小扎亲自演示首个「闽南语」翻译系统!主攻3000种无文字的语言
![]()
新智元报道
新智元报道
【新智元导读】没有文字系统的语言该如何开发翻译系统?
到目前为止,虽然机器翻译无法完全做到「信、达、雅」,但翻译结果的准确性对于一般应用场景来说已经足够。
但目前机器翻译相关工作主要关注于「书面语言」,也就是通过文字进行互译,而在全世界范围下有7000多种语言,其中超过40%的语言根本没有文字系统,这也让「通用机器翻译」的开发变得更难。
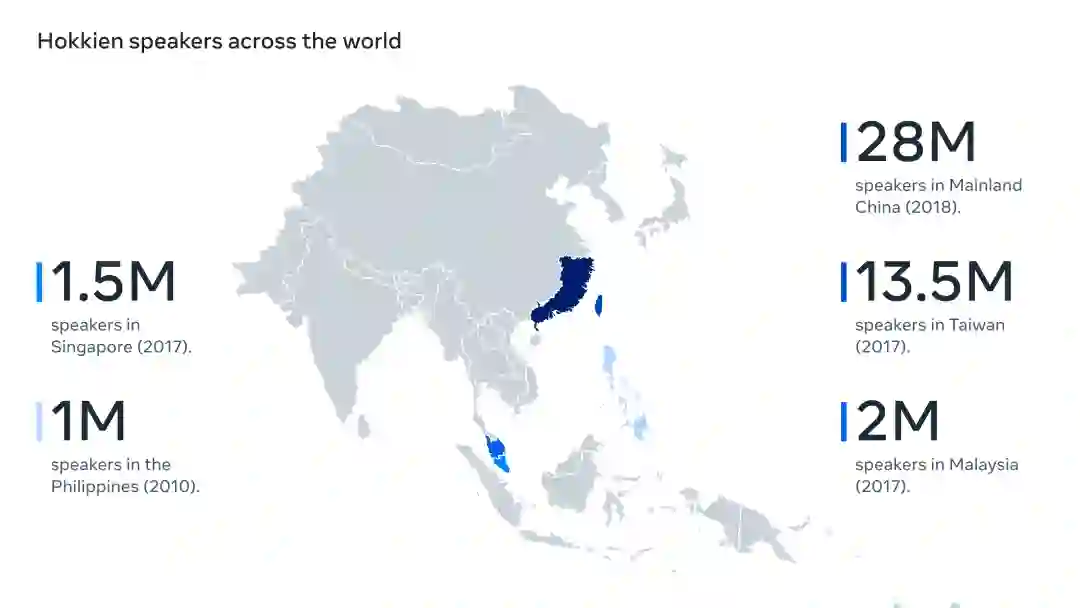
比如汉语方言之一的「闽南语」就是以口语为主的语言,全世界大约有7000多万人使用闽南语。
最近,Meta发布了第一个「闽南语」翻译系统,使用语音对语音翻译(speech-to-speech translation, S2ST)技术,让闽南语的使用者也能与讲英语的人流畅对话!

论文链接:
https://research.facebook.com/file/799432337944526/Speech-to-speech-translation-for-a-real-world-unwritten-language.pdf
为了开发这种新型语音翻译系统,研究人员必须克服传统机器翻译系统的诸多难题,包括数据收集、模型设计和评估。
从训练数据收集、模型选择并发布基准数据集,论文中提出了一个端到端的解决方案,在大规模无标注的语音数据集中自动挖掘数据模式,并采用伪标签(pesudo-labeling)生成弱监督数据。
论文的第一作者Peng-Jen Chen出生和成长与于中国台湾,他讲普通话,但他的父亲主要讲闽南语,所以他们俩在进行复杂对话时感到很棘手。Peng-Jen Chen开发这个项目的出发点就是让他的父亲能够用闽南语和每个人进行交流,因为这是他说起来最舒服的语言。
下面是扎克伯格和Peng-Jen Chen分别用英语和闽南语的翻译对话,模型在这两种语言之间可以互相翻译。
该开源翻译系统是 Meta 的通用语音翻译器(UST)项目的一部分,旨在开发新的人工智能方法,研究人员希望这些方法最终能够实现所有现存语言的实时语音对语音翻译,主要是口语语言。
这也是Meta布局元宇宙的一步大棋,口头交流可以更容易打破人们的交流障碍,让人们无论身处何地都能团结在一起,尤其是在元宇宙中。
训练数据从哪来?
