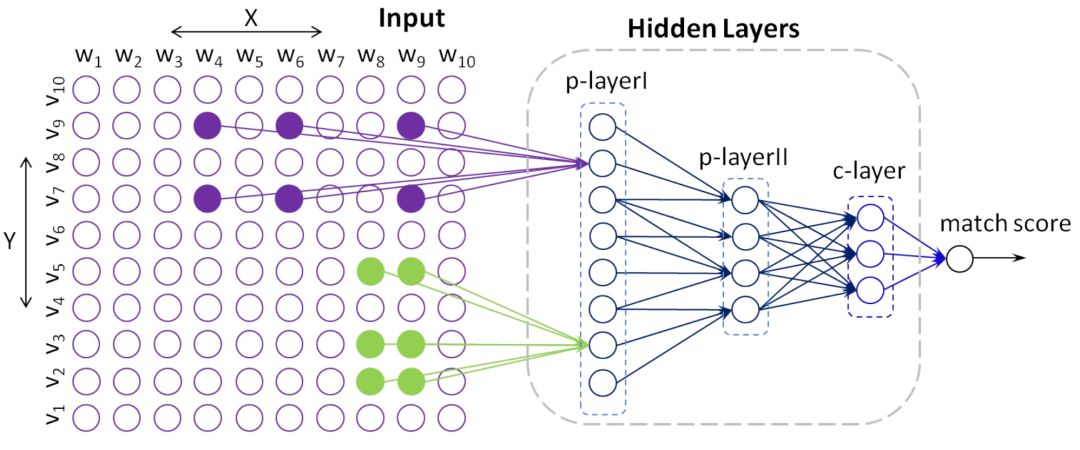
DRMM模型是中科院在2016提出的的相关性匹配模型,文中把query和doc分别表示为由M和N个term组成的term vector。
可以将query和document的term两两比对,计算相似性,再将相似性进行以直方图的形式进行分桶计算。例如:query:car ; document:( car,rent,truck,bump,injunction,runway )。query和doc两两计算相似度为 ( 1,0.2,0.7,0.3,-0.1,0.1 )
将[-1,1]的区间分为{[−1,−0.5], [−0.5,−0], [0, 0.5], [0.5, 1], [1, 1]} 5个区间。落在0-0.5区间(第三个区间)的个数有0.2,0.3,0.1共3个,所以最终表示为:[0,1,3,1,1]。
其中,⨂ 代表interaction,也就是query和doc的匹配函数;l=1,…,L表示的是L层隐层函数。值得注意的是最后一个公式,z
i
表示的是MLP网络最后一层第i个query的输出,g
i
表示的是第i个query和document的参数权重,通过term gating的网络来学习,其实就是query的softmax归一化表达:
这里x
i(q)
表示的是query中第i个term vector, w
g
为待学习的参数。对于该文章中提到的query和doc的相似度匹配计算,论文中提出了3种方法:
a. Count-based histogram ( CH )
这种方法使用直接计数的方法进行分桶计算。也就是说先计算原始的相似度 ( 通过cosine等 ),然后进行等距分桶 ( bin ) 后,统计每个桶 ( bin ) 的数量,得到的就是个基于计数的直方图。
b.
Normalized Histogram ( NH )
在CH的计数基础上做了归一化,确保所有直方图的分桶都在一个区间范围。
c.
LogCount-based Histogram ( LCH )
对CH的计数直方图取log对数,这个在搜索引擎里主要也是为了迎合大多数query和doc的分布都是pow-law的,取对数后pow-law分布的数据会更加服从线性分布。
总结下DRMM的模型流程,基本思想就是每个query在检索doc的过程中,对结果的贡献程度是不同的:
-
把query和doc分别表示成M和N个term的向量表达
