谷歌大脑提出RandAugment:自动数据增广新方法 | NeurIPS 2020
点击上方“CVer”,选择加"星标"置顶
重磅干货,第一时间送达

论文导读
“ 为解决自动数据增强所带来的大量计算成本,Google提出了一种减少了数据增强搜索空间的RandAugmentation,具有很强的工程实用性。”

论文:https://arxiv.org/abs/1909.13719
代码链接:
https://github.com/tensorflow/tpu/tree/master/models/official/efficientnet

摘 要
Abstract
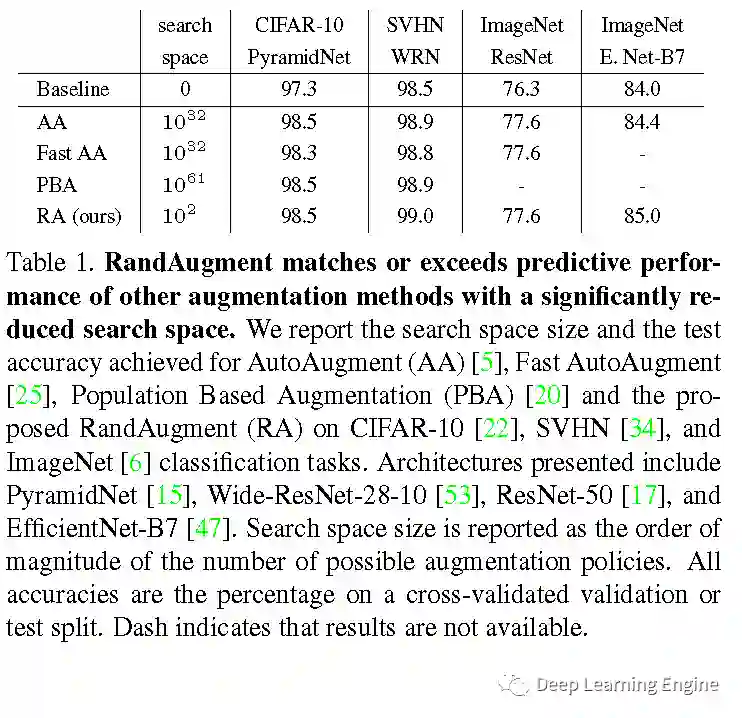
本期分享Google发表在NeurIPS 2020的关于数据增强的一篇文章《RandAugment: Practical automated data augmentation with a reduced search space》。大量的工作论证了使用数据增强(Data Augmentation)能够提升模型的鲁棒性和泛化能力。近期发表的使用自动增强策略进行训练的模型均能优于未使用该方法的baseline。在图像分类,目标检测等方向达到SOTA。但大规模使用自动数据增强其过程采用的是独立的搜索方式。这种独立的搜索方式增加了训练的复杂度和计算成本(obstacle①)。并且其无法根据模型和数据集的大小进行自动的调整(obstacle②)。自动数据增强的策略往往是先在较小的数据集 上训练较小的模型,然后在应用在大的模型上。基于上述两个Obstacles,作者提出:在训练目标任务时,显著减少搜索空间而无需采用独立的额外代理任务;根据模型和数据集的大小定制化不同的超参数已进行不同程度(regularization strength)的数据增强。从Table1的结果易知,本文提出的RandAugment(RA),在的搜索空间下,能够达到和超越更大搜索空间(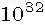
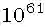
01
—
Introduction


