这应该是业界第一款完整支持 Transformer、GPT 等多种模型高速推理的开源引擎。
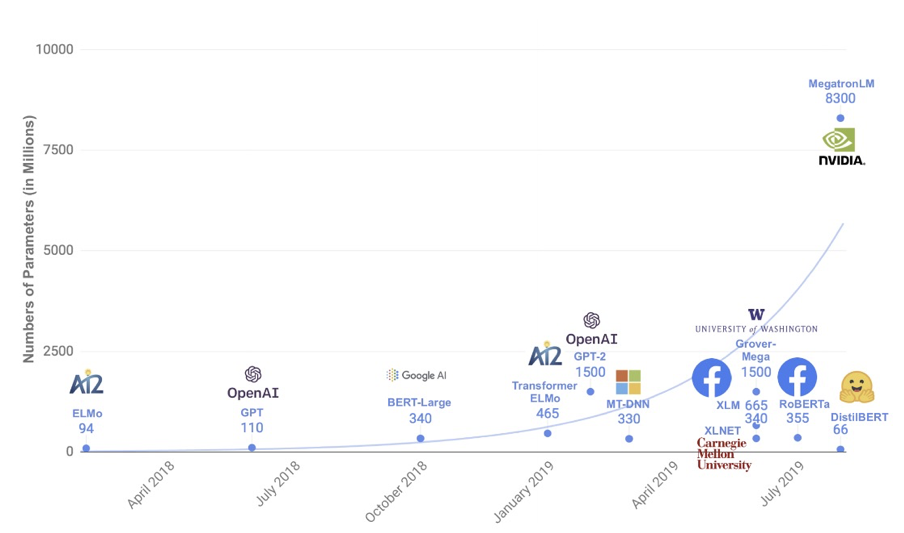
2017 年 Google 提出了 Transformer [1] 模型,之后在它基础上诞生了许多优秀的预训练语言模型和机器翻译模型,如 BERT [2] 、GPT 系列[13]等,不断刷新着众多自然语言处理任务的能力水平。与此同时,这些模型的参数量也在呈现近乎指数增长(如下图所示)。例如最近引发热烈讨论的 GPT-3 [3],拥有 1750 亿参数,再次刷新了参数量的记录。
![]()
如此巨大的参数量,也为模型推理部署带来了挑战。以机器翻译为例,目前 WMT[4]比赛中 SOTA 模型已经达到了 50 层以上。主流深度学习框架下,翻译一句话需要好几秒。这带来了两个问题:一是翻译时间太长,影响产品用户体验;二是单卡 QPS (每秒查询率)太低,导致服务成本过高。
因此,今天给大家安利一款速度非常快,同时支持非常多特性的高性能序列推理引擎——LightSeq。它对以 Transformer 为基础的序列特征提取器(Encoder)和自回归的序列解码器(Decoder)做了深度优化,早在 2019 年 12 月就已经开源,应用在了包括火山翻译等众多业务和场景。据了解,这应该是业界第一款完整支持 Transformer、GPT 等多种模型高速推理的开源引擎。
LightSeq 可以应用于机器翻译、自动问答、智能写作、对话回复生成等众多文本生成场景,大大提高线上模型推理速度,改善用户的使用体验,降低企业的运营服务成本。
相比于目前其他开源序列推理引擎,LightSeq具有如下几点优势:
LightSeq推理速度非常快。例如在翻译任务上,LightSeq相比于Tensorflow实现最多可以达到14倍的加速。同时领先目前其他开源序列推理引擎,例如最多可比Faster Transformer快1.4倍。
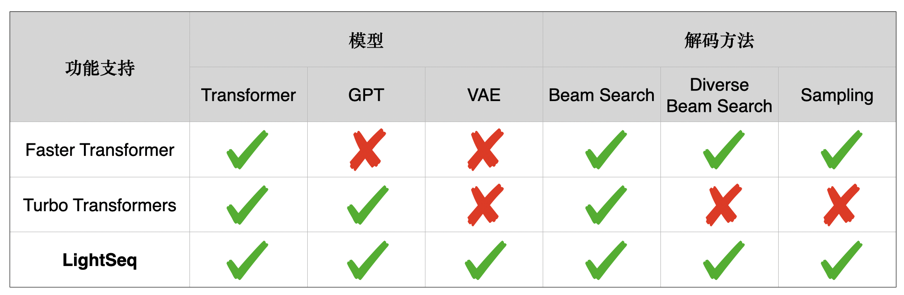
LightSeq支持BERT、GPT、Transformer、VAE 等众多模型,同时支持beam search、diverse beam search[5]、sampling等多种解码方式。下表详细列举了Faster Transformer[7]、Turbo Transformers[6]和LightSeq三种推理引擎在文本生成场景的功能差异:
![]()
3. 简单易用,无缝衔接Tensorflow、PyTorch等深度学习框架
LightSeq通过定义模型协议,支持各种深度学习框架训练好的模型灵活导入。同时包含了开箱即用的端到端模型服务,即在不需要写一行代码的情况下部署高速模型推理,同时也灵活支持多层次复用。
利用 LightSeq 部署线上服务比较简便。LightSeq 支持了 Triton Inference Server[8],这是 Nvidia 开源的一款 GPU 推理 server ,包含众多实用的服务中间件。LightSeq 支持了该 server 的自定义推理引擎 API 。因此只要将训练好的模型导出到 LightSeq 定义的模型协议[9]中,就可以在不写代码的情况下,一键启动端到端的高效模型服务。更改模型配置(例如层数和 embedding 大小)都可以方便支持。具体过程如下:
首先准备好模型仓库,下面是目录结构示例,其中 transformer.pb 是按模型协议导出的模型权重,libtransformer.so 是 LightSeq 的编译产物。
- model_zoo/ - model_repo/ - config.pbtxt - transformer.pb - 1/ - libtransformer.so
然后就可以启动Triton Inference Server[8],搭建起模型服务。
1. trtserver --model-store=${model_zoo}
在 NVIDIA Tesla P4 和 NVIDIA Tesla T4 显卡上,笔者测试了 LightSeq 的性能,选择了深度学习框架 Tensorflow v1.13 和解码场景支持较为丰富的 Faster Transformer v2.1 实现作为对比。Turbo Transformers 解码方法比较单一(只支持 Beam Search ,不支持文本生成中常用的采样解码),尚未满足实际应用需求,因此未作对比。
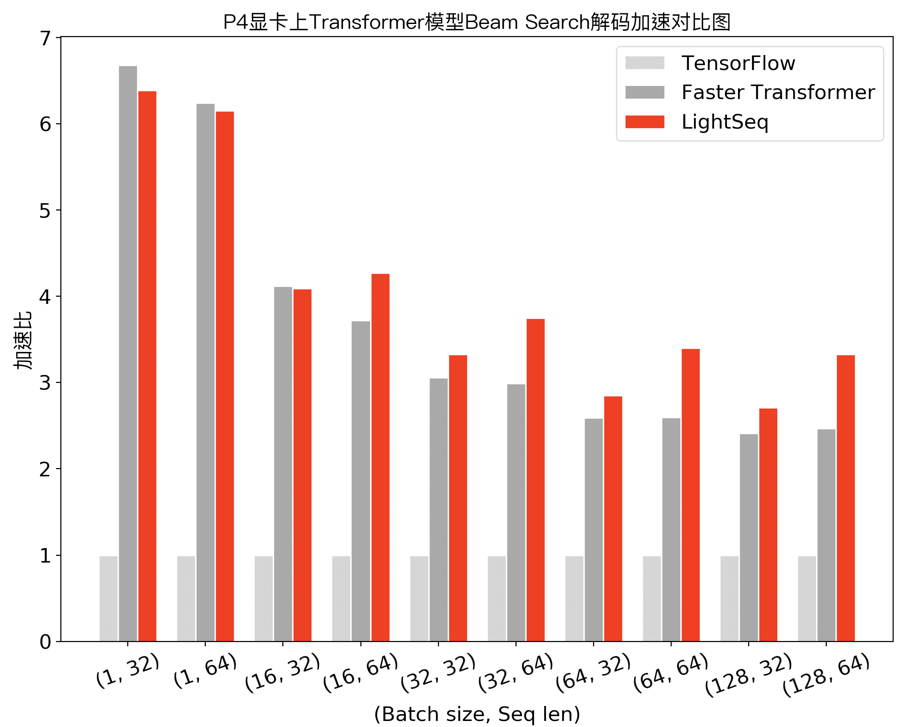
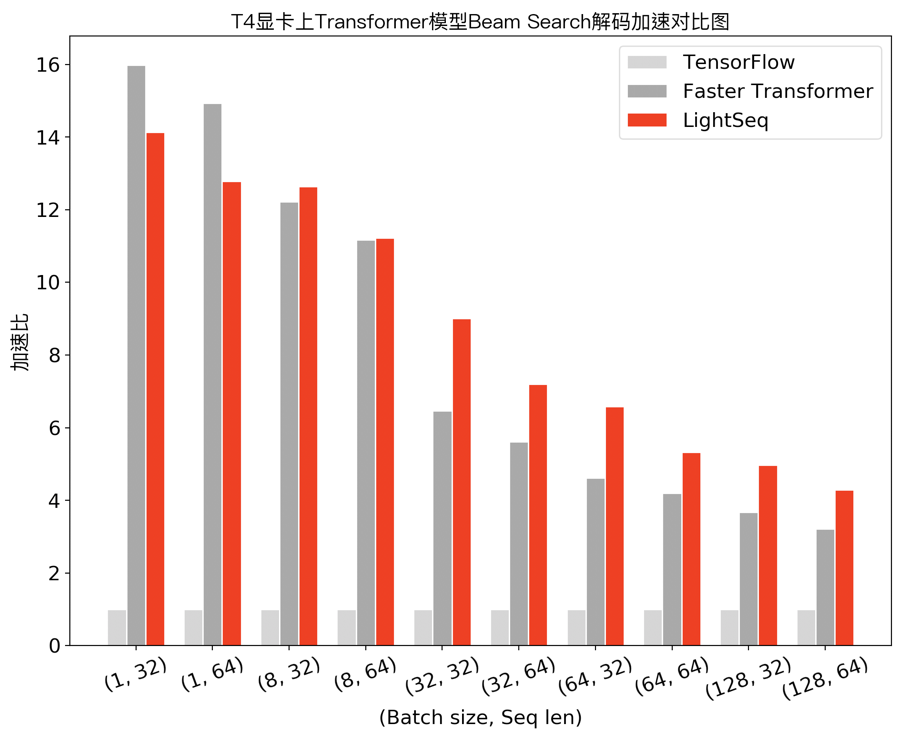
在机器翻译场景下,笔者测试了 Transformer base 模型(6层 encoder、6层 decoder 、隐层维度 512 )采用 beam search 解码的性能,实验结果如下:
![]()
![]()
