7 papers | Quoc V. Le、何恺明等新论文;用进化算法设计炉石
本周较为重要的研究有 Quoc V. Le 和何恺明各自在 ImageNet 上的新研究。同时 Keras 之父 François Chollet 针对智能水平的评价方法提出了自己的定义和基准。此外还有一些有趣的研究,如在股票预测任务上对比神经网络性能,以及使用进化算法设计炉石传说游戏等。
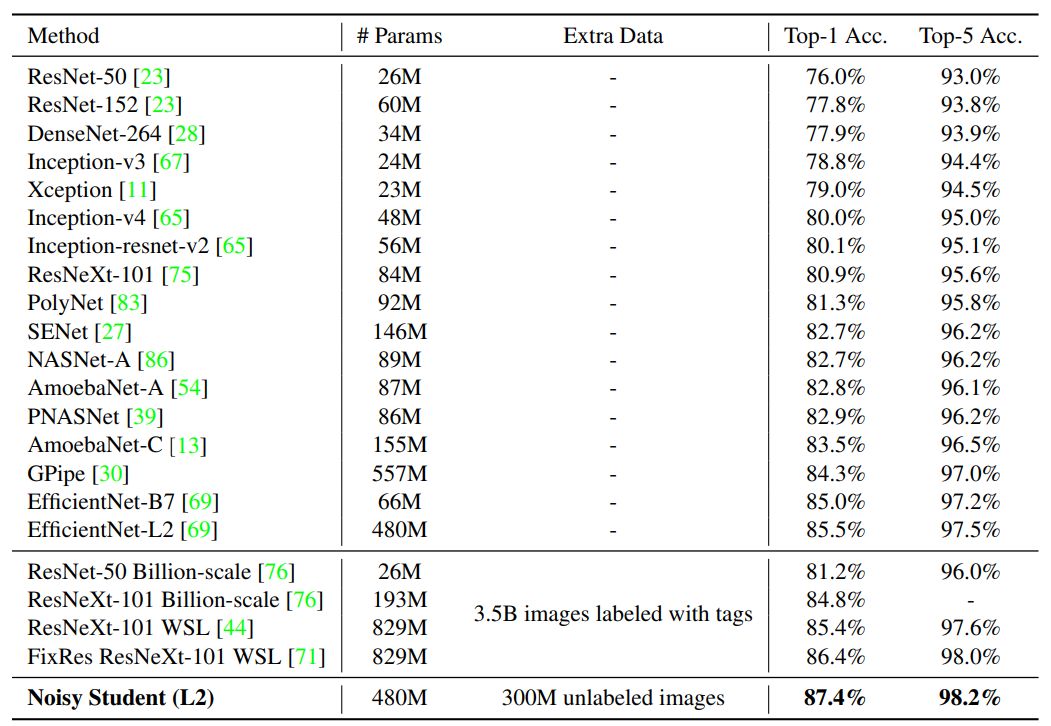
Self-training with Noisy Student improves ImageNet classification
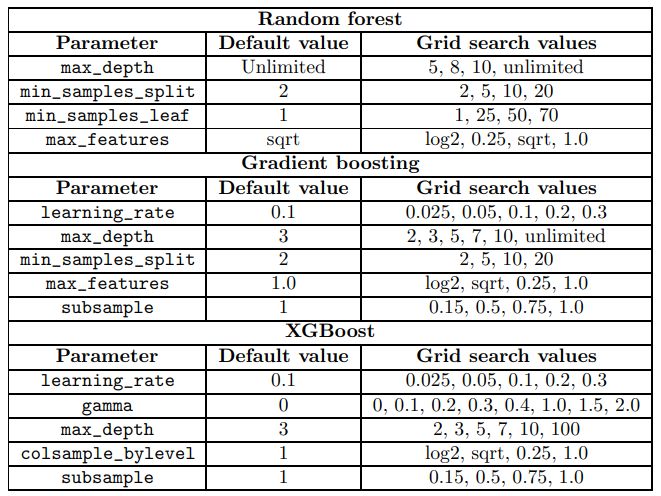
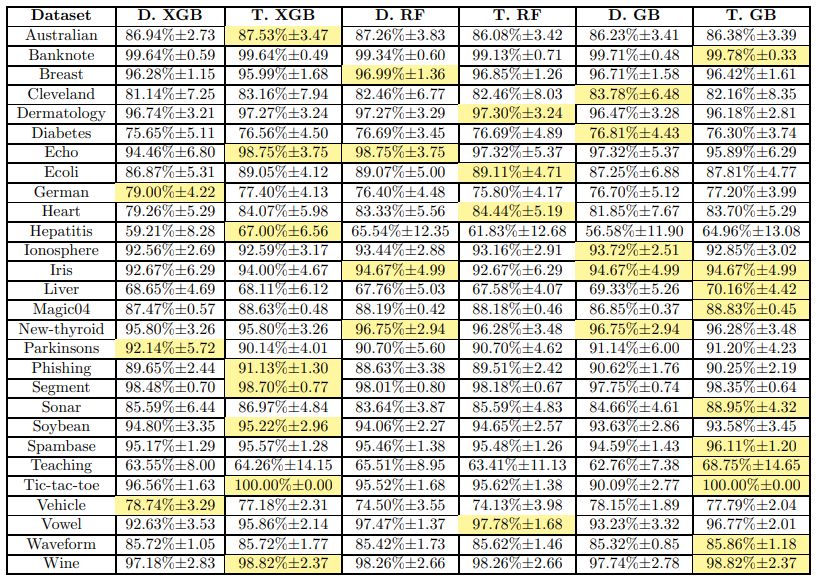
A Comparative Analysis of XGBoost
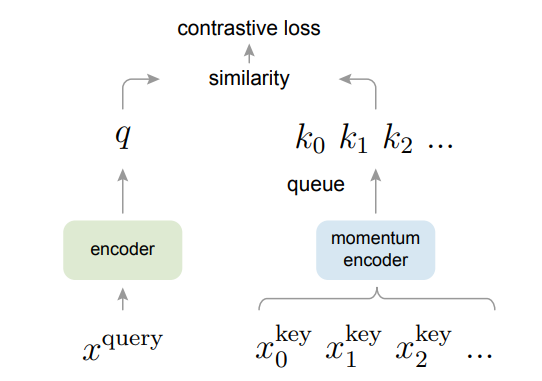
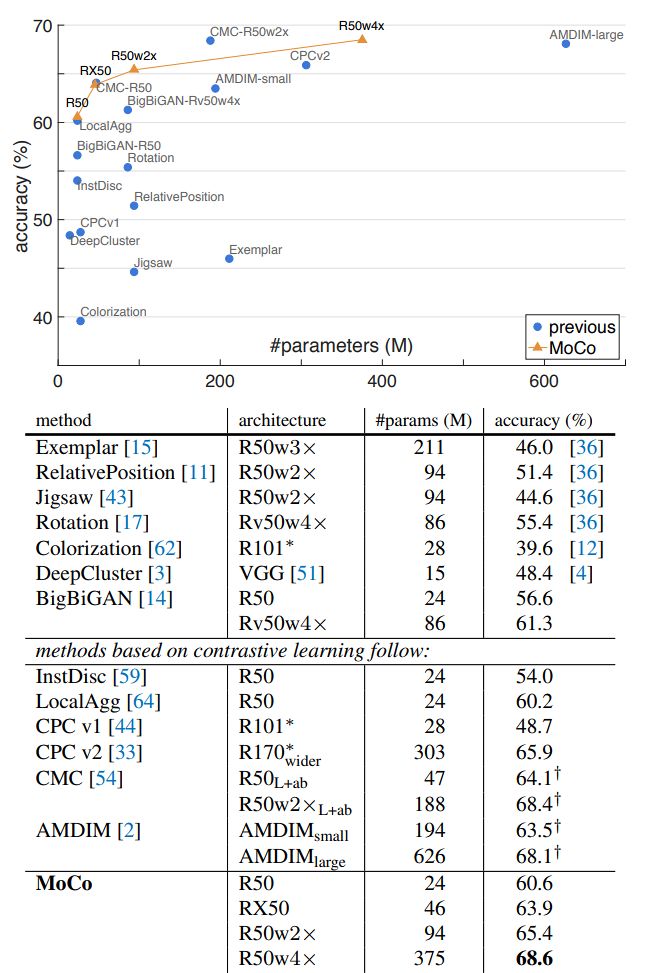
Momentum Contrast for Unsupervised Visual Representation Learning
Deep Learning for Stock Selection Based on High Frequency Price-Volume Data
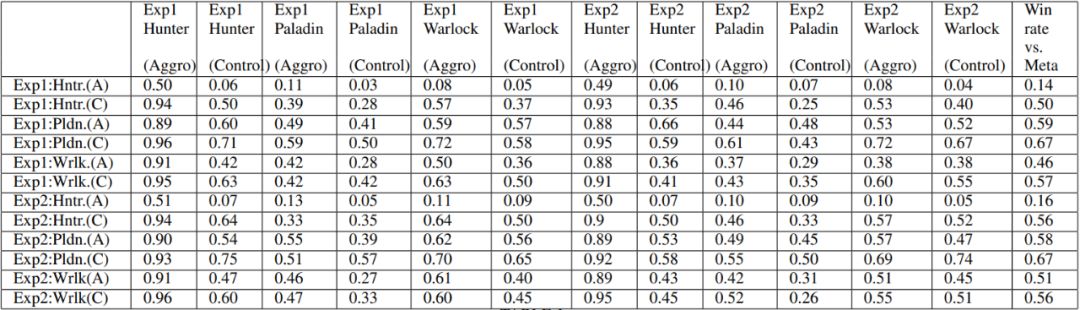
Evolving the Hearthstone Meta
The Measure of Intelligence
Emerging Cross-lingual Structure in Pretrained Language Models
作者:Qizhe Xie、Eduard Hovy、Minh-Thang Luong、Quoc V. Le
论文链接:https://arxiv.org/pdf/1911.04252.pdf

作者:Candice Bentéjac、Anna Csörgő、Gonzalo Martínez-Muñoz
论文链接:https://arxiv.org/pdf/1911.01914v1.pdf
作者:Kaiming He、Haoqi Fan、Yuxin Wu、Saining Xie、Ross Girshick
论文链接:https://arxiv.org/pdf/1911.05722.pdf
作者:Junming Yang、Yaoqi Li、Xuanyu Chen、Jiahang Cao、Kangkang Jiang
论文链接:https://arxiv.org/pdf/1911.02502v1.pdf
作者:Fernando de Mesentier Silva、Rodrigo Canaan、Scott Lee 等
论文链接:https://arxiv.org/pdf/1907.01623v1.pdf

作者:François Chollet
论文链接:https://arxiv.org/abs/1911.01547
作者:Shijie Wu、Alexis Conneau、Haoran Li、Luke Zettlemoyer、Veselin Stoyanov
论文链接:https://arxiv.org/pdf/1911.01464.pdf