训练数据从哪来?
以当下的AI技术来说,性能不是问题,前提是有足够的数据。
虽然闽南语的使用人数众多,但由于没有标准的书写系统,所以闽南语仍然是一种低资源的语言;并且同时掌握英语和闽南语的翻译人员较少,所以在数据收集和数据标注阶段就遇上了难题。
研究人员利用普通话作为中间语言来建立伪标签(pesudolabel)和人工翻译。

首先将英语(或闽南语)语音翻译成普通话文本,然后将其翻译成闽南语(或英语)并将其添加到训练数据中,该方法通过利用相似的高资源语言数据,能够极大提高模型的性能。
生成训练数据的另一种方式是语音挖掘(speech mining)。
使用预训练的语音编码器,能够将闽南语语音的embedding编码到与其他语言相同的语义空间中而无需闽南语的书面形式。闽南语可以与英语语音对齐,也可以与语义embedding相似的文本对齐。
然后从文本中合成英语语音,生成相似的闽南语和英语语音。
新的建模方法
新的建模方法
大部分语音翻译系统都依赖于转录结果或语音到文本系统。
但由于口头语言没有标准的书面形式,转录后的文本作为翻译输出没有意义,所以对闽南语的翻译系统需要把重点放在语音到语音的翻译上。
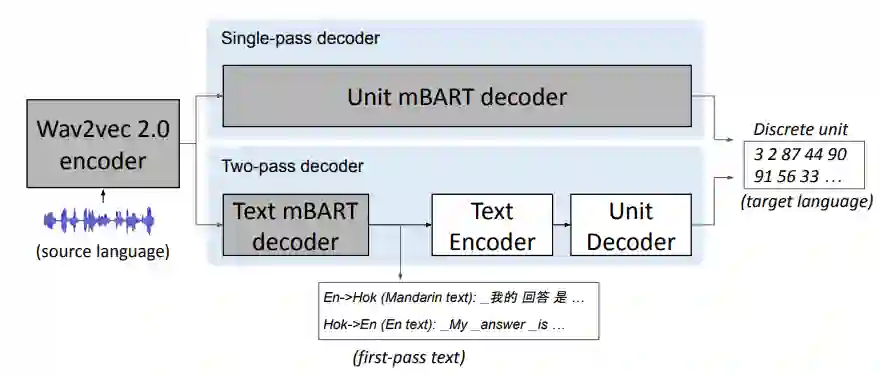
研究人员使用语音到单元的转换(S2UT)来将输入的语音直接转换成一系列的声学单元,然后从声学单元生成波形,这种方法在 Meta 之前就已经有过先例。
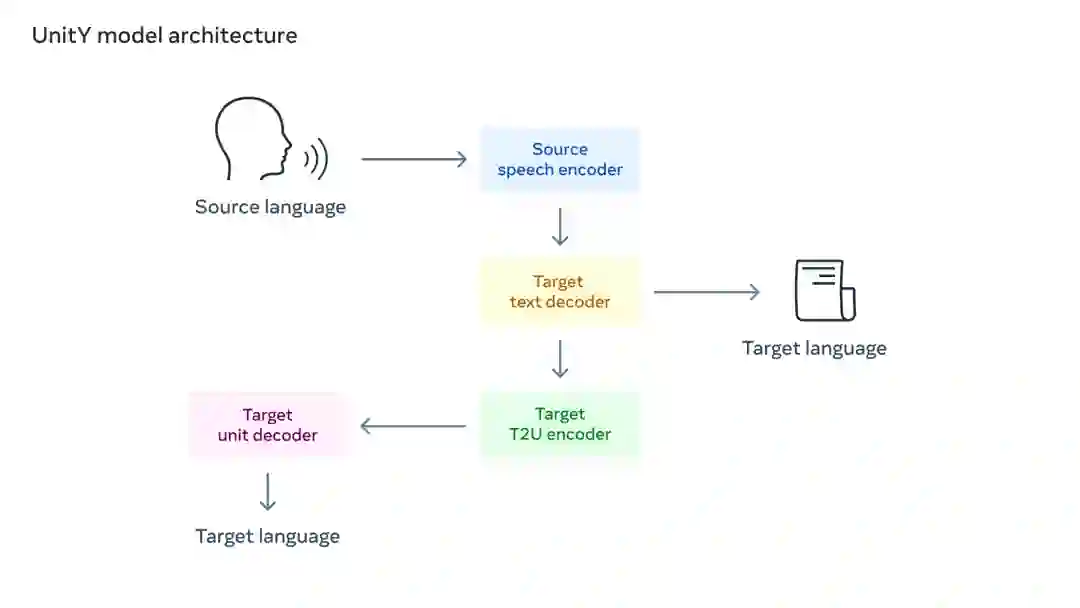
此外,UnitY 被用于双通解码机制,其中第一通解码器生成相关语言(汉语)的文本,而第二通解码器生成单元。
新的评估指标
新的评估指标
语音翻译系统通常使用ASR-BLEU指标进行评估,该指标包括首先使用自动语音识别(ASR)将翻译的语音转换成文本,然后通过将转换的文本与人工翻译的文本进行比较来计算 BLEU 分数(一种标准的机器翻译指标)。
然而,像闽南语这样的口语语音翻译的评估挑战之一是没有标准的书写系统。
为了能够自动评估,研究人员开发了一个系统,将闽南语转录成一个标准的语音符号,称之为 Tâi-lô,这项技术可以在音节水平上计算 BLEU 分数,并且很容易比较不同方法的翻译质量。
除了开发闽英语语音翻译的评估方法外,文中还建立了第一个基于闽南语语料库的闽英语双向语音翻译基准数据集 Taiwanese Across Taiwan

