加上Web UI,文本-图像模型Stable Diffusion变身绘图工具,生成艺术大片
机器之心报道
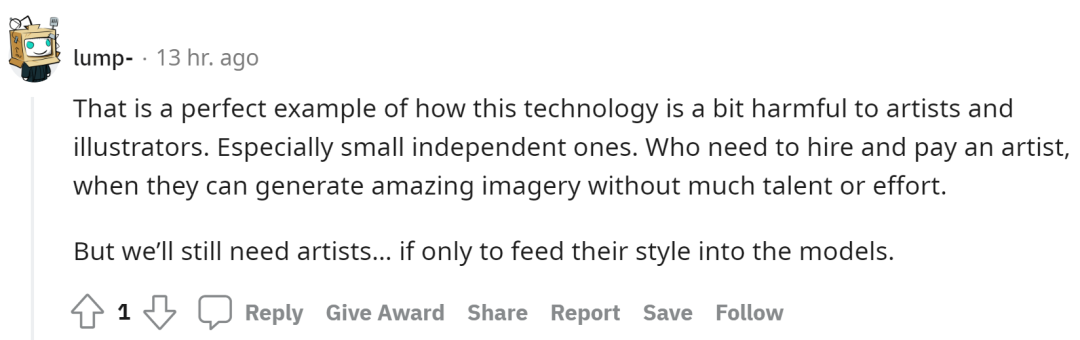
对于艺术家和插图画家来说,这类绘图工具虽然省时省力,但如何保持自己的创作风格是一个大问题。
Stable Diffusion 可以在消费级 GPU 上的 10 GB VRAM 下运行,并在几秒钟内生成 512x512 像素的图像,无需预处理和后处理。
Stable Diffusion的生成效果是这样的。宇宙的演变:


-
项目地址: https://github.com/hlky/stable-diffusion -
Docker镜像: https://github.com/AbdBarho/stable-diffusion-webui-docker



不过想要实现上述效果,还需要Gradio库,这是一个免费、开源的Python库,它允许用户为机器学习模型开发易于使用的可定制组件演示,还可以帮助用户构建一个可以互动的网络应用。
不过带有Gradio UI的原始脚本是由一位匿名用户编写的,现在该项目进行了一些修改:
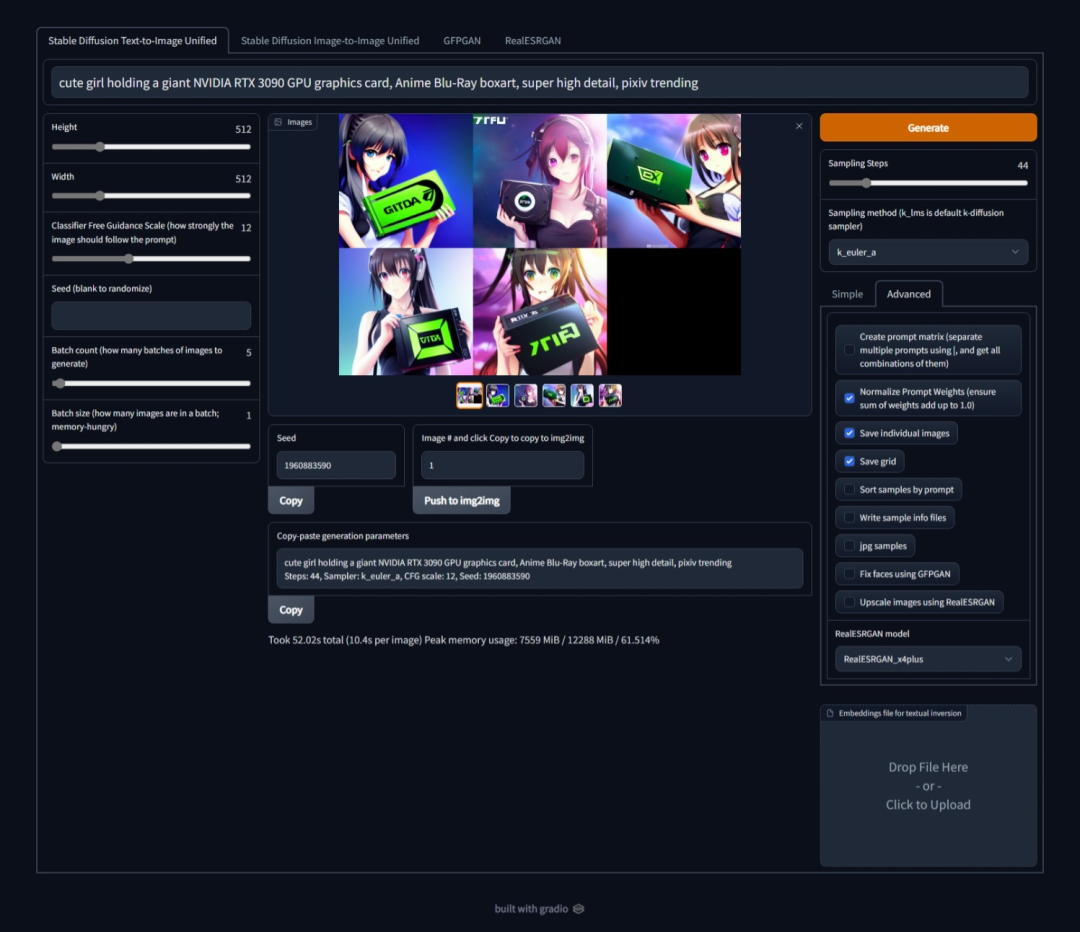
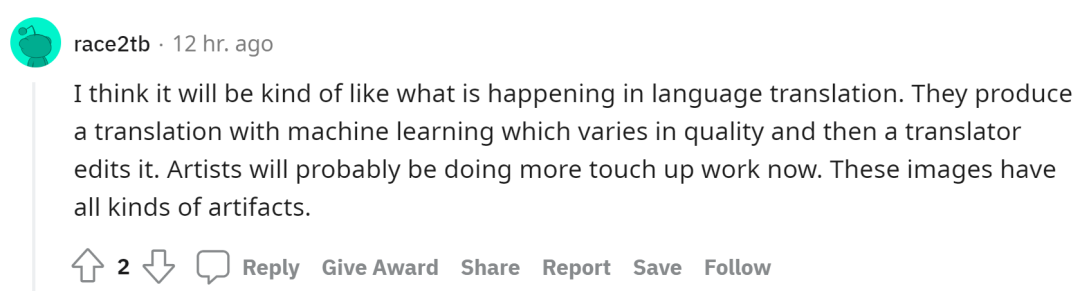
网友:文本转图像模型有利有弊
掌握「声纹识别技术」:前20小时交给我,后9980小时……
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com
登录查看更多
相关内容
Arxiv
0+阅读 · 2022年11月28日
Arxiv
0+阅读 · 2022年11月25日

相关VIP内容
相关资讯
相关论文
Arxiv
0+阅读 · 2022年11月28日
Arxiv
0+阅读 · 2022年11月25日