02
—
Proposed Method
import numpy as nptransforms = ['Identity', 'AutoContrast', 'Equalize', 'Rotate', 'Solarize', 'Color', 'Posterize', 'Contrast','Brightness', 'Sharpness', 'ShearX', 'ShearY', 'TranslateX', 'TranslateY']def randaugment(N, M):'''Generate a set of distortions.Args:N: Number of augmentation transformations toapply sequentially.M: Magnitude for all the transformations.'''sampled_ops = np.random.choice(transforms, N)return [(op, M) for op in sampled_ops]if __name__ == '__main__'
在仍保持图像数据的多样性的同时,为减少参数空间,作者用一个无参话的操作替换了需要进行学习的策略,即均匀选取1/K概率的图像增强变换。
直白理解:直接枚举出常见的K=14种数据增强的方法,根据数据集和模型的大小,随机选择N种进行模型的训练。那么潜在的训练策略就包含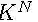
identity
autoContrast
equalize
rotate
solarize
color
posterize
contrast
brightness
sharpness
shear-x
shear-y
translate-x
translate-y
03
—
Results
A. 多种数据增强方式的对比
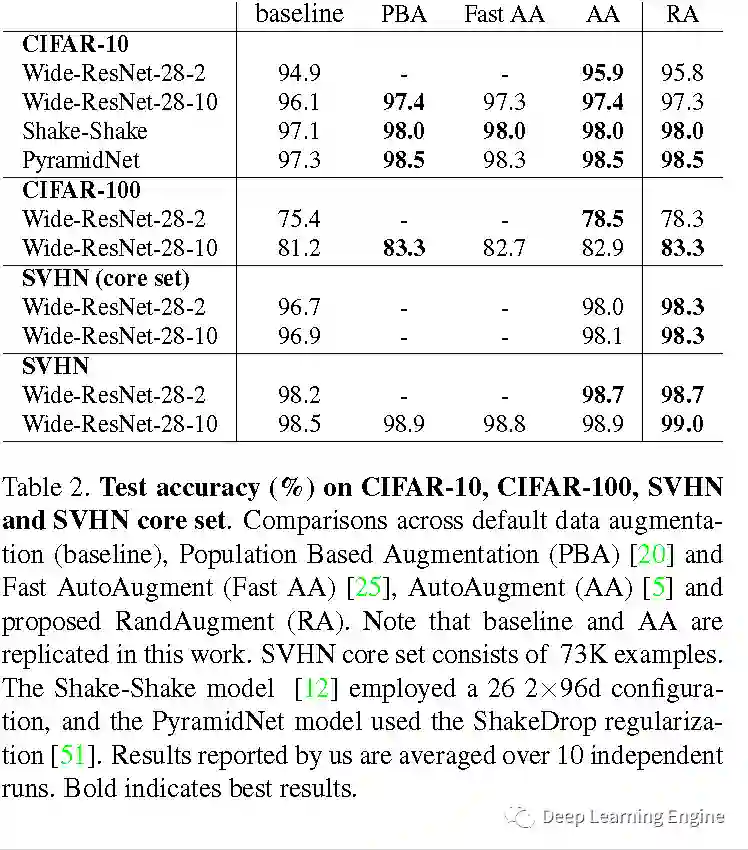
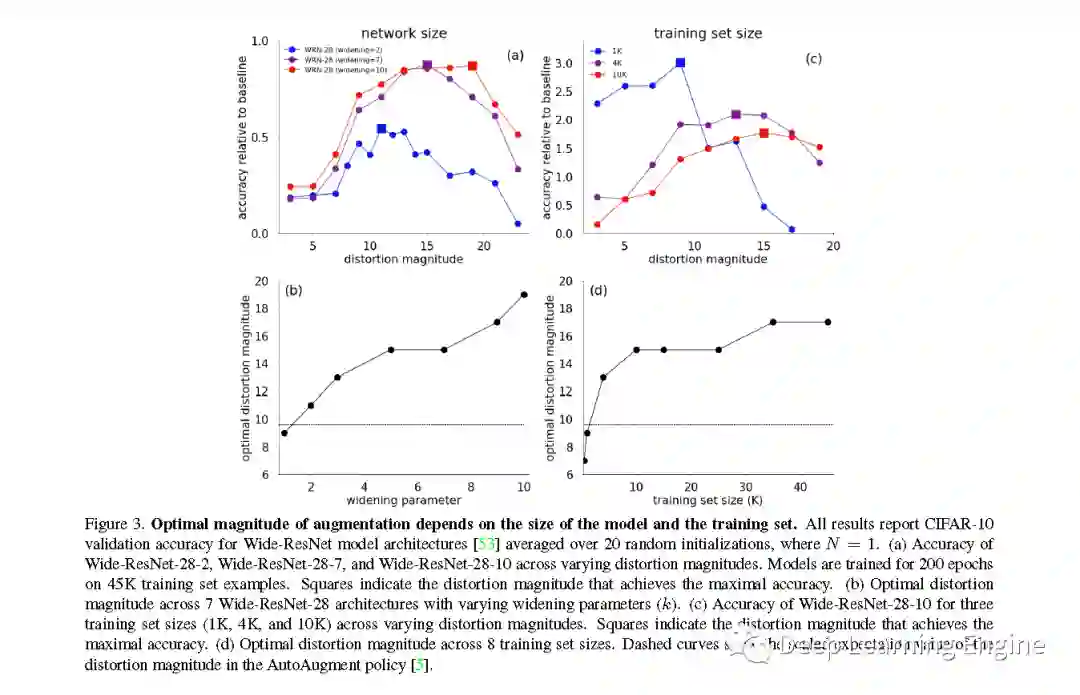
B. 模型和数据集大小与形变程度的关系
C. ImageNet数据集实验结果