可以发现,在小 batch 场景下,Faster Transformer 和 LightSeq 对比 Tensorflow 都达到了 10 倍左右的加速。而随着 batch 的增大,由于矩阵乘法运算占比越来越高,两者对 Tensorflow 的加速比都呈衰减趋势。LightSeq 衰减相对平缓,特别是在大 batch 场景下更加具有优势,最多能比 Faster Transformer 快 1.4 倍。这也对未来的一些推理优化工作提供了指导:小 batch 场景下,只要做好非计算密集型算子融合,就可以取得很高的加速收益;而大 batch 场景下则需要继续优化计算密集型算子,例如矩阵乘法等。
最后在 WMT14 标准的法英翻译任务上,笔者测试了 Transformer big 模型的性能。LightSeq 在 Tesla P4 显卡上平均每句翻译延迟为 167ms ,Tesla T4 上减小到了 82ms。而作为对比, TensorFlow 延迟均为 1071ms,LightSeq 分别达到了 6.41 和 13.06 倍加速。另外,笔者尝试了其他多种模型配置,得到了比较一致的加速效率。例如更深层的模型结构上(encoder加深至 16 层),LightSeq 得到的加速比,分别是 6.97 和 13.85 倍。
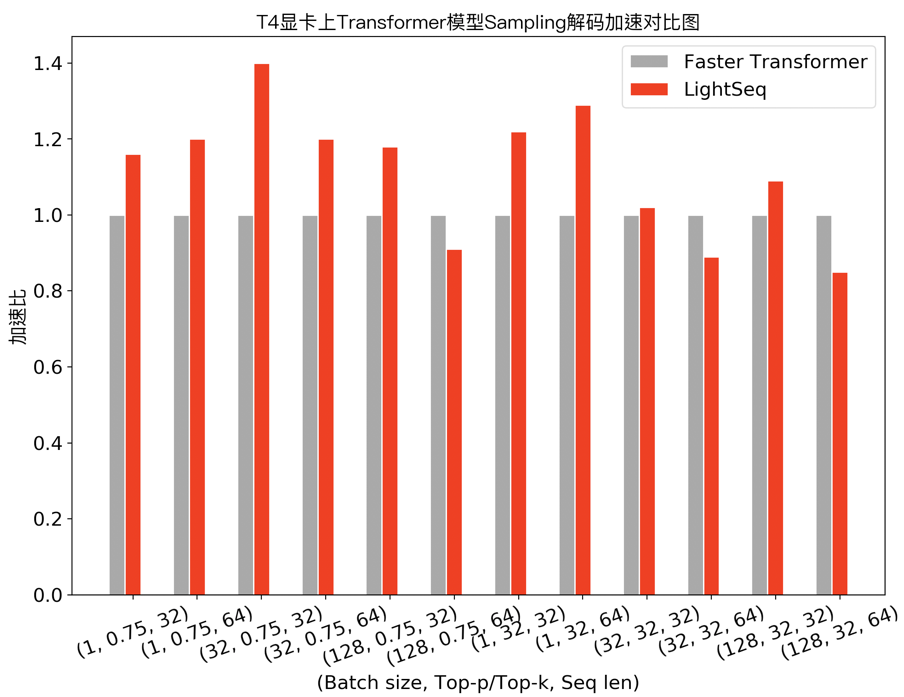
上述机器翻译通常采用 Beam Search 方法来解码, 而在文本生成场景,经常需要使用采样( Sampling )来提升生成结果的多样性。下图展示了 Transformer base 模型采用 top-k/top-p sampling 的性能测试对比:
![]()
可以发现,在需要使用采样解码的任务中,LightSeq 在大部分配置下领先于 Faster Transformer,最多也能达到 1.4 倍的额外加速。此外,相比于 TensorFlow 实现,LightSeq 对 GPT 和 VAE 等生成模型也达到了 5 倍以上的加速效果。
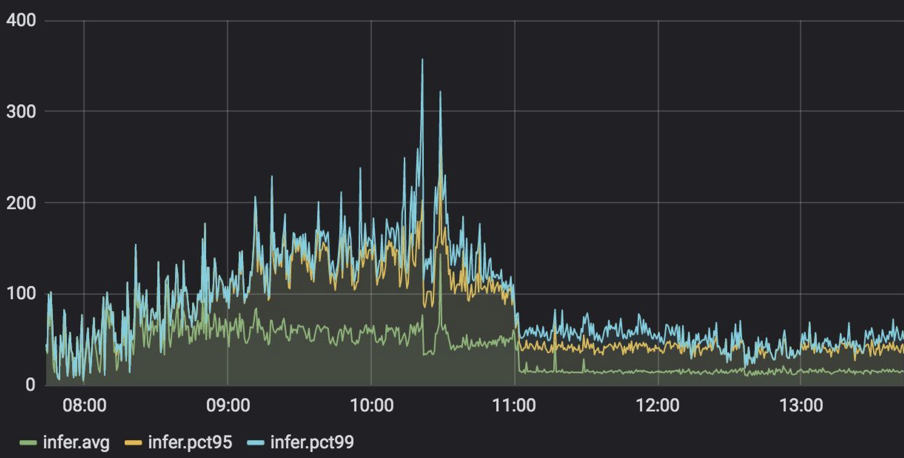
在云服务上,笔者测试了在实际应用中 GPT 场景下,模型服务从 Tensorflow 切换到LightSeq 的延迟变化情况(服务显卡使用 NVIDIA Tesla P4)。可以观察到,pct99 延迟降低了 3 到 5 倍,峰值从 360 毫秒左右下降到 80 毫秒左右,详细结果如下图所示:
![]()
更多的对比实验结果可以在 LightSeq 性能评测报告 [10] 中查看到。
