一文概览神经网络的激活函数:从ReLU到GELU
点击上方“CVer”,选择“置顶公众号”
重磅干货,第一时间送达

本文转载自:机器之心
作者:Casper Hansen | 参与:熊猫、杜伟
激活函数对神经网络的重要性自不必多言,CVer也曾转载过一些相关的介绍文章,比如《 一文概览深度学习中的激活函数》。本文同样关注的是激活函数。来自丹麦技术大学的 Casper Hansen 通过公式、图表和代码实验介绍了 sigmoid、ReLU、ELU 以及更新的 Leaky ReLU、SELU、GELU 这些激活函数,并比较了它们的优势和短板。

概述
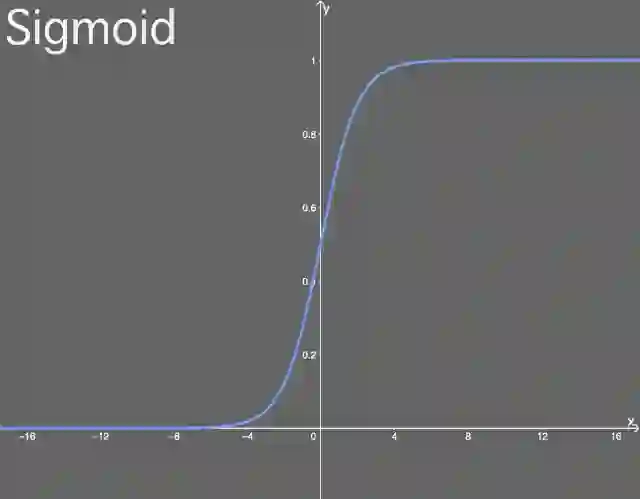
sigmoid 函数是什么?
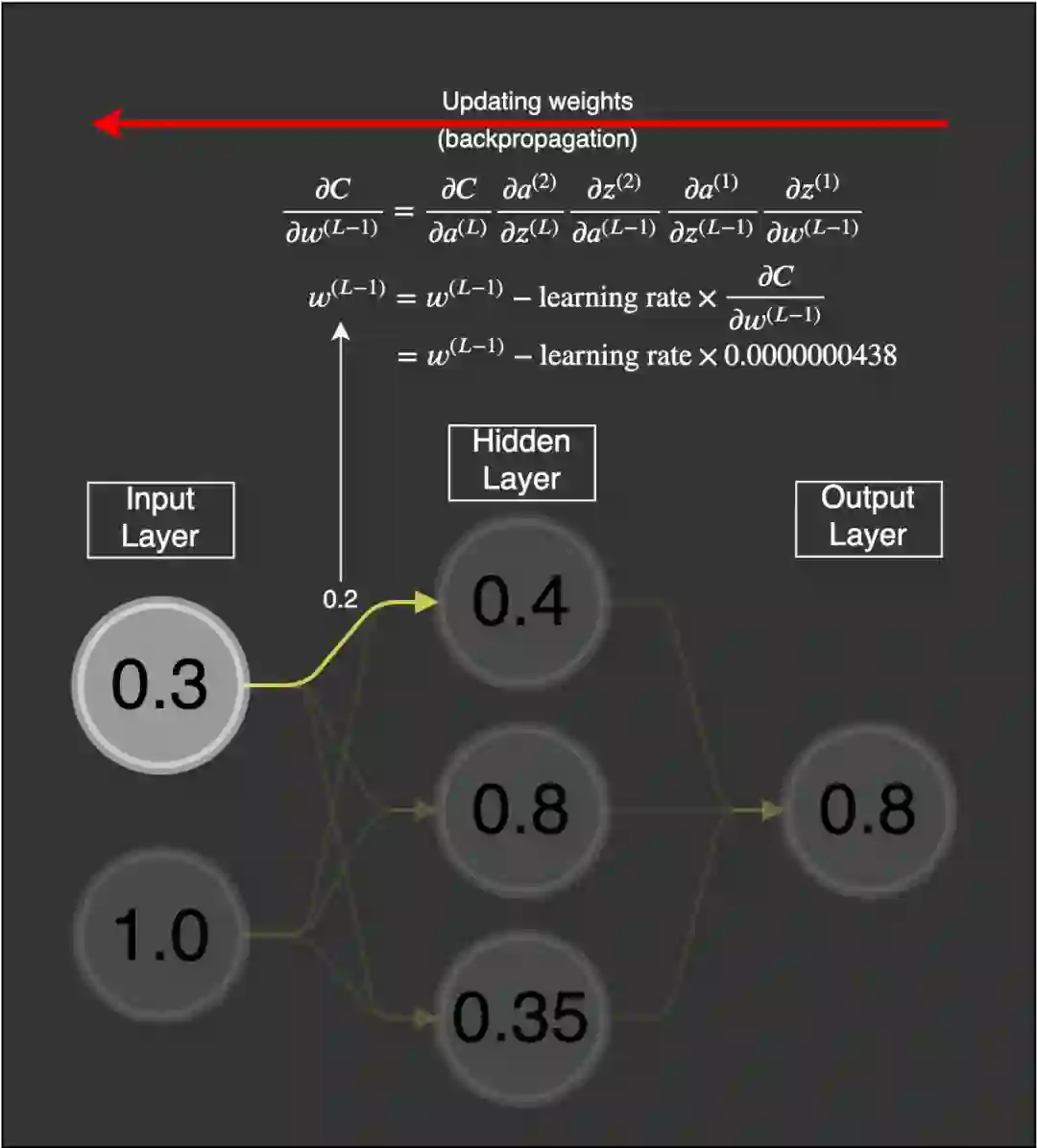
梯度问题:反向传播
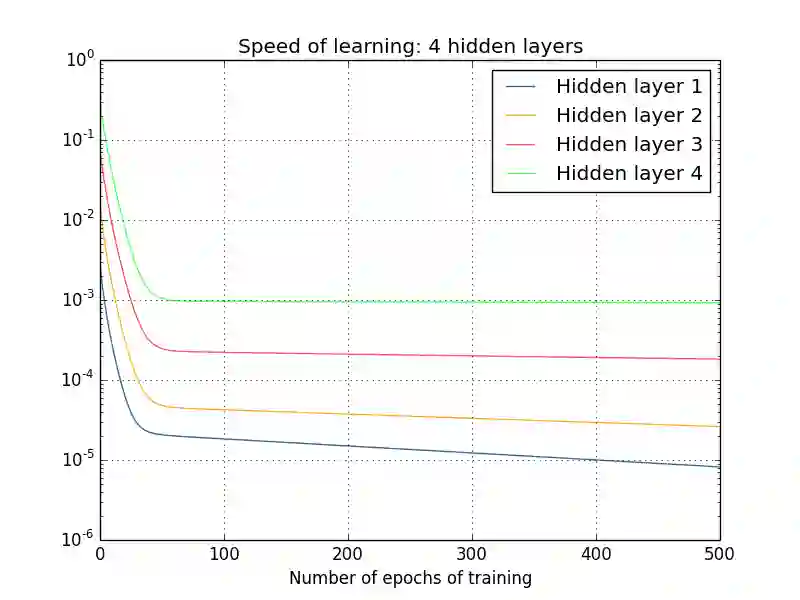
梯度消失问题
梯度爆炸问题
梯度爆炸的极端案例
避免梯度爆炸:梯度裁剪/范数
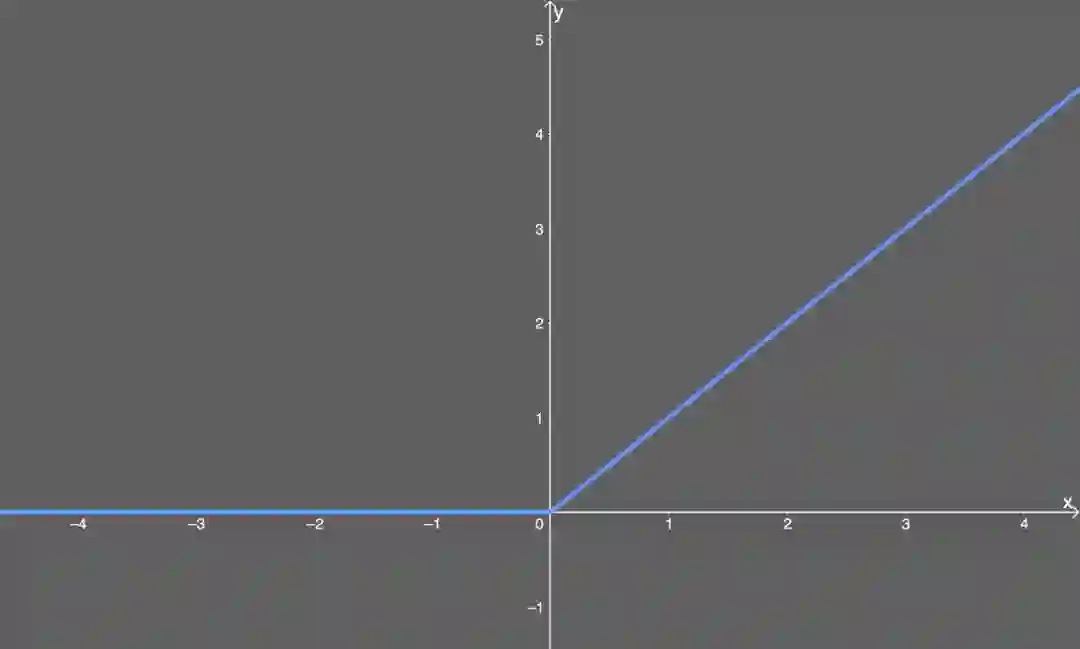
整流线性单元(ReLU)
死亡 ReLU:优势和缺点
指数线性单元(ELU)
渗漏型整流线性单元(Leaky ReLU)
扩展型指数线性单元(SELU)
SELU:归一化的特例
权重初始化+dropout
高斯误差线性单元(GELU)
代码:深度神经网络的超参数搜索
扩展阅读:书籍与论文
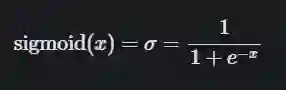

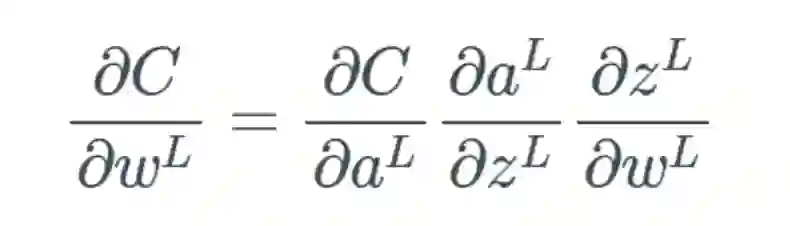
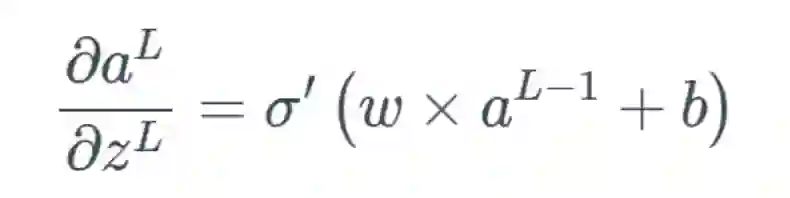
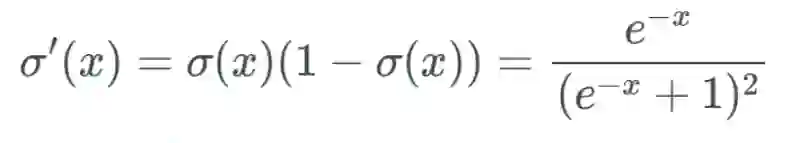
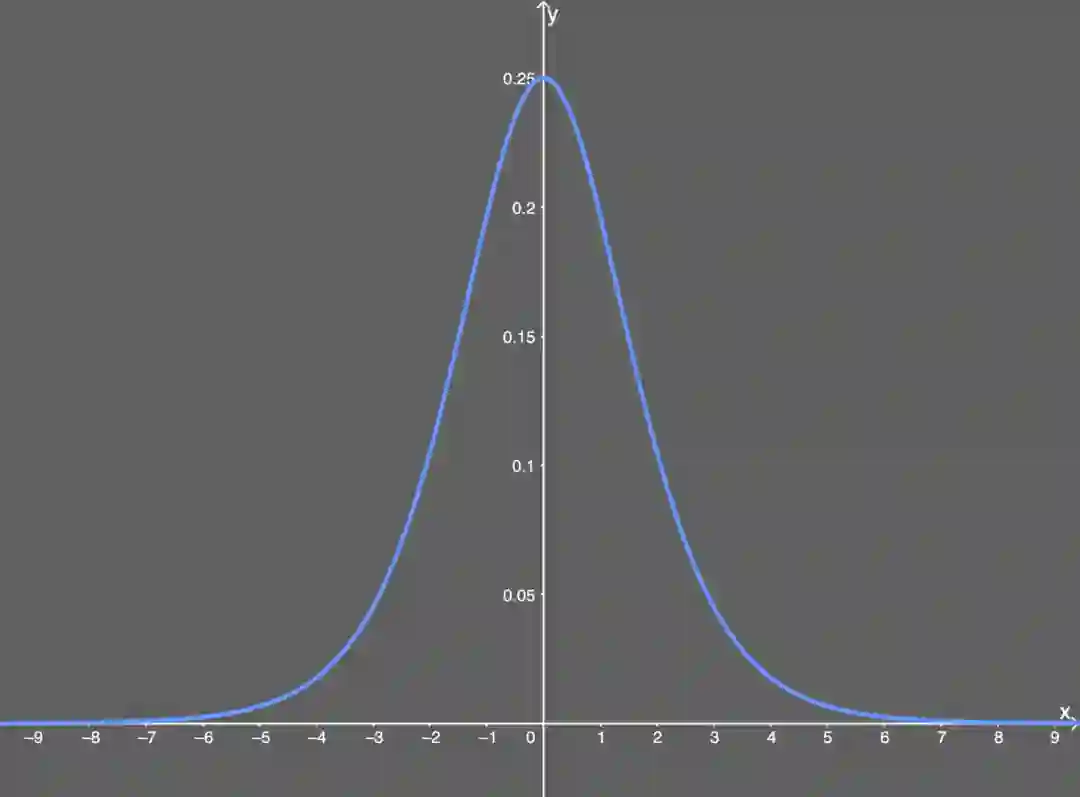
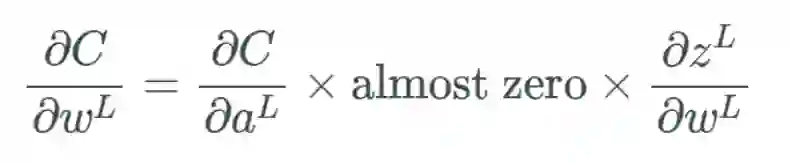
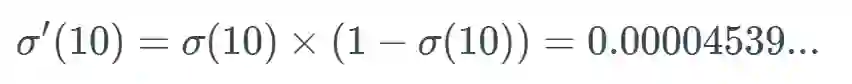

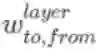 的表示方式将其记为
的表示方式将其记为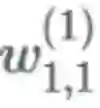

假设这个权重的值为 0.2,给定一个学习率(具体多少不重要,这里使用了 0.5),则新的权重为:
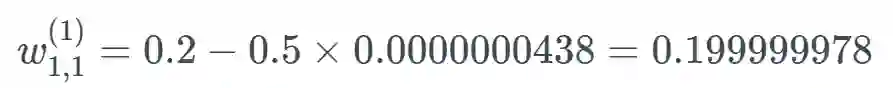
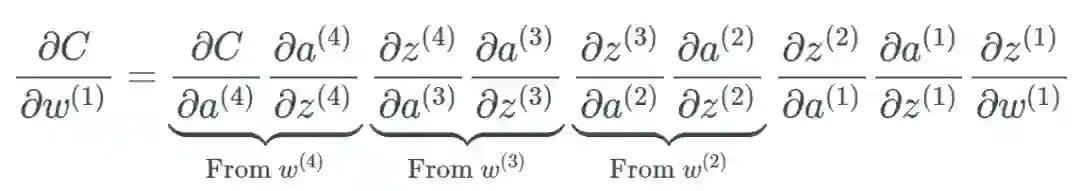
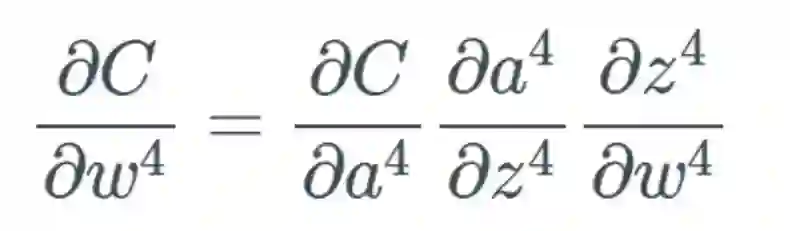
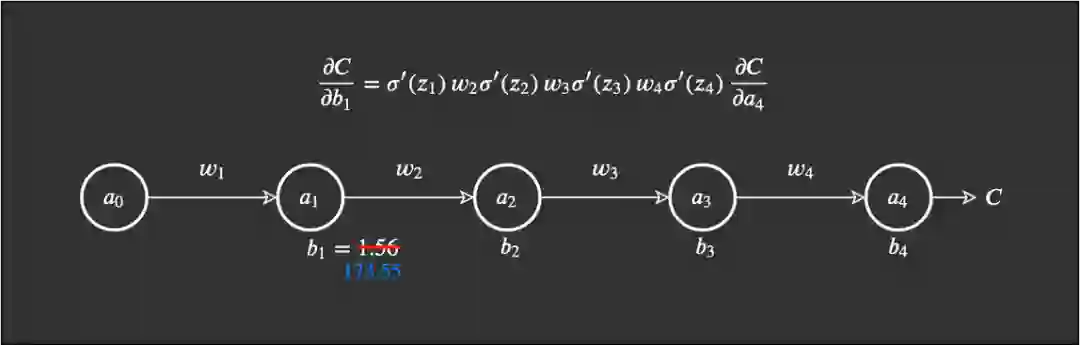
我们将遵照以下示例来进行说明:
http://neuralnetworksanddeeplearning.com/chap5.html#what's_causing_the_vanishing_gradient_problem_unstable_gradients_in_deep_neural_nets
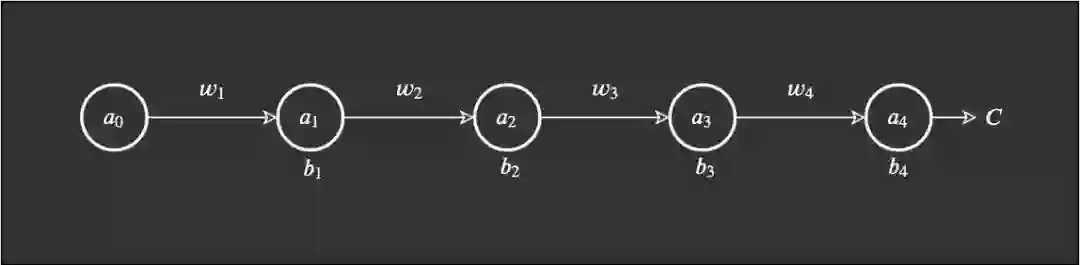
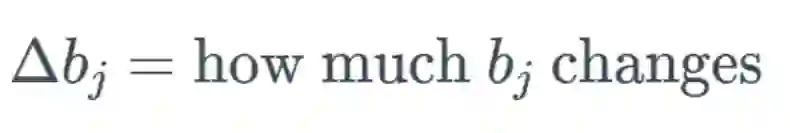
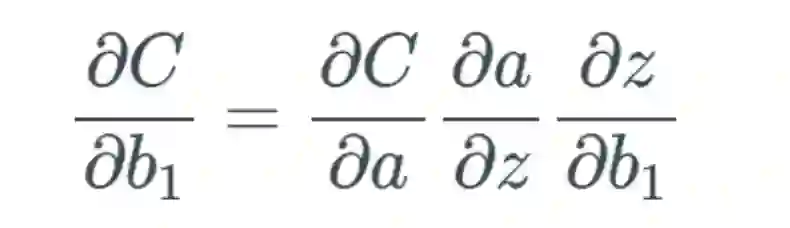
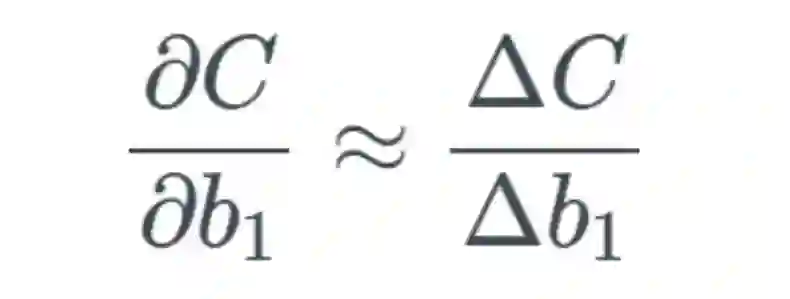

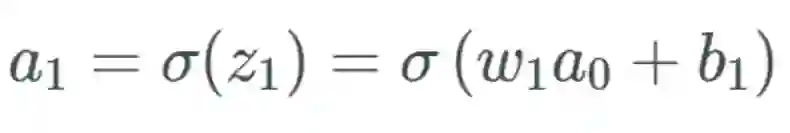
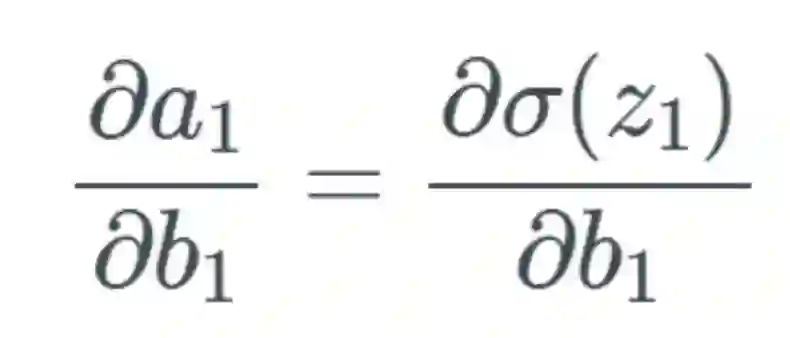
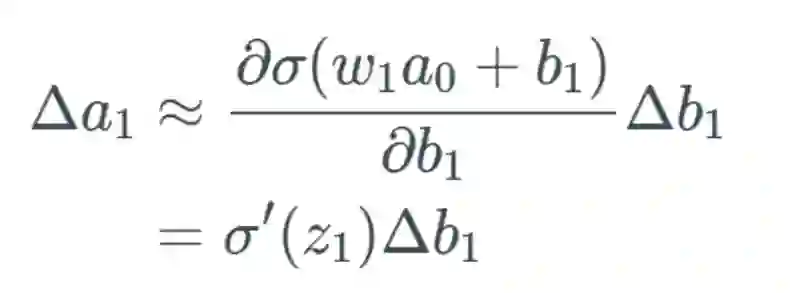
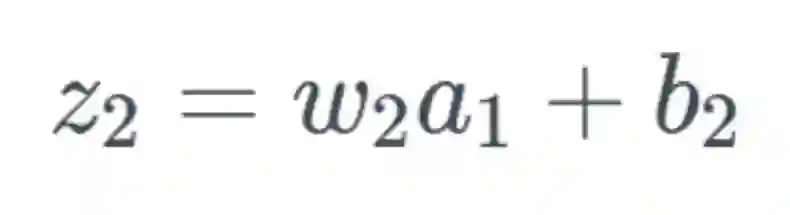
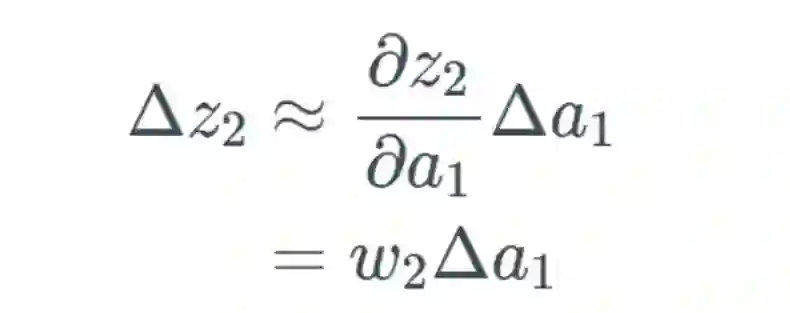
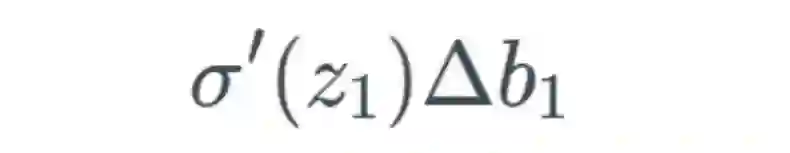
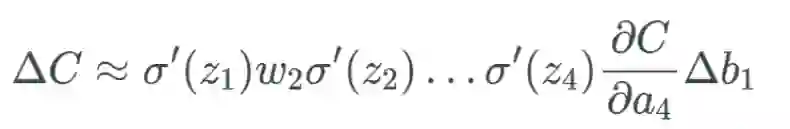
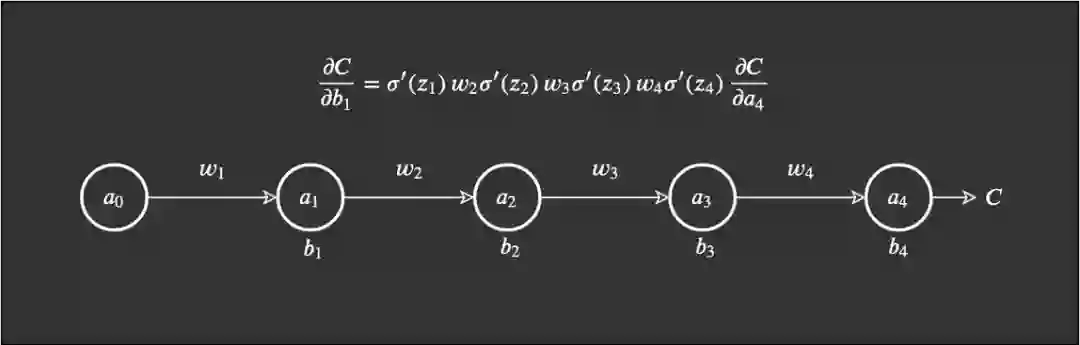
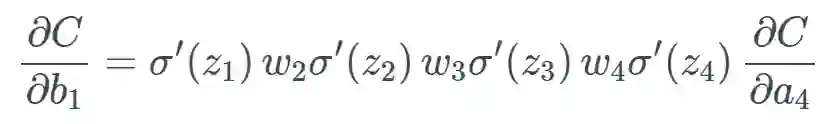
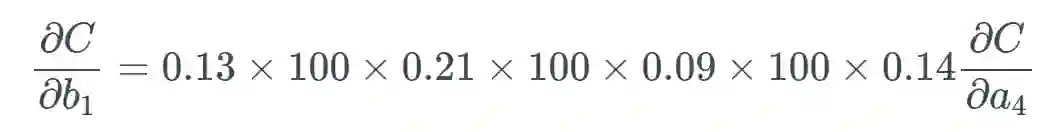
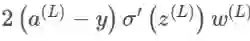 ,可以合理地相信这会远大于 1,但为了方便示例展示,我们将其设为 1。
,可以合理地相信这会远大于 1,但为了方便示例展示,我们将其设为 1。
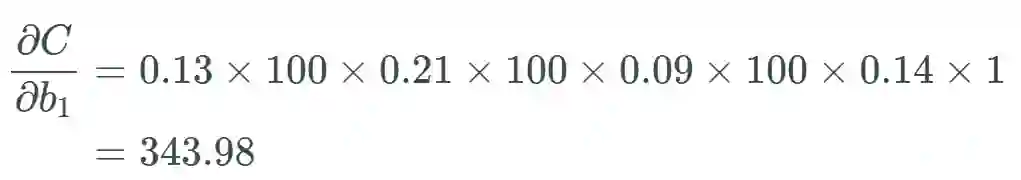
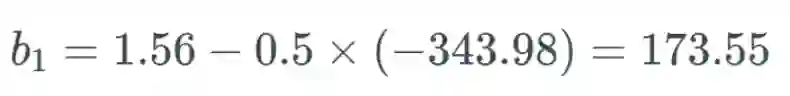
