SemBERT: BERT 的语义知识增强
至此,GLUE leaderboard 上模型基本都公布了细节,上次是阿里的 ALICE,这次是云从科技和上交的 SemBERT。重新看了看 Leaderboard,却发现榜首已不是 RoBERTa,而成了 Adv-RoBERTa(ensemble),来自微软和UMD(马里兰大学)。

Adv-RoBERTa 只公布了粗略信息
We adopt an improved adversarial training approach to fine-tune the pre-trained RoBERTa_large models on each task, using the same data and number of training iterations as RoBERTa.Results are based on ensembles of 7 models.
大概就是在 RoBERTa 下游任务中加入了对抗性训练方法,结果是七个模型集成的表现,单一模型表现可能还得等更详细结果放出。
回归正题,关于 SemBERT,其实是 NLP 发论文很通常的一条路线,就是对某些通用模型,将语言学的一些知识给结合进去,从而获得些提高,之前研究过的 linguistic-aware NMT 就是差不多思路。而 SemBERT 就是想把 Semantic Role Labeling (SRL,语义角色标注) 的知识给结合进 BERT(实际不是从 BERT 模型内部)。
关于如何结合 SRL 的知识,我想请大家从第一人称视角出发,来思考这个问题。这样之后发文也可以参考这种思路。
获得 SRL 标注
首先对于一批语料,我们怎样获得 SRL 的知识呢?
方法一,花钱请标注;
方法二,找现成的最好 SRL 标注工具,自动标注。
显然方法一过于昂贵,而方法二更加经济实惠,而且想要多少有多少。
于是用目前最好的模型,参考 Deep Semantic Role Labeling: What Works and What’s Next,在英文的 OntoNotes v5.0 上训练,然后获得 SRL 标注器,在 CoNLL-2012 测试集上 F1 分能达到 84.6%。
融合多种语义标签(Semantic Labels)
对于同一句话,语义标签有多种标法,可以将这个当作从不同角度看待一句话。
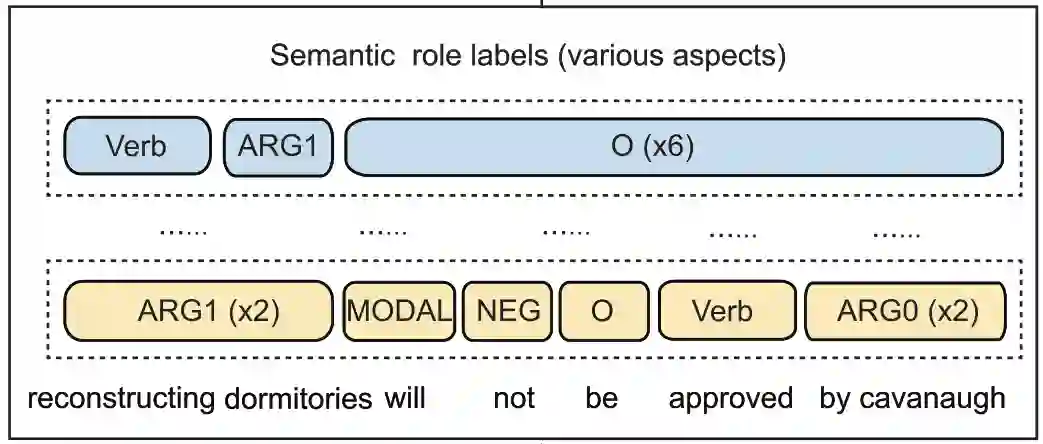
于是首先就需要解决如何获得各个角度语义标签更深层次信息,还有怎么将不同角度的语义标签信息结合到一起。
针对第一条获得更深层次信息,我们只需要对各个标签建立向量表,取向量,之后简单地用一个双向 GRU(BiGRU) 模型来获得深层的全局双向信息即可。
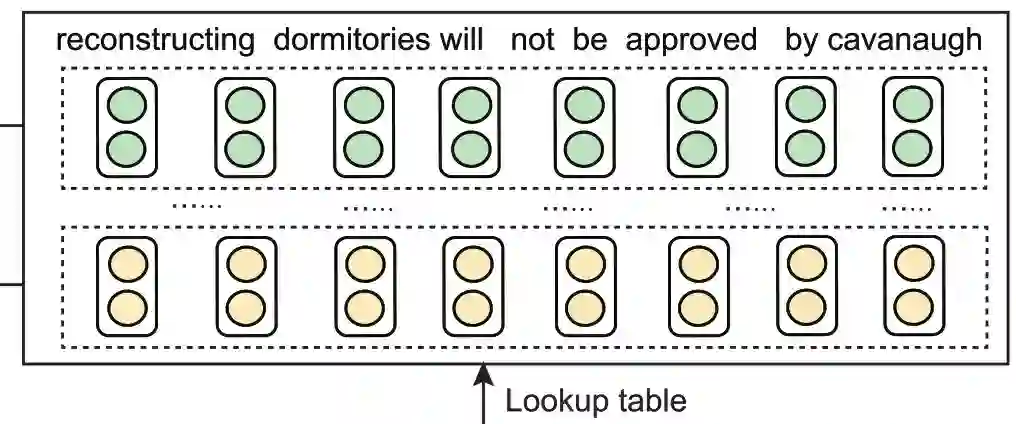
对于第二条,怎么将不同角度语义信息结合起来,就更简单,直接拼接起来,过个全连接层。
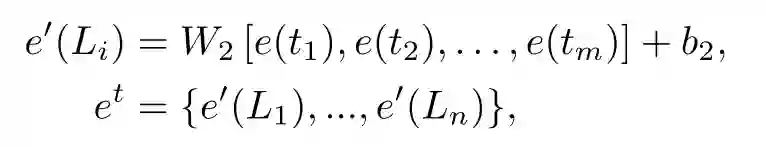
最后就获得了需要文本对应语义标签信息。
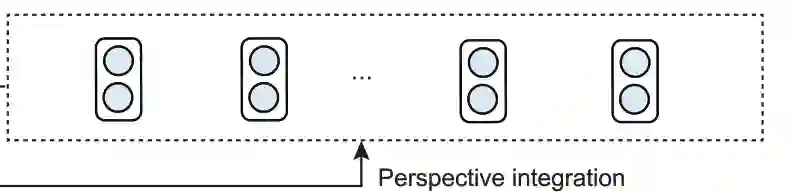
对齐 SRL 和 BERT 的粒度
有了每个词对应的 SRL 信息向量后,最简单的结合就是直接和 BERT 的输出向量拼起来。但当你准备拼的时候,就突然发现问题了,这特么怎么对不上,就像你拿着两孔插头去插三孔插座一样。
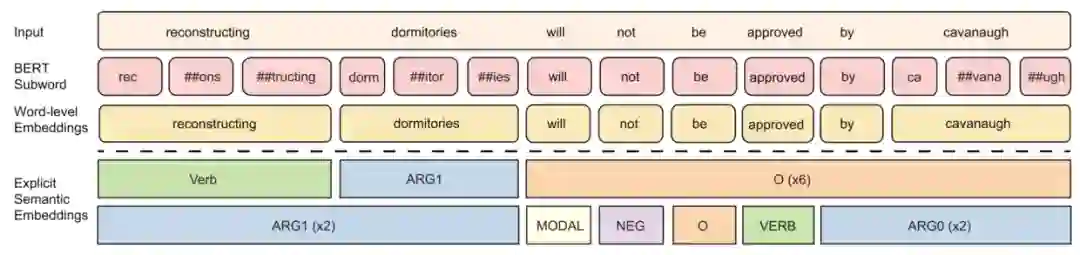
原来 BERT 词表用了 BPE(Byte Pair Encoding),会把词分成子词(subword)。
于是需要思考一下,怎样将子词向量结合成一个词向量。当然,粗暴一些就直接 pooling 一下,average 或 max 都随意。
要高级一些,那就用 RNN 或 CNN,可以像这里一样,直接用 CNN 卷一下,过个 ReLU,再 max pooling。
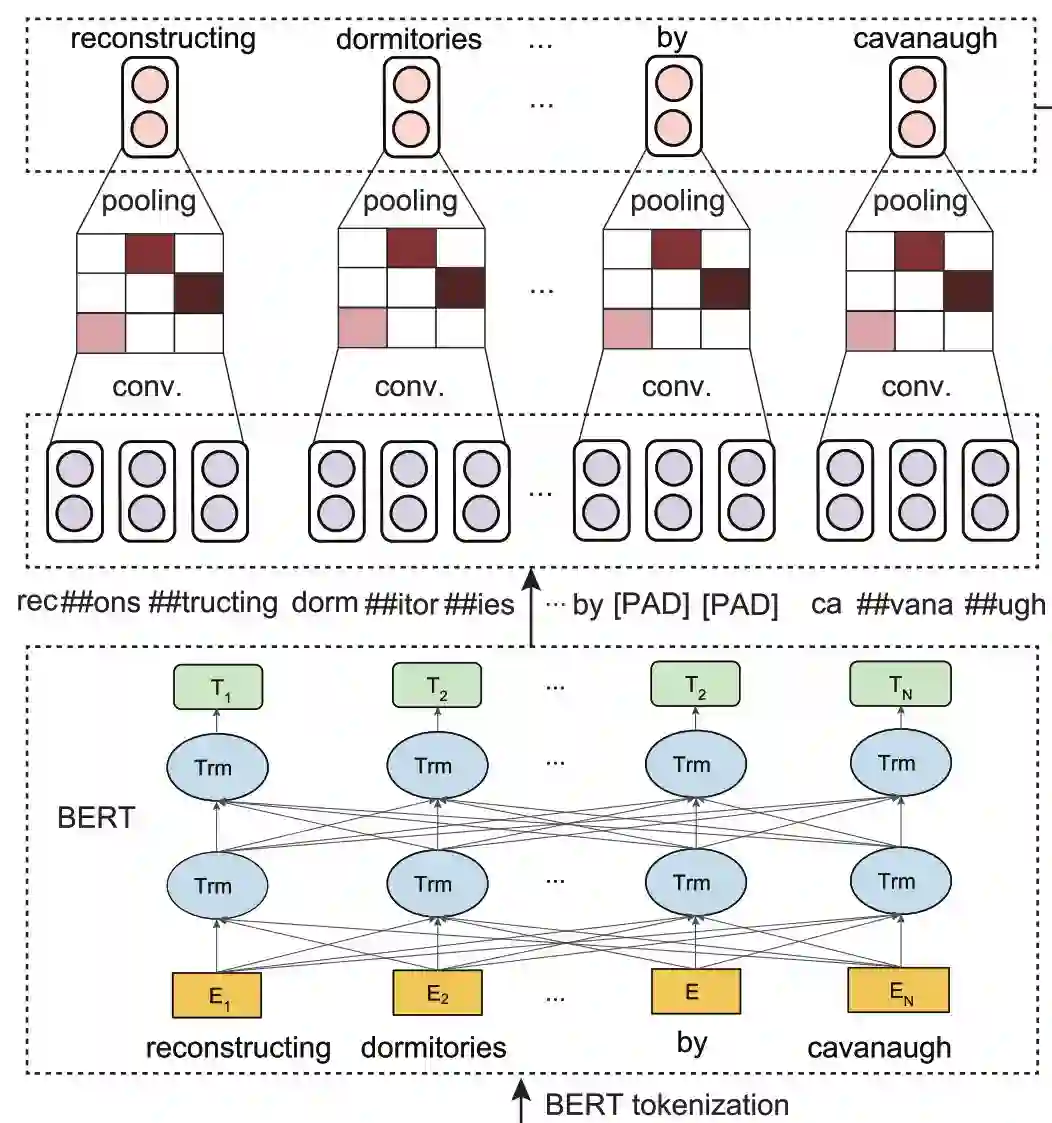
于是就获得了各个词所对应的 BERT 输出向量了。
合体!!!
粒度对齐,就到了最后一步了,将 SRL 向量和 BERT 向量合体!
I have a Sem, I have a BERT, I have a SemBERT.

本文转载自公众号:安迪的写作间,作者:Andy
推荐阅读
T5 模型:NLP Text-to-Text 预训练模型超大规模探索
BERT 瘦身之路:Distillation,Quantization,Pruning
Transformer (变形金刚,大雾) 三部曲:RNN 的继承者
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLP君微信(id:AINLP2),备注工作/研究方向+加群目的。