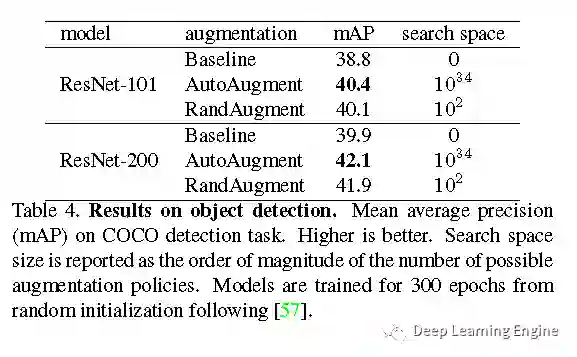
D. 目标检测任务实验结果
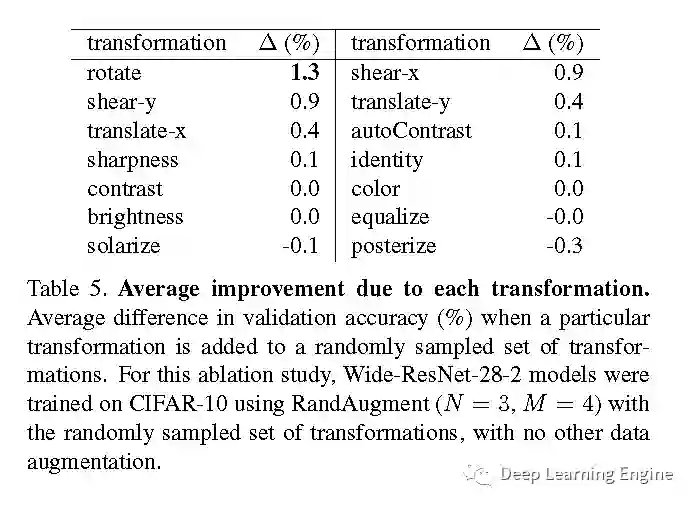
E. 增加数据增强方式对性能的提升

