干货|【西瓜书】周志华《机器学习》学习笔记与习题探讨(二)①
【分类】:对是离散值的结果进行预测。
【回归】:对是连续值的结果进行预测。
分类和回归属于监督学习。
【错误率】:分类错误的样本数占样本总数的比例。
eg:m个样本中有a个样本分类错误,则错误率
【精度】:分类正确的样本数占样本总数的比例。即:精度=1-错误率。
eg:m个样本中有m-a个样本分类正确,则精度
【误差】:学习器的实际预测输出与样本的真实输出之间的差异。
eg:1000个西瓜中,好瓜有400个,但学习器预测有500个,这之间的差异就是误差。
【训练误差、经验误差】:学习器在训练集上的误差。
值得一提的事,学习器就是在训练集上训练出来的,但实际上在回到训练集上对样本进行结果预测时,仍有误差。(即结果值和标记值不同)
下面看quora的一个回答
https://www.quora.com/What-is-a-training-and-test-error
Training error is the error that you get when you run the trained model back on the training data. Remember that this data has already been used to train the model and this necessarily doesn’t mean that the model once trained will accurately perform when applied back on the training data itself.
eg:100000个用来得出学习器的西瓜在学习器中进行分类测试,发现有10000个西瓜分类错误。则分类错误率为10%,分类精度为90%
【泛化误差】:学习器在新样本上的误差。
eg:100个新西瓜,使用学习器分类,分类错误的有20个。则分类错误率为20%,精度为80%。
希望:得到泛化误差最小的学习器。
实际能做的:努力使经验误差最小化。
注意:努力使经验误差最小化≠让经验误差达到最小值即训练集的分类错误率为0%。
因为在训练集上表现很好的学习器,泛化能力却并不强。
【过拟合】:学习能力过于强大。学习器把训练样本学得太好,导致将训练样本中自身含有的特点当成所有潜在样本都会具有的一般性质,从而训练后使得泛化性能下降。
eg:100000个用来得出学习器的西瓜都是球形瓜,训练出的决策树判断只有瓜是球形才可能是好瓜,但实际上市场上培养的方形瓜也是好瓜,这就让训练出的决策树在面对方形瓜时的泛化能力变得很差。
【欠拟合】:学习能力底下。对训练样本的一般性质尚未学好。
eg:色泽是判断瓜是否是好瓜的重要标准,但经过训练得到的决策树却没有对色泽进行判断的步骤。
所以实际能做的:努力使经验误差最小化,是指在“过拟合”与“欠拟合”之间寻找一种平衡,并尽可能的使学习器在不太过拟合的情况下使得训练集的分类更准确。
任何学习算法都有针对过拟合的措施,但过拟合是无法完全避免的。
【多项式时间(Polynomial time)】:在计算复杂度理论中,指的是一个问题的计算时间m(n)不大于问题大小n的多项式倍数。任何抽象机器都拥有一复杂度类,此类包括可于此机器以多项式时间求解的问题。
【P问题】:指的是能够在多项式的时间里得到解决的问题。
【NP问题】:指的是能够在多项式的时间里验证一个解是否正确的问题。
【证明过拟合无法避免】:
1.机器学习面临的是一个NP或更难的问题,即∃NP;
2.有效的算法需在多项式时间内运行完成,即∃P;
3.当可彻底避免过拟合时,通过最小化经验误差就可获得最优解,即P=NP;
4.但实际上P≠NP;
5.过拟合无法避免。
理想:通过评估学习器的泛化误差,选出泛化误差最小的学习器。
实际:泛化误差只能通过测试求得的测试误差来表现。
【测试误差】:学习器在测试集上的实际预测输出与测试样本的真实输出之间的差异。
【数据集】:一组记录的集合。D={x1,x2,x3...xm}
为了实现测试、表现出学习器的泛化误差从而进行评估,需要在数据集D中产生出训练集S与测试集T,其中测试集应尽可能与训练集互斥。
通过对数据集不同的处理方法,可以分出不同的训练集与测试集,常见的做法有如下三种。
1.留出法
【留出法】:直接将数据集D划分为两个互斥的集合,其中一个集合作为训练集S,另一个作为测试集T,即D=S∪T,S∩T=∅。

如上图,不是西瓜,是两个同心圆。其中内圆红色部分为训练集,外环绿色部分为测试集,两部分是两个互斥的集合。
除此之外,留出法还要尽可能的保持数据分布的一致性,要保持样本类别比例相似,从采样的角度看待数据采集的划分过程,保留类别比例的采样方式通常称为“分层采样”。
就好比它真是一个西瓜,按甜度将其分为七块,采样时每一块都要按照相同的所占比例去采。这七类数据集的测试集与训练集的比值应是相等的。
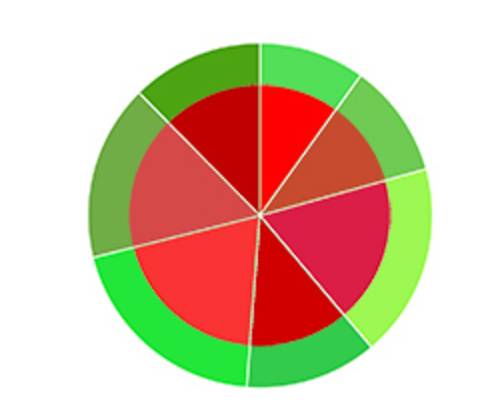
单次使用留出法得到的结果往往不稳定可靠,一般采用若干次随机划分,重复进行实验评估后取平均值作为留出法的评估结果。

例如测试集分别取此图中三组同心圆中绿色的部分,得出的结果再取平均值,就是留出法的评估结果。
总结:
留出法的特点:1.直接划分训练集与测试集、2.训练集和测试集均分层采样、3.随机划分若干次,重复试验取均值
p.s.上面五幅图,用圆心角来体现数据分布的一致性,无论是训练集还是测试集,均在360度范围内分布。
【交叉验证法】:先将数据集D分为k个大小相似的互斥子集,即D=D1∪D2∪...∪Dk;Di∩Dj=∅(i≠j),如下图。
转自:机器学习算法与自然语言处理
完整内容请点击“阅读原文”