![]()
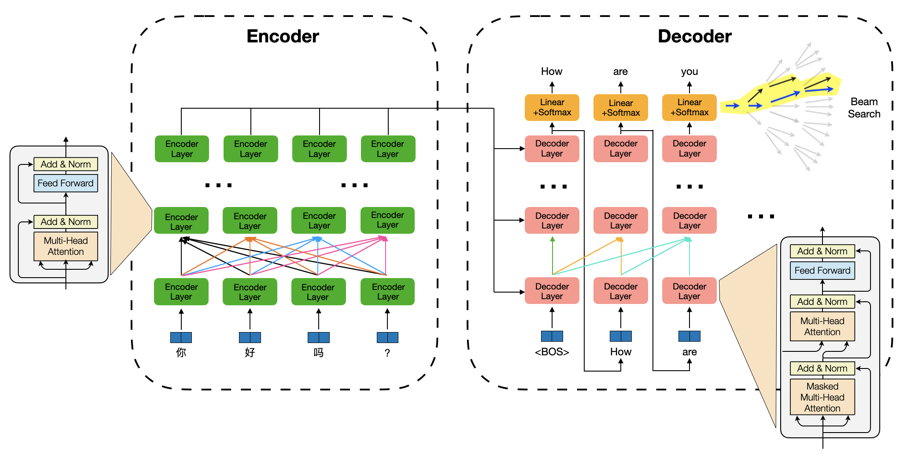
以 Transformer 为例,一个机器翻译/文本生成模型推理过程包括两部分:序列编码模块特征计算和自回归的解码算法。其中特征计算部分以自注意力机制及特征变换为核心(矩阵乘法,计算密集型),并伴随大量 Elementwise(如 Reshape)和 Reduce(如Layer Normalization)等 IO 密集型运算;解码算法部分包含了词表 Softmax、beam 筛选、缓存刷新等过程,运算琐碎,并引入了更复杂的动态 shape。这为模型推理带来了众多挑战:
1. IO 密集型计算的细粒度核函数调用带来大量冗余显存读写,成为特征计算性能瓶颈。
2. 复杂动态 shape 为计算图优化带来挑战,导致模型推理期间大量显存动态申请,耗时较高。
3. 解码生成每一步字符过程逻辑复杂,难以并行化计算从而发挥硬件优势。
LightSeq 取得这么好的推理加速效果,对这些挑战做了哪些针对性的优化呢?笔者分析发现,核心技术包括这几项:融合了多个运算操作来减少 IO 开销、复用显存来避免动态申请、解码算法进行层级式改写来提升推理速度。下面详细介绍下各部分的优化挑战和 LightSeq 的解决方法。
近年来,由于其高效的特征提取能力,Transformer encoder/decoder 结构被广泛应用于各种 NLP 任务中,例如海量无标注文本的预训练。而多数深度学习框架(例如 Tensorflow、Pytorch 等)通常都是调用基础运算库中的核函数(kernel function)来实现 encoder/decoder 计算过程。这些核函数往往粒度较细,通常一个组件需要调用多个核函数来实现。
以层归一化(Layer Normalization)为例,Tensorflow 是这样实现的:
mean = tf.reduce_mean(x, axis=[-1], keepdims=True)variance = tf.reduce_mean(tf.square(x - mean), axis=[-1], keepdims=True)result = (x - mean) * tf.rsqrt(variance + epsilon) * scale + bias
可以发现,即使基于编译优化技术(自动融合广播(Broadcast)操作和按元素(Elementwise)运算),也依然需要进行三次核函数调用(两次 reduce_mean,一次计算最终结果)和两次中间结果的显存读写(mean 和 variance)。而基于 CUDA,我们可以定制化一个层归一化专用的核函数,将两次中间结果的写入寄存器。从而实现一次核函数调用,同时没有中间结果显存读写,因此大大节省了计算开销。有兴趣的同学可以在文末参考链接中进一步查看具体实现[11]。
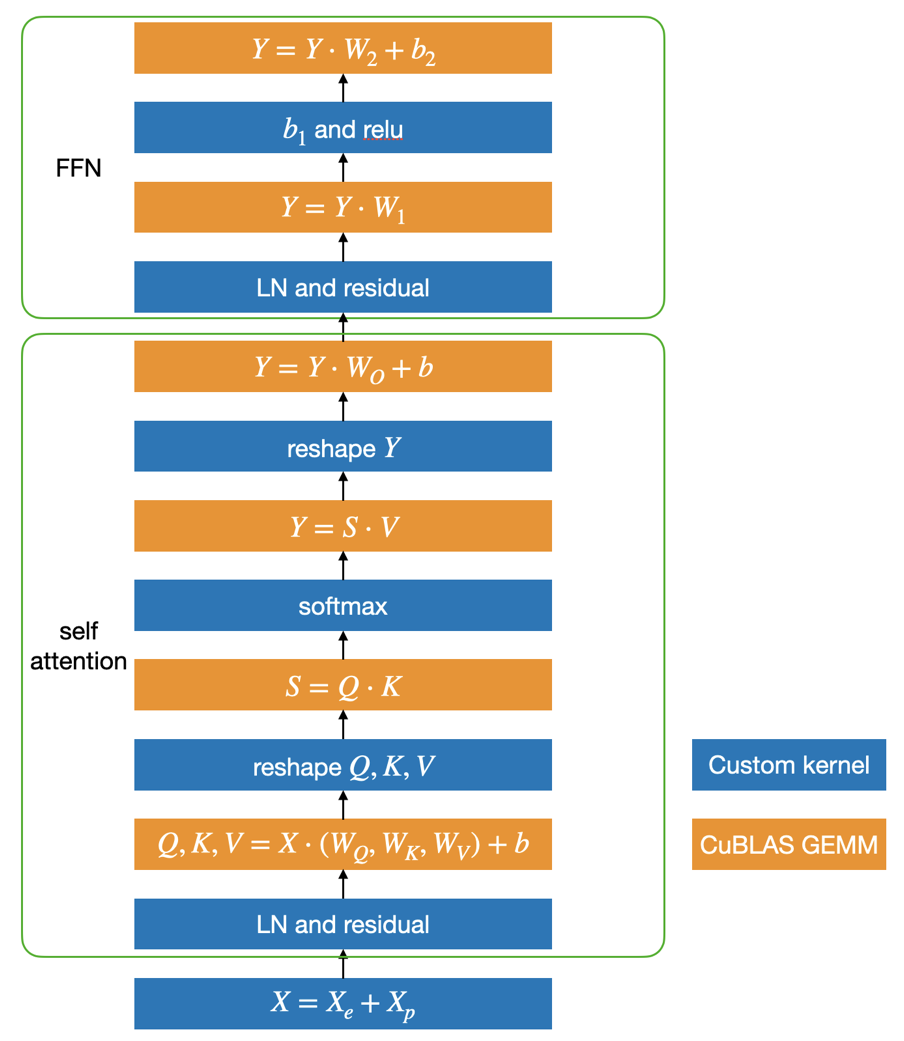
基于这个思路,LightSeq 利用 CUDA 矩阵运算库 cuBLAS[12]提供的矩阵乘法和自定义核函数实现了 Transformer,具体结构如下图所示:
![]()
蓝色部分是自定义核函数,黄色部分是矩阵乘法。可以发现,矩阵乘法之间的运算全部都用一个定制化核函数实现了,因此大大减少了核函数调用和显存读写,最终提升了运算速度。
为了避免计算过程中的显存申请释放并节省显存占用,LightSeq 首先对模型中所有动态的 shape 都定义了最大值(例如最大序列长度),将所有动态shape转换为静态。接着在服务启动的时候,为计算过程中的每个中间计算结果按最大值分配显存,并对没有依赖的中间结果共用显存。这样对每个请求,模型推理时不再申请显存,做到了:不同请求的相同 Tensor 复用显存;同请求的不同 Tensor 按 shape 及依赖关系复用显存。
通过该显存复用策略,在一张 T4 显卡上,LightSeq 可以同时部署多达 8 个 Transformer big 模型(batch_size=8,最大序列长度=8,beam_size=4,vocab_size=3万)。从而在低频或错峰等场景下,大大提升显卡利用率。
在自回归序列生成场景中,最复杂且耗时的部分就是解码。LightSeq 目前已经支持了 beam search、diversity beam search、top-k/top-p sampling 等多种解码方法,并且可以配合 Transformer、GPT使用,达到数倍加速。这里我们以应用最多的 beam search 为例,介绍一下 LightSeq 对解码过程的优化。
首先来看下在深度学习框架中传统是如何进行一步解码计算的:
# 1.计算以每个token为结尾的序列的log probability
log_token_prob = tf.nn.log_softmax(logit) log_seq_prob += log_token_prob log_seq_prob = tf.reshape(log_seq_prob, [-1, beam_size * vocab_size])
# 2. 为每个序列(batch element)找出排名topk的token
topk_log_probs, topk_indices = tf.nn.top_k(log_seq_prob, k=K)
# 3. 根据beam id,刷新decoder中的self attention模块中的key和value的缓存
refresh_cache(cache, topk_indices)
可以发现,为了挑选概率 top-k 的 token ,必须在 [batch_size, beam_size, vocab_size]大小的 logit 矩阵上进行 softmax 计算及显存读写,然后进行 batch_size 次排序。通常 vocab_size 都是在几万规模,因此计算量非常庞大,而且这仅仅只是一步解码的计算消耗。因此实践中也可以发现,解码模块在自回归序列生成任务中,累计延迟占比很高(超过 30%)。
LightSeq 的创新点在于结合 GPU 计算特性,借鉴搜索推荐中常用的粗选-精排的两段式策略,将解码计算改写成层级式,设计了一个 logit 粗选核函数,成功避免了 softmax 的计算及对十几万元素的排序。该粗选核函数遍历 logit 矩阵两次:
• 第一次遍历,对每个 beam,将其 logit 值随机分成k组,每组求最大值,然后对这k个最大值求一个最小值,作为一个近似的top-k值(一定小于等于真实top-k值),记为R-top-k。在遍历过程中,同时可以计算该beam中logit的log_sum_exp值。
• 第二次遍历,对每个 beam,找出所有大于等于 R-top-k 的 logit 值,将(logit - log_sum_exp + batch_id * offset, beam_id * vocab_size + vocab_id)写入候选队列,其中 offset 是 logit 的下界。
在第一次遍历中,logit 值通常服从正态分布,因此算出的R-top-k值非常接近真实top-k值。同时因为这一步只涉及到寄存器的读写,且算法复杂度低,因此可以快速执行完成(十几个指令周期)。实际观察发现,在top-4设置下,根据R-top-k只会从几万token中粗选出十几个候选,因此非常高效。第二次遍历中,根据R-top-k粗选出候选,同时对 logit 值按 batch_id 做了值偏移,多线程并发写入显存中的候选队列。
粗选完成后,在候选队列中进行一次排序,就能得到整个batch中每个序列的准确top-k值,然后更新缓存,一步解码过程就快速执行完成了。
下面是k=2,词表大小=8的情况下一个具体的示例(列代表第几个字符输出,行代表每个位置的候选
)。可以看出,原来需要对 16 个元素进行排序,而采用层级解码之后,最后只需要对 5 个元素排序即可,大大降低了排序的复杂度。
![]()
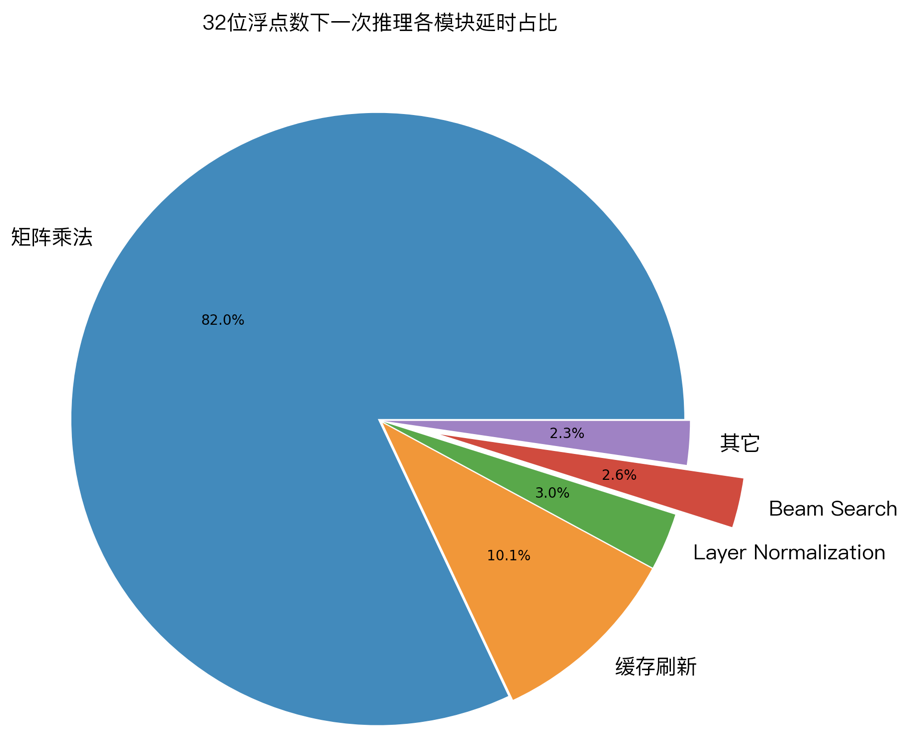
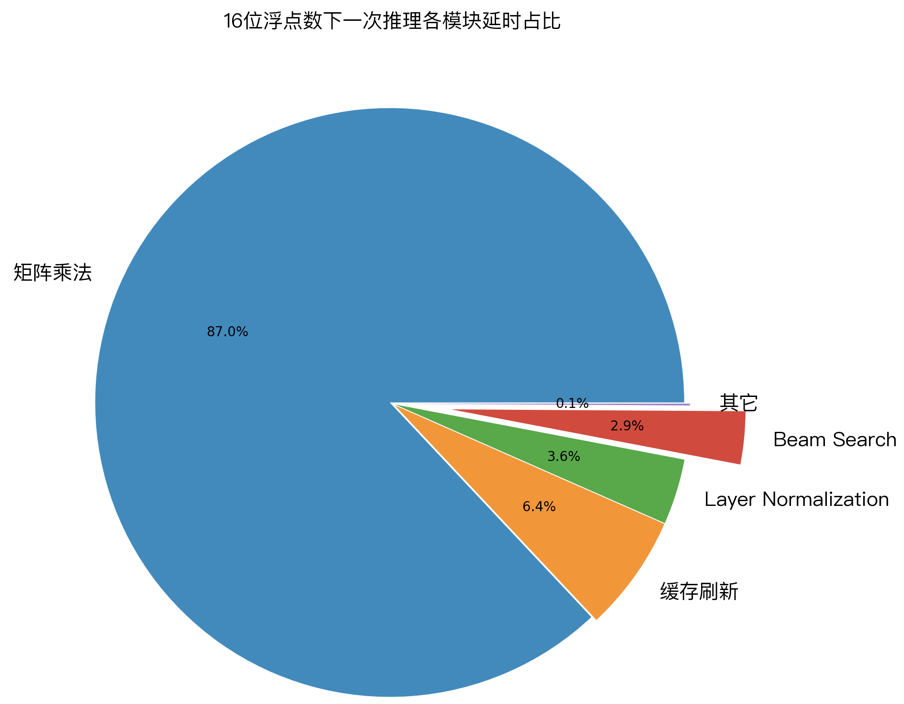
为了验证上面几种优化技术的实际效果,笔者用 GPU profile 工具,对 LightSeq 的一次推理过程进行了延迟分析。下图展示了 32 位浮点数和 16 位浮点数精度下,各计算模块的延迟占比:
![]()
![]()
1. 经过优化后,cuBLAS 中的矩阵乘法计算延迟分别占比 82% 和 88% ,成为推理加速新的主要瓶颈。而作为对比,我们测试了 Tensorflow 模型,矩阵乘法计算延迟只占了 25% 。这说明 LightSeq 的 beam search 优化已经将延迟降到了非常低的水平。
2. 缓存刷新分别占比 10% 和 6% ,比重也较高,但很难继续优化。今后可以尝试减少缓存量(如降低 decoder 层数,降低缓存精度等)来继续降低延迟。
3. 其他运算总计占比 8% 和 6% ,包括了 Layer Normalization、beam search 和中间结果的显存读写等。
可视化结果说明了 LightSeq 已经做到了极致优化,大大提升了推理速度。
https://github.com/bytedance/lightseq
[1] Vaswani, Ashish, et al. "Attention is all you need." Advances in neural information processing systems. 2017.
[2] Devlin, Jacob, et al. "Bert: Pre-training of deep bidirectional transformers for language understanding." arXiv preprint arXiv:1810.04805 (2018).
[3] Brown, Tom B., et al. "Language models are few-shot learners." arXiv preprint arXiv:2005.14165 (2020).
[4] WMT2020, http://www.statmt.org/wmt20/
[5] Li, Jiwei, Will Monroe, and Dan Jurafsky. "A simple, fast diverse decoding algorithm for neural generation." arXiv preprint arXiv:1611.08562 (2016).
[6] TurboTransformers, https://github.com/Tencent/TurboTransformers
[7] FasterTransformer, https://github.com/NVIDIA/DeepLearningExamples/tree/master/FasterTransformer
[8] NVIDIA Triton Inference Server, https://github.com/triton-inference-server/server
[9] LightSeq proto, https://github.com/bytedance/lightseq/tree/master/proto
[10] LightSeq性能评测报告, https://github.com/bytedance/lightseq/blob/master/docs/performance.md
[11] LightSeq Layer Normalization, https://github.com/bytedance/lightseq/blob/master/kernels/transformerKernels.cu.cc#L269
[12] cuBLAS, https://docs.nvidia.com/cuda/cublas/index.html
[13] GPT2,"Language Models are Unsupervised Multitask Learners"
近日,华为推出了MindSpore深度学习实战营,帮助小白更快的上手高性能深度学习框架。
扫描下图二维码,添加小助手微信:mindspore0328,备注21,完成报名。
![]()
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com