从注意力机制出发,上海交大提出实时语义分割新网络LRNNet
加入极市专业CV交流群,与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度 等名校名企视觉开发者互动交流!
同时提供每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流。关注 极市平台 公众号 ,回复 加群,立刻申请入群~

本文是 上海交通大学团队提出的轻量级实时语义分割算法。本文主要从视觉注意力机制中的non-local 模块出发,通过对non-local模块的简化,使得整体模型计算量更少、参数量更小、占用内存更少。在Cityscapes测试集上,没有预训练步骤和额外的后处理过程,最终LRNNET模型在GTX 1080Ti显卡上的速度为71FPS,获得了72.2% mIoU,整体模型的参数量仅有0.68M。
简介
语义分割可以看作是逐像素分类的任务,它可以为图像中的每个像素分配特定的预定义类别。该任务广泛应用于在自动驾驶领域。开发轻量,高效和实时的语义分割方法对于语义分割算法实际应用至关重要。在这些属性中,轻量级可能是最重要的属性,因为使用较小规模的网络可以导致更快的速度和更高的计算效率,或者更容易获得内存成本。
随着视觉注意力机制在计算机视觉领域的广泛应用。语义分割中也采用non-local网络来建模远程依赖(具体的Non-local网络的讲解可以参考公众号视觉注意力机制系列文章,在文末有推荐)。但是,针对每个像素建模位置关系计算和存储成本都非常大。本文利用spatial regional dominant singular vectors 得到更简洁但更具表示能力的non-local 模块,更加有效地建模远程依赖关系并进行全局特征选择。
本文的主要贡献:
1、本文提出了分解因子卷积块(FCB),通过更适当的方式处理远程依赖关系和短距离的特征来构建轻量级且高效的特征提取网络。
2、本文提出的高效简化Non-local模块,其利用了区域性奇异向量可产生更多的简化特征和代表性特征,以对远程依赖关系和全局特征选择进行建模。
3、实验显示了LRNNet在Cityscapes数据集和Camvid数据集上兼顾了计算速度和分割精度,都具有不错的表现。
本文方法