-
忽略query中每个term的位置关系和上下文,并且认为每个term对doc的共享程度不同
-
匹配强度计算:query中每个term和doc通过直方图匹配的方法计算其匹配强度,可以分为基于计数、归一化计数、log计数等不同直方图匹配,得到匹配强度z
i
-
权重计算:query中每个term在整个query的权重,通过所有term的softmax权重表达计算,得到权重g
i
-
前两步得到的z
i
和g
i
的加权表达就是最终整个query对doc的表达
DRMM作为相关性模型的baseline,忽略了每个词的位置信息和上下文信息。后续一些加入position和attention的方法都是为了改进该模型无位置信息的缺点。但个人觉得,读DRMM更大的收获,其实是更加清晰的了解了语义匹配和相关性匹配两者的异同点。
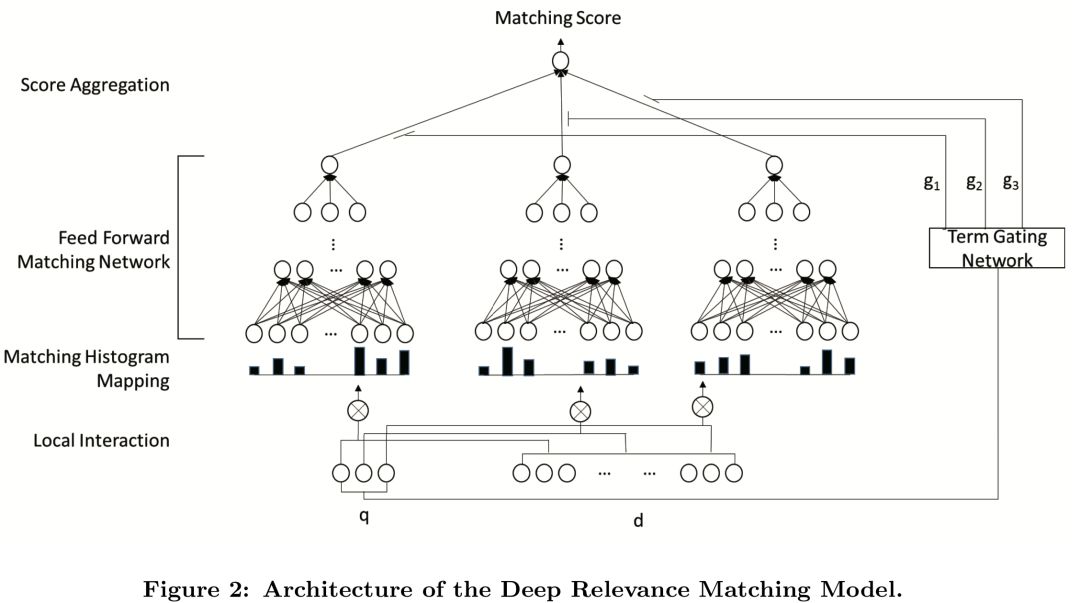
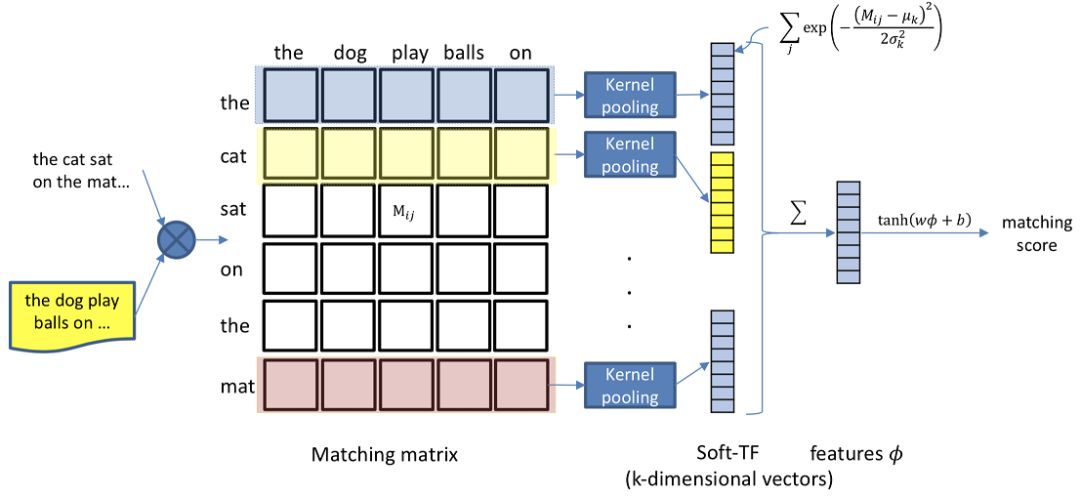
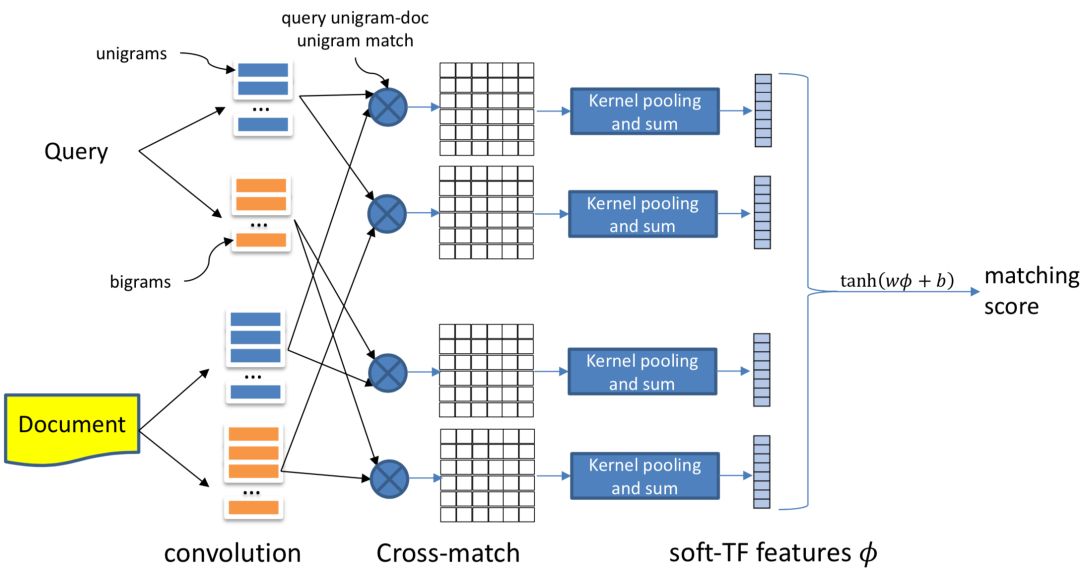
针对DRMM提到的无位置信息的相关性模型,卡梅隆大学在SIGIR2017提出了K-NRM模型,全称为Kernel-based Neural Rank Model,一种基于kernel-pooling的相关性模型。整个框架如图5.2所示:
整个模型可以分为以下3层:① translation layer;② kernel pooling layer;③ rank layer
query和doc分别由n个term和m个term的词向量组成的vector。通过query和doc之间每个term两两求cosine相似度,得到一个n*m的矩阵M:
Kernel pooling层引入了K个kernel。对于第k个kernel,query中第i个term ( M矩阵中的第i行 ) 如果采用RBF kernel进行计算,表达如下:
其中,u
k
和sigma
k
为第k个kernel的超参数均值和标准差,是超参数,需要在训练前事先设定。这里使用RBF核函数也是有原因的。当M
ij
越趋近于u, 方差sigma
k
越趋近于无穷大,kernel pooling的输出越大。我们来看下2种不同的特殊情况:
a.
当方差sigma接近无穷大,上述公式趋近于1,相当于是average pooling
b.