基准数据集将会开源以促进其他研究人员致力于闽南语语音翻译,并共同在该领域取得进一步的进展。
不止步于闽南语
不止步于闽南语
在目前阶段,该方法允许讲闽南语的人与讲英语的人交谈。虽然该模型仍在开发中,一次只能翻译一个完整的句子,但它是向着将来实现语言间同步翻译迈出的一步。
研究人员开创的闽南语技术可以推广到其他许多书面和非书面语言。
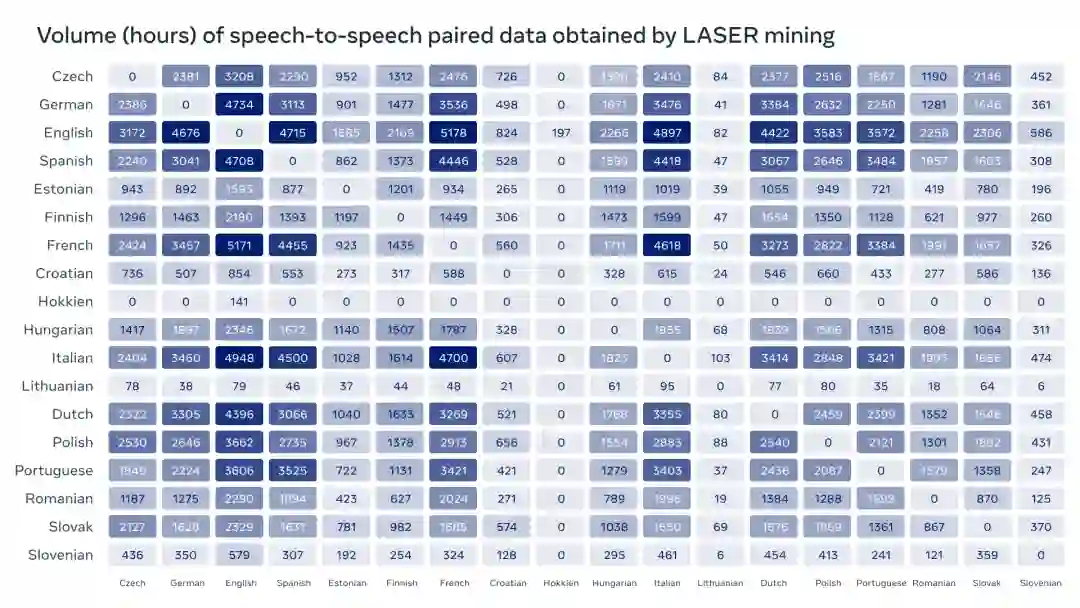
为此,Meta考虑未来发布一个大型语音对语音翻译语料库SpeechMatrix,也是采用Meta的创新数据挖掘技术LASER,使得研究人员能够基于该类工作创建自己的语音对语音翻译(S2ST)系统。
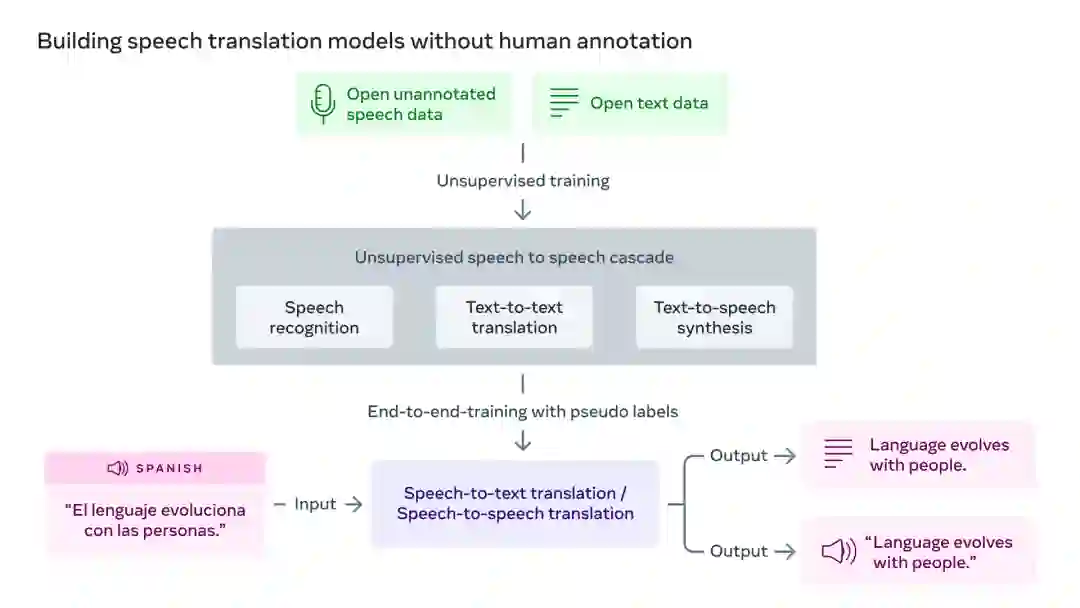
Meta 在无监督语音识别(wave 2vec-U)和无监督机器翻译(mBART)方面的最新进展将为未来翻译更多口语语言的工作提供参考。
非监督式学习翻译方面的进展证明了在没有任何人工注释的情况下建立高质量的语音到语音翻译模型的可行性,该类系统大大降低了扩大低资源语言覆盖面的要求,因为其中许多语言根本没有可用的标签数据。






