如何解决常见的并发问题?

并发错误臭名昭著,常常导致令人十分崩溃的 bug。大多数软件的 bug 是一致的。如果你先做 X,然后做 Y,然后做 Z,你将会得到 Bug A。
但通过并发,你会遇到竞争条件(race condition)。这是一个 bug,如果你做 X,然后做 Y,你可能有 10% 的几率得到 Bug A。错误的出现是间歇性的,这使得你很难找到错误根本原因,因为你不能可靠地重现它。这也使得你很难证明你确实解决了这个问题。如果 Bug A 发生的几率只有 10%,那么你就需要多次尝试重现该 Bug,以确信自己已经修复了它。
处理并发性问题是我职业生涯早期的谋生之道。我喜欢使用多线程并修复高级开发人员错过的竞争条件,这种工作可以大幅提升我自己的信心。
然后我参加了一个面试,并被问到并发问题。结果相当好。
就在那时,我意识到我擅长某种类型的并发问题,而这类问题恰好是大多数并发问题的原因。
首先,让我们稍微讨论一下什么是并发。然后,我们将继续讨论一个简单的并发问题,然后是一个更复杂的问题。
并发基本上是让多个独立的代码段同时运行。让我们从假设开始,然后进入一个真实情况。
假设我需要对一个 API 发出 5 个不同的请求。每一个请求都需要 100 毫秒才能完成。如果我等待一个完成后才开始下一个,我将会等待 500ms。
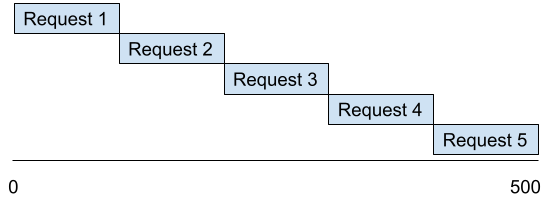
如果我同时执行这 5 个 web 请求,我最终将等待 100 毫秒加上很少的一些额外开销。

这是一个相当大的性能差异,也是人们通常使用并发的原因所在。
这听起来像是一个简单的概念,对吧?这是因为它就是一个简单的概念。
问题在于执行过程。那些 API 请求每个耗时大约 100 毫秒,而不是精确的 100 毫秒。
这意味着你将按顺序发出 API 请求,但返回将是乱序的:

每次运行执行 API 请求的代码时,返回顺序都会不同。
你通过并发性获得了性能改进,但是放弃了一致性。
如果处理这些 API 请求响应的代码使用共享数据,就会出现 bug。
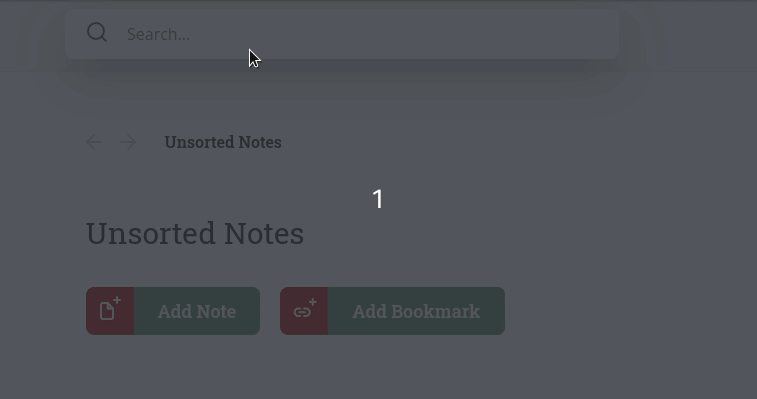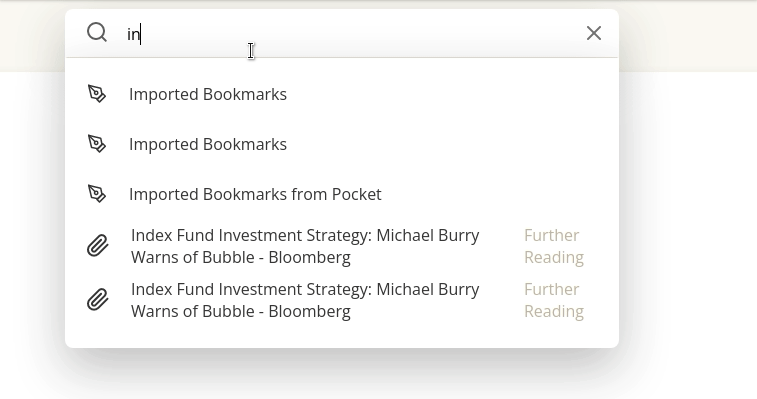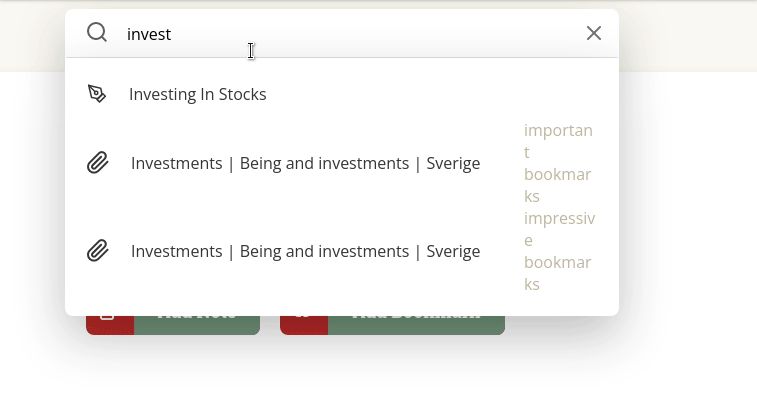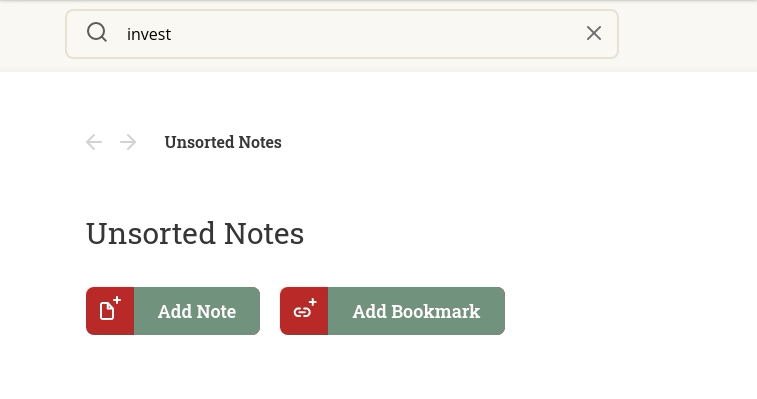
让我们看一个更详细的例子,看看这是如何发生的。Dynomantle 的搜索栏建议有个 bug。
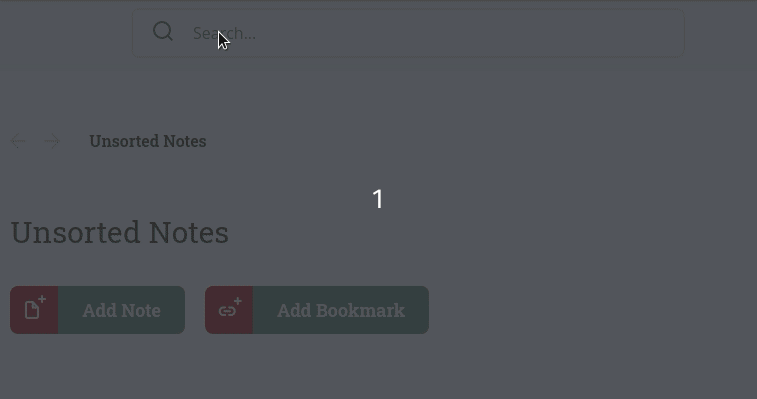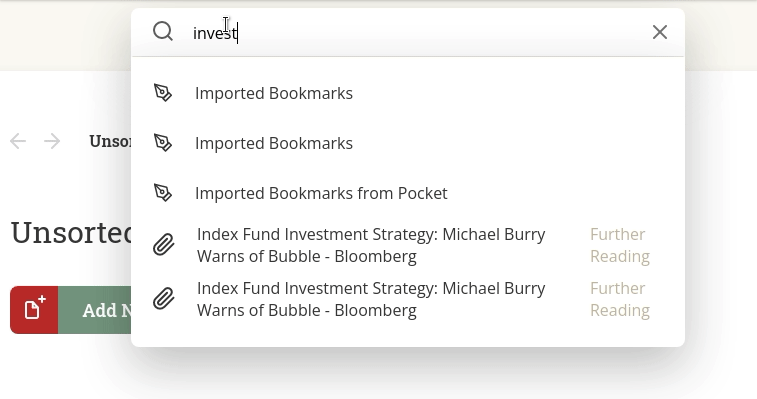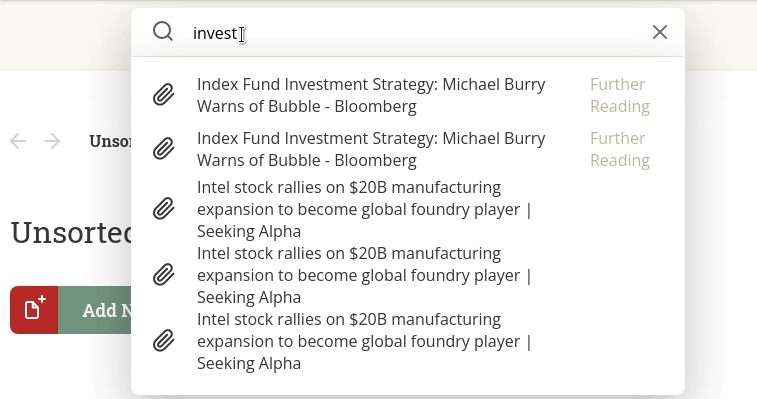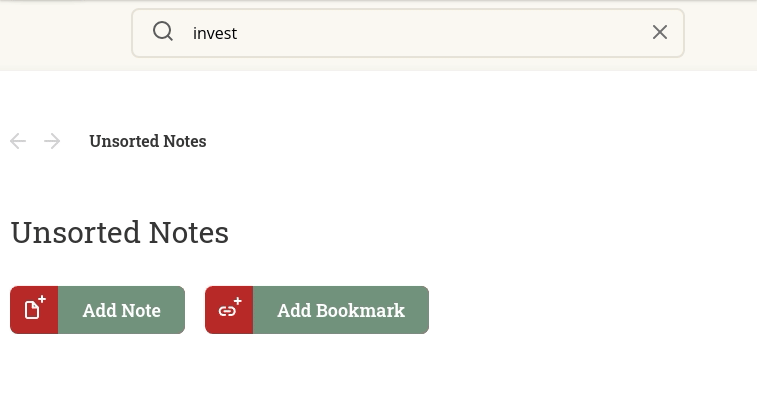
它的问题是:每当你输入一个字符,就会发出一个 api 请求。这是为了让你在键入时能够顺畅地看到提示。你输入“i”,以“i”开头的笔记 / 书签 / 邮件就会弹出来。你输入“in”,列表就会顺滑的变为以“in”开头的内容。
当你知道你要搜索什么时,输入 5 个字符要花多长时间?2 秒?1 秒?半秒?