当方差sigma趋近于0,均值u等于1,相当于是TF词频统计模式
可以发现,如果M
ij
等于1,此时该term的输出才为1,而M
ij
=1意味着query的第i个term和doc的第j个term是完全精准匹配的 ( exact match ),只有这样才能使得cosine距离为1。所以在这种情况下,kernel pooling相当于是一个完全精准匹配。也完全等价于TF词频统计模式,也就是只统计query和doc有多少个term是完全匹配的。
对M矩阵每一行,也就是每个query使用一个核函数可以得到一个匹配分数,K个kernel则能得到一个维度为K的向量。如下面的公式所示,第二个公式表示,M矩阵的每一行通过K个核函数,可以得到长度为K的向量,第一个公式对所有行 ( n ) 进行对数log加和,得到一个维度为K的向量进入下一层网络。
上一层kernel pooling layer得到的K维向量通过一个线性映射后,再经过tanh得到最终的分数。使用tanh是为了让最终的match score映射到-1到1之间,也符合相关性从-1到1的定义。这里的w和b都是一个可训练的维度为K的参数向量。
总结下K-NRM的核心公式,可以用如图5.3的6个公式表示,值得注意的是从1-6的公式网络结构是从输出到输入自顶向下的关系
① 对比DRMM最大的不同,就是引入了K个kernel function,通过kernel pooling的方式,对query中每个term求和对应的doc的匹配分数。
② 这里的K个kernel可以类比CNN中的filter,卷积过程是从上到下卷积列数保持固定;这里的kernel pooling 计算也是按列计算。
③ Kernel pooling的每个kernel的均值和方差都是超参数,需要事先设定。
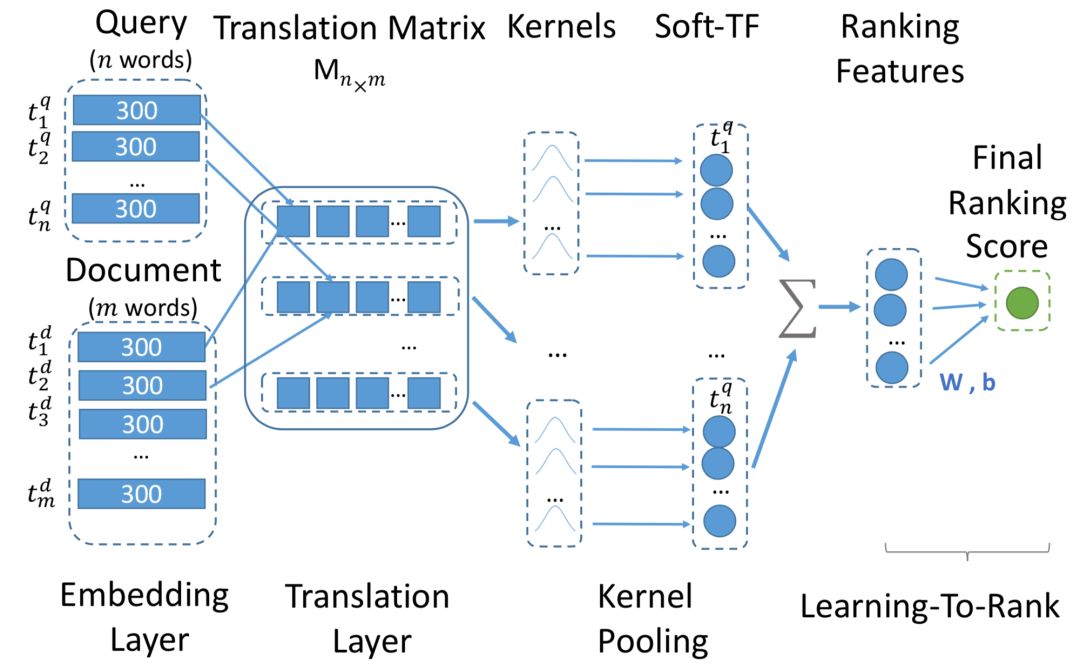
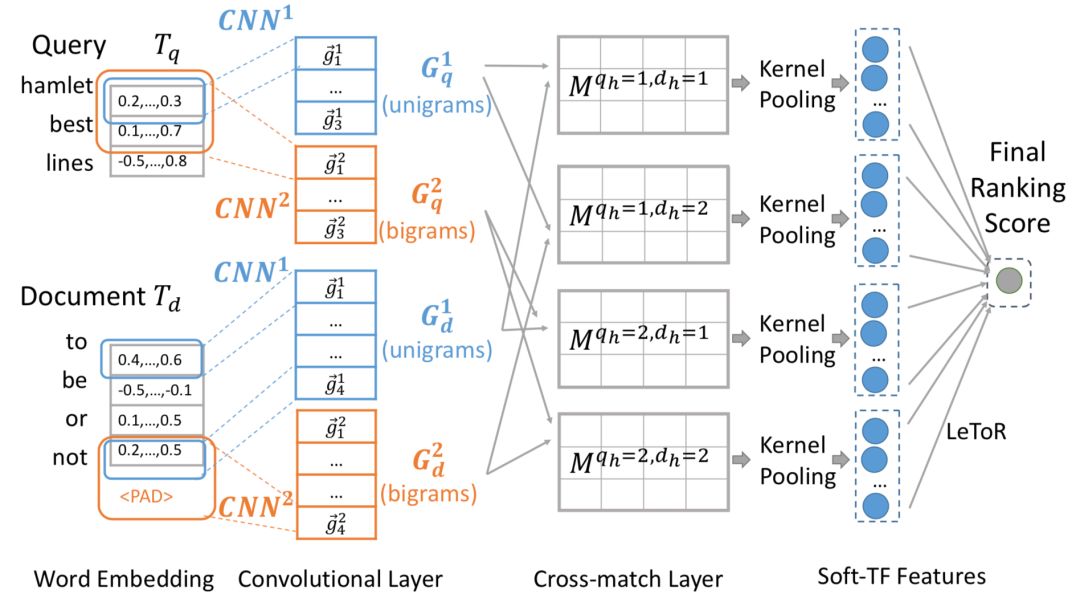
2018年的WSDM上,卡梅隆大学&清华又在原来的K-NRM上提出了加入卷积元素的Conv-KRNM模型,对比原来的kernel pooling,显式的引入了CNN模块,框架如图5.5所示:
整个模型可以分为4层:① embedding 层;② convolutional 层;③ cross-match 层;④ kernel pooling 层;⑤ rank 层。
首先,把query和document投射到隐层维度为L的embedding去,维度均为m*L:
卷积层通过大小为h*L的filter ( 一共有F个 ),来从上到下对query和doc分别进行卷积。对于第i个term,通过和filter 进行卷积,得到一个实数v如下:
因为有F个filer ( w
1
,w
2
,w
3
,…,w
F
),每个term可以得到一个F维度的向量,然后再通过一个RELU层进行映射得到第i个term经过卷积后的F维输出:
这里W大小为h*L*F,b大小为F,均为待学习的模型参数。因此,对于不同的滑动窗口h
1
,h
2
,…,h
max
,每个窗口我们都可以得到原始m个term的卷积输出。维度从原始embedding的m*L变成了m*F,L为embedding size,F为filter个数。
从②中经过CNN提取的query和document分别的矩阵m*F和m*F后,对于query中第i个元素、h
q
的n-gram的值,以及doc中第j个元素、h
d
的n-gram的值的匹配分数为:
最终可以得到h
max
* h
max
个元素的匹配矩阵M,每个元素都是一个m*m的矩阵模块M
hq, hd
:
上一步得到匹配矩阵M后,在kernel pooling layer这里的做法是K-NRM是一样的。M元素里一共有h
max
*h
max
个元素,每个元素都是一个矩阵模块,一共有K个kernel:
每个元素产出的是一个K维的向量,因此最终得到的向量为K*h
max
*h
max
上一层kernel pooling layer得到的K*h
max
*h
max
维向量通过一个线性映射后,在经过tanh得到最终的分数。
损失函数loss用pairwise loss表示如下:
