WEB前端压缩看这里就够了

0写在前面
web前端在越来越多的Hmtl5游戏 web App的复杂的web运用中需要更多有针对的压缩方案。 本文抛砖引玉,聊一下基于前端javascript以及Html5线上有损图像压缩,无损数据压缩方案等运用。
web项目需求中有很多资源压缩优化有很多不错的方案
比如针对文本js的compress 以及服务器gzip,比如sprite雪碧图+png压图。

在越来越多的Hmtl5游戏 webApp的复杂的web运用中需要更多有针对的压缩方案。
本文抛砖引玉,聊一下基于前端javascript以及Html5线上有损图像压缩,无损数据压缩方案等运用。下图中分别列出了本文中涉及到了内容:
1概要
下图中分别列出了本文中涉及到了内容:![]()
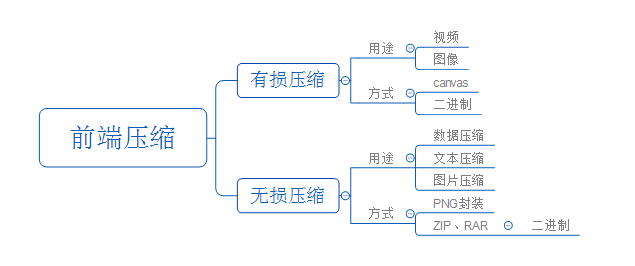
好,接下来才是本文的重点!
2分类
1)有损压缩
主要用于图像压缩:
用户自拍图片
验证信息的图片
随着智能化的云端服务,很多业务需要大量的线上智能化处理例如人脸识别。特点是本身对图片的质量要求不高(本身机器识别质量低速度更快,虽然这个速度差别可以忽略)压缩到1%的体积基本不影响。
主要原理方式:基于canvas API
new image() ->canvas->base64

例如,Mega组件:http://pub.code.oa.com/project/home?projectName=mega&comeFrom=newhome
2)无损压缩
主要用于数据压缩和下载:
a.数据压缩,文本压缩
可用用户操作大量数据后本地保存数据,上传数据。
b.下载
大资源(例如字体无法使用gzip)的运用
碎片资源打包(H5游戏中普遍使用)
无损压缩原理
无损压缩算法可行的基本原理是:任意一个非随机文件都含有重复数据,这些重复数据可以通过用来确定字符或短语出现概率的统计建模技术来压缩。
统计模型可以用来为特定的字符或者短语生成代码,基于它们出现的频率,配置最短的代码给最常用的数据。
这些技术包括熵编码(entropy encoding)、游程编码(run-length encoding)以及字典压缩。
运用这些技术以及其它技术,一个8-bit长度的字符或者字符串可以用很少的bit来表示,从而大量的重复数据被移除。
so,重点来啦!

在web前端进行无损压缩解压缩有以下方案:
3方案
方案一 基于LZ开头压缩算法等传统压缩方案(推荐)
基于JavaScript操作二进制数据的接口(ArrayBuffer对象、TypedArray对象、DataView对象)以及浏览器的APIFile APIcanvas等,
结合LZ开头的一些传统压缩算法:
1)LZ77算法对应ZIP
2)bzip2和lzma 算法对应 7zip
以下是一些普通的转换二进制算法:
1) File API
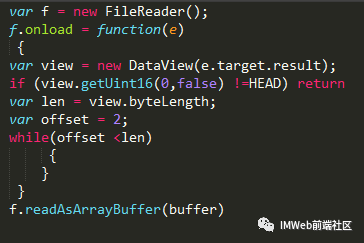
2) Base64->转换
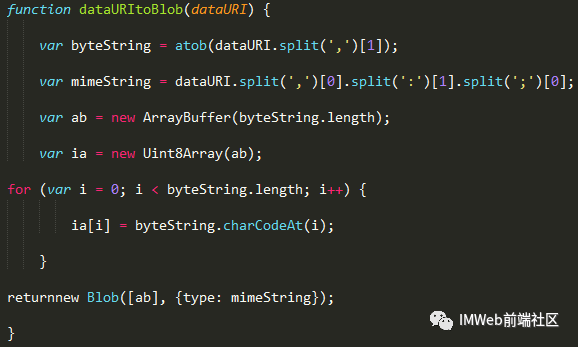
相关压缩算法已经很成熟可以查阅相关资料,下面推荐有关js库
推荐开源库:
https://stuk.github.io/jszip/(zip算法 api友好)
https://github.com/LZMA-JS/LZMA-JS(7zip 压缩率更好)
案例:
1)例如threejs 3d 的编辑器使用 jszip库线上压缩打包https://threejs.org/editor/
2)字体组件http://pub.code.oa.com/project/home?comeFrom=111&projectName=fontZip
方案二 利用png无损格式进行数据压缩
该方案做作为一种思路的发散了解,其中压缩率百分之五十。
大致流程为:

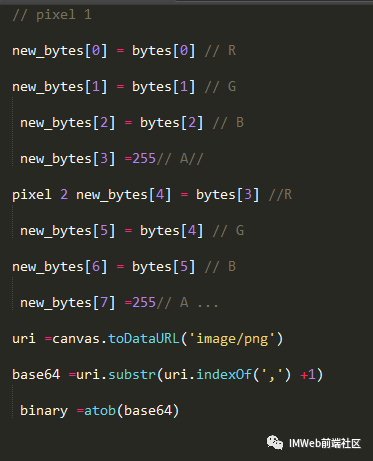
其中我们把普通数据当成像素点,画到 canvas 上,然后导出成 PNG格式的图片:
R = bytes[0] G = bytes[1] B = bytes[2] A = bytes[3]
浏览器为了提高渲染性能,有一个 Premultiplied Alpha 的机制。
并且alpha设置为255。
由此,基本算法:
技术文章结束啦,轻松一刻,小编送上!
可爱的宋民国,希望大家多多关注我们呦!

扫码下方二维码,
随时关注更多前端干货文章!
▼

微信:IMWebTech