F. 不同增强方式对性能的影响
G. 数据集大小对数据增强性能的影响
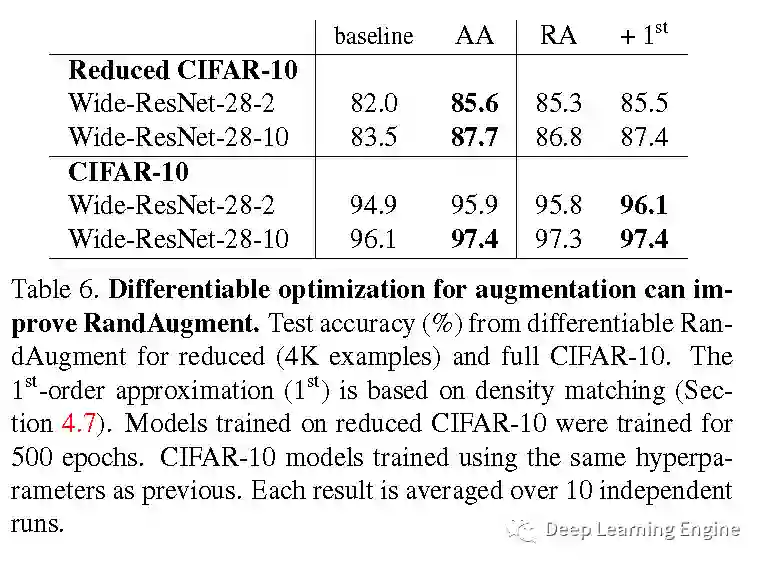
H. 不同数据增强强度方式对准确率的影响

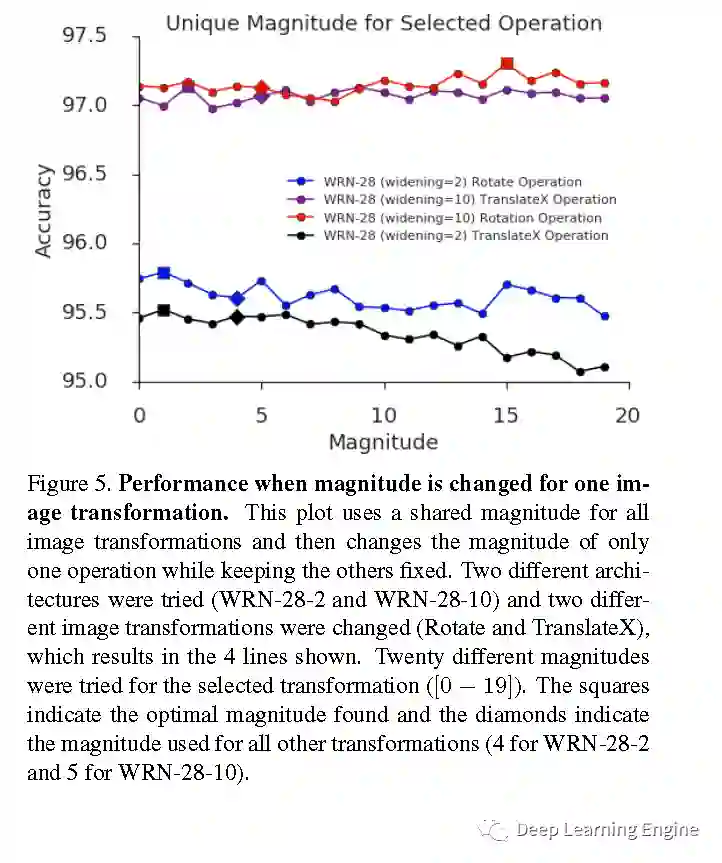
I. 不同Magntitude对准确率的影响
04
—
Conclusion
05
—
结语
Google大佬们从数据增强存在的问题开始,挖掘出导致该问题的原因,提出行之有效的方法,进行完备的实验设计和验证,并在最后引出新的,值得进一步挖掘的研究方向。从文章结构的角度来看,非常值得大家学习。大佬不愧为大佬!
从工程实践的角度分析,只需要简单的从14种数据增强方式中随机选择N种数据增强的方法,进行M类不同强度的图像扭曲形变,就能在平衡计算成本和性能提升上能达到SOTA。真乃大道至简!膜拜了!
论文和代码下载
后台回复:RandAugment,即可下载上述论文和代码
下载:CVPR / ECCV 2020开源代码
在CVer公众号后台回复:CVPR2020,即可下载CVPR 2020代码开源的论文合集
在CVer公众号后台回复:ECCV2020,即可下载ECCV 2020代码开源的论文合集
重磅!CVer-论文写作与投稿交流群成立
扫码添加CVer助手,可申请加入CVer-论文写作与投稿 微信交流群,目前已满2400+人,旨在交流顶会(CVPR/ICCV/ECCV/NIPS/ICML/ICLR/AAAI等)、顶刊(IJCV/TPAMI/TIP等)、SCI、EI、中文核心等写作与投稿事宜。
同时也可申请加入CVer大群和细分方向技术群,细分方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch和TensorFlow等群。
一定要备注:研究方向+地点+学校/公司+昵称(如论文写作+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群

▲长按加微信群

▲长按关注CVer公众号
整理不易,请给CVer点赞和在看!