总结来说,Conv-NRM模型对比K-NRM模型,在kernel pooling之前对于query和doc各自引入了高度为h
max
的滑动窗口。对图5.6来说,h
max
=2,分别代表unigram和bigrams。整体过程如下:
① query和doc各自映射为embedding特征向量m*L
② query和doc各自通过h
max
=2的滑动窗口 ( unigram和bigram ),F个filter进行卷积得到卷积后的新特征向量,各有2*m*F个
③ 通过cross match的匹配,对②得到的query和doc的新特征向量,两两进行cosine匹配,得到2*2个匹配矩阵,每个匹配矩阵是个m*m的矩阵
④ 通过kernel pooling,对于③中4个匹配矩阵中的每一个,应用K个kernel提取得到k维度的特征向量,一共得到4*K的特征向量,然后concat起来作为下一层的输入
⑤ 对kernel pooling得到的4*K个向量,应用tanh函数得到match score, 损失函数使用pairwise loss
对于local context的模型来说,计算步骤分为两步:
b. 计算该term,以及在doc中对应的上下文两者的匹配信号
注意到对于这种global distribution的模型相比于5.1讲到的global distribution,捕获了词序信息,同时它关注的是doc中与term相关部分的上下文,丢弃了无关部分 ( 非上下文 ),因此匹配会更加的鲁棒。
EMNLP2017年提出的PACRR,全称是Position-Aware Convolutional- Recurrent Relevance Matching,在原来的相关性模型DRMM基础上引入了位置信息。PACRR模型基于一种假设,就是query和doc的相关性匹配是由doc中的特定位置决定的,论文通过CNN的卷积操作来捕捉局部词序的关系,在doc上利用不同大小的卷积核进行卷积,然后在整个doc上进行池化。主要整体框架如图5.7所示:
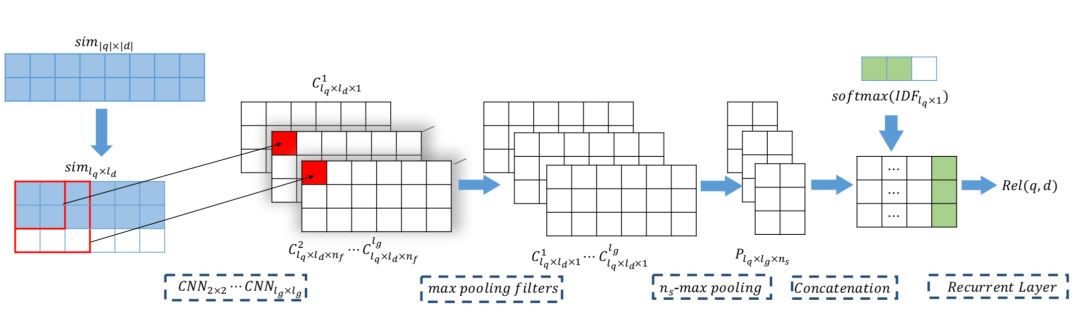
给定query和doc,term的长度大小为别为q和d,通过word embedding映射得到query embedding和doc embedding矩阵。这里word embedding 采用预训练得到并且训练中保持不更新。
query和doc的匹配矩阵采用cosine相似度,从q个query embedding和d个doc embedding两两计算cosine相似度,得到一个维度为q*d的相似度矩阵。为了保证长度一致,假设query最大长度为l
q
,对于query来说统一补齐到长度l
q
,如果q<l
q
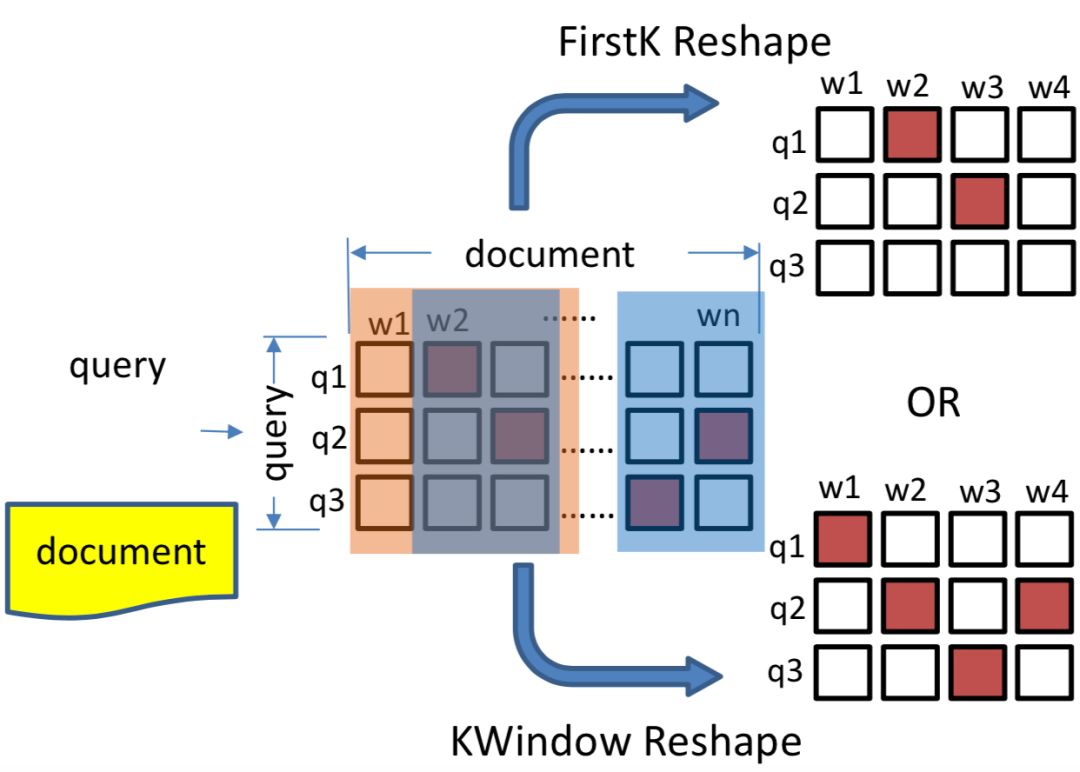
的则直接用0补齐。对于doc文中提出了两种方法:first-k和k-window,如图5.8所示:
图5.8 query-doc的两种方法:firstK和KWindow
对于匹配矩阵,取前k行。如果当前doc长度d<k,则不足部分用0补齐。
k-window方法的基本假设是doc中相关性比较低的term对结果的共享应该比较小。因此引入了一个超参数n,表示的是每个doc的片段最大长度,相当于是个n-gram的卷积,过程如下:
-
对于doc中的每个n-gram,相当于有n个term,每个term和query中的l
q
个term计算相似度,取这l
q
个相似度中最高的值作为该term的匹配分数
-
对当前这n个term的匹配分数求均值作为该n-gram和query的匹配分数
-
对于doc的所有term都按照第一步从头到尾滑动,按照n-gram求每个n-gram的匹配矩阵,表示如下:
对所有的n-gram匹配分数,求top k的片段,k的取值如下,不足补0。
通过上述得到一个l
q
*l
d
的相似度矩阵后,在该层则通过不同的卷积核,2*2,3*3,4*4,…,l
g
*l
g
来进行卷积得到l
g-1
个卷积层 ( 原始的相似度矩阵相当于是1*1的卷积核 ),相当于是提取了bigram,trigram,…,l
