仅靠一道简单的数学题,他就变成了Stack Overflow的数据科学家
古语有云,“学好数理化,走遍天下都不怕。”
人工智能时代尤其如此。
比如,写上几句基础的数学概念,天上就能掉下一个工作来……这是真事。

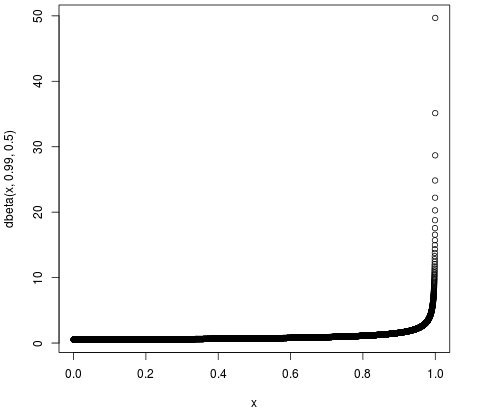
那么这个图代表什么意思?Y轴是一个概率密度,那么X轴呢?
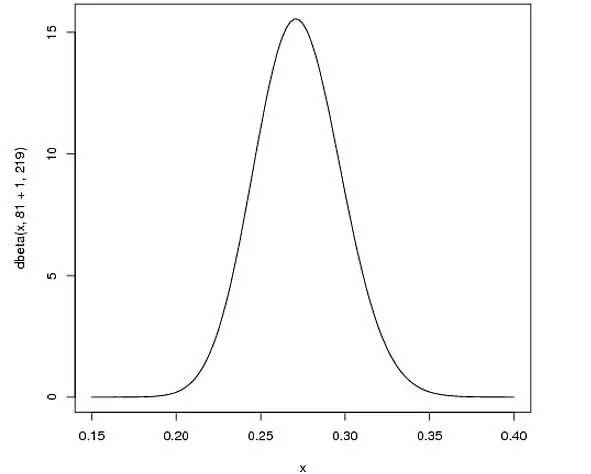
curve(dbeta(x, 81, 219))
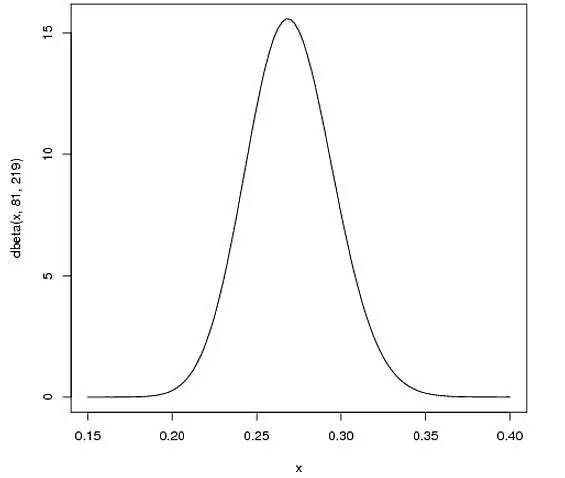
之所以取这两个参数,原因如下:
贝塔分布的均值
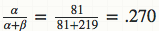
从上图中可以看出,这个分布主要落在(0.2, 0.35)之间,这是从经验得到的合理范围。

curve(dbeta(x, 82, 219))
curve(dbeta(x, 81+100, 219+200))
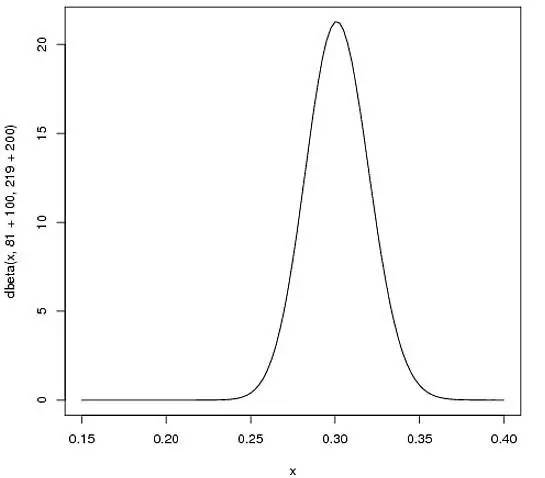
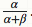
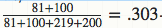
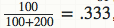
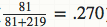
你可能已经注意到了,这个公式就相当于给运动员的击中次数添加了“初始值”,相当于在赛季开始前,运动员已经有81次击中219次不中的记录。
如果你对这位从生物信息学博士变身Stack Overflow数据科学家的David Robinson感兴趣,可在微信公众号后台回复“数据”,即可获得David Robinson的R语言文本挖掘《Text Mining with R》免费电子书。

怎么样?读到这里,对于火车到达时间、彩票中奖机会、抛硬币和棒球击球率所对应的概率分布,你应该都能回想起来了,除非你在《概率论与数理统计》课上所学的东西真的还给老师了。
扫描下面的二维码,仅需8小时,你就能拾回早已还给老师的概率论和数理统计,拿到理解机器学习的入门钥匙。

参考链接:
https://stats.stackexchange.com/questions/47771/what-is-the-intuition-behind-beta-distribution http://varianceexplained.org/r/year_data_scientist/
活动预告:中国国内级别最高、规模最大的人工智能大会——中国人工智能大会(CCAI)将于7.22-7.23在杭州举行,赶快扫描下方图片中的二维码或点击【阅读原文】火速抢票吧。
中国人工智能大会(CCAI),由中国人工智能学会发起,目前已成功举办两届,是中国国内级别最高、规模最大的人工智能大会。秉承前两届大会宗旨,由中国人工智能学会、阿里巴巴集团 & 蚂蚁金服主办,CSDN、中国科学院自动化研究所承办的第三届中国人工智能大会(CCAI 2017)将于 7 月 22-23 日在杭州召开。
作为中国国内高规格、规模空前的人工智能大会,本次大会由中国科学院院士、中国人工智能学会副理事长谭铁牛,阿里巴巴技术委员会主席王坚,香港科技大学计算机系主任、AAAI Fellow 杨强,蚂蚁金服副总裁、首席数据科学家漆远,南京大学教授、AAAI Fellow 周志华共同甄选出在人工智能领域本年度海内外最值得关注的学术与研发进展,汇聚了超过 40 位顶级人工智能专家,带来 9 场权威主题报告,以及“语言智能与应用论坛”、“智能金融论坛”、“人工智能科学与艺术论坛”、“人工智能青年论坛”4 大专题论坛,届时将有超过 2000 位人工智能专业人士参与。







