来看看新一代 MIM 青年 CAE 是如何克服 MAE 中表征学习不充分的问题

极市导读
北大等提出的一种新的MIM方法CAE:通过对表征学习和 “解决 pretext task” 这两个功能做尽可能的分离,使得encoder学习到更好的表征,从而在下游任务实现了更好的泛化性能。这是一篇效果超越了恺明大神MAE的工作,它的优势究竟在何处,是如何对MAE进行改进的?来看看作者风趣幽默的解读吧! >>加入极市CV技术交流群,走在计算机视觉的最前沿
前言
自从恺明大神的 MAE(Masked AutoEncoder) 横空出世后,SSL(Self-Supervised Learning, 自监督学习) 圈子的风气已经逐渐从往日的 Contrasive Learning(对比学习) 转移到 MIM(Masked Image Modeling) 这类方法中来了,孰优孰劣还请各位江湖大侠各抒己见(CW 最爱听大家吹水了)。
新旧交替乃世间常态,新事物在刚冒尖的时期很容易博得眼球,许多头脑发热的“热力青年”可能以为这就 yyds 了(中招的可别怪 CW 哦),但也正是在这时期,新事物往往存在着一些“漏洞”。
这不,五四青年节才过不久,一位叫作 CAE(Context AutoEncoder) 的新青年就出来“抓毛病”了,他说:别看 MAE 火遍大江南北,其实他并未完全激发 Encoder 的表征学习能力!
“哦?”底下观众(CW 也是其中的一位)不禁发出疑问的呼声。
因为不想被蒙在鼓里,所以 CW 花时间去调查了下 CAE 这位新青年的背景,把它的 motivation, method & code 都研究了下,最终得以释怀。
当然,我也不独食,好酒好菜还是要和各位朋友们分享,现在,就请大家敞开胃口开吃吧!
新青年 CAE
CAE 是一位很有思想的新青年,虽然 MAE 是目前 MIM 圈子中的当红大咖,这点毋庸置疑,但是 CAE 并不盲从,他在向 MAE 学习的同时,还冷静地分析了对方的招(套)数(路),从而发现 MAE 存在一些不足的方面。
于是,趁着五四青年节之际,新青年风气尚未完全弥散,他决定向大家分享下自己的研究成果,包括 MAE 的不足以及自己的改进方法。CAE 之所以这么做,并不是为了向大家炫耀,而是为了促进整个圈子的学术风气,希望大家对于每个方法都有自己的独到见解,并且能够开放地进行交流。这样,由于思想的碰撞才可能诞生更多的可能性,最终使整个圈子共同进步!
MAE 的“毛病”
扯了这么多,是时候进入主题了(其实是 CW 不吹一下水的话会找不到节奏,没有 feel..)。那么,MAE 到底有什么“毛病”呢?
先来简短地回顾下 MAE 在预训练时的做法,他的 Encoder 仅接受 visible(un-masked) patches,然后将编码后的结果送给 Decoder。除此之外,Decoder 中还会输入 masked tokens,最终以预测出 masked patches 的像素值。
(对于 MAE 不了解的可以参考下 CW 的以下这篇文章)
在这种“分工”体系中,Encoder 负责学习通用表征,Decoder 主要是为了完成预训练代理任务。因此,在做下游任务时,Encoder 会被保留下来使用,而 Decoder 通常会被“抛弃”(因为下游任务的形式与预训练的通常不一样,也就是训练目标不一致)。于是,Encoder 是否足够“强大”、学习到的表征质量是否足够好才是关键。
普通老百姓会觉得,没问题呀,这里 Encoder & Decoder 解耦,前者学特征、后者完成预训练代理任务,挺好的嘛~
然而,CAE 则抓到了一个关键点 —— 由于 Decoder 中也同时输入了 Encoder 输出的编码特征,那么在完成预训练代理任务的时候,就会对这部分也进行优化。因此,尽管 Encoder 抽取的表征质量不够好,也没关系!Decoder 也会对这部分进行优化(Decoder 对 Encoder 说:我不需要你那么优秀,我也不差!)。
于是,这就限制了 Encoder 的表征学习能力,因为没有足够的“压迫力”来充分激发它的潜能,Decoder 会 carry 部分表征学习的职责(Encoder 对 Decoder 说:你居然“偷偷”学特征,抢我 KPI,过份!)。
另外,CAE 进一步指出,不仅仅是 MAE,在一些老前辈如 BEiT、ViT 等的方法中,往往用同一个架构(即不解耦 Encoder & Decoder)进行编解码,这也限制了模型表征学习的能力,因为它必须分出一部分精力去完成目标任务。
CAE 的“药方”
有病就得治(MAE 忍不住喷了句:你才有病),于是 CAE 结合各位前辈与自己的经验,设计出了对应的“药方”:
-
进一步解耦编码和解码的角色(如 MAE 前辈一般,只不过它没有完全做好..),前者专心做内容理解,后者专心去预测目标,从而充分激发编码器表征学习的潜能,进而提升表征质量; -
在潜在表征空间中基于 visible patches 去预测 masked patches(具体后文会解释),而非像 MAE 那样直接将 visible patches 的特征也输入到 Decoder。CAE 的这个出发点是为了 避免让 Encoder 之外的其它部分去学习特征,而是基于 Encoder 抽取的语义信息去完成目标任务,从而给 Encoder “打鸡血”,鼓励它去抽取更多更优质的语义信息。
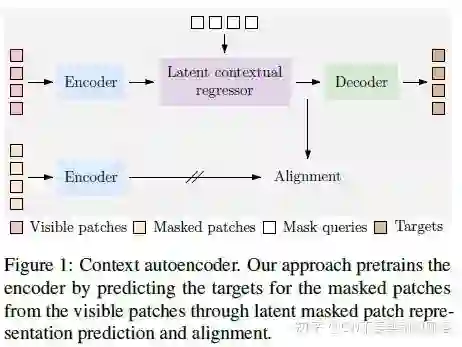
CAE
良药不苦口
药方有了,接下来就介绍下具体的药物成分以及治疗手段,CAE 十分有信心地对大家说:良药不一定苦口,也可以很香。
CAE 之所以能够防止 Decoder 偷偷学习特征、从而充分激发出 Encoder 抽取语义特征的潜能,主要靠的还是这家伙 —— Latent Contextual Regressor(CW 为了偷懒,后文均简称其为 'regressor')。它是一个在潜在特征空间中捕捉语义的模块,这个模块的设计十分巧妙,CAE 的精髓可以说都在其中了。它位于 Encoder 与 Decoder 之间,它既充当了“桥梁”的角色,又作为一道“屏障”,怎么说?继续听 CW 吹水(虽说是吹水,但也并非瞎说,我还是很认真的好不好)你就知道了~
这道屏障使得 Decoder “安守本份”
为什么说 regressor 是一道屏障?因为它“阻断”了 Decoder 学习特征的途径,让其专心负责解码任务(在这里是预测 masked patches 对应的 vision tokens,沿用了 BEiT 的做法),也就是 CW 所说的 “安守本份”。
具体怎么做的?CW 来为您揭晓:
首先,regressor 本质上就是一系列堆叠的带有 cross attention 层的类 transformer blocks,即每个 block 都是:cross attention->feed forward network(注意没有 self attention)。
regressor 有两部分输入:一部分是 masked tokens,对应 masked patches 的表征估计,在 attention 中作为 query,它是1个可学习的向量,对于所有图片的所有 masked patches 都一样,可看作是一种特征统计分布;另一部分是 un-masked patches 经过 Encoder 编码后的表征,它们与 maksed tokens 拼接(concat)在一起,作为 cross attention 中的 key & value 角色。
由此可以看出,regressor 的一个作用是从可见的视觉内容中(经过 Encoder 编码的 un-masked patches 的视觉表征)去捕捉所需的语义(通过 cross attention)。
接着,经过一些列堆叠的 blocks 后,regressor 仅将 masked tokens 表征送给 Decoder,之前来自 Encoder 的那部分它就“私吞”了。于是,Decoder 由于拿不到 Encoder 那部分 un-masked patches 的表征,因此无法“开小差”去学习表征提取了,只能专心负责完成解码任务。
最后,一起来回顾下:可见的那部分视觉内容的表征是 Encoder 编码好后送过来的,regressor 通过 cross attetnion 去捕捉所需的语义,Decoder 由于只拿到了 regressor 这个小气鬼给的 masked tokens 的表征而无法去更新 un-masked patches 对应的表征。于是,**视觉表征的抽取(学习)均由 Encoder 承担**,而 regressor 仅仅从已编码好的表征中捕捉所需的语义、Decoder 则专心地去完成解码任务。
是么!?(灵魂拷问,让你们心慌慌,hhh~)
这道屏障还有“内门”
以上,CW 故意调皮地对大家发起灵魂拷问,就是想让大家仔细斟酌下。
Decoder 无法偷偷学特征是没错,但是!regressor 可是拿到了 Encoder 的编码特征啊,它是可以偷偷学的!
Oh, my GOD! 此刻你们是不是瞬间崩溃,觉得无解了。因为尽管再在 Encoder & regressor 之间设置一个模块充当屏障,但那个模块本身也会偷偷学特征..
冷静,少年(哦,你说你是大叔,好吧~)。所谓解铃还须系铃人,因此解法不是在外部寻求门路,而是需要在屏障内部本身去寻找解。也如教员在《矛盾论》中所述:事物发展的根本原因在于事物内部的矛盾,因此,想要进步或者进一步发展,根源上要从内部去寻找解。
OK,CW 也不绕圈子了,解法就是:将 regressor 估计的 masked tokens 表征与 Encoder 对于 masked patches 进行编码得到的表征对齐。
但是,有个重要的前置操作就是需要将 masked patches un-mask 掉:也就是不要将这部分掩盖,而是将这部分的原图内容输入到 Encoder 进行编码,这样出来的编码结果才有参考意义(不然你给一堆盖住的乱码给 Encoder 你看看它会不会喷死你..)。
另外,Encoder 在做这部分操作时是一个推理过程,需要取消掉梯度(在 Pytorch 实现中可以用 torch.no_grad() 上下文管理器来包含这部分)。
不得不感叹这招真的相当妙啊!CW 当时看到这部分时不禁拍桌子叫好!这么搞相当于对 regressor 做了约束:无论 regressor 怎么去偷学特征,始终都要和 Encoder 对齐,regressor 的“最优参考标准”就是 Encoder 输出的表征。犹如在 regressor 这道屏障中设立了一道“内门”,在屏障内部也起到了一层阻断作用。
于是,有了这层约束后,regressor 就变成去专心去优化 masked token,它是基于数据的统计分布,作为 masked patches 的表征。虽然它拿到了 un-masked patches 表征,但这是为了去捕捉这部分中与 masked patches 强相关的上下文语义,regressor 估计出来的表征最终还是得与 Encoder 的表征对齐。
另外,关于这个对齐的效果(即验证 regressor 和 Encoder 的表征确实对齐了),CAE 也为大家进行了可视化展示:

以上的做法是,将 RGB 像素值作为解码目标(考虑到 token id 难以可视化)进行训练。训练完后进行测试,这时候将 regressor 去掉,直接将 Encoder 的输出送进 Decoder 去预测所有 patches 的 RGB 像素值。
可以发现,去掉了 regressor 也可以将图片重建出来,这说明 Encoder 输出的表征和 regressor 确实在同一个编码空间中,因为在训练时 Decoder 一直接受的都是 regressor 输出的表征,如果没有对齐的话,Decoder 是不会“认得” Encoder 输出的表征的。
这道桥梁使得 Encoder “努力拼搏”
截止到目前,我们已经了解 regressor 作为“屏障”的角色是如何发挥作用的了。但是,CW 也提到,regressor 同时还作为“桥梁”的角色,这究竟是咋回事捏?
不知各位江湖好友是否有思考过,Encoder 学习特征的“驱动力”来自于哪里?为何它能够进行优化,明明经过它编码的表征并未传递给 Decoder。
大家都是炼丹圈里的人,于是我们理所当然得从梯度传播的角度来进行分析。
首先,由于梯度传播是反向传播,因此我们就从最末端,也就是 Decoder 的头部开始,反向进行分析。经过损失函数的计算得到 loss,梯度会由 Decoder 解码的部分开始,沿头部反向传播,一直传播到 Decoder 的输入端,即 masked tokens。
接着来看,Decoder 拿到的 masked tokens 来自 regressor 的输出,它可不仅仅是 regressor 最初在其输入端设置的那一个自学习的向量,在输出端,它可是通过 cross attention 结合了 Encoder 编码的表征语义的。于是,梯度会沿两部分传播,其中一部分的效果当然是优化 masked token 这个自学习的向量本身;而另一部分则会沿 Encoder 对 un-masked patches 编码的表征传递。
然后,关键部分来了!要是没有将 regressor 的输出与 Encoder 对 masked patches 的图片内容进行编码而得到的表征对齐,那么这时候 regressor 就会有机会“偷偷”地优化 Encoder 对 un-masked patches 编码的表征,也就是它也承担了一部分特征抽取的责任,这样 Encoder 就不需要那么“努力”了(Em..有点躺平的味道~)。
最后,梯度便沿着 un-masked patches 的表征传递到 Encoder,使 Encoder 获得“驱动力”得以进行优化。
So, 由此我们再次体会到“将 regressor 的表征估计与 Encoder 对齐”这个操作的重要性,可以说这是 CAE 的大招也实至名归了。正是因为这波操作,避免了 regressor 偷学特征(防止城墙内有鬼),从而充分激发了 Encoder 学习特征抽取的潜能。也正是这样,CW 才说 CAE 设计的 regressor 同时承担着“屏障”与“桥梁”的角色。
妙!妙哇!喵~(咦,楼下的小猫窜场子了..)
传承
作为新青年,CAE 虽然有个性,但前辈们的优良传统还是继承了下来 —— 整体架构上沿袭了 Encoder & Decoder 的设计。
Encoder
如 MAE 前辈那样,CAE 的 Encoder 也只对 un-masked pathces 进行编码然后传递给后续的其它模块。但不同的是,如前文所述,Encoder 同时还对 masked patches 的原图内容(即不掩盖)做了推理,推理的结果则作为 regressor 对 masked tokens 估计的表征的参考目标,让 regressor 估计的表征与 Encoder 对齐,从而让特征学习的责任完全落到 Encoder 上。
这里有个在实现时的细节:考虑到 Encoder 是在训练的,其参数会不断改变,为了让 regressor 的训练更稳定,那么可以令它的参考目标,即:Encoder 的推理输出分布更稳定。于是,在实际做推理时,可以使用带动量的 Encoder,让它的参数更新幅度不那么大。
具体来说,首先设置一个动量值,标量即可,比如 0.3。然后,可以先将推理用的 Encoder 初始化为那个不断优化的 Encoder。最后,每次推理完,就进行动量更新:
其中, 和 分别表示推理用的 Encoder 权重与那个训练中不断学习的 Encoder 的权重。
Decoder
Decoder 可谓是“大众脸”了——长相既不清奇、技能也不风骚。它就是一系列堆叠的 transformer blocks,和 Encoder 一样,是没有 cross attention 层的,即每个 block 都是:self-attention->feed forward network。
它以 regressor 估计的 masked patches 表征作为输入,输出对应于 masked patches 的 vision tokens(沿用了 BEiT 的解码目标,使用 DALL-E tokenizer 对输入图像做 tokenize)。
合理配药
药方有了,想要治好病(MAE 说:你才有病~!),还得合理配药。在炼丹界,损失函数的设计就犹如配药,合理搭配好各项损失才能治愈。
其实,只要你认真阅读了前文,应该也能大致想到 CAE 的配药方式了,损失项就包括两样:Decoder 解码的 loss (i.e. decoding loss) 以及 regressor 估计的表征与 Encoder 对齐的 loss(i.e. alignment loss)。
其中,alignment loss 使用 MSE(Mean Square Error) loss,decoding loss 使用 CE(Cross Entropy) loss。另外,给 alignment loss 赋予了一个加权因子 (在作者的实验中设为2)用于平衡这两项损失。
所以,总的损失就是:
MIM 是更好的疗程
CAE 这位新青年不仅仅给大家详细介绍了自己的药方和配药方式,还进一步上升了一个高度:向大家论述了为何 MIM 这种掩码图像建模相比于对比学习来说是一种更好的疗程。
最主要的原因是:由于 MIM 的 masked patches 是随机在图片中选取的,最终又要恢复出这部分内容,因此这种做法就使得模型可以关注到图片上所有位置的表征,其中的一些区域并不一定属于图片中的物体。
相对地,对比学习这类方法通常要搭配 random crop 这种数据增强手段。当在 ImageNet 这类目标主体几乎都分布在图片中心区域的数据集上进行预训练时,crop 出来的部分,其区域几乎都包含了目标主体。于是,模型基于 crop 出来的部分去训练,最终就会造成其更多地仅关注到原图像的中心区域。这么一搞,模型学到的知识就主要是关于数据集目标类别(例如 ImageNet 的1000类)的,于是在泛化到其它下游任务时就并不那么具备通用性。
貌似不来张图片证实下感觉很虚..你们看咯:

由此可知,MIM 是更具“治愈性”的疗程,它让模型更能够关注到图片的各个区域,从而学到的表征更通用、在其它下游任务中更具有泛化性。
药效评估方法
虽然 CAE 为大家详细介绍了其药方以及配药方法,听起来头头是道,但实际的药效如何还是得通过客观合适的方式去评估。在这里,我们以图像分类任务、将 ImageNet 数据集作为例子来谈谈。
在自监督圈子里,linear probing 几乎是表征质量评估的“代言人”,它在预训练好的 Encoder(fix 住,此时不训练) 后接一个线性分类头(通常是 Linear 层)去微调(使用图像标签做监督学习),然后通过在验证/测试集上进行评估,看性能如何,从而最终反推出预训练好的 Encoder 提取的表征质量如何。
然而,CAE 和其前辈 MAE 一样,有模有样地说 linear probing 这种评估方式对它来说并不“公平”,因为它的 Encoder 提取的表征是关注到了图像所有区域的,而非主要关注图像中心区域的目标主体。
所以,无论是将 Encoder 提取的所有 patches 的表征进行均值池化后送入线性分类头、亦或是直接使用 Encoder 预训练好的 class token 都是不合适的,因为这些表征都并非是主要 care 图像物体的,而是一种更具泛化性的全局表示。
于是,有些江湖侠士就开喷了:“这么说难道就不用通过某种手段来评估你的效果了?直接默认你 CAE 就是牛逼的?离谱!”面对诸多质疑,CAE 这位新青年倒显得不急不躁,耐心地向大家介绍了一种既适合于它同时又公正的评估方式 —— attentive probing。
在具体介绍 attentive probing 的做法前先谈谈其出发点。既然 CAE 中的 Encoder 提取的表征是关注到所有图片区域的,而如今我们在下游评估时又以图像中的目标物体(i.e. 图像标签,即物体类别)作为目标,那么我们自然就要将与目标物体强相关的表征给抽取出来。
OK,motivation 清楚之后,就来看看 attentive probing 这种方法是如何实现的。
attentive probing 与 linear probing 的主要区别就是:在 Encoder 和 线性分类头之间接了一个 cross attention 模块,它将 Encoder 输出的表征作为 key&value,同时额外设置了一个可学习的 class token 作为 query(注意,并非是 Encoder 的 class token 哦!)。经过多层的 cross attention 后,再将输出的 class token 送到后面的线性分类头中进行分类。
很明显,由于在模型尾部(线性分类头最后面那部分)有图像标签作为监督,因此这个额外设置的 class token( cross attention 模块中的 query) 就会从 Encoder 输出的全局(图像所有区域)表征中抽取出与目标物体强相关的语义。
纳尼!?你不信啊?有图有真相的..

attentive probing
依然是不无聊的风格
啰里巴嗦了这么多,你们是否觉得 CW 变得只会吹水而偏离实际了。不会不会的,作为 coder 如果只吹水那也太无聊了(当然,不吹水更无聊..),CW 依旧不要无聊的风格,所以,代码解析还是会为各位大佬献上的。
CAE 的代码实现还是比较简洁的,如果有看过 CW 之前介绍 MAE 的那篇文章的源码解析部分的话,那么相信你会发现它们的套路还是挺相似的。
Forward
先来看看模型在训练时的一个前向反馈过程:
def forward_train(self, samples: Sequence, **kwargs) -> dict:
img, img_target, mask = samples
# 常规套路,对输入图像做归一化:减均值除标准差。
img_list = [self.img_norm(x).unsqueeze(0) for x in img]
# 拼接成一个 batch,此时 img.size(0) == batch_size
img = torch.cat(img_list)
img_target = 0.8 * img_target + 0.1
# 由于 mask 后续要施加在 patches 上,因此要将 (h,w) 维度展平为 (h*w,)。
mask = mask.flatten(1).to(torch.bool)
# 和 MAE 一样,backbone 也就是 Encoder,对 un-masked patches 编码,输出对应的表征。
unmasked = self.backbone(img, mask)
# 这部分是利用 Encoder 做推理,对 masked patches 位置的原图内容进行编码,
# 以得到对应的表征来作为 regressor 的参考目标。
with torch.no_grad():
# teacher 是指专门用来做推理的 Encoder,它是不进行训练学习的(其参数设置了 requires_grad = False),
# 但每次推理完它会进行“动量更新”(如以下的 momentum_update()),具体后面会解析。
# 注意,以下的是 '~mask',是 mask 的逆(也就是将 mask 中的 True|False 颠倒)
# 从而将遮盖掉的原图部分“掀开”,得到 masked pathces 的原图内容。
latent_target = self.teacher(img, ~mask)
# 以下之所以有 '1:' 也就是去掉最前面那个token(index=0)是因为它是 class token。
latent_target = latent_target[:, 1:, :]
self.momentum_update()
# 将 position embedding 的 shape 与 patches 对齐,然后分别获取 masked & un-masked 部分的 position embedding
# 注意,以下的 '1:' 也是因为要避开预训练的 ViT 的 class token 的影响,
# 因为 mask 是针对图像空间位置来设置的,并不含括 class token
pos_embed = self.backbone.pos_embed.expand(img.shape[0], -1, -1)
pos_embed_masked = pos_embed[:,1:][mask].reshape(img.shape[0], -1, pos_embed.shape[-1])
pos_embed_unmasked = pos_embed[:, 1:][~mask].reshape(img.shape[0], -1, pos_embed.shape[-1])
# neck 部分包含了 regressor & Decoder。
# 以下的 unmasked(Encider 的推理输出) 用于给 regressor 的 attention 作 key&value,至于 masked 表征则由 regressor
# 自行设置并且经过多层 cross attention layers 编码输出(得到以下的 latent pred),
# 然后传给 Decoder 解码,最终再接一个线性分类头预测出 logits。
logits, latent_pred = self.neck(unmasked[:, 1:], pos_embed_masked, pos_embed_unmasked)
# (b,n_masked_patches,c)->(b*n_masked_patches,c)
logits = logits.view(-1, logits.shape[-1])
# 别被骗了(hhh~),以下这个 head 仅仅是一个 loss 函数,并非是通常意义上模型中的头部结构。
# loss 计算分两部分,一部分是解码部分的损失,利用 logits & img_target 计算;
# 另一部分是 regressor 估计的表征与 Encoder 对齐的损失,利用 latent_pred & latent_target 进行计算。
# 注:这里 mask 用与从 img_target 提取出 masked patches 的部分,这个 img_target 是包括了整体图像的。
losses = self.head(img_target, logits, latent_pred, latent_target, mask)
return losses
在以上部分之外,还有关于 teacher(即推理用的 Encoder) 动量更新的部分未解析,放心,我不会拉下的,作为中华民族男子(其实我也可能是女子),言出必行还是应该的。
def momentum_update(self) -> None:
# 可以看到,其实就是设置1个动量值,
# 将训练中不断学习的 Encoder(即以下的 backbone) 参数和这个推理用的 Encoder(即以下 teacher) 参数按比例加权混合。
# 当 momentum = 1 时,相当于固定住 teacher,不会更新;
# 相反,当 momentum = 0 时,teacher 的参数就完全和 backbone 一样(在作者的实现中默认情况就是这样)。
for param_bacbone, param_teacher in zip(self.backbone.parameters(), self.teacher.parameters()):
param_teacher.data = param_teacher.data * self.momentum + param_bacbone.data * (1. - self.momentum)
哦,对了,teacher 的权重初始化也应该放出来让你们喵喵:
def _init_teacher(self) -> None:
# 其实就是初始化成 backbone,不过需要注意的是要将参数设置为不需要梯度(如以下 'requires_grad = False')
for param_backbone, param_teacher in zip(self.backbone.parameters(), self.teacher.parameters()):
param_teacher.detach()
param_teacher.data.copy_(param_backbone.data)
param_teacher.requires_grad = False
由于 backbone 太无聊,就是 ViT 那套,CW 在 MAE 那篇文中也讲过了,因此直接略过。接下来就看看 neck 部分吧,也就是包含了 regressor & Decoder 的那 part。
Neck
def forward(
self, x_unmasked: torch.Tensor,
pos_embed_masked: torch.Tensor,
pos_embed_unmasked: torch.Tensor
) -> Tuple[torch.Tensor, torch.Tensor]:
"""Get the latent prediction and final prediction.
Args:
x_unmasked (torch.Tensor): Features of unmasked tokens.
pos_embed_masked (torch.Tensor): Position embedding of masked tokens.
pos_embed_unmasked (torch.Tensor): Position embedding of unmasked tokens.
Returns:
Tuple[torch.Tensor, torch.Tensor]: Final prediction and latent prediction.
"""
# mask_token 仅仅是1个可学习的向量,对于所有 patches 所有图片都是一样的,
# 因此这里先扩展维度以方便后续的张量计算。
x_masked = self.mask_token.expand(x_unmasked.shape[0], self.mask_token_num, -1)
# regressor 就是多层 cross attention,
# un-masked & masked 表征拼接在一起作为 key&value。
for regressor in self.regressors:
x_masked = regressor(
x_masked, torch.cat([x_unmasked, x_masked], dim=1),
pos_embed_masked,
torch.cat([pos_embed_unmasked, pos_embed_masked], dim=1)
)
x_masked = self.norm_regressor(x_masked)
# regressor 估计的 masked patches 表征,它要与 Encoder 对齐。
latent_pred = x_masked
# Decoder 是多层 self-attention
x_masked = x_masked + pos_embed_masked
for decoder in self.decoders:
x_masked = decoder(x_masked)
x_masked = self.norm_decoder(x_masked)
# head 就是1个线性分类头(Linear 层)
logits = self.head(x_masked)
return logits, latent_pred
顺便放下 masked token 的初始化吧:
self.mask_token = nn.Parameter(torch.zeros(1, 1, embed_dims))
喏,看到没,就是1个向量。
(貌似 neck 这部分也挺无聊的..)
Head
有始有终,最后,将 head 部分(注意,如前文所述,这部分的 head 实质上是一个 loss 函数的计算过程,并非模型结构上的 head)也讲完吧。
def forward(
self, img_target: torch.Tensor, outputs: torch.Tensor,
latent_pred: torch.Tensor, latent_target: torch.Tensor, mask: torch.Tensor
) -> dict:
losses = dict()
# 利用 tokenizer 得到 patches 对应的 vision tokens
target = self._generate_target(img_target)
# 取出 masked patches 对应的部分作为最终的解码目标,解码 loss 仅针对 masked patches 计算。
target = target[mask]
# 解码部分的 loss:交叉熵损失
loss_main = self.loss_cross_entropy(outputs, target)
# regressor 与 Encoder 编码空间对齐的 loss: 均方误差损失,lambd 用于加权平衡。
# 其中 latent_pred 是 regressor 估计的 masked patches 的表征,
# latent_target 是 推理用的 Encoder 对 masked patches 位置的图像内容编码得到的表征。
loss_align = self.loss_mse(latent_pred, latent_target.detach()) * self.lambd
losses['loss'] = loss_main + loss_align
losses['main'] = loss_main
losses['align'] = loss_align
return losses
以上产生解码目标,即 _generate_target() 那部分也放一下,不然你们肯定很难受:
@torch.no_grad()
def _generate_target(self, img_target: torch.Tensor) -> torch.Tensor:
# 这里的 encoder 就是1个 tokenizer,注意不要和 CAE 的 Encoder 混淆了。
logits = self.encoder(img_target)
