别再无聊地吹捧了,一起来动手实现MAE玩玩吧!

©作者 | CW不要無聊的風格
研究方向 | 目标检测、大规模预训练模型

前言

概述

好奇心:Why Masked Autoencoding?
Aided by the rapid gains in hardware, models today can easily overfit one million images and begin to demand hundreds of millions of—often publicly inaccessible—labeled images.

灵魂拷问:Why Masked Autoencoding In CV Lags Behind NLP?
progress of autoencoding methods in vision lags behind NLP.
We ask: what makes masked autoencoding different between vision and language?
Driven by this analysis, we present a simple, effective, and scalable form of a masked autoencoder (MAE) for visual representation learning.

With a vanilla ViT-Huge model, we achieve 87.8% accuracy when finetuned on ImageNet-1K. This outperforms all previous results that use only ImageNet-1K data.

具体方法
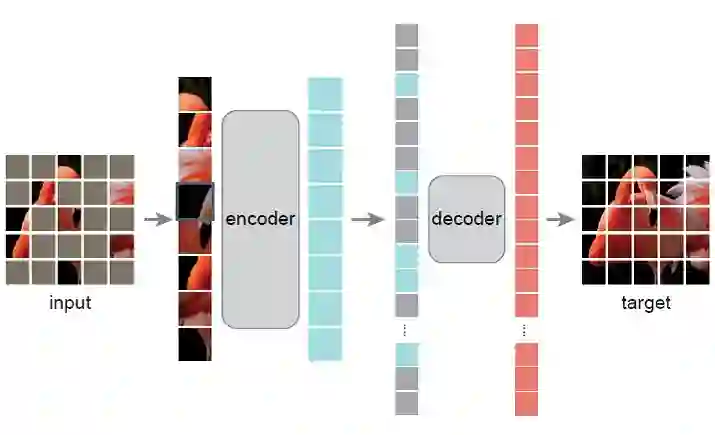
5.1 Mask 策略

5.2 Encoder
5.3 Decoder
5.4 任务目标:重建像素值
Computing the loss only on masked patches differs from traditional denoising autoencoders that compute the loss on all pixels. This choice is purely result-driven:
computing the loss on all pixels leads to a slight decrease in accuracy (e.g., ~0.5%).
5.5 Pipeline

实验理解
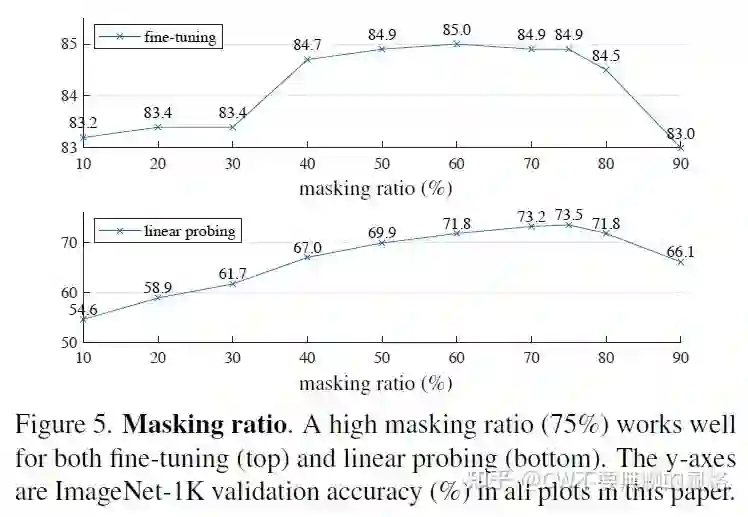
6.1 Mask 比例
6.2 Mask 采样策略

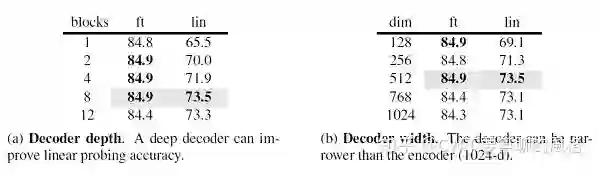
6.3 Decoder 的设计
6.4 Mask token 为何被 Encoder “抛弃”?

