动手做个DialoGPT:生成式多轮对话模型

语料简介
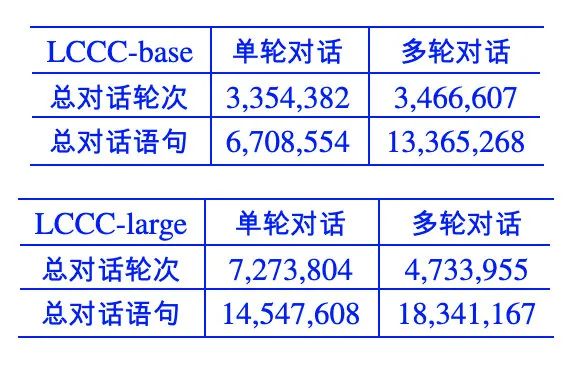
A: 等过年咱们回去买点兔头好好吃顿火锅
B: 太原就没看见有好吃的兔头
A: 我从虹桥给你带个回去那天瞅到一正宗的
B: 最爱你了
A: 那是必须A: 嗯嗯,我再等等!你现在在上海吧?上海风好像比南京还大呢,少出门吧
B: 对啊,我在家,没事儿。一定要小心啊!A: 我去年也去转了一圈,还碰见以前的体育老师了,合了个影
B: 哈哈我还去找高一时侯的英语老师没找到她刚好有事情没在学校~
A: 你也是真心找回忆了哦
B: 哈哈毕业了没去过想去看看啊
模型设计
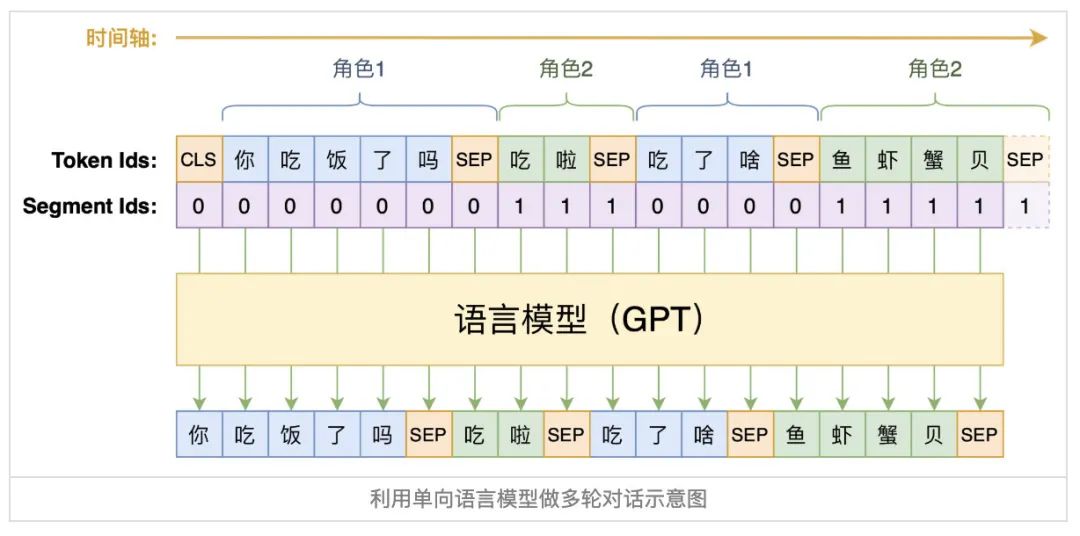
训练细节
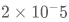 的学习率、0.01的权重衰减率的Adam优化器进行训练的,训练了1000万步(20多天),单步batch_size为16,累积梯度步数为16,所以相当于以256的batch_size训练了62.5万步,最终的loss大概是2.83(平均每个token的交叉熵)。
的学习率、0.01的权重衰减率的Adam优化器进行训练的,训练了1000万步(20多天),单步batch_size为16,累积梯度步数为16,所以相当于以256的batch_size训练了62.5万步,最终的loss大概是2.83(平均每个token的交叉熵)。
>>> print(chatbot.response([u'我最近天天吃火锅']))
火锅好吃啊
>>> print(chatbot.response([u'我最近天天吃火锅']))
我也是
>>> print(chatbot.response([u'我最近天天吃火锅']))
哈哈哈哈哈哈我最近一周吃了两顿火锅
>>> print(chatbot.response([u'我最近天天吃火锅']))
我也是,每次都吃的撑
>>> print(chatbot.response([u'我最近天天吃火锅']))
吃火锅不长胖
>>> print(chatbot.response([u'我最近天天吃火锅']))
火锅好啊
>>> print(chatbot.response([u'我最近天天吃火锅']))
你们那边有这种火锅?
>>> print(chatbot.response([u'我最近天天吃火锅']))
火锅好吃吗?我也想吃
>>> print(chatbot.response([u'我最近天天吃火锅']))
吃吧,吃了就开心了
>>> print(chatbot.response([u'我最近天天吃火锅']))
我也想天天吃火锅!
>>> print(chatbot.response([u'我最近天天吃火锅']))
火锅吃不了多久的。>>> print(chatbot.response([u'你那天气好吗']))
还好,不热,有点冷
>>> print(chatbot.response([u'你那天气好吗', u'还好,不热,有点冷', u'那你得穿多厚的衣服']))
我穿了两件
对比分析

文章总结
[2] CDial-GPT-tf:https://github.com/bojone/CDial-GPT-tf

点击阅读原文,直达“CCF-NLP走进高校之郑州大学”直播页面!
登录查看更多
相关内容
专知会员服务
37+阅读 · 2020年4月10日
微软发布DialoGPT预训练语言模型,论文与代码 Large-Scale Generative Pre-training for Conversational Response Generation
专知会员服务
28+阅读 · 2019年11月8日
Arxiv
5+阅读 · 2019年11月1日
Arxiv
8+阅读 · 2019年8月30日
Arxiv
4+阅读 · 2018年6月11日





相关VIP内容
专知会员服务
37+阅读 · 2020年4月10日
微软发布DialoGPT预训练语言模型,论文与代码 Large-Scale Generative Pre-training for Conversational Response Generation
专知会员服务
28+阅读 · 2019年11月8日
相关资讯
相关论文
Arxiv
5+阅读 · 2019年11月1日
Arxiv
8+阅读 · 2019年8月30日
Arxiv
4+阅读 · 2018年6月11日