target = torch.argmax(logits, dim=1)
# 展平,将图像二维展平为 patches 一维,以便后续计算损失。
return target.flatten(1)
关于源码的解析,CW 主要针对一些核心部分,更多细节欢迎大家去参考 repo:
https://github.com/open-mmlab/mmselfsup/blob/master/mmselfsup/models/algorithms/cae.py
or 作者的实现:
https://github.com/lxtGH/CAE
解码目标的选择
在本文的结尾部分(舍不得与你们说 byebye 咯~),CW 想谈谈解码目标这个点。虽说这部分不算是核心,毕竟我们更多地关注在如何让 Encoder 学会提取更优质的表征,但就 CAE vs MAE 这方面来说,我之前始终感觉它们解码形式的不一致可能会导致 CAE 有“作弊”的嫌疑:很有可能 CAE 的方法只是搭配 vision token 做预训练效果才比较好,如果换成是解码 RGB 像素值可能就不那么理想了,毕竟传给 Decoder 的是具有高级语义表征,从高级语义->低级语义(RGB)可能并不太容易,可能需要更仔细地去设计 Decoder。
后来,结合作者的理解(感谢作者大大~),CW 自己也悟了:
首先,由于 CAE 最初的设计是基于 BEiT 的 codebase 去做的,于是就沿用了 vision token 的解码形式。
其次,vision token 也并非都具有高级语义(如 dalle 的 tokenizer 直接拿 RGB 作为重建目标,里面基本是 RGB 像素值到离散区间的映射)。
然后,尽管是预测 RGB 像素值,在掩码率很高的情况下也没办法通过插值得到,这就要求 Decoder 的输入本身得拥有一定程度的语义信息,这样才能解码出来。
最后,使用 vision token 与 RGB 像素值作为解码目标的主要不同之处在于:vision token 是拿 CE loss 做监督,而 RGB 像素值拿 MSE loss 做监督。更换语义信息不同的 vision token 作为解码目标,训练超参基本不用变(于是 CAE 能够很方便地沿用 BEiT 的 codebase);而如果将解码目标换为 RGB 像素值,由于 MSE loss 比 CE loss 通常小一个量级,因此很可能需要重新调参。从这点来说,vision token 这种形式就更具有扩展性。
Update: 悟
这部分是近几天(current is 2022/06/28)读了一些 paper 后悟到的一些理解:
-
CAE 的做法实质上是在 MIM(掩码图像建模) 的基础上加多了一个建模任务——掩码 表征建模(我姑且称其为 'MRM', R 代表 Representation),通过 regressor 与 Encoder 对齐来实现,其中 prediction 是 regressor 估计的 masked patches 表征,target 是 Encoder 根据 masked patches 的位置在图片中对应提取的表征; -
基于以上第1点,或许给到了我们这样一个启示: 掩码表征建模 可能比 掩码图像建模 更为“强大”。毕竟 pretrain task 是为了让 Encoder 拥有更强大的表征提取能力,那么直接在表征层(如 paper 中所述的 潜在编码空间)而非低语义级的原始图像去建模是不是来得更加直接&有用? -
在以上第2点的启示下,那么 是否可以将 CAE 中的 regressor 去掉,将自学习的 masked tokens 结合 Encoder 编码的 un-masked tokens 输入到 Decoder,Decoder 中设置 cross attention 让两种 tokens 交互最终估计出 masked tokens 的表征,与 Encoder 对齐。如同 regressor 一样,由于有了对齐,因此 Decoder 即使接受了 Encoder 输出的 un-masked 表征也无法(或者说重心不在这)“偷偷”优化,而是专注于解码出表征; -
在以上第3点更进一步, 为了增强泛化性,Encoder 输出的作为对齐部分的 target,可以是在原图做了 augmentation 的基础上进行编码而得到的表征。至于具体的数据增强手段,可以先尝试参考对比学习的做法,如 random crop, color jitter 等。但如果用了 cropping 相关的手段,那么用于 prediction 部分的 Encoder 输入也要做相应的 cropping,确保位置关系能对应起来(或者通过另外的位置编码计算方式建立这不同 cropping 视图之间位置关系的联系)。
以上仅仅是 CW 脑洞的一些 idea,大佬们如果有指导意见尽管在留言区“教育”我。尽管可能会经受严格的“思想教育”,但后续如果 CW 一不小心又胡思乱想一些点还是也会记录上来(hhh! 我是顽固分子)..
公众号后台回复“项目实践”获取50+CV项目实践机会~

“
点击阅读原文进入CV社区
收获更多技术干货