我仍然需要优化这个服务,但是现在处理每个 API 请求需要半秒到一秒的时间。
让用户在键入每个字符后等待一秒钟再键入下一个字符是一种糟糕的用户体验。所以我在用户键入每个字符时发出一个 API 请求。问题是请求返回的顺序不一致。带有 2 个字符的请求可能在带有 5 个字符的请求之后返回。
搜索建议被存储为一个列表。每当响应传入时,整个列表都会刷新。在这种情况下,当最后一个请求返回时,会用正确的建议刷新整个列表,但是当旧的请求返回时,会在列表中填充不正确的建议。
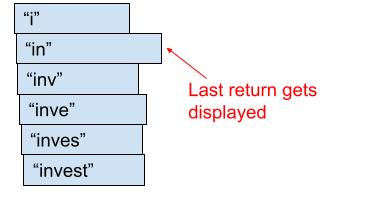
幸运的是,这是一个非常容易解决的问题,因为请求是按顺序发出的。
1) 每次发出请求时生成时间戳或哈希值,这被用作请求 ID。
let requestId = Date.now()2) 将请求 id 设置为带有建议列表的附加变量。因为我们按顺序提交请求,所以这永远是最后一个请求。
let requestId = Date.now()// Datastore is some singleton for// easy access to these types of variablesdatastore.setLastRequestId(requestId)
3) 在每个 API 调用的 success 函数中传递请求 id。
let requestId = Date.now()datastore.setLastRequestId(requestId)$.ajax({success: function(json) {suggestionsReceived(json, requestId)},})
4) 当响应到来时,验证它是否是预期请求的响应。
suggestionsReceived(suggestions: Array,requestId: number,) {if(datastore.lastRequestId != requestId) {return}// the rest of the code}
不幸的是,如果用户输入得非常快,他们可能会看到建议列表更新有延迟。即使用户不使用 2 个字符的建议,看到建议列表出现可以提供一种感觉,即应用正在做一些事情,而非只是等待。
解决这个问题需要对上面的代码做一点小小的修改。
我们将继续使用时间戳而不是哈希值。
接下来,我们将存储最后接收到的请求 id,而不是最后发出的请求 id。
let requestId = Date.now()$.ajax({success: function(json) {suggestionsReceived(json, requestId)},})suggestionsReceived(suggestions: Array,requestId: number,) {datastore.setLastRequestId(requestId)// the rest of the code}
最后,只有当响应的请求 id 高于最后接收到的请求 id 时,我们才会刷新列表。因为我们使用时间戳作为请求 id,所以所有请求都是有序的,id 越大请求就越新。
suggestionsReceived(suggestions: Array,requestId: number,) {if(datastore.lastRequestId > requestId) {return}datastore.setLastRequestId(requestId)// the rest of the code}
注意:这一机制运作的前提是满足以下条件:用户不会在同一毫秒内键入多个字符。如果他们这样做,他们是在粘贴内容,此时我们只需要进行一次 api 请求。
另外需要注意的是,这也只适用于 Javascript 处理并发性的方式。它并不是真正的并发。每个函数都在另一个函数运行之前执行并完成。
在 Java 中尝试类似的代码,你会感觉很糟糕。因为对 suggesReceived() 的多个调用可能同时执行。这意味着对“in”和“inv”的建议响应都可以通过 if 语句中的检查,然后执行函数的其余部分。
suggestionsReceived(suggestions: Array,requestId: number,) {if(datastore.lastRequestId > requestId) {return}// 2 function calls can end up here at the same exact time.datastore.setLastRequestId(requestId)// the rest of the code// Maybe the results for "inv" get set slightly faster,// then the results for "in" get set.// We end up with old suggestion results again.}
你看到的行为将非常不一致,这取决于函数其余部分的长度和两个函数调用的时间。要使它在真正的并发编程语言中正常运作,你需要查找如何在该语言中使用锁。如果你要处理跨多个服务器的并发,也可以考虑 Redis 的分布式锁。
当某一个函数拥有锁时,锁可以阻止其他函数执行。如果我们需要在 Javascript 中使用锁,它应该是这样的:
suggestionsReceived(suggestions: Array,requestId: number,) {// Wait for the lock to be unlocked before continuinglock.lock()if(datastore.lastRequestId > requestId) {return}datastore.setLastRequestId(requestId)// the rest of the code// Let other functions waiting for the lock execute.lock.unlock()}
当然,这样做有风险,如果我们从不解锁,那么其他函数就不会执行。如果我们在多个函数中使用多个锁,可能会出现两个函数都在等待的情况,此时它们都在等待对方已经锁定的锁。我们的程序现在卡住了,因为两个函数都不能执行。这就是所谓的死锁情况。
Dynomantle 中的搜索建议 bug 是一个简单的并发问题,因为它是在 Javascript 中。让我们探讨一个更复杂的问题,它发生在 Java 中,但它的教训应该对许多其他问题有帮助。
我大学毕业后的第一份工作是开发一个网络管理应用程序。例如:你正在访问一家公司,并连接到客户 wifi 网络。我们的应用程序将允许系统管理员根据登录凭据、在办公室的位置、一天中的时间等配置你的访问。他们可以根据公司策略启用或阻止某个端口。
由于我们支持多个协议,并发发挥了作用。我们为 wifi 支持 802.1x,但我们也支持基于用户所连接的以太网端口的身份验证、Kerberos 身份验证协议和其他一些协议。
只要你打开计算机,它就会尝试使用配置的尽可能多的协议同时进行连接。
假设管理员为以太网端口访问设置了一个不太容易访问的策略,你可能通过它访问端口 80 和 443(基本上只是 web 浏览)。如果你使用 Kerberos 进行身份验证,就可以获得更广泛的网络访问。这里的问题是顺序无关紧要。如果一个用户通过多个认证,管理员可以配置哪个协议具有优先级。
当我开始这个项目时,交给我的代码将身份验证的状态存储在一个数据库表中,每个人的 MAC 地址只有一行:
primary_key - int
mac_address - varchar(255) and a unique key
authentication_protocol - enum
status - enum
(真实的数据表要复杂得多,但这是 15 年前的事了,所以请原谅我)
authentication_protocol 列存储优先级最高且成功的协议。如果所有的身份验证尝试都失败了,它还是会存储最高优先级的协议。
我把问题简化了,实际上我们需要上千行代码来协调所有不同的协议,找出哪个优先级最高,处理那些有多个认证步骤的协议,处理各种各样的锁,同时也要处理各种交换机和路由器制造商在固件方面的一些怪癖。客户非常不高兴,因为它很少正常工作,用户经常得到分配给他们的错误的网络策略。
在我职业生涯的前几个月,我花了大部分时间来修复一个又一个不断出现的 bug。最终我意识到问题不在于我们的用户需求很复杂,问题是我们建立了一个糟糕的数据模型,它使代码变得特别复杂。
解决办法很简单。以上面相同的数据库表为例。现在为每个 MAC 地址和协议添加一行。此前每个 mac 地址在数据库表中只有一行,由程序协调在该行中显示哪个协议,修改后则为每个协议添加一行。
并发仍然在发生,但是你不再需要协调并发过程中实际保存哪些数据。每个线程 / 进程都有自己的数据,他们负责修改这些数据而其他线程 / 进程无权修改。当确定一个用户的网络访问时,只需查找该用户的所有行并选择相关的行。
没有锁,也没有共享数据要修改。
代码最终变得更简单,因为你可以忽略大部分并发情况。开发人员很开心。代码正常工作,客户也很高兴。
在实际情况下,管理员只为一个人设置了 2-3 个策略,所以我最终将表的大小增加了 2-3 倍。然而,这是线性增长的。数据库可以轻松地处理线性增长。从 1000 行增加到 3000 行是无关紧要的。即使从 100 万行增加到 300 万行,也可以由现代硬件轻松处理。
从 10 亿行增加到 30 亿行可能会有问题。但是,在你达到 10 亿行之前,你应该已经开始将数据库扩展到支持 30 亿行。
所有这些都是一种冗长的说法:将表的大小增加 3 倍是值得的,因为这可以使我们不必担心并发。
这类问题是常见的并发性问题。许多数据似乎需要由不同的并发进程同时访问和修改,大多数情况下这并不正确。对数据模型进行微调并利用存储成本低廉这一事实,可以为你的团队节省大量工作。
原文链接:
https://blog.professorbeekums.com/2021/solving-concurrency-problems/
点击底部阅读原文访问 InfoQ 官网,获取更多精彩内容!
今日好文推荐
解读云原生的2021:抢占技术C位,迎来落地大爆发
阿里云回应被工信部处罚;“告别996”元年,超40%职场人加班更多;雷军称小米高端手机对标苹果 | Q资讯
新项目别一上来就用微服务
流量超过谷歌的Tiktok,在扩张过程中被质疑“偷窃”OBS代码

参与活动就有机会获得:索尼 WH-CH710N 耳机、机械师空间站背包、小米银离子加湿器、 InfoQ GEEK 抱枕。长按识别二维码,发送【2022】获得属于自己的专属海报以及活动参与方式!

点个在看少个 bug 👇




