本周重要论文包括获得 AAAI 2022 以及 WSDM 2022 会议的各奖项论文,以及华为诺亚的视觉 Transformer 综述。
Online Certification of Preference-based Fairness for Personalized Recommender Systems
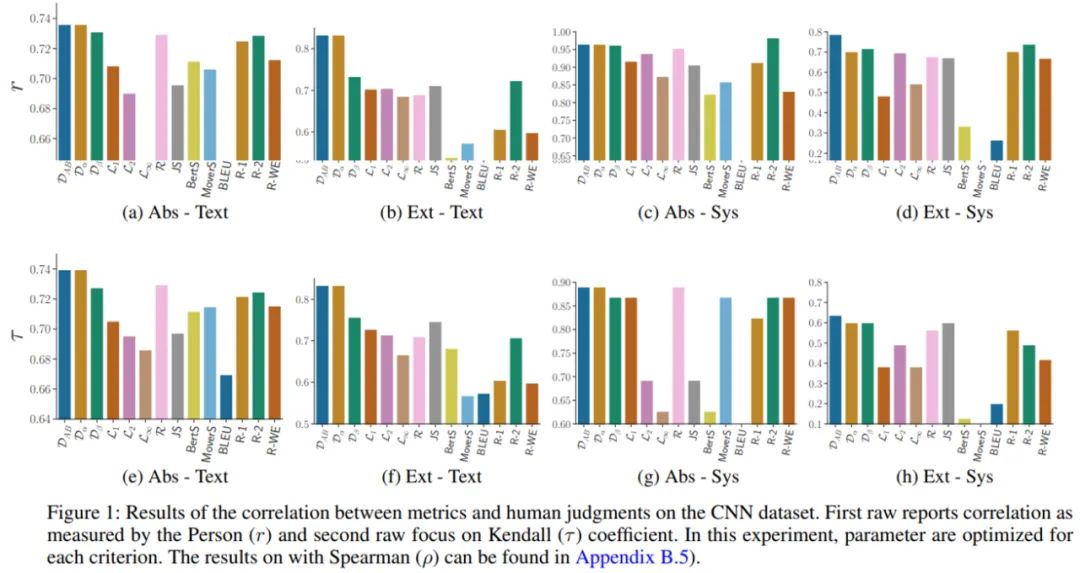
InfoLM: A New Metric to Evaluate Summarization & Data2Text Generation
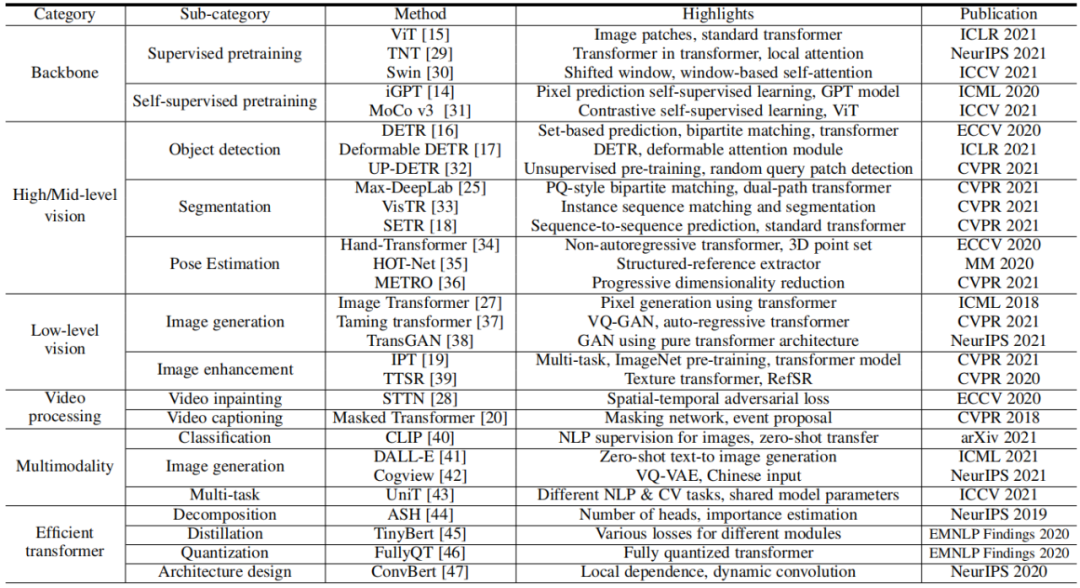
A Survey on Vision Transformer
Information Flow in Deep Neural Networks
Learning Discrete Representations via Constrained Clustering for Effective and Efficient Dense Retrieval
Using Deep Learning to Annotate the Protein Universe
Should You Mask 15% in Masked Language Modeling?