选取一个阈值——如果梯度超过这个值,则使用梯度裁剪或梯度规范;
定义是否使用梯度裁剪或规范。如果使用梯度裁剪,你就指定一个阈值,比如 0.5。如果这个梯度值超过 0.5 或 -0.5,则要么通过梯度规范化将其缩放到阈值范围内,要么就将其裁剪到阈值范围内。
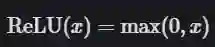
如果输入 x 小于 0,则令输出等于 0;
如果输入 x 大于 0,则令输出等于输入。
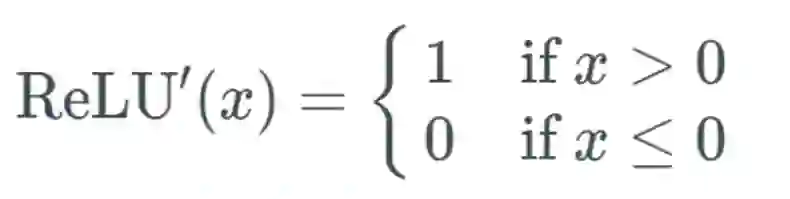
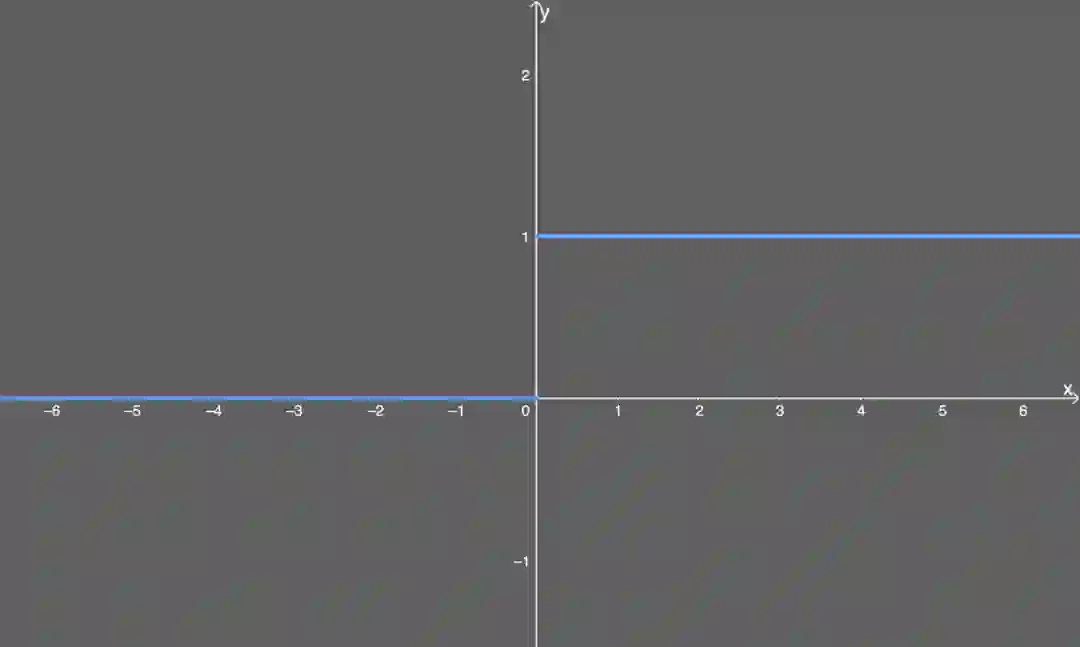
如果输入 x 大于 0,则输出等于 1;
如果输入小于或等于 0,则输出变为 0。
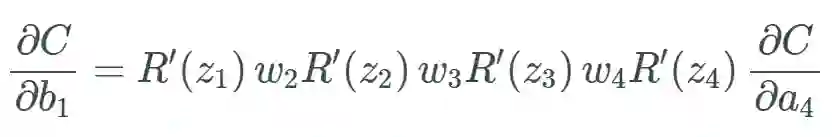
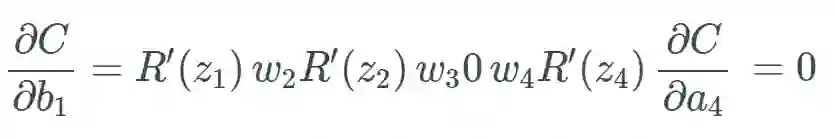
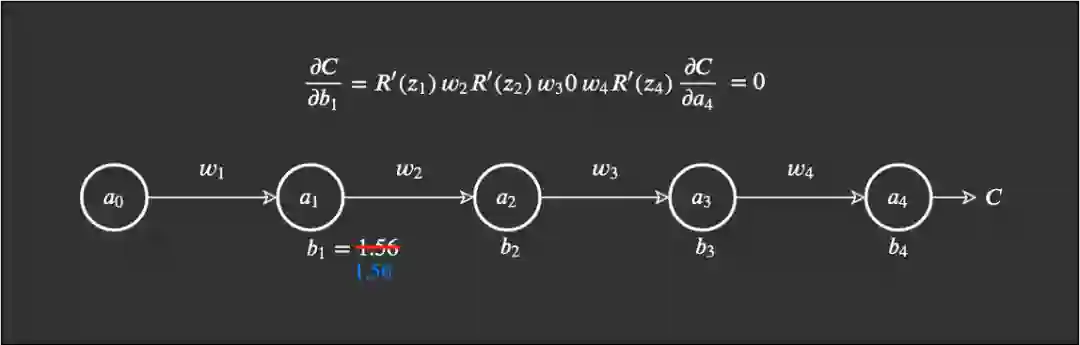
相比于 sigmoid,由于稀疏性,时间和空间复杂度更低;不涉及成本更高的指数运算;
能避免梯度消失问题。
引入了死亡 ReLU 问题,即网络的大部分分量都永远不会更新。但这有时候也是一个优势;
ReLU 不能避免梯度爆炸问题。
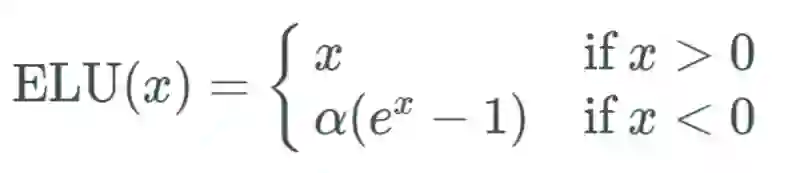
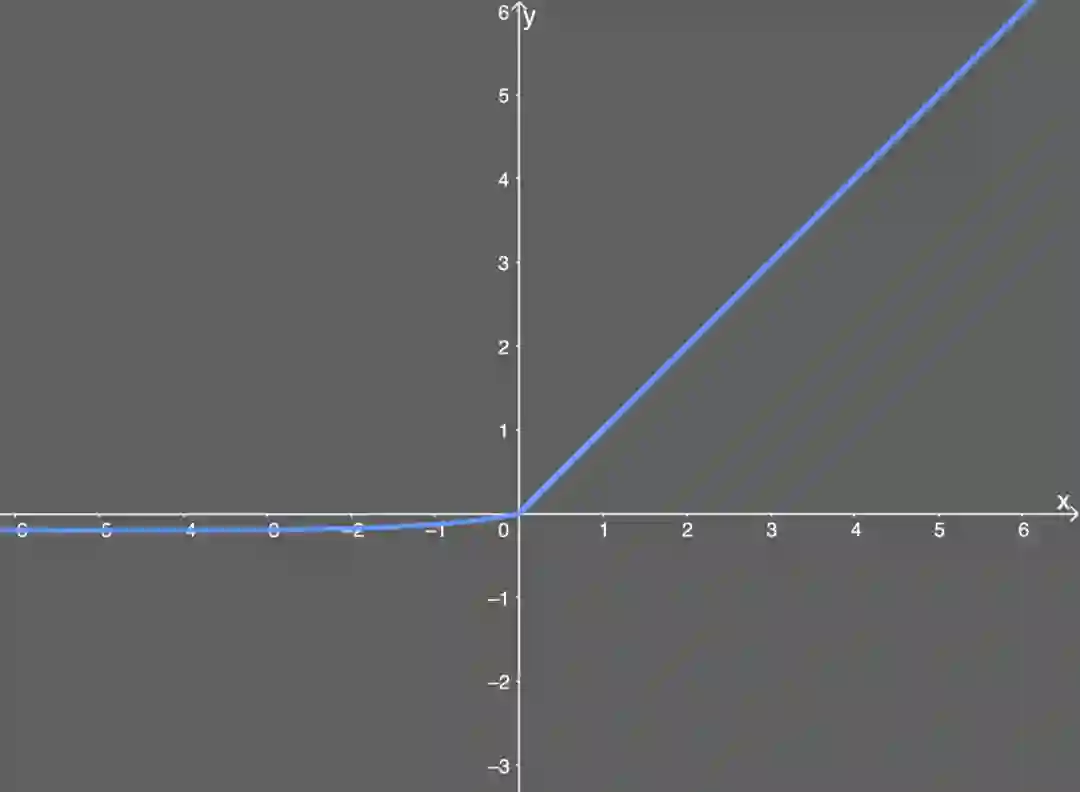
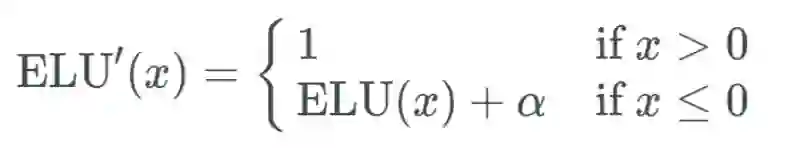
能避免死亡 ReLU 问题;
能得到负值输出,这能帮助网络向正确的方向推动权重和偏置变化;
在计算梯度时能得到激活,而不是让它们等于 0。
由于包含指数运算,所以计算时间更长;
无法避免梯度爆炸问题;
神经网络不学习 α 值。
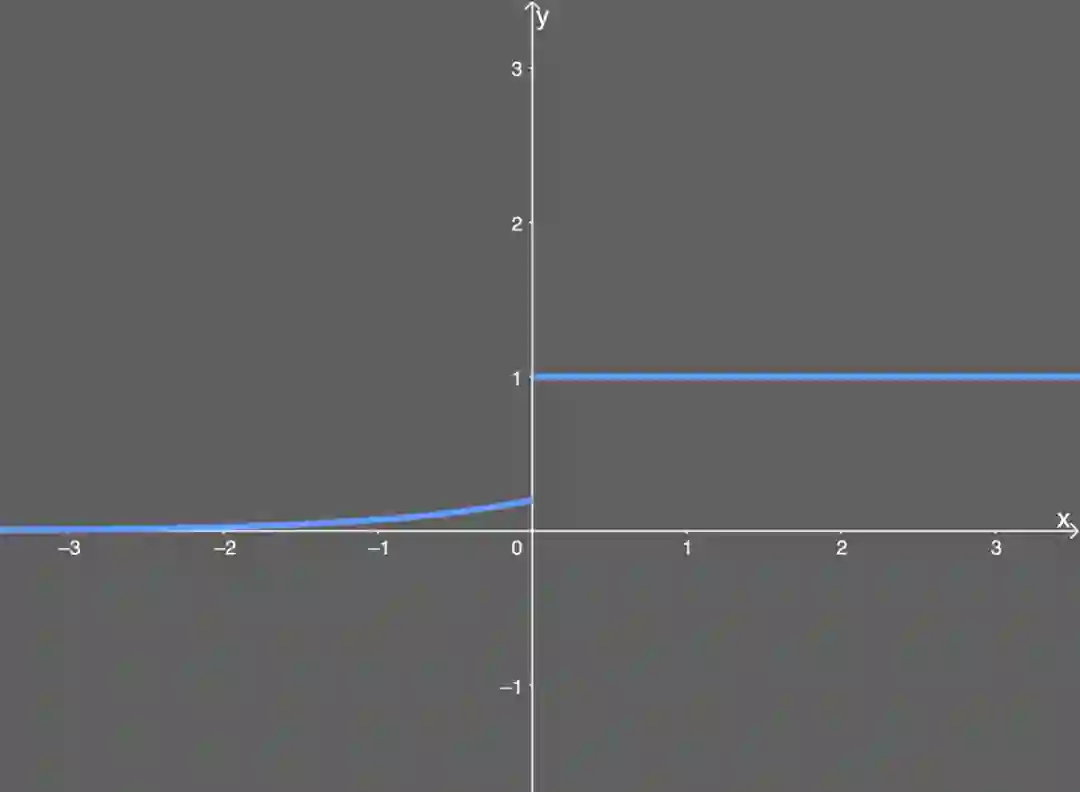
渗漏型整流线性单元激活函数(Leaky ReLU)
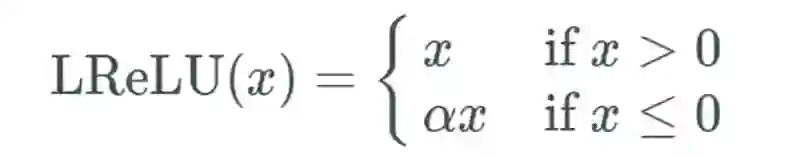
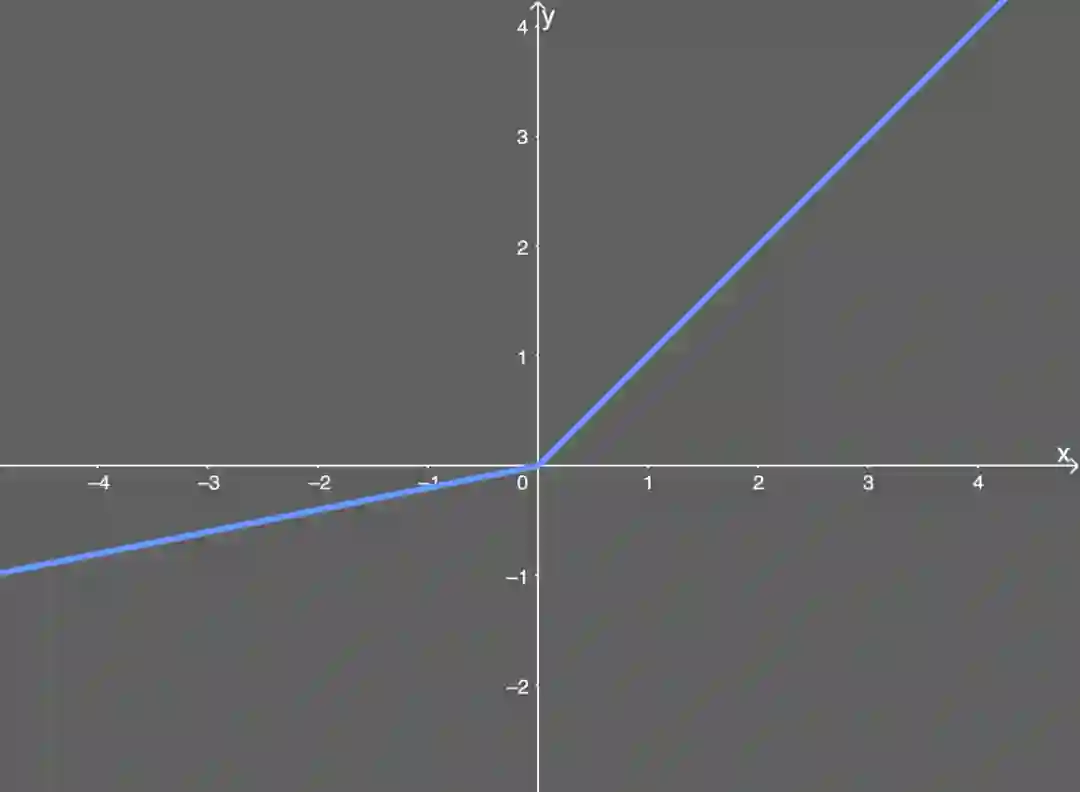
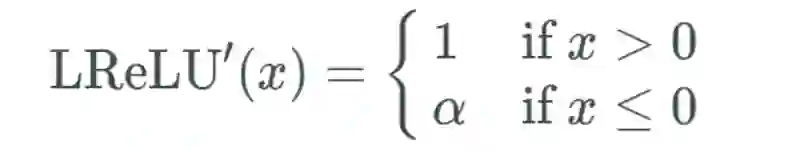
类似 ELU,Leaky ReLU 也能避免死亡 ReLU 问题,因为其在计算导数时允许较小的梯度;
由于不包含指数运算,所以计算速度比 ELU 快。
