GluonCV 0.8 助力街景分析
街景分析是计算机视觉应用最广泛的一个领域之一,越来越多的项目正在围绕街景展开,比如生成一个交互式的虚拟城市,建造一个属于自己的无人车等等。最近,OpenBot项目的推出大大降低了小机器人成本。一部旧的智能手机加上一个电动车身,不到 400 软妹币,你就可以造出一个先进的小机器人,行人跟踪和自主导航都不在话下。想必很多人都很心动,正准备打造一个属于自己的无人车吧。基于这波热潮,我们在 GluonCV 最新发布的 0.8 版中引入了一个新的任务:深度估计。同时,这次发布还有更多的语义分割模型,一起助力街景分析。
深度估计
场景深度估计是一个经典的计算机视觉问题,是从平面图片中推测场景几何关系的重要一步。它的目的就是要去预测平面图片中每个像素的深度,简单地说,就是每个像素离你有多远。一旦有了精确的深度估计,你的无人车就能很大程度上做到避撞了。废话不多说,上图为证:

最近,自监督深度估计取得了重大的进展,尤其是 monodepth2[1] 这个代表性的工作,深受广大从业者好评。于是,我们在 GluonCV 0.8 中提供了 monodepth2 的各种实现,包括单目,双目,单双目混合的三种模式。我们的模型完美复现了作者论文中的效果,同时还提供训练日志当做参考,免去大家复现的烦恼。
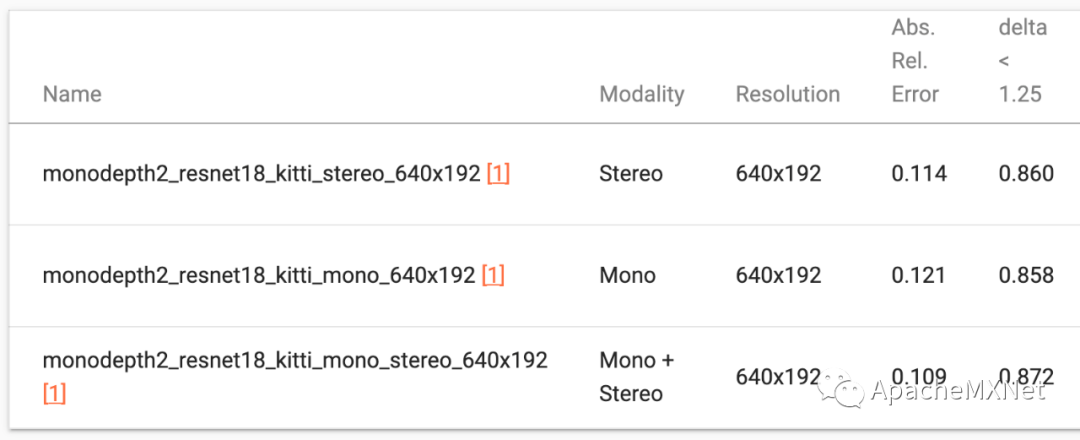
为了帮助大家快速上车,我们还提供了一系列的教程,包括如何估计一张图的深度信息,如何分析一段视频的深度信息,如何训练一个 monodepth2 的模型以及如何使用 PoseNet 去估计物体在一段视频中的轨迹。感兴趣的小伙伴现在就可以试起来啦。
更多更快的语义分割模型
语义分割一直是街景分析中的重头戏。很多算法不仅可以做语义分割,也可以直接拿来做可驾驶道路检测。深度估计配上语义分割,你的无人车离自主导航就不远了。在这次 GluonCV 0.8 的发布中,我们引入了一个更强的模型 DANet[2] 和一个更快的模型 FastSCNN[3],满足你的各种需求。且看他们在 Cityscapes 数据集上的表现:
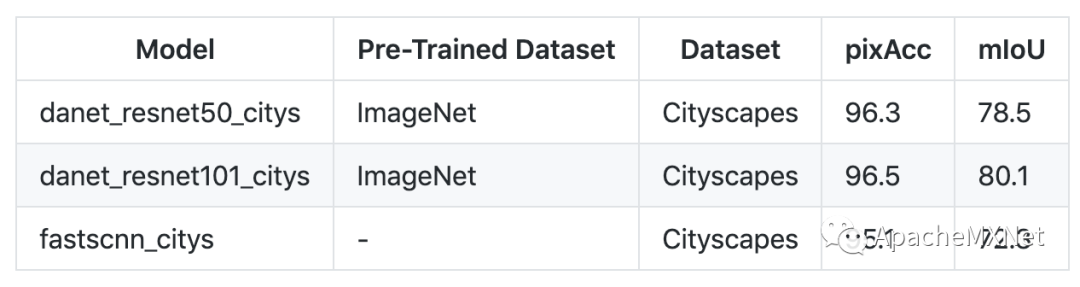
需要特别指出的是,表中的 FastSCNN 模型得到了我们最新论文的加持,通过半监督学习生成大量伪标签,在不使用任何额外标注数据的情况下就能得到高达 72.3 的 mIoU,这个数字远高于原文中的 68.6。在 V100 显卡上,FastSCNN 可以在 1024x2048 的视频上跑到 80fps,是部署到小机器人上的不二人选。近期我们还会发布论文中的另一个强力实时模型,达到 78.3 mIoU 的 BiSeNet,敬请期待。

想在你的数据集上训练分割模型?没问题,我们也提供了大量教程。同时,你也可以尝试我们最新论文中的方法,只需少量标注数据,就可以训练一个相当不错的分割模型,具体细节请猛戳论文[4]。
结语
本次 GluonCV 0.8 囊括了 monodepth2,DANet 和 FastSCNN 三个算法,可以顺利帮你分析街景,造一个属于你自己的无人车。然而我们想说的是,这些算法本身是通用的,并不局限于街景分析,比如你也可以用我们的代码训练室内深度估计模型。所以欢迎多多关注使用 GluonCV,也欢迎给我们留 issue 开 PR,感谢小伙伴们一直以来的支持!
相关链接
[1] https://arxiv.org/abs/1806.01260
[2] https://arxiv.org/abs/1809.02983
[3] https://arxiv.org/abs/1902.04502
[4] https://arxiv.org/abs/2004.14960
喜欢我们的工作并且希望支持更多的更新,欢迎点赞加星 Fork!