6.5 各种重建目标的比较
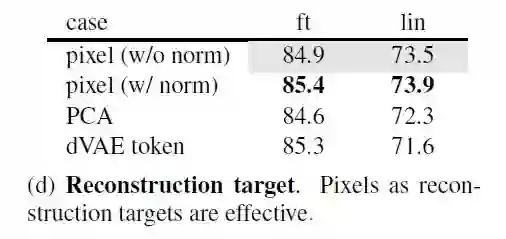
6.6 数据增强

6.7 干倒 linear probe

开局:源码实现
class MAE(nn.Module):
def __init__(
self, encoder, decoder_dim,
mask_ratio=0.75, decoder_depth=1,
num_decoder_heads=8, decoder_dim_per_head=64
):
super().__init__()
assert 0. < mask_ratio < 1., f'mask ratio must be kept between 0 and 1, got: {mask_ratio}'
# Encoder(这里 CW 用 ViT 实现)
self.encoder = encoder
self.patch_h, self.patch_w = encoder.patch_h, encoder.patch_w
# 由于原生的 ViT 有 cls_token,因此其 position embedding 的倒数第2个维度是:
# 实际划分的 patch 数量加上 1个 cls_token
num_patches_plus_cls_token, encoder_dim = encoder.pos_embed.shape[-2:]
# Input channels of encoder patch embedding: patch size**2 x 3
# 这个用作预测头部的输出通道,从而能够对 patch 中的所有像素值进行预测
num_pixels_per_patch = encoder.patch_embed.weight.size(1)
# Encoder-Decoder:Encoder 输出的维度可能和 Decoder 要求的输入维度不一致,因此需要转换
self.enc_to_dec = nn.Linear(encoder_dim, decoder_dim) if encoder_dim != decoder_dim else nn.Identity()
# Mask token
# 社会提倡这个比例最好是 75%
self.mask_ratio = mask_ratio
# mask token 的实质:1个可学习的共享向量
self.mask_embed = nn.Parameter(torch.randn(decoder_dim))
# Decoder:实质就是多层堆叠的 Transformer
self.decoder = Transformer(
decoder_dim,
decoder_dim * 4,
depth=decoder_depth,
num_heads=num_decoder_heads,
dim_per_head=decoder_dim_per_head,
)
# 在 Decoder 中用作对 mask tokens 的 position embedding
# Filter out cls_token 注意第1个维度去掉 cls_token
self.decoder_pos_embed = nn.Embedding(num_patches_plus_cls_token - 1, decoder_dim)
# Prediction head 输出的维度数等于1个 patch 的像素值数量
self.head = nn.Linear(decoder_dim, num_pixels_per_patch)
7.1 Patch Partition
num_patches = (h // self.patch_h) * (w // self.patch_w)
# (b, c=3, h, w)->(b, n_patches, patch_size**2 * c)
patches = x.view(
b, c,
h // self.patch_h, self.patch_h,
w // self.patch_w, self.patch_w
).permute(0, 2, 4, 3, 5, 1).reshape(b, num_patches, -1)
7.2 Masking
# 根据 mask 比例计算需要 mask 掉的 patch 数量
# num_patches = (h // self.patch_h) * (w // self.patch_w)
num_masked = int(self.mask_ratio * num_patches)
# Shuffle:生成对应 patch 的随机索引
# torch.rand() 服从均匀分布(normal distribution)
# torch.rand() 只是生成随机数,argsort() 是为了获得成索引
# (b, n_patches)
shuffle_indices = torch.rand(b, num_patches, device=device).argsort()
# mask 和 unmasked patches 对应的索引
mask_ind, unmask_ind = shuffle_indices[:, :num_masked], shuffle_indices[:, num_masked:]
# 对应 batch 维度的索引:(b,1)
batch_ind = torch.arange(b, device=device).unsqueeze(-1)
# 利用先前生成的索引对 patches 进行采样,分为 mask 和 unmasked 两组
mask_patches, unmask_patches = patches[batch_ind, mask_ind], patches[batch_ind, unmask_ind]
7.3 Encode
# 将 patches 通过 emebdding 转换成 tokens
unmask_tokens = self.encoder.patch_embed(unmask_patches)
# 为 tokens 加入 position embeddings
# 注意这里索引加1是因为索引0对应 ViT 的 cls_token
unmask_tokens += self.encoder.pos_embed.repeat(b, 1, 1)[batch_ind, unmask_ind + 1]