无法避免梯度爆炸问题;
神经网络不学习 α 值;
在微分时,两部分都是线性的;而 ELU 的一部分是线性的,一部分是非线性的。

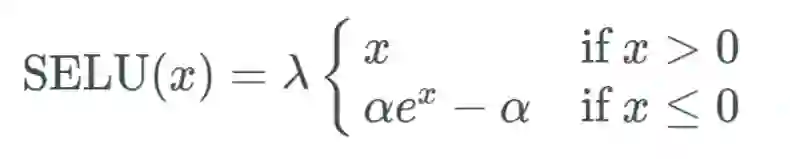
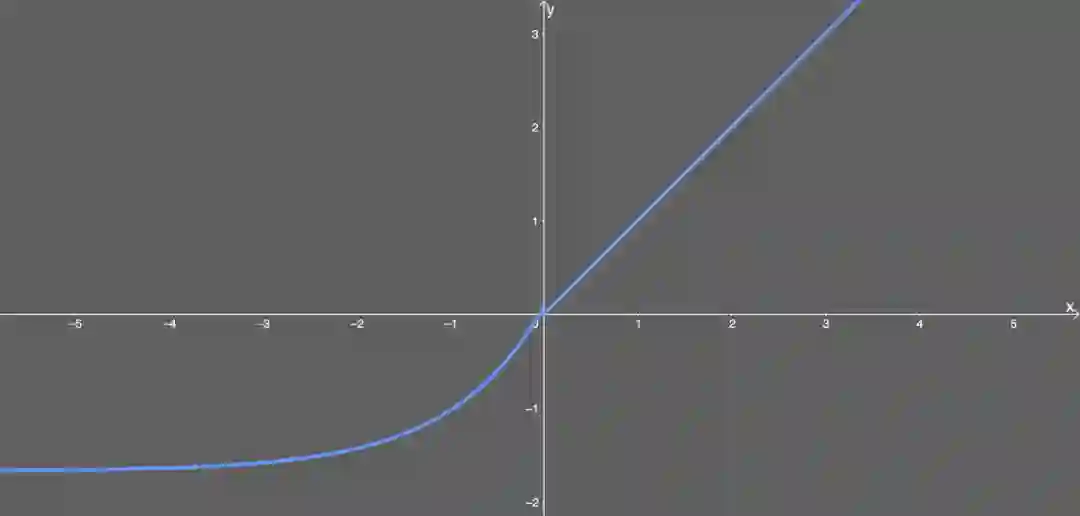
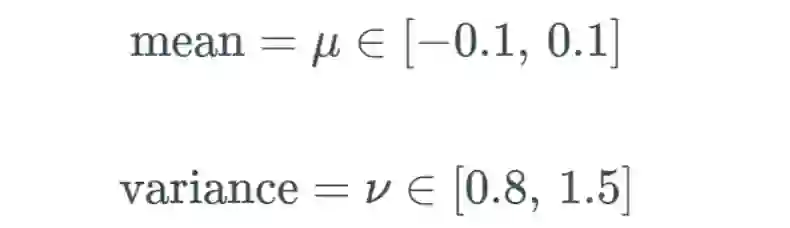
SELU 允许构建一个映射 g,其性质能够实现 SNN(自归一化神经网络)。SNN 不能通过(扩展型)修正线性单元(ReLU)、sigmoid 单元、tanh 单元和 Leaky ReLU 实现。这个激活函数需要有:(1)负值和正值,以便控制均值;(2)饱和区域(导数趋近于零),以便抑制更低层中较大的方差;(3)大于 1 的斜率,以便在更低层中的方差过小时增大方差;(4)连续曲线。后者能确保一个固定点,其中方差抑制可通过方差增大来获得均衡。我们能通过乘上指数线性单元(ELU)来满足激活函数的这些性质,而且 λ>1 能够确保正值净输入的斜率大于 1。
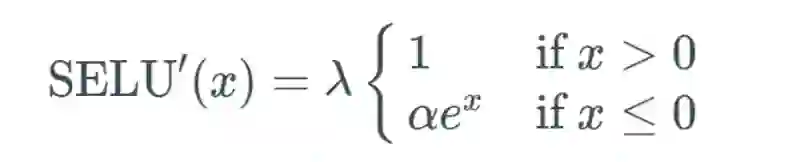
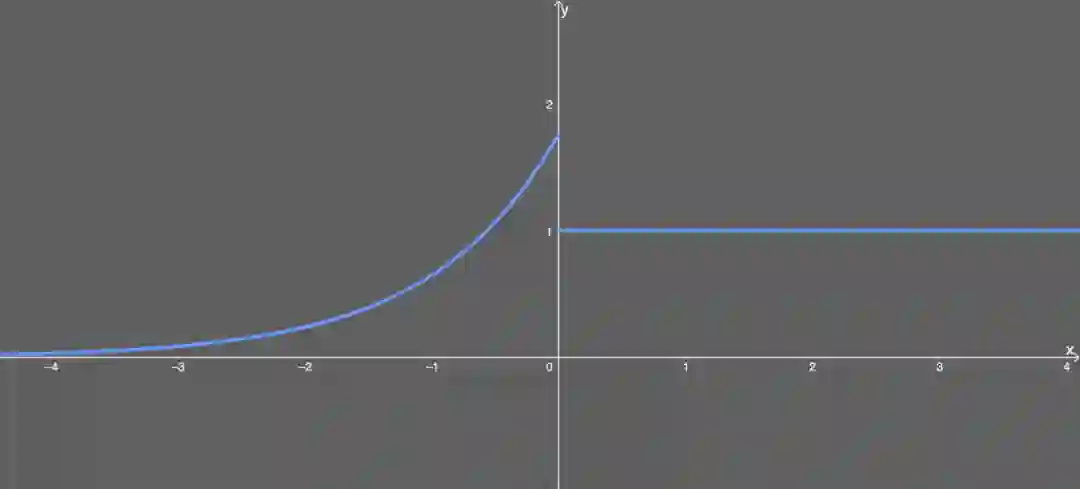
内部归一化的速度比外部归一化快,这意味着网络能更快收敛;
不可能出现梯度消失或爆炸问题,见 SELU 论文附录的定理 2 和 3。
这个激活函数相对较新——需要更多论文比较性地探索其在 CNN 和 RNN 等架构中应用。
这里有一篇使用 SELU 的 CNN 论文:https://arxiv.org/pdf/1905.01338.pdf
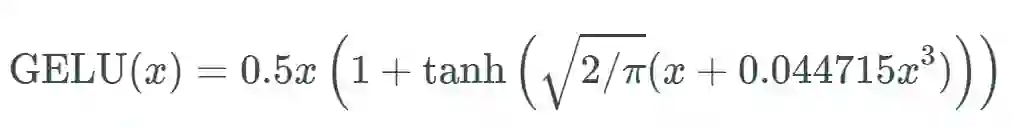
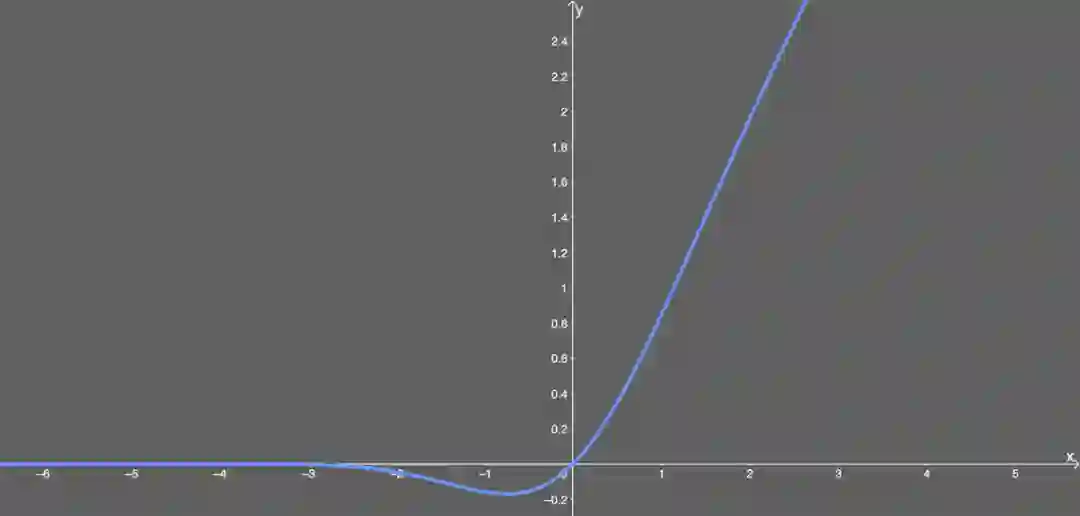

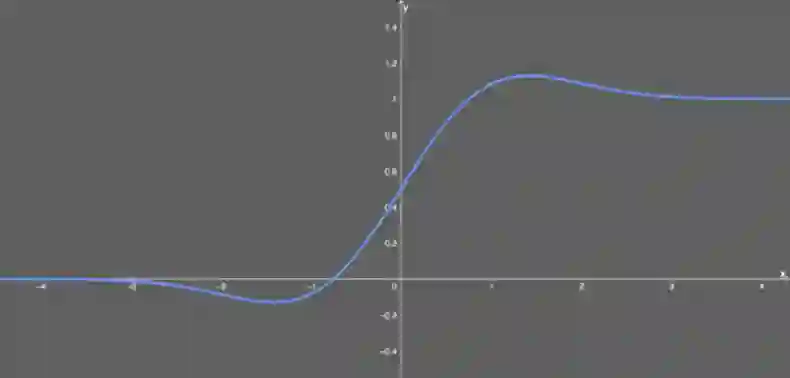
似乎是 NLP 领域的当前最佳;尤其在 Transformer 模型中表现最好;
能避免梯度消失问题。
尽管是 2016 年提出的,但在实际应用中还是一个相当新颖的激活函数。
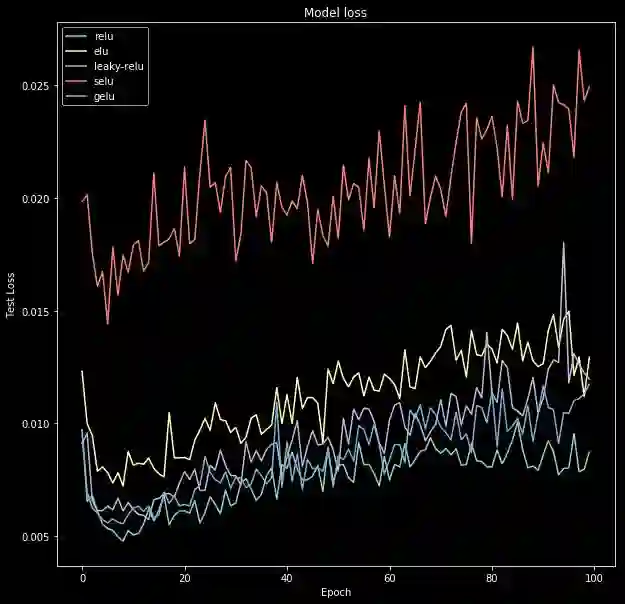
使用本文提及的激活函数训练同样的神经网络模型;
使用每个激活函数的历史记录,绘制损失和准确度随 epoch 的变化图。
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