g
-gram信息。每个卷积核又有n
f
个filter, 可以得到l
g
个l
q
*l
d
*n
f
的三维矩阵。
在池化层通过两层的pooling提取信息。首先是max pooling,对于l
g
个三维矩阵,每个矩阵有n
f
个filter,通过max pooling在n
f
个filter中提取得到最大值,因此可以得到l
g
个矩阵c
1
,c
2
,c
3
,…,c
lg
,每个矩阵维度l
q
*l
d
和原始匹配度矩阵维度一致。
为了保留n
s
个最强信号,在max-pooling之后论文由使用了k-max-pooling,在l
q
维度上 ( 也就是对于l
q
*l
d
矩阵的每一行 ) 进行提取最大的n
s
个信号,直观解释就是doc中的l
d
个term,只提取其中和当前query匹配度最高的n
s
个,可以得到l
g
个二维矩阵l
q
*n
s
。因此,最终得到一个l
q
*l
g
*n
s
维度的三维向量作为下一层的输入。
该层的目的是为了提取得到全局的匹配信号。前面得到的向量维度l
q
*l
g
*n
s
中,其中l
q
为query经过pad的长度,这里作者使用的query的IDF信息,将其进行归一化,目的是消除query在全局频次的影响。
因此,通过IDF的归一化,可以得到一个l
g
*n
s
的矩阵P,通过展开得到一个向量,并且将当前query的IDF信息concat后,接入LSTM网络,最终的输出为匹配分数。
① 提到的位置相关 ( position aware ) 原意指的是query和doc的相关性由doc中特定位置决定。
② 通过不同大小的卷积核进行卷积提取匹配信息、max-pooling以及k-max pooling两层池化层的信息提取。
③ 引入query 的IDF信息等各种细节对位置信息进行强化。
2018年的WSDM上作者等人在2017年的PACRR模型上由加入了上文context信息,context-aware,因此该模型称为CO-PACRR,整体框架如图5.9所示:
模型的核心创新点有3部分:① 上下文信息;② 级联的k-max pooling;③ query位置随机打乱
和PACRR模型相比,在输入层除了query和doc的原始相似度矩阵 ( 维度大小为l
q
*l
d
),最大的不同在于引入了局部上下文信息作为输入。对于doc中的每个term,除了当前term和query的相似度,还考虑当前term上下文和query的相似度。
对于query来说,由于一般都比较短,因此query的上下文向量表示queryvec用整个query的所有term求平均作为其上下文表示;对于doc来说,类似于word2vec的思想,取上下文滑动窗口大小为w
c
,doc在该窗口内上下文的向量的平均值作为其上下文表示:
因此,对于doc中第i个term的上下文和query上下文向量的相似度表示如下:
由于doc的term个数为d,query都是固定的q个term求平均,对doc的term挨个计算和query上下文的相似度,可以得到一个d维的向量作为输入。
在PACRR模型中用到的k-max pooling是在整个doc中选择最大的n
s
个值,例如doc的长度为100,n
s
=2,相当于是在每个doc的100个词中选择最大的2个值。
而CO-PACRR模型引入了新的超参数n
c
,表示文档划分的个数,比如n
c
=4,则分别在文档的25%、50%、75%、100%把doc划分成了4部分,对于每一部分进行k-max pooling,以n
s
=2为例,在doc的第1-25、26-50、51-75、76-100这4部分,分别取2个作为最大值,最终得到8个值。
前面我们知道PACRR模型在整个doc上使用k-max pooling后得到的向量为l
q
*l
g
*n
s
,通过这种层次k-max pooling得到的矩阵维度为l
q
*n
c
*l
g
*n
s
。
在PACRR模型中,query都是统一pad到固定长度l
q
的,对于较短的query,尾部需要用0补齐到l
q
。这种做法缺点是对于query尾部特征的向量,将得不到足够的信息进行权重更新,这样模型在训练学习过程会认为query尾部的term对结果的共享较小,权重也接近0,从而导致真正在query尾部的term对结果贡献较小,模型缺乏泛化能力。
为了了避免这种情况,CO-PACRR模型对query的顺序,也就是矩阵的行进行shuffle随机打乱,从而让用0填充的向量均匀的分散在query的特征各处,从而解决了用0填充带来的问题。
-
引入了上下文信息 ( context-aware ):doc中每个word的表示出了自身的embedding,还将其窗口为w
c
的上下文平均向量作为其表示,与query计算相似度
-
级联的k-max-pooling:将doc平均分成n
c
个部分,每个部分进行k-max-pooling提取最大的n
s
个值,总共可以得到n
c
*n
s
的最大值
( 3 ) 对query的位置进行shuffle,消除pad带来的尾部特征训练不充分影响
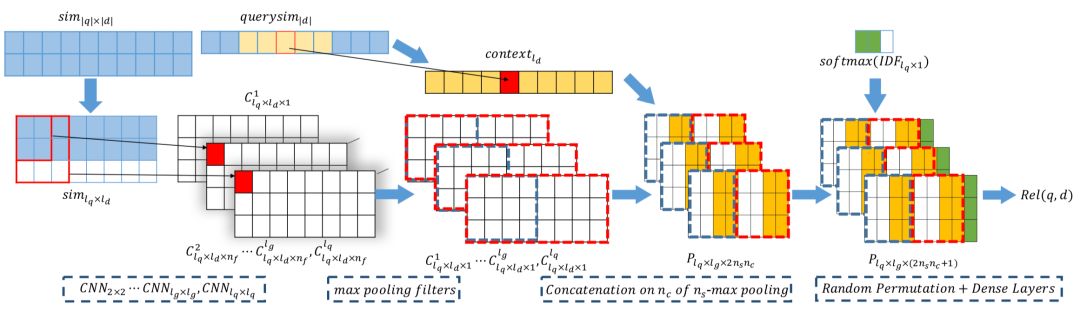
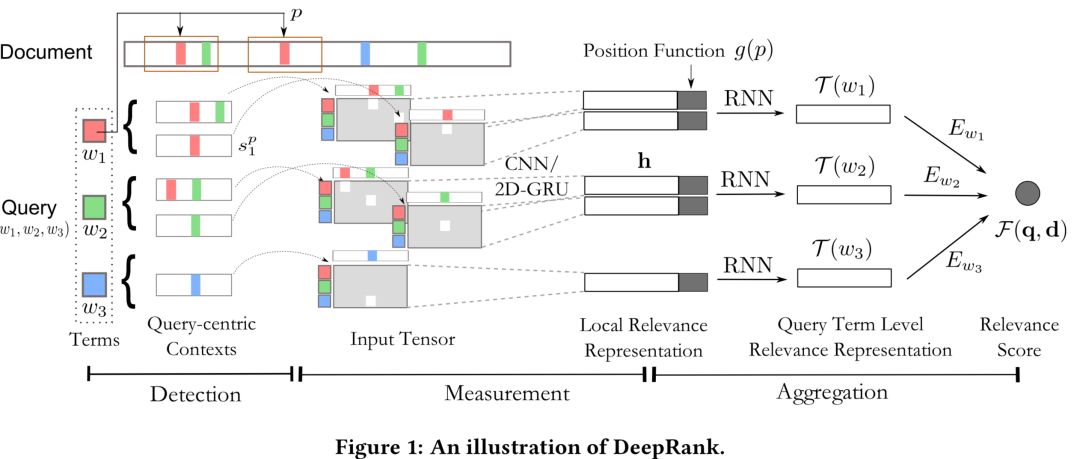
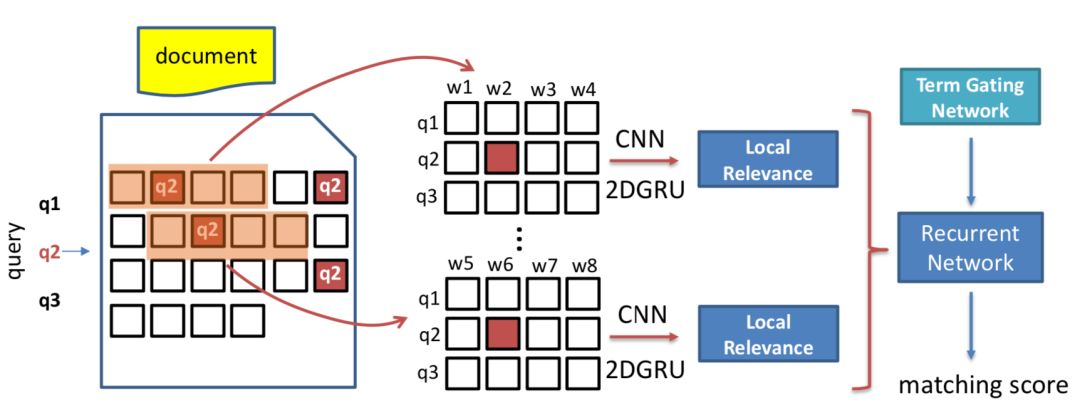
CIKM2017提出的DeepRank模型,基于一个有趣的假设,用户搜索query后,在展现的doc里面 ( title ),往往更关注的在doc中和query匹配的词的上下文。有个关于眼球实验的paper也做了类似的验证。比如,你搜索了"佳能相机价格"后,在展现结果里,往往会快速的扫描"佳能相机"前后相关的词,例如相关型号之类的,以及"价格"前后的信息,例如具体多少钱的信息,这种假设在信息检索是比较make sense的。
DeepRank模型主要是基于该假设,集中在doc中与query相关的term上下文,称为query-centric contexts。整体框架如下图5.10所示:
整个过程分为3步:① detection策略,也就是找到doc中与query中的term匹配的位置;② measurement策略;③ aggregation策略
首先,对于给定的query,第一步的detection,需要检测找到query中的term在doc中的位置。给定query和doc,分别由M和N个term组成,每个term隐层维度d。
如果query中的term w
u
在doc中第p个位置出现,就把该位置前后位置窗口大小为k的term都找出来,总共2k+1个的词向量,称为query-centric contexts。
前一步得到query中的term,以及在doc中对应的query-centric contexts后,需要进行匹配得到交互矩阵。对每个query中的第i个term,以及query-centric contexts中的第j个term,用s
ij
来表示,和MatchPyramid模型一样,文中使用了indicator和cosine两种方法,indicator相当于是精确匹配,只有query的第i个term和doc的第j个term完全一致才s
ij
为1,否则为0;cosine则直接计算query 第i个term和doc第j个term的向量cosine距离。
为了充分表达上下文信息,最终的input tensor是个三维的向量表达,s
ij
分别由query第i个term,doc的第j个term,以及两者的交互 ( indicator或者cosine ) 表示。
对于输入向量S,引入K个kernel进行卷积表达,每个kernel卷积核大小为γ*γ。对于卷积输出第i,j个元素,其表达为S
i,j
到S
i+γ-1, j+γ-1
之间的元素和卷积核 ( γ*γ ) 的卷积输出。
由于S中每个元素都是个三维向量,因此l=3。第二个公式采用max pooling,对K个kernel分别求max,得到K维的向量。
这里论文使用了Match-SRNN中的递归RNN,由4个更新gate和3个reset gate来拟合。
总结DeepRank模型的特点和人类的直觉判断相关性很类似:
-
首先对于query中的每个term,找出每个term在doc中出现的位置
-
对于第一步每个term在doc出现的位置,将该位置前后各k个词(总共2k+1)找出来,作为query在doc中该位置匹配的上下文表示query-centric contexts
-
对第二步得到的每一个query-centric contexts以及query对,使用CNN或者2D-GRU的网络及结构提取信息得到匹配分数
-
通过term gating network对前一步得到的每个query和query-centric contexts局部相关性分数进行加权融合。
06
▬
总结
推荐和搜索的本质其实都是匹配,前者匹配用户和物品;后者匹配query和doc。具体到匹配方法,分为传统模型和深度模型两大类。本文系统的介绍传统模型和深度模型,以及语义匹配和相关性匹配。
传统模型。有两种主要的方法,第一种是把query和doc都同时映射到latent space的方法,比如基于统计的BM25方法,以及PLSRMLS方法。另一种方法,是通过将doc映射到query的空间的,然后在query的空间进行匹配。这种方法和机器翻译中,将源语言映射到目标语言的做法是一致的,因此又称为基于translation的方法。
深度匹配模型。对于query和doc的匹配分数,有两种思路,一种是query和doc都各自学习自己的表示,不到最后一刻不交互,在得到query和doc各自充分的representation后,再进行融合匹配。因此,我们首先介绍了基于representation的深度匹配模型。为了得到query和doc的表示,当然是各种网络结构都可以尝试使用,比如基于DNN的DSSM模型、基于CNN的CNN-DSSM模型、基于RNN的LSTM-RNN模型。
深度匹配模型中的第二种思路,也就是让query和doc在一开始就通过match function进行交互,因此称为基于match function 的深度匹配模型,也称为interaction-based的模型。既然要交互,当然需要想办法得到query和doc尽可能丰富的匹配信号。比如4.1提到的在word level层级的匹配度矩阵。有了匹配度矩阵,4.2讲述了众多在匹配度矩阵上进行各种attention的模型。
最后,介绍了相关性匹配以及语义匹配的不同,并基于global distribution以及local context分别介绍了不同的相关性匹配模型。
如果您喜欢本文,欢迎点击右上角,把文章分享到朋友圈~~
欢迎加入 DataFunTalk
机器学习
交流群,跟同行零距离交流。如想进群,请加逃课儿同学的微信 ( 微信号:
DataFunTalker
),回复:
机器学习
,逃课儿会自动拉你进群。
1. https://www.comp.nus.edu.sg/~xiangnan/sigir18-deep.pdf
2. https://github.com/NTMC-Community/awesome-neural-models-for-semantic-match
3. [SMT] Stefan Riezler and Yi Liu. Query Rewritting Using Monolingual Statistical Mac3.hine Translation. In ACL 2010.
4. [WTM] Jianfeng Gao, Xiaodong He, and JianYun Nie. Click-through-based Translation Models for Web Search: from Word Models to Phrase Models. In CIKM 2010.
5. [DSSM] Huang P S, He X, Gao J, et al. Learning deep structured semantic models for web search using clickthrough data[C]//Proceedings of the 22nd ACM international conference on Conference on information & knowledge management. ACM, 2013: 2333-2338.
6. [ARC-I,ARC-II] Z, Li H, et al. Convolutional neural network architectures for matching natural language sentences[C]//Advances in neural information processing systems. 2014: 2042-2050.
7. [CNN-DSSM] Hu B, LuShen Y, He X, Gao J, et al. A latent semantic model with convolutional-pooling structure for information retrieval[C]//Proceedings of the 23rd ACM International Conference on Conference on Information and Knowledge Management. ACM, 2014: 101-110.
8. [CNTN] Qiu X, Huang X. Convolutional Neural Tensor Network Architecture for Community-Based Question Answering[C]//IJCAI. 2015: 1305-1311.
9. [LSTM-RNN] Palangi H, Deng L, Shen Y, et al. Deep sentence embedding using long short-term memory networks: Analysis and application to information retrieval[J]. IEEE/ACM Transactions on Audio, Speech and Language Processing (TASLP), 2016, 24(4): 694-707.
10. [MatchPyramid] Pang L, Lan Y, Guo J, et al. Text Matching as Image Recognition[C]//AAAI. 2016: 2793-2799.
11. [MatchPyramid-cont] Liang Pang, Yanyan Lan, Jiafeng Guo, Jun Xu, Xueqi Cheng. A Study of MatchPyramid Models on Ad-hoc Retrieval. In Proceedings of SIGIR 2016 Neu-IR Workshop.
12. [Martch-SRNN] Shengxian Wan, Yanyan Lan, Jun Xu, Jiafeng Guo, Liang Pang, and Xueqi Cheng. 2016. Match- SRNN: modeling the recursive matching structure with spatial RNN. In Proceedings of the Twenty- Fifth International Joint Conference on Artificial Intelligence (IJCAI'16), 2922-2928.
13. [MV-LSTM] Wan S, Lan Y, Guo J, et al. A Deep Architecture for Semantic Matching with Multiple Positional Sentence Representations[C]//AAAI. 2016, 16: 2835-2841.
14. [aNMM] aNMM: Ranking Short Answer Texts with Attention-Based Neural Matching Model. CIKM 2016.
15. [ABCNN] Wen Y, Hin S, Bing X, Bowen Z. ABCNN: Attention-Based Convolutional Neural Network for Modeling Sentence Pairs. ACL 2016.
16. [DecAtt] Ankur P. Parikh, Oscar Tackstrom, Dipanjan Das, and Jakob Uszkoreit. A Decomposable Attention Model for Natural Language Inference. In Proceedings of EMNLP, 2016.
17. [MCAN] Yi T, Luu T, Siu H. Multi-Cast Attention Networks for Retrieval-based Question Answering and Response Prediction. KDD 2018.
18. [HCRN] Yi T, Luu T, Siu H. Hermitian Co-Attention Networks for Text Matching in Asymmetrical Domains. IJCAI 2018.
19. [BiMPM] Zhi W, Wael H, Radu H. Bilateral Multi-Perspective Matching for Natural Language Sentences. IJCAI 2017.
20. [ESIM] Qian C, Xiao Z, Zhen L, et al. Enhanced LSTM for Natural Language Inference. ACL 2017.
21. [DIIN] Yi G, Heng L, Jian Z. Natural Lanuguage Inference Over Interaction Space. ICLR 2018.
22. [MwAN] Chuan T, Fu W, Wen W, et al. Multiway Attention Networks for Modeling Sentences Pairs. IJCAI 2018.
23. [HAR] Ming Z, Aman A, Wei W, Chandan R. HAR: A Hierarchical Attention Retrieval Model for Healthcare Question Answering. WWW 2019.
24. [HiNT] Yi F, Jia G, Yan L, et al. Modeling Diverse Relevance Patterns in Ad-hoc Retrieval. SIGIR 2018.
25. [MIX] Hao C, Fred H, Di N, et al. MIX: Multi-Channel Information Crossing for Text Matching. KDD 2018.
26. [Duet] Bhaskar Mitra, Fernando Diaz, and Nick Craswell. Learning to match using local and distributed representations of text for web search. In Proceedings of WWW 2017.
27. [DRMM] Jiafeng Guo, Yixing Fan, Qiqing Yao, W. Bruce Croft, A Deep Relevance Matching Model for Ad-hoc Retrieval. In Proceedings of CIKM 2016.
28. [K-NRM] Chenyan Xiong, Zhuyun Dai, Jamie Callan, Zhiyuan Liu, Russell Power. End-to-End Neural Ad-hoc Ranking with Kernel Pooling. In Proceedings of SIGIR 2017.
29. [Conv-KRNM] Zhuyun Dai, Chenyan Xiong, Jamie Callan, and Zhiyuan Liu. Convolutional Neural Networks for Soft-Matching N-Grams in Ad-hoc Search. In Proceedings of WSDM 2018.
30. [Co-PACRR] Kai Hui, Andrew Yates, Klaus Berberich, and Gerard de Melo. Co-PACRR: A Context-Aware Neural IR Model for Ad-hoc Retrieval. WSDM '18, 279-287.
31. [DeepRank] Liang Pang, Yanyan Lan, Jiafeng Guo, Jun Xu and Xueqi Cheng. DeepRank: a New Deep Architecture for Relevance Ranking in Information Retrieval. In Proceedings of CIKM 2017.
DataFunTalk
专注于大数据、人工智能技术应用的分享与交流。发起于2017.12,至今已在全国7个数据智能企业和人才聚集的城市 ( 北京、上海、深圳、杭州等 ) 举办超过100场线下技术分享和数场千人规模的行业论坛及峰会,邀请300余位工业界专家和50位知名学者参与分享,30000+从业者参与线下交流。合作企业包括BATTMDJ等知名互联网公司和数据智能方向的独角兽公司,旗下DataFunTalk公众号共生产原创文章300+,百万+阅读,5万+精准粉丝。
注:
左侧关
注"社区小助手"加入各种技术交流群,右侧关注"DataFunTalk"公众号最新干货文章不错过👇👇