ArXiv Weekly Radiostation:NLP、CV、ML 更多精选论文(附音频)
论文 1:Online Certification of Preference-based Fairness for Personalized Recommender Systems
摘要:
推荐系统正面临审查,因为它们对用户的影响越来越大。当前的公平审计仅限于敏感群体级别的粗粒度奇偶校验评估。该研究建议审计应该「envy-freeness」,这是一个与个人偏好一致的更细化的标准:每个用户都应该更喜欢符合自己的推荐而不是其他用户的推荐。由于「envy」审计需要估计用户现有推荐之外的偏好。该研究提出了一种样本高效算法,理论上保证推荐系统不会降低用户体验。此外,他们还研究了所提方法在现实世界推荐数据集上可以实现的权衡。
下图为审计场景:审计员要么在当前推荐中向用户展示他们的推荐系统,或通过向其他用户显示推荐来进行探索:
![]()
![]()
论文 2:InfoLM: A New Metric to Evaluate Summarization & Data2Text Generation
摘要:
通过人工注释评估自然语言生成系统质量的方法成本非常高,并且非常耗时。因此在实践中,研究人员大多依靠自动指标来评估模型质量。过去十年,领域内涌现出许多基于字符串的指标(例如 BLEU)。但是,此类指标通常依赖于精确的匹配,因此不能稳健地处理同义词。
基于此,该研究提出了一系列未经训练的指标 InfoLM,这些指标可被视为基于字符串的指标,但借助预训练掩码语言模型解决了上述缺陷。这些指标还利用信息度量,允许 InfoLM 适应各种评估标准。该研究使用直接评估证明了 InfoLM 显著改进了文本摘要和 data2text 生成任务的许多配置,并获得了超过 10 点的相关增益。
![]()
论文 3:A Survey on Vision Transformer
摘要:
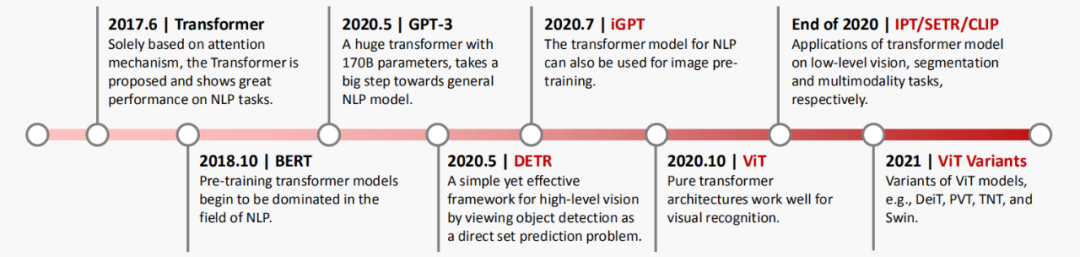
2021 年对计算机视觉来说是非常重要的一年,各个任务的 SOTA 不断被刷新。这么多种 Vision Transformer 模型,到底该选哪一个?新手入坑该选哪个方向?华为诺亚方舟实验室的这一篇综述或许能给大家带来帮助。
图 1 展示了视觉 Transformer 的发展里程碑,从图像分类到目标检测,从图片生成到视频理解,视觉 Transformer 展现出了非常强的性能。
![]()
![]()
推荐:
华为诺亚调研 200 多篇文献,视觉 Transformer 综述入选 TPAMI 2022。
论文 4:Information Flow in Deep Neural Networks
摘要:
尽管深度神经网络已经取得了巨大的成功,但我们还没有一个全面的理论来解释这些网络如何工作或如何构造。深度网络通常被视为黑盒,我们无法清楚地解释它们的预测结果或可靠性。如今,了解深度神经网络的突破性性能是科学界面临的最大挑战之一。为了更有效地使用这些算法并改进它们,我们需要了解它们的动态行为(dynamic behavior)以及它们学习新表示的能力。
在这篇博士论文中,作者应用了信息论中的原理和技术来解决上述问题,以提高我们的理论理解,并运用这一理解来设计更好的算法。第二章和第三章介绍了作者针对深度学习模型提出的信息论方法。第四章讨论了将 IB 应用于深度神经网络时最困难的问题之一 —— 估计高维空间中的互信息。第五章介绍了一个新的信息论框架 —— 双重信息瓶颈(dualIB)。
![]()
推荐:
信息瓶颈提出者 Naftali Tishby 生前指导,129 页博士论文「神经网络中的信息流」公布。
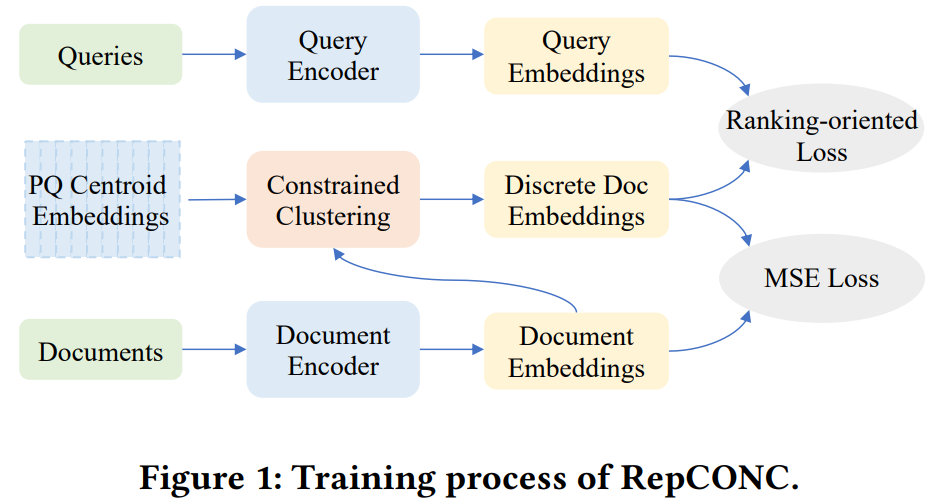
论文 5:Learning Discrete Representations via Constrained Clustering for Effective and Efficient Dense Retrieval
摘要:
密集检索(DR)已经实现了 SOTA 排序效果。然而,大多数现有 DR 模型的效率受到一些限制,特别是存储密集向量需要大量内存成本,并且在向量空间中做最近邻搜索(NNS)非常耗时。
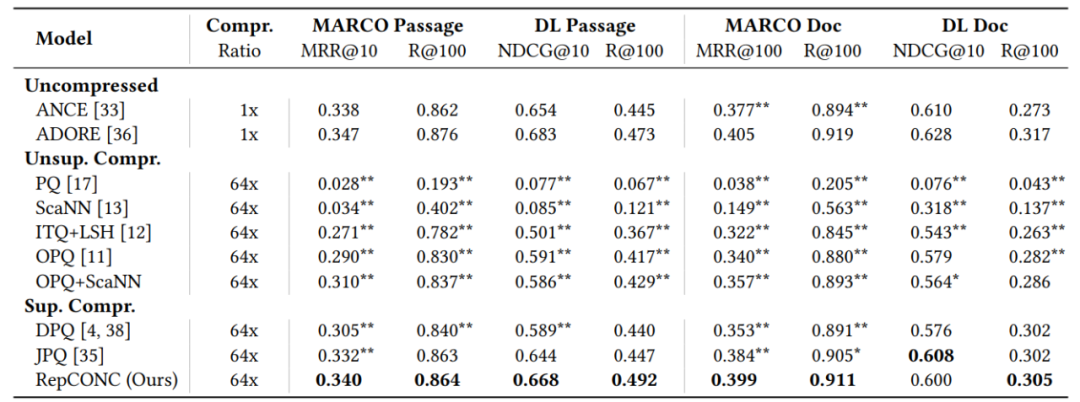
因此,该研究提出了一种新型检索模型 RepCONC,通过约束聚类(CONstrained Clustering)学习离散表征。RepCONC 联合训练双编码器和乘积量化(PQ)方法来学习离散文档表征,并实现具有紧凑索引的快速近似 NNS。它将量化建模为一个受约束的聚类过程,这要求文档嵌入围绕量化质心均匀聚类,并支持量化方法和双编码器的端到端优化。该研究从理论上证明了 RepCONC 中均匀聚类约束的重要性,并通过将其简化为最优传输问题的一个实例,为约束聚类导出了一个有效的近似解。除了约束聚类,RepCONC 进一步采用基于向量的倒排文件系统 (IVF) 来支持 CPU 上的高效向量搜索。
对两个流行的 ad-hoc 检索基准进行的大量实验表明,在多种压缩比设置下,RepCONC 比其他向量量化基准实现了更好的排序效果,它在检索效率、记忆效率和时间效率方面也大大优于现有的各种检索模型。
![]()
![]()
TREC 2019 Deep Learning Track 上不同压缩方法的比较。
推荐:
清华、人大等机构学者获得数据挖掘顶会 WSDM22 唯一最佳论文奖。
论文 6:Using Deep Learning to Annotate the Protein Universe
摘要:
蛋白质是组成人体一切细胞、组织的重要成分。机体所有重要的组成部分都需要有蛋白质的参与。目前已知存在的蛋白质种类有数十亿,但其中大约有三分之一的功能是不可知的。我们迫切地需要探索这片未知区域,因为它们关系到抗菌素耐药性,甚至气候变化等重要议题。例如,青霉素是蛋白质之间自然反应的产物,植物蛋白可用于减少大气中的二氧化碳。
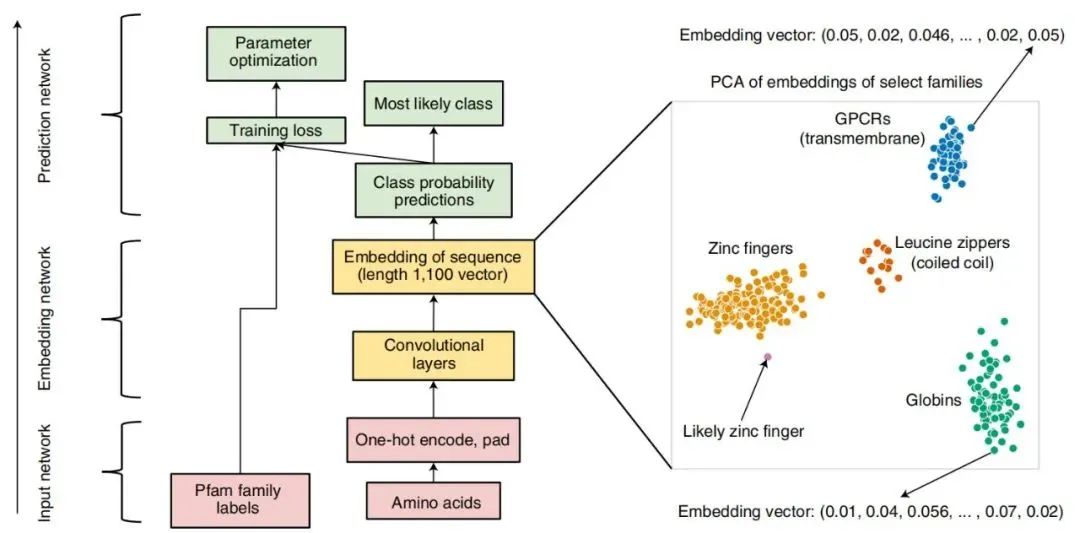
近日,谷歌与欧洲生物信息学研究所合作开发了一种技术 ProtCNN,其能够使用神经网络可靠地预测蛋白质功能,帮助我们缩小蛋白质宇宙中最后不可见的区域。谷歌表示,这种新方法可以较为准确地预测蛋白质功能、突变的功能效应,并进行蛋白质设计,进而应用于药物发现、酶设计,甚至了解生命的起源。谷歌的方法可靠地预测了更多蛋白质的作用,而且它们快速、便宜且易于尝试,其研究已让主流数据库 Pfam 中注释的蛋白质序列增加了近 10%,一举超过了过去十年的增速,并预测了 360 种人类蛋白质功能。
![]()
Pfam 数据库是一系列蛋白质家族的集合,其中每一个蛋白家族都以多序列比对和隐马尔科夫模型的形式来表示。
![]()
ProtCNN 的架构。中心图展示了输入(红色)、嵌入(黄色)和预测(绿色)网络以及残差网络 ResNet 架构(左),而右图展示了 ProtCNN 和 ProtREP 通过简单的最近邻方法利用。
推荐:
谷歌 AI 一次注释了 10% 的已知蛋白质序列,超过人类十年研究成果。
论文 7:Should You Mask 15% in Masked Language Modeling?
摘要:
预训练语言模型已经改变了自然语言处理领域的格局。大型语言模型经过巨量文本数据的训练,可获得丰富多样的语言表示能力。与总是预测序列中下一个 token 的自回归模型相比,像 BERT 这样的掩蔽语言模型(MLM)会根据上下文预测输入 token 的掩蔽子集,由于具有双向性质,此方法效果通常更佳。此种方法是把模型限制为只掩蔽一小部分 token 内容开始进行学习的,通常为每序列 15%。15% 的数字反映 le 这样一个假设 —— 若掩蔽太多文本,则模型无法很好地学习表示,这一思路被 BERT 之后的研究普遍采用。同时,仅对 15% 的序列进行预测已被视为对 MLM 进行有效预训练的限制。
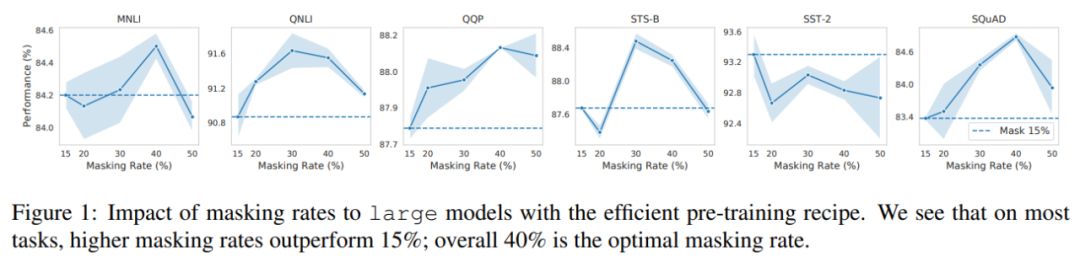
在普林斯顿大学陈丹琦等人的研究中,作者发现了与此前结论完全不同的情况:在有效的预训练方案下,他们可以掩蔽 40-50% 的输入文本,并获得比默认的 15% 更好的下游性能。
![]()
不同掩蔽率下的掩蔽示例、验证困惑度和下游任务性能。在这里,所有模型都是有效预训练条件下训练的大模型。
![]()
掩蔽率对具有高效预训练方案的大模型的影响。研究者发现,在大多数任务中,更高的掩蔽率比 15% 的掩蔽率表现更好,40% 是最佳的掩蔽率。
推荐:
陈丹琦组掩蔽语言模型研究引争议:15% 掩蔽率不是最佳,但 40% 站得住脚吗?
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com