LRNNet整体结构:(a)LRNNet的编码器,由分解因子卷积块(FCB)和下采样模块组成 (b)LRNNet带SVN模块的解码器。上分支以不同比例的区域优势奇异向量来执行非局部运算。红色箭头表示1×1卷积,可调整通道大小以形成瓶颈结构。分类器(classifier)包括一个3×3卷积,然后是一个1×1卷积。
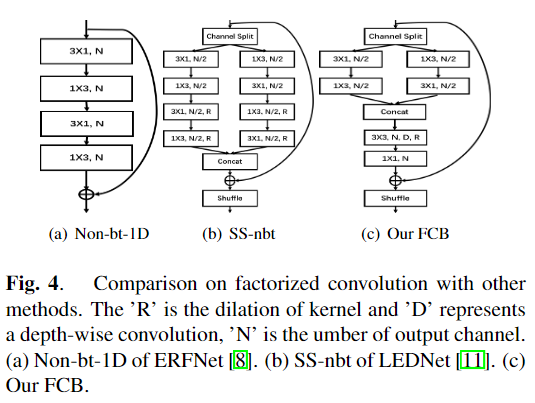
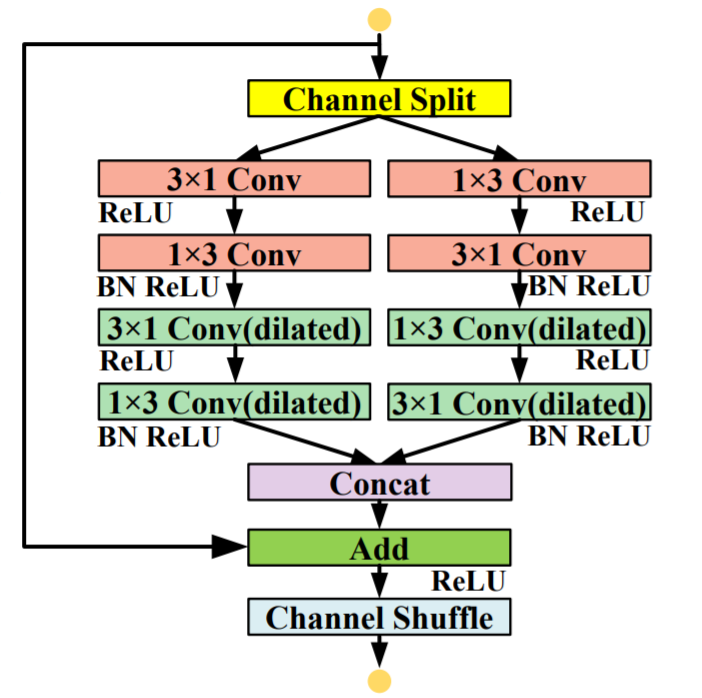
def Split(x):c = int(x.size()[1])c1 = round(c * 0.5)x1 = x[:, :c1, :, :].contiguous()x2 = x[:, c1:, :, :].contiguous()return x1, x2def Merge(x1,x2):return torch.cat((x1,x2),1)def Channel_shuffle(x,groups):batchsize, num_channels, height, width = x.data.size()channels_per_group = num_channels // groupsx = x.view(batchsize,groups,channels_per_group,height,width)x = torch.transpose(x,1,2).contiguous()x = x.view(batchsize,-1,height,width)return xclass SS_nbt_module_paper(nn.Module):def __init__(self, chann, dropprob, dilated):super().__init__()oup_inc = chann//2self.conv3x1_1_l = nn.Conv2d(oup_inc, oup_inc, (3,1), stride=1, padding=(1,0), bias=True)self.conv1x3_1_l = nn.Conv2d(oup_inc, oup_inc, (1,3), stride=1, padding=(0,1), bias=True)self.bn1_l = nn.BatchNorm2d(oup_inc, eps=1e-03)self.conv3x1_2_l = nn.Conv2d(oup_inc, oup_inc, (3,1), stride=1, padding=(1*dilated,0), bias=True, dilation = (dilated,1))self.conv1x3_2_l = nn.Conv2d(oup_inc, oup_inc, (1,3), stride=1, padding=(0,1*dilated), bias=True, dilation = (1,dilated))self.bn2_l = nn.BatchNorm2d(oup_inc, eps=1e-03)self.conv3x1_1_r = nn.Conv2d(oup_inc, oup_inc, (3,1), stride=1, padding=(1,0), bias=True)self.conv1x3_1_r = nn.Conv2d(oup_inc, oup_inc, (1,3), stride=1, padding=(0,1), bias=True)self.bn1_r = nn.BatchNorm2d(oup_inc, eps=1e-03)self.conv3x1_2_r = nn.Conv2d(oup_inc, oup_inc, (3,1), stride=1, padding=(1*dilated,0), bias=True, dilation = (dilated,1))self.conv1x3_2_r = nn.Conv2d(oup_inc, oup_inc, (1,3), stride=1, padding=(0,1*dilated), bias=True, dilation = (1,dilated))self.bn2_r = nn.BatchNorm2d(oup_inc, eps=1e-03)self.relu = nn.ReLU(inplace=True)self.dropout = nn.Dropout2d(dropprob)def forward(self, x):residual = xx1, x2 = Split(x)output1 = self.conv3x1_1_l(x1)output1 = self.relu(output1)output1 = self.conv1x3_1_l(output1)output1 = self.bn1_l(output1)output1_mid = self.relu(output1)output2 = self.conv1x3_1_r(x2)output2 = self.relu(output2)output2 = self.conv3x1_1_r(output2)output2 = self.bn1_r(output2)output2_mid = self.relu(output2)output1 = self.conv3x1_2_l(output1_mid)output1 = self.relu(output1)output1 = self.conv1x3_2_l(output1)output1 = self.bn2_l(output1)output2 = self.conv1x3_2_r(output2_mid)output2 = self.relu(output2)output2 = self.conv3x1_2_r(output2)output2 = self.bn2_r(output2)if (self.dropout.p != 0):output1 = self.dropout(output1)output2 = self.dropout(output2)out = Merge(output1, output2)out = F.relu(residual + out)out = Channel_shuffle(out,2)return out
解码器环节
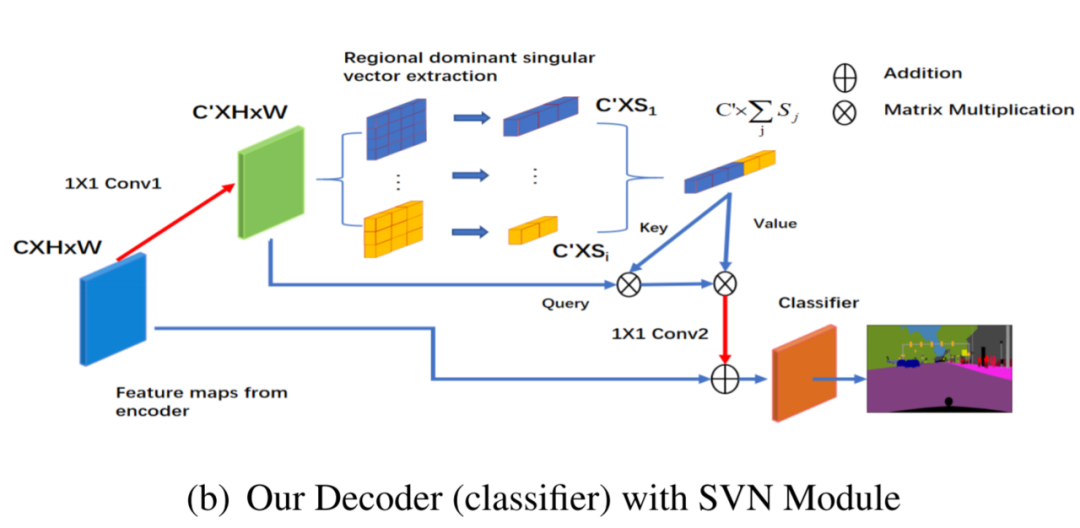

实验与结果
在消融实验中,将不带SVN的LRNNet表示为model A,带单尺度的SVN(有64(8×8)个子区域)表示为model B和带多尺度的SVN(有8×8 + 4×4个子区域)表示model C。
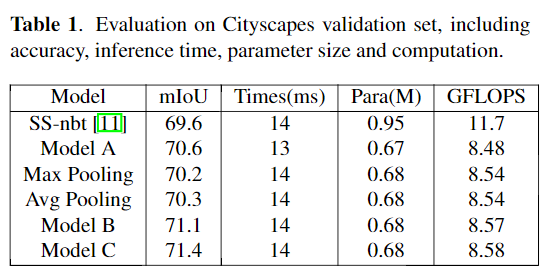
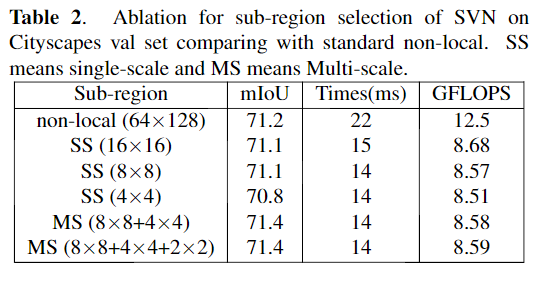

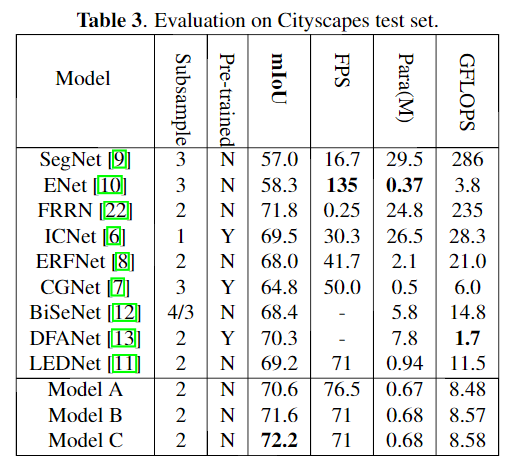

更多实验细节可以参考原文。
推荐阅读:

添加极市小助手微信(ID : cv-mart),备注:研究方向-姓名-学校/公司-城市(如:AI移动应用-小极-北大-深圳),即可申请加入AI移动应用极市技术交流群,更有每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、行业技术交流,一起来让思想之光照的更远吧~

△长按添加极市小助手

△长按关注极市平台,获取最新CV干货
觉得有用麻烦给个在看啦~


