【微软Sebastien Bubeck】Transformers with LEGO,最新报告

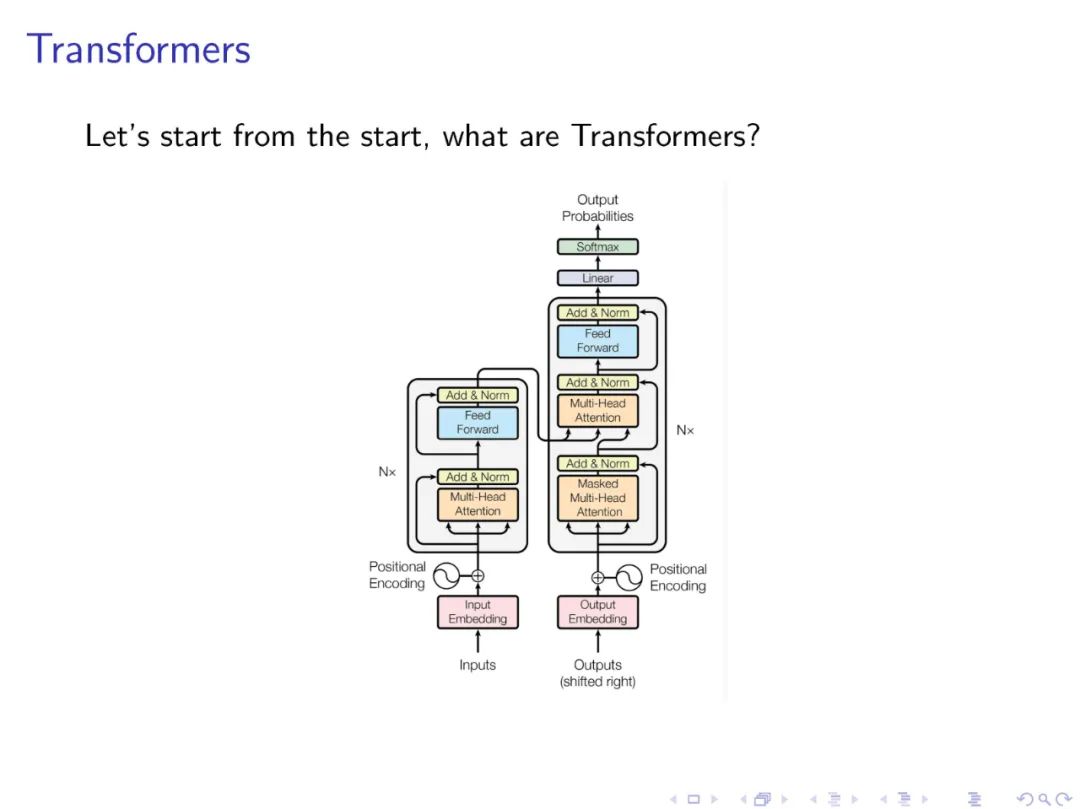
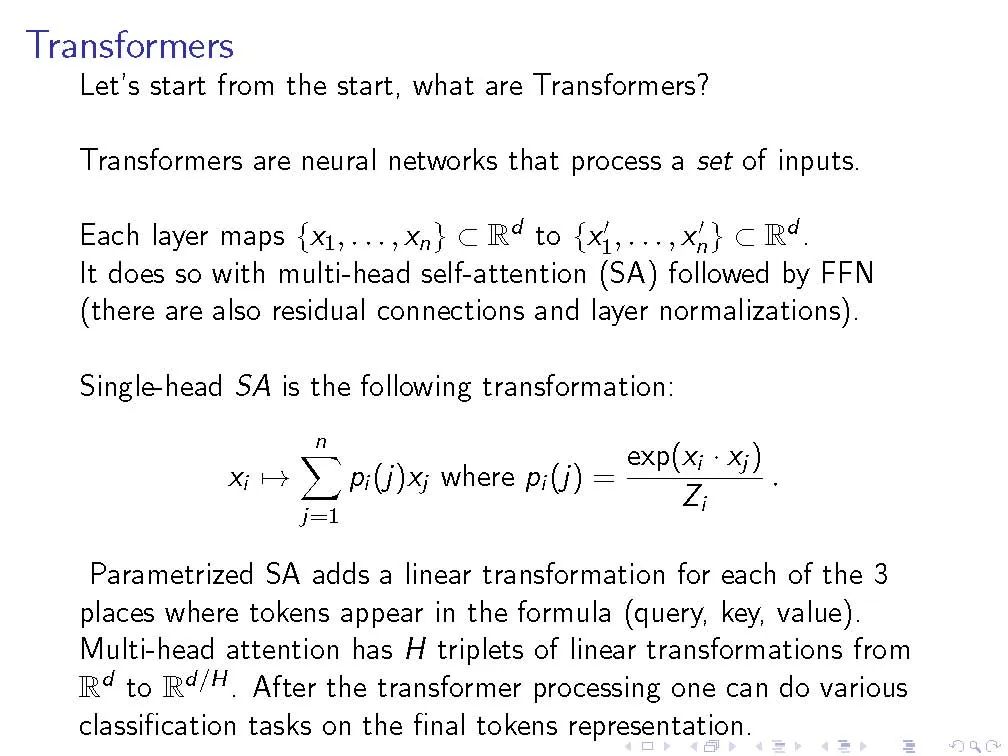
本文提出一个合成任务LEGO(学习平等和组操作),封装了遵循推理链的问题,研究了transformer架构如何学习这一任务。我们特别关注数据效果,如预训练(对看似不相关的NLP任务)和数据集组成(例如,训练和测试时不同的链长度),以及体系结构变量,如权重绑定层或添加卷积组件。我们研究经过训练的模型如何最终成功完成任务,特别是,我们能够(在一定程度上)理解一些注意力头以及信息如何在网络中流动。基于这些观察,我们提出了一个假设,预训练的帮助仅仅是因为它是一个聪明的初始化,而不是存储在网络中的一些深入的知识。在一些数据环境中,经过训练的transformer找到了"捷径"解决方案来遵循推理链,这妨碍了模型泛化到主要任务的简单变体的能力,而且可以通过适当的架构修改或仔细的数据准备来防止这种捷径。在发现的激励下,开始探索学习执行C程序的任务,其中对transformer的卷积修改,即在键/查询/值映射中添加卷积结构,显示了令人鼓舞的优势。




专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“T81” 就可以获取《【微软Sebastien Bubeck】Transformers with LEGO,最新报告》专知下载链接



登录查看更多
相关内容

专知会员服务
21+阅读 · 2022年3月18日
专知会员服务
94+阅读 · 2020年4月13日
专知会员服务
48+阅读 · 2019年11月25日
Arxiv
17+阅读 · 2020年6月2日
Arxiv
10+阅读 · 2019年9月15日
Arxiv
15+阅读 · 2018年10月11日


相关VIP内容
专知会员服务
21+阅读 · 2022年3月18日
专知会员服务
94+阅读 · 2020年4月13日
专知会员服务
48+阅读 · 2019年11月25日
相关资讯
相关论文
Arxiv
17+阅读 · 2020年6月2日
Arxiv
10+阅读 · 2019年9月15日
Arxiv
15+阅读 · 2018年10月11日