from keras.datasets import mnist
from keras.utils.np_utils import to_categorical
from keras.models import Sequential
from keras.layers import Dense, Dropout, Flatten, Conv2D, MaxPooling2D, Activation, LeakyReLU
from keras.layers.noise import AlphaDropout
from keras.utils.generic_utils import get_custom_objects
from keras import backend as K
from keras.optimizers import Adam(x_train, y_train), (x_test, y_test) = mnist.load_data()def preprocess_mnist(x_train, y_train, x_test, y_test):
# Normalizing all images of 28x28 pixels
x_train = x_train.reshape(x_train.shape[0], 28, 28, 1)
x_test = x_test.reshape(x_test.shape[0], 28, 28, 1)
input_shape = (28, 28, 1)
# Float values for division
x_train = x_train.astype('float32')
x_test = x_test.astype('float32')
# Normalizing the RGB codes by dividing it to the max RGB value
x_train /= 255
x_test /= 255
# Categorical y values
y_train = to_categorical(y_train)
y_test= to_categorical(y_test)
return x_train, y_train, x_test, y_test, input_shape
x_train, y_train, x_test, y_test, input_shape = preprocess_mnist(x_train, y_train, x_test, y_test)def build_cnn(activation,
dropout_rate,
optimizer):
model = Sequential()if(activation == 'selu'):
model.add(Conv2D(32, kernel_size=(3, 3),
activation=activation,
input_shape=input_shape,
kernel_initializer='lecun_normal'))
model.add(Conv2D(64, (3, 3), activation=activation,
kernel_initializer='lecun_normal'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(AlphaDropout(0.25))
model.add(Flatten())
model.add(Dense(128, activation=activation,
kernel_initializer='lecun_normal'))
model.add(AlphaDropout(0.5))
model.add(Dense(10, activation='softmax'))else:
model.add(Conv2D(32, kernel_size=(3, 3),
activation=activation,
input_shape=input_shape))
model.add(Conv2D(64, (3, 3), activation=activation))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(128, activation=activation))
model.add(Dropout(0.5))
model.add(Dense(10, activation='softmax'))
model.compile(
loss='binary_crossentropy',
optimizer=optimizer,
metrics=['accuracy'])return model# Add the GELU function to Keras
def gelu(x):
return 0.5 * x * (1 + tf.tanh(tf.sqrt(2 / np.pi) * (x + 0.044715 * tf.pow(x, 3))))
get_custom_objects().update({'gelu': Activation(gelu)})
# Add leaky-relu so we can use it as a string
get_custom_objects().update({'leaky-relu': Activation(LeakyReLU(alpha=0.2))})
act_func = ['sigmoid', 'relu', 'elu', 'leaky-relu', 'selu', 'gelu']result = []for activation in act_func:print('\nTraining with -->{0}<-- activation function\n'.format(activation))
model = build_cnn(activation=activation,
dropout_rate=0.2,
optimizer=Adam(clipvalue=0.5))
history = model.fit(x_train, y_train,
validation_split=0.20,
batch_size=128, # 128 is faster, but less accurate. 16/32 recommended
epochs=100,
verbose=1,
validation_data=(x_test, y_test))
result.append(history)
K.clear_session()del model
print(result)new_act_arr = act_func[1:]
new_results = result[1:]def plot_act_func_results(results, activation_functions = []):
plt.figure(figsize=(10,10))
plt.style.use('dark_background')# Plot validation accuracy valuesfor act_func in results:
plt.plot(act_func.history['val_acc'])
plt.title('Model accuracy')
plt.ylabel('Test Accuracy')
plt.xlabel('Epoch')
plt.legend(activation_functions)
plt.show()# Plot validation loss values
plt.figure(figsize=(10,10))for act_func in results:
plt.plot(act_func.history['val_loss'])
plt.title('Model loss')
plt.ylabel('Test Loss')
plt.xlabel('Epoch')
plt.legend(activation_functions)
plt.show()
plot_act_func_results(new_results, new_act_arr)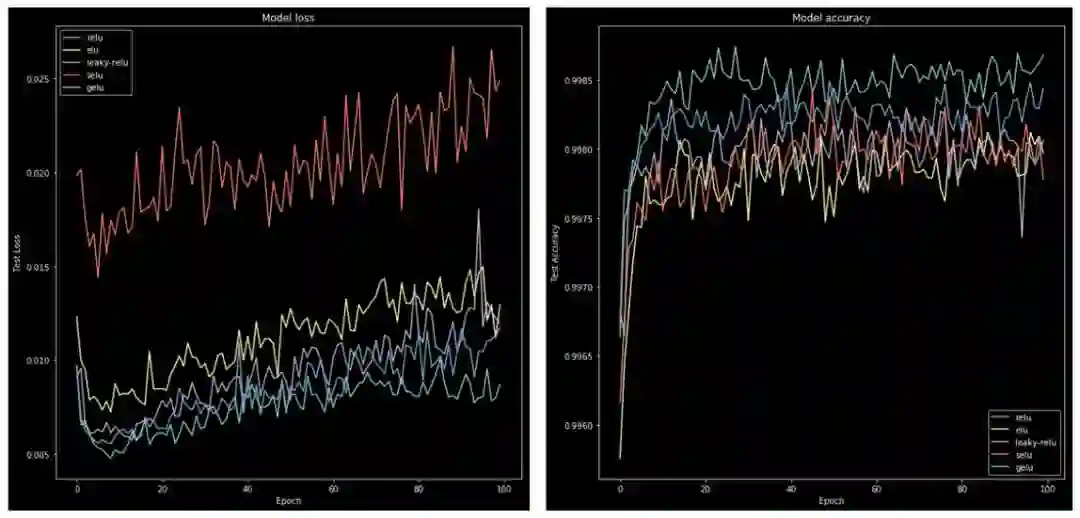
Deep Learning,作者:Ian Goodfellow、Yoshua Bengio、Aaron Courville
The Hundred-Page Machine Learning Book,作者:Andriy Burkov
Hands-On Machine Learning with Scikit-Learn and TensorFlow,作者:Aurélien Géron
Machine Learning: A Probabilistic Perspective,作者:Kevin P. Murphy
Leaky ReLU 论文:https://ai.stanford.edu/~amaas/papers/relu_hybrid_icml2013_final.pdf
ELU 论文:https://arxiv.org/pdf/1511.07289.pdf
SELU 论文:https://arxiv.org/pdf/1706.02515.pdf
GELU 论文:https://arxiv.org/pdf/1606.08415.pdf
CVer 推荐阅读
YOLOv3最全复现代码合集(含PyTorch/TensorFlow和Keras等)
重磅!CVer-学术交流群已成立
扫码可添加CVer助手,可申请加入CVer大群和细分方向群,细分方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索等群。
一定要备注:研究方向+地点+学校/公司+昵称(如目标检测+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群

▲长按加群

▲长按关注我们
麻烦给我一个在看!