# 真正的编码过程
encoded_tokens = self.encoder.transformer(unmask_tokens)7.4 Decode
# 对编码后的 tokens 维度进行转换,从而符合 Decoder 要求的输入维度
enc_to_dec_tokens = self.enc_to_dec(encoded_tokens)
# 由于 mask token 实质上只有1个,因此要对其进行扩展,从而和 masked patches 一一对应
# (decoder_dim)->(b, n_masked, decoder_dim)
mask_tokens = self.mask_embed[None, None, :].repeat(b, num_masked, 1)
# 为 mask tokens 加入位置信息
mask_tokens += self.decoder_pos_embed(mask_ind)
# 将 mask tokens 与 编码后的 tokens 拼接起来
# (b, n_patches, decoder_dim)
concat_tokens = torch.cat([mask_tokens, enc_to_dec_tokens], dim=1)
# Un-shuffle:恢复原先 patches 的次序
dec_input_tokens = torch.empty_like(concat_tokens, device=device)
dec_input_tokens[batch_ind, shuffle_indices] = concat_tokens
# 将全量 tokens 喂给 Decoder 解码
decoded_tokens = self.decoder(dec_input_tokens)
7.5 Loss Computation
# 取出解码后的 mask tokens
dec_mask_tokens = decoded_tokens[batch_ind, mask_ind, :]
# 预测 masked patches 的像素值
# (b, n_masked, n_pixels_per_patch=patch_size**2 x c)
pred_mask_pixel_values = self.head(dec_mask_tokens)
# loss 计算
loss = F.mse_loss(pred_mask_pixel_values, mask_patches)
7.6 Reconstruction (Inference)
@torch.no_grad
def predict(self, x):
self.eval()
device = x.device
b, c, h, w = x.shape
'''i. Patch partition'''
num_patches = (h // self.patch_h) * (w // self.patch_w)
# (b, c=3, h, w)->(b, n_patches, patch_size**2*c)
patches = x.view(
b, c,
h // self.patch_h, self.patch_h,
w // self.patch_w, self.patch_w
).permute(0, 2, 4, 3, 5, 1).reshape(b, num_patches, -1)
'''ii. Divide into masked & un-masked groups'''
num_masked = int(self.mask_ratio * num_patches)
# Shuffle
# (b, n_patches)
shuffle_indices = torch.rand(b, num_patches, device=device).argsort()
mask_ind, unmask_ind = shuffle_indices[:, :num_masked], shuffle_indices[:, num_masked:]
# (b, 1)
batch_ind = torch.arange(b, device=device).unsqueeze(-1)
mask_patches, unmask_patches = patches[batch_ind, mask_ind], patches[batch_ind, unmask_ind]
'''iii. Encode'''
unmask_tokens = self.encoder.patch_embed(unmask_patches)
# Add position embeddings
unmask_tokens += self.encoder.pos_embed.repeat(b, 1, 1)[batch_ind, unmask_ind + 1]
encoded_tokens = self.encoder.transformer(unmask_tokens)
'''iv. Decode'''
enc_to_dec_tokens = self.enc_to_dec(encoded_tokens)
# (decoder_dim)->(b, n_masked, decoder_dim)
mask_tokens = self.mask_embed[None, None, :].repeat(b, num_masked, 1)
# Add position embeddings
mask_tokens += self.decoder_pos_embed(mask_ind)
# (b, n_patches, decoder_dim)
concat_tokens = torch.cat([mask_tokens, enc_to_dec_tokens], dim=1)
# dec_input_tokens = concat_tokens
dec_input_tokens = torch.empty_like(concat_tokens, device=device)
# Un-shuffle
dec_input_tokens[batch_ind, shuffle_indices] = concat_tokens
decoded_tokens = self.decoder(dec_input_tokens)
'''v. Mask pixel Prediction'''
dec_mask_tokens = decoded_tokens[batch_ind, mask_ind, :]
# (b, n_masked, n_pixels_per_patch=patch_size**2 x c)
pred_mask_pixel_values = self.head(dec_mask_tokens)
# 比较下预测值和真实值
mse_per_patch = (pred_mask_pixel_values - mask_patches).abs().mean(dim=-1)
mse_all_patches = mse_per_patch.mean()
print(f'mse per (masked)patch: {mse_per_patch} mse all (masked)patches: {mse_all_patches} total {num_masked} masked patches')
print(f'all close: {torch.allclose(pred_mask_pixel_values, mask_patches, rtol=1e-1, atol=1e-1)}')
'''vi. Reconstruction'''
recons_patches = patches.detach()
# Un-shuffle (b, n_patches, patch_size**2 * c)
recons_patches[batch_ind, mask_ind] = pred_mask_pixel_values
# 模型重建的效果图
# Reshape back to image
# (b, n_patches, patch_size**2 * c)->(b, c, h, w)
recons_img = recons_patches.view(
b, h // self.patch_h, w // self.patch_w,
self.patch_h, self.patch_w, c
).permute(0, 5, 1, 3, 2, 4).reshape(b, c, h, w)
mask_patches = torch.randn_like(mask_patches, device=mask_patches.device)
# mask 效果图
patches[batch_ind, mask_ind] = mask_patches
patches_to_img = patches.view(
b, h // self.patch_h, w // self.patch_w,
self.patch_h, self.patch_w, c
).permute(0, 5, 1, 3, 2, 4).reshape(b, c, h, w)
return recons_img, patches_to_img
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# 读入图像并缩放到适合模型输入的尺寸
from PIL import Image
img_raw = Image.open(os.path.join(BASE_DIR, 'mountain.jpg'))
h, w = img_raw.height, img_raw.width
ratio = h / w
print(f"image hxw: {h} x {w} mode: {img_raw.mode}")
img_size, patch_size = (224, 224), (16, 16)
img = img_raw.resize(img_size)
rh, rw = img.height, img.width
print(f'resized image hxw: {rh} x {rw} mode: {img.mode}')
img.save(os.path.join(BASE_DIR, 'resized_mountain.jpg'))
# 将图像转换成张量
from torchvision.transforms import ToTensor, ToPILImage
img_ts = ToTensor()(img).unsqueeze(0).to(device)
print(f"input tensor shape: {img_ts.shape} dtype: {img_ts.dtype} device: {img_ts.device}")
# 实例化模型并加载训练好的权重
encoder = ViT(img_size, patch_size, dim=512, mlp_dim=1024, dim_per_head=64)
decoder_dim = 512
mae = MAE(encoder, decoder_dim, decoder_depth=6)
weight = torch.load(os.path.join(BASE_DIR, 'mae.pth'), map_location='cpu')
mae.to(device)
# 推理
# 模型重建的效果图,mask 效果图
recons_img_ts, masked_img_ts = mae.predict(img_ts)
recons_img_ts, masked_img_ts = recons_img_ts.cpu().squeeze(0), masked_img_ts.cpu().squeeze(0)
# 将结果保存下来以便和原图比较
recons_img = ToPILImage()(recons_img_ts)
recons_img.save(os.path.join(BASE_DIR, 'recons_mountain.jpg'))
masked_img = ToPILImage()(masked_img_ts)
masked_img.save(os.path.join(BASE_DIR, 'masked_mountain.jpg'))

▲ 原图

▲ mask(ratio=75%)图

▲ 模型重建效果

附录
import torch
import torch.nn as nn
def to_pair(t):
return t if isinstance(t, tuple) else (t, t)
class PreNorm(nn.Module):
def __init__(self, dim, net):
super().__init__()
self.norm = nn.LayerNorm(dim)
self.net = net
def forward(self, x, **kwargs):
return self.net(self.norm(x), **kwargs)
class SelfAttention(nn.Module):
def __init__(self, dim, num_heads=8, dim_per_head=64, dropout=0.):
super().__init__()
self.num_heads = num_heads
self.scale = dim_per_head ** -0.5
inner_dim = dim_per_head * num_heads
self.to_qkv = nn.Linear(dim, inner_dim * 3, bias=False)
self.attend = nn.Softmax(dim=-1)
project_out = not (num_heads == 1 and dim_per_head == dim)
self.out = nn.Sequential(
nn.Linear(inner_dim, dim),
nn.Dropout(dropout)
) if project_out else nn.Identity()
def forward(self, x):
b, l, d = x.shape
'''i. QKV projection'''
# (b,l,dim_all_heads x 3)
qkv = self.to_qkv(x)
# (3,b,num_heads,l,dim_per_head)
qkv = qkv.view(b, l, 3, self.num_heads, -1).permute(2, 0, 3, 1, 4).contiguous()
# 3 x (1,b,num_heads,l,dim_per_head)
q, k, v = qkv.chunk(3)
q, k, v = q.squeeze(0), k.squeeze(0), v.squeeze(0)
'''ii. Attention computation'''
attn = self.attend(
torch.matmul(q, k.transpose(-1, -2)) * self.scale
)
'''iii. Put attention on Value & reshape'''
# (b,num_heads,l,dim_per_head)
z = torch.matmul(attn, v)
# (b,num_heads,l,dim_per_head)->(b,l,num_heads,dim_per_head)->(b,l,dim_all_heads)
z = z.transpose(1, 2).reshape(b, l, -1)
# assert z.size(-1) == q.size(-1) * self.num_heads
'''iv. Project out'''
# (b,l,dim_all_heads)->(b,l,dim)
out = self.out(z)
# assert out.size(-1) == d
return out
class FFN(nn.Module):
def __init__(self, dim, hidden_dim, dropout=0.):
super().__init__()
self.net = nn.Sequential(
nn.Linear(dim, hidden_dim),
nn.GELU(),
nn.Dropout(p=dropout),
nn.Linear(hidden_dim, dim),
nn.Dropout(p=dropout)
)
def forward(self, x):
return self.net(x)
class Transformer(nn.Module):
def __init__(self, dim, mlp_dim, depth=6, num_heads=8, dim_per_head=64, dropout=0.):
super().__init__()
self.layers = nn.ModuleList([])
for _ in range(depth):
self.layers.append(nn.ModuleList([
PreNorm(dim, SelfAttention(dim, num_heads=num_heads, dim_per_head=dim_per_head, dropout=dropout)),
PreNorm(dim, FFN(dim, mlp_dim, dropout=dropout))
]))
def forward(self, x):
for norm_attn, norm_ffn in self.layers:
x = x + norm_attn(x)
x = x + norm_ffn(x)
return x
class ViT(nn.Module):
def __init__(
self, image_size, patch_size,
num_classes=1000, dim=1024, depth=6, num_heads=8, mlp_dim=2048,
pool='cls', channels=3, dim_per_head=64, dropout=0., embed_dropout=0.
):
super().__init__()
img_h, img_w = to_pair(image_size)
self.patch_h, self.patch_w = to_pair(patch_size)
assert not img_h % self.patch_h and not img_w % self.patch_w, \
f'Image dimensions ({img_h},{img_w}) must be divisible by the patch size ({self.patch_h},{self.patch_w}).'
num_patches = (img_h // self.patch_h) * (img_w // self.patch_w)
assert pool in {'cls', 'mean'}, f'pool type must be either cls (cls token) or mean (mean pooling), got: {pool}'
patch_dim = channels * self.patch_h * self.patch_w
self.patch_embed = nn.Linear(patch_dim, dim)
self.cls_token = nn.Parameter(torch.randn(1, 1, dim))
# Add 1 for cls_token
self.pos_embed = nn.Parameter(torch.randn(1, num_patches + 1, dim))
self.dropout = nn.Dropout(p=embed_dropout)
self.transformer = Transformer(
dim, mlp_dim, depth=depth, num_heads=num_heads,
dim_per_head=dim_per_head, dropout=dropout
)
self.pool = pool
self.mlp_head = nn.Sequential(
nn.LayerNorm(dim),
nn.Linear(dim, num_classes)
)
def forward(self, x):
b, c, img_h, img_w = x.shape
assert not img_h % self.patch_h and not img_w % self.patch_w, \
f'Input image dimensions ({img_h},{img_w}) must be divisible by the patch size ({self.patch_h},{self.patch_w}).'
'''i. Patch partition'''
num_patches = (img_h // self.patch_h) * (img_w // self.patch_w)
# (b,c,h,w)->(b,n_patches,patch_h*patch_w*c)
patches = x.view(
b, c,
img_h // self.patch_h, self.patch_h,
img_w // self.patch_w, self.patch_w
).permute(0, 2, 4, 3, 5, 1).reshape(b, num_patches, -1)
'''ii. Patch embedding'''
# (b,n_patches,dim)
tokens = self.patch_embed(patches)
# (b,n_patches+1,dim)
tokens = torch.cat([self.cls_token.repeat(b, 1, 1), tokens], dim=1)
tokens += self.pos_embed[:, :(num_patches + 1)]
tokens = self.dropout(tokens)
'''iii. Transformer Encoding'''
enc_tokens = self.transformer(tokens)
'''iv. Pooling'''
# (b,dim)
pooled = enc_tokens[:, 0] if self.pool == 'cls' else enc_tokens.mean(dim=1)
'''v. Classification'''
# (b,n_classes)
logits = self.mlp_head(pooled)
return logits

End
特别鸣谢
感谢 TCCI 天桥脑科学研究院对于 PaperWeekly 的支持。TCCI 关注大脑探知、大脑功能和大脑健康。
更多阅读




#投 稿 通 道#
让你的文字被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
📝 稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
📬 投稿通道:
• 投稿邮箱:hr@paperweekly.site
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿

△长按添加PaperWeekly小编
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧



