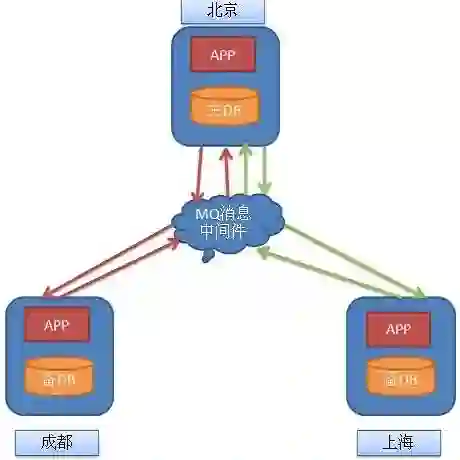
一 流计算中的一致性
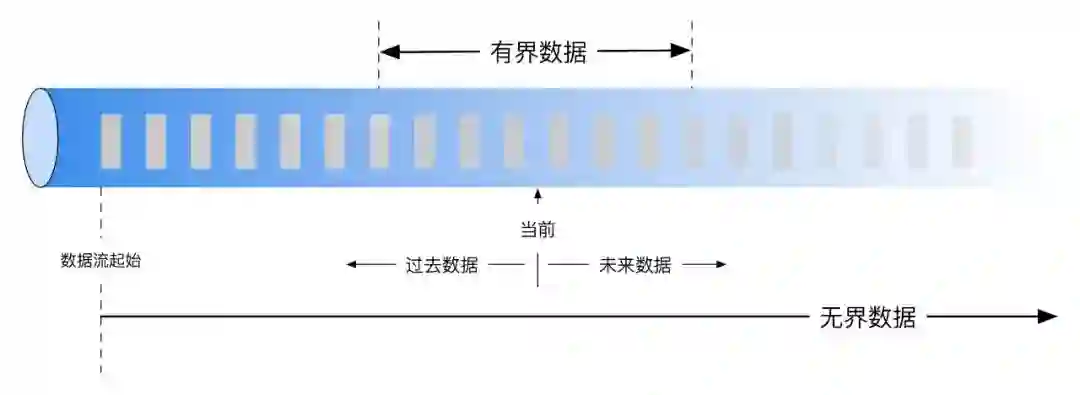
1 一致性定义及挑战

2 一致性相关概念祛魅
二 流计算系统的本质
1 再次认识流计算
-
流 -> 流:没有聚合操作的数据处理过程; -
流 -> 表:存在聚合操作的数据处理过程; -
表 -> 流:触发输出表数据变化的情况; -
表 -> 表:不存在这样的数据处理逻辑。
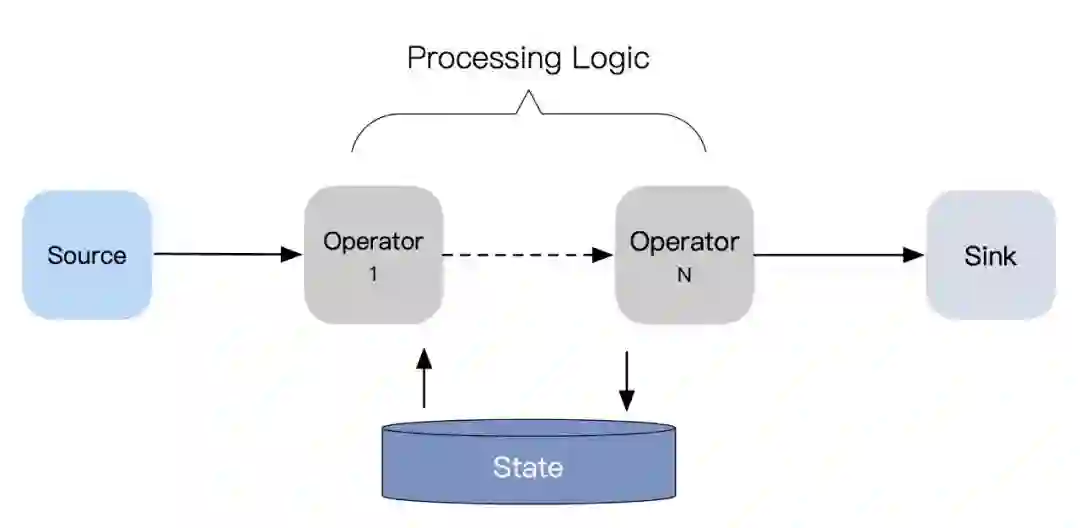
2 确定性/非确定性计算
3 一致性问题的形式化定义
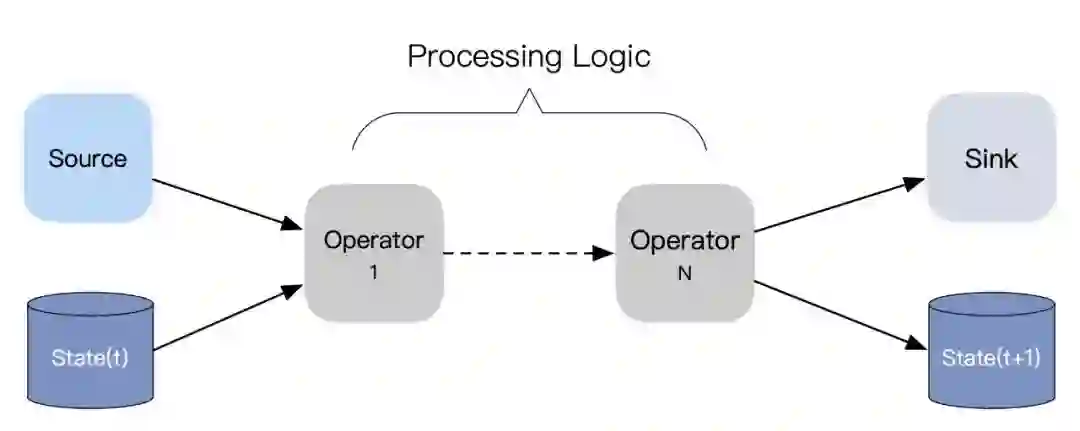
三 一致性的通用解法
1 通用解法的推导
2 通用解法的工程实现
四 一致性的引擎实现
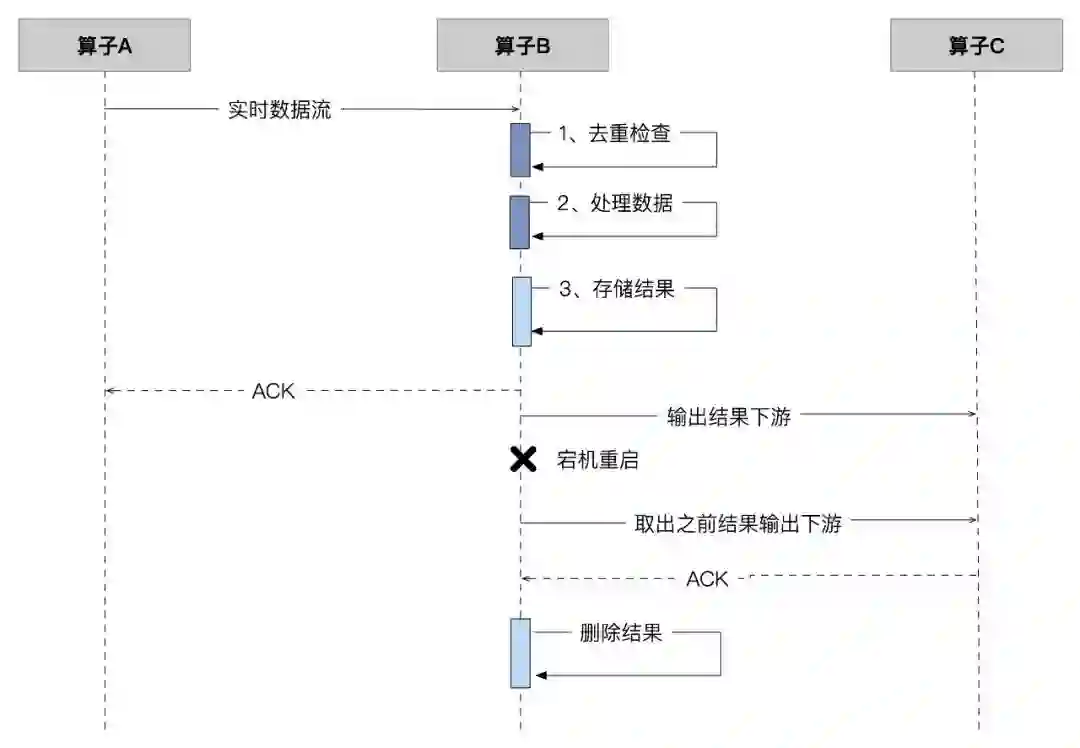
1 Google MillWheel
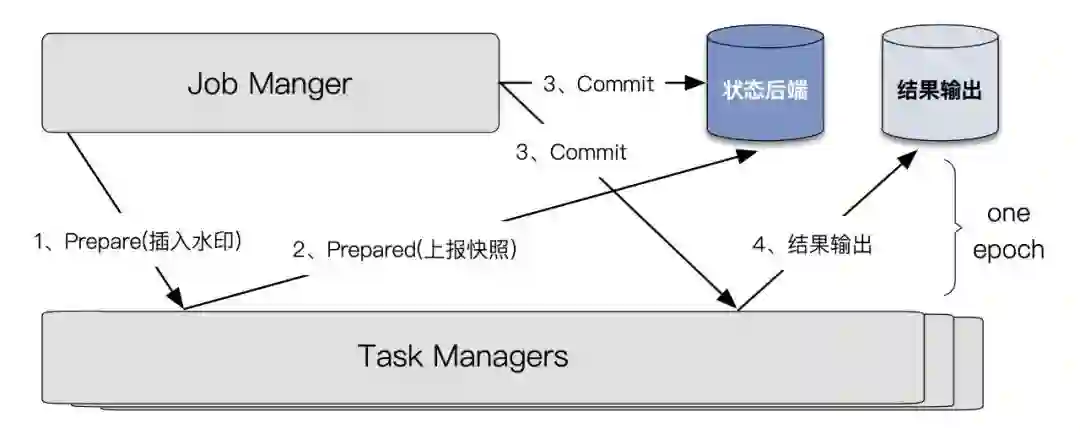
2 Apache Flink
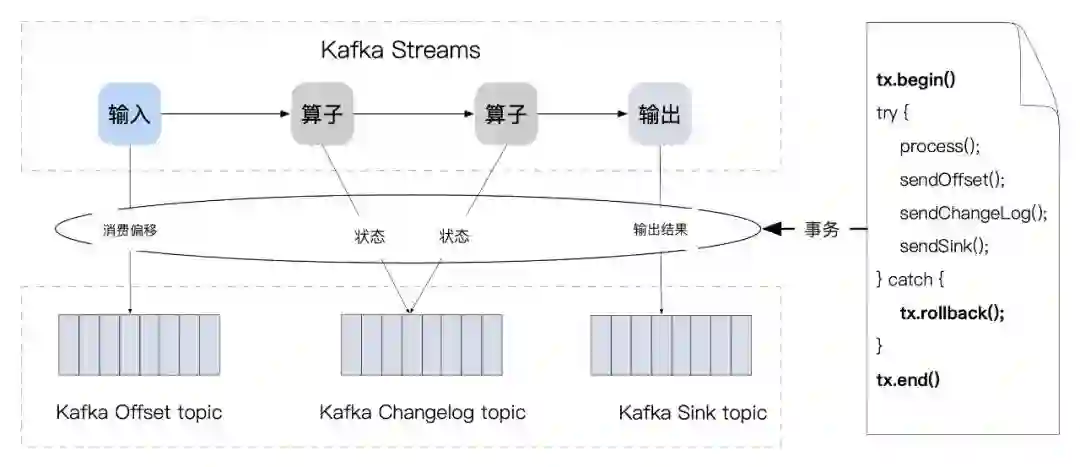
3 Apache Kafka Streams
源状态 SourceState(t):即 Kafka 源中的 Offset 信息,会被写入一个单独的 Kafaka 队列中,该队列对用户透明;
算子状态 OperatorState(t) :计算中算子的 Changelog,也会写入单独的 Kafaka 队列中,该队列对用户透明;
输出结果 Sink(t) :即用户配置的实际的输出队列,用于存放计算结果。
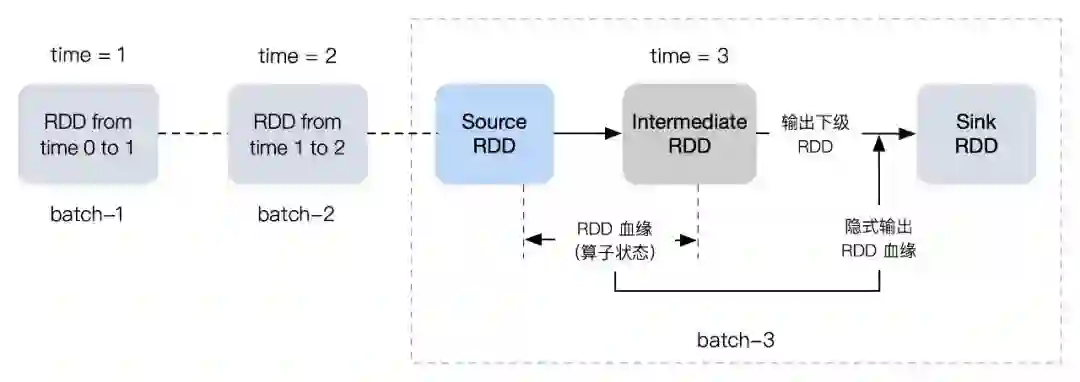
4 Apache Spark Streaming
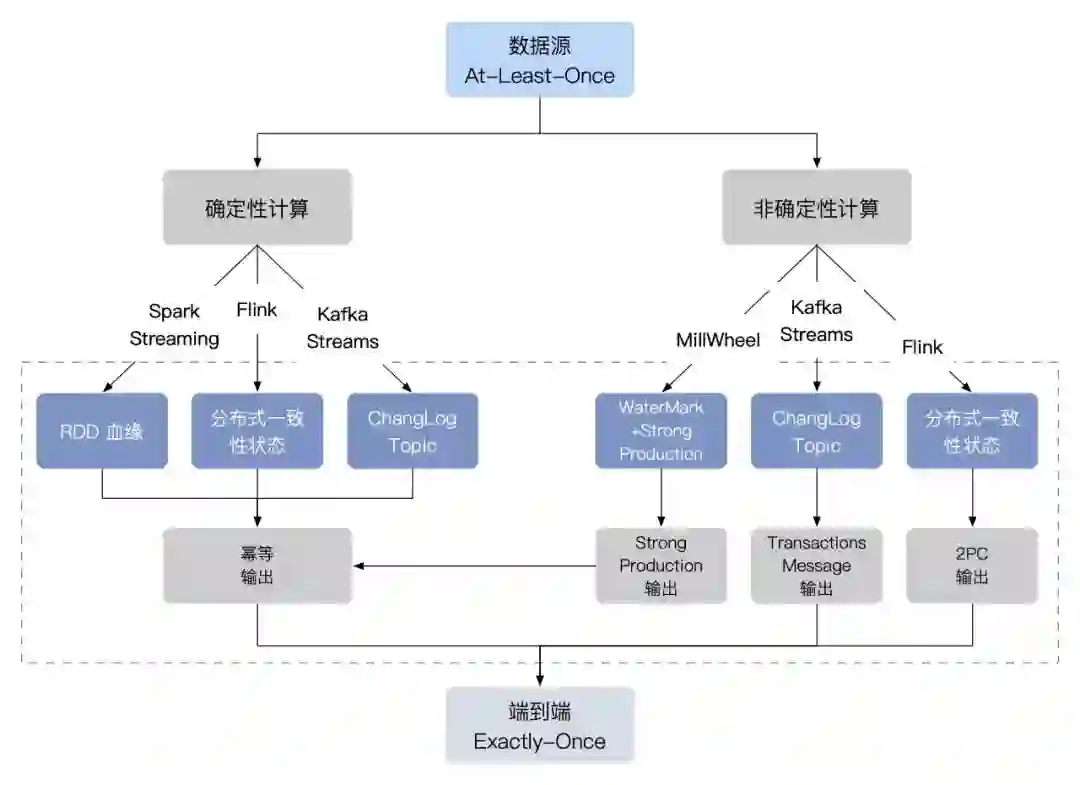
5 各引擎一致性实现总结
五 总结与展望
-
《Streaming System》,T Akidau, S Chernyak, R Lax -
《Transactions in Apache Kafka》,Apurva Mehta,Jason Gustafson -
《A Survey of State Management in Big Data Processing Systems》,QC To, J Soto, V Markl -
《MillWheel: fault-tolerant stream processing at Internet scale》,T Akidau, A Balikov, K Bekiroğlu, S Chernyak -
《Discretized Streams: Fault-Tolerant Streaming Computation at Scale》,M Zaharia, T Das, H Li, T Hunter