条件随机场知识整理(超长文!)

最近用条件随机场完成了一个任务,效果不错,总结起来感觉收获很大,我来给大家谈谈有关条件随机场的理论和有关的落地方案。
理论
有关条件随机场的理论,其实大量材料都讲的很完整,嗯,我用的是完整,因为难度真的不低,下面简单总结一下我看的比较好的材料。
《统计学习方法》第二版,李航。这应该是有关条件随机场完整的解释了。
条件随机场(CRF):https://blog.csdn.net/Scythe666/article/details/82021692。整个有关知识的链路解释的都比较清楚。
当然,我肯定不是放了资料就走的,我来说说我对CRF的理解线路,角度可能比较特别,可供大家协助理解,当然的,有关细节知识还要靠大家仔细啃的。
大量的材料都是从概率无向图,向条件随机场的角度去讨论,但是我比较喜欢从条件随机场,尤其是线性链条件随机场的概念出发理解,然后引入团和概率无向图的因子分解来解释和处理;理解这两个概念后,用HC定理解释其参数化形式、简化形式和矩阵形式,这样一来,整个条件随机场的运作就会比较明显了在此基础上,概率图的三大问题就会迎刃而解——概率问题、参数估计问题和预测问题。
条件随机场的概念
条件随机场其实定义不是特别难。

简单地说,对于特定位置的Y,他在已知特征且Y相邻点的条件下的概率,与已知条件且不与Y相邻点的条件下的概率,是相同的。这个概念能在线性链条件随机场上能体现的更加清晰。

相邻和不相邻的概念非常清晰,对于Y(t),相邻的其实就是Y(t-1)和Y(t+1),其他的就是不相邻的。看图。
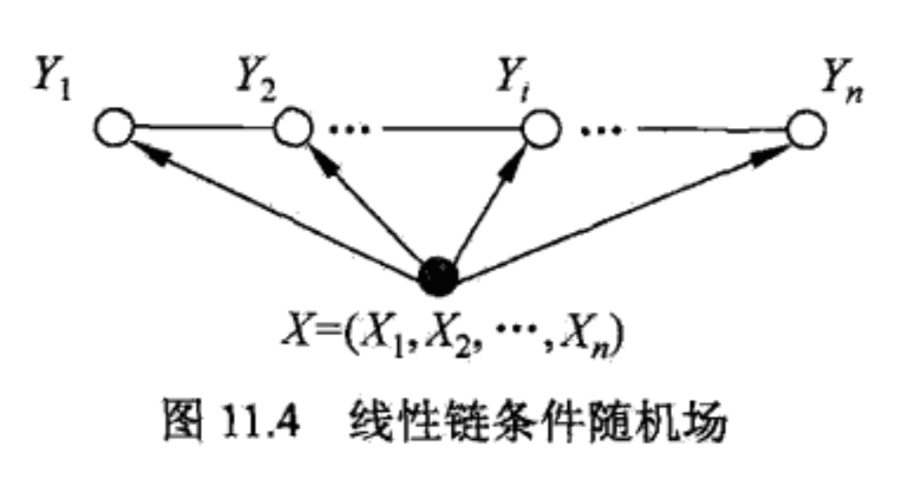
其实理解了条件随机场的定义,但是不够,要做预测我们是需要知道P(y|x)的直接关系,不能依赖y的上下文,因此我们要进行分解,要进行分解,我们引入图论里面团的概念,从而推导出条件随机场的多种形式。
条件随机场的形式
Hammersley-Clifford定理直接给出:

在导出条件随机场的参数化形式之前,来继续看看里面的势函数,即上面提到的严格正函数,一般地,使用指数函数。
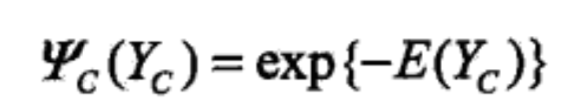
划重点,这里里面是每个最大团对应的数学期望。
这个一个定理的实质就是找到联合变量和概率图中的随机变量的概率的关系,有了这个定理,我们可以推导出线性链条件随机场的参数化形式:
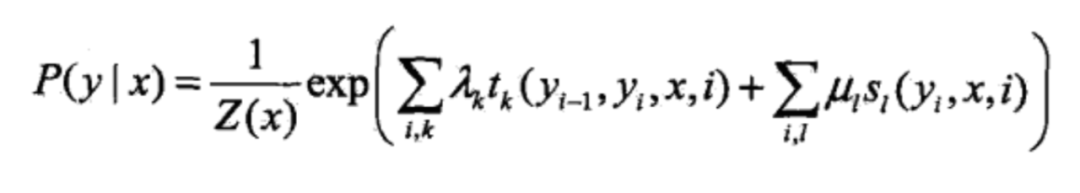
括号里面实质上就是数学期望,可以这么理解,但更像是是一种逼近方法,在这种逼近方法下,且t和s的功能相似的情况下,我们可以给出更加抽象的表示,首先是特征函数:
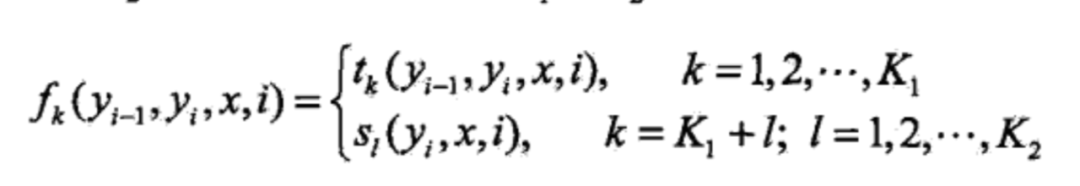
然后是权重,可以抽象为待估参数:
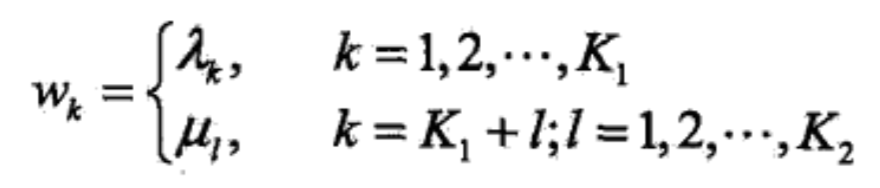
于是就有:
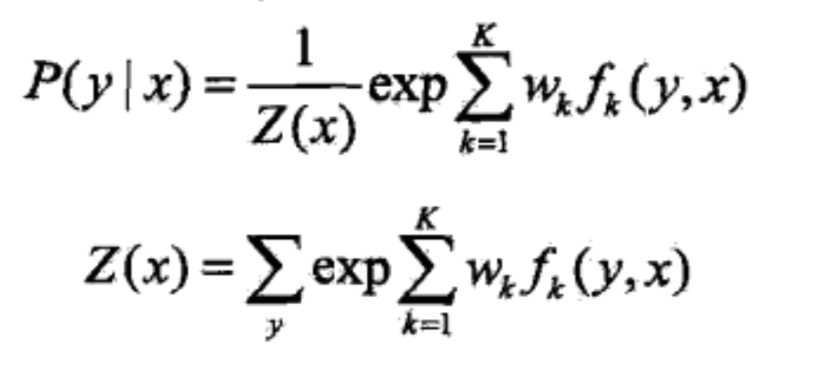
条件随机场是判别模型的含义
条件随机场是判别模型,这点在我刚看到结论的时候是很吃惊的,毕竟在大部分常规下,概率类的模型都是生成模型,例如朴素贝叶斯和隐马尔可夫,尤其是隐马尔可夫,和条件随机场如此类似,条件随机场为什么会是判别模型?
判别模型和生成模型的概念区别不是在于建模的类型,而是建模的角度,生成模型重在预测特征和标注的联合分布,然后借助条件概率预测P(Y|X),而判别模型则是重在后者,是判别模型还是生成模型,其实就是看两者的训练过程。
身为生成模型的朴素贝叶斯,先计算先验概率和条件概率,然后计算特征下属于每个类的概率,取最大值最终得到的分类,实质上是计算先验概率和条件概率;而隐马尔可夫的学习算法在于估计状态转移概率矩阵和观测概率分布矩阵,实质是EM算法。但是条件随机场并非如此,条件随机场的学习是借助标注构建损失函数,通过最小化损失的方式学习上述参数,从而得到结果,此过程其实并不需要知道联合分布,因此条件随机场就是一个判别模型。
说个不太严格的观点,有明确的损失函数(隐马尔可夫是需要使用EM算法逼近的不算),可以通过最优化方法进行求解的(SVM也有明确的损失函数,但是本身并非处处可导,所以采取了特殊的手段,但这并不影响他是一个判别模型),基本上就可以认为是判别模型了,说白了你还是要知道原理,才能知道是不是判别。
我想就说到这里啦,条件随机场到这其实就理解了整体结构,熟悉隐马尔可夫的小伙伴,其实就知道下面的操作了,我一直认为隐马尔可夫是条件随机场的重要基础,有向图对条件概率的解释会更加清晰,在理解隐马尔可夫后,在上面的一系列定义下(没错,上面的所有,基本上都是定义),求解的方法就很类似了
概率问题:前向算法和后向算法,和隐马尔可夫类似。
学习问题:这个和隐马尔可夫不同,由于有明确地损失函数,且可导,所以可以使用梯度下降法处理,甚至,可以借助收敛性更强的拟牛顿法进行求解。
预测问题:维特比算法,和隐马尔可夫类似。
TF方案
tensorflow之前自己其实写过一个demo,也是命名实体识别的。
来看看CRF这块是怎么操作的:
with tf.name_scope("crf"):
# CRF
sequence_lengths = np.full(
self.config.batch_size, self.config.seq_length, dtype=np.int32)
self.shape1 = sequence_lengths
log_likelihood, self.transition_params = tf.contrib.crf.crf_log_likelihood(
dense_out, self.input_y, sequence_lengths)
self.viterbi_sequence, self.viterbi_score = tf.contrib.crf.crf_decode(
dense_out, self.transition_params, sequence_lengths)
首先是 tf.contrib.crf.crf_log_likelihood,这是一个对数似然的接口。
在之前的文章中我给出了这个借口的源代码,这次来详细说说吧:
def crf_log_likelihood(inputs,
tag_indices,
sequence_lengths,
transition_params=None):
"""Computes the log-likelihood of tag sequences in a CRF.
Args:
inputs: A [batch_size, max_seq_len, num_tags] tensor of unary potentials
to use as input to the CRF layer.
tag_indices: A [batch_size, max_seq_len] matrix of tag indices for which we
compute the log-likelihood.
sequence_lengths: A [batch_size] vector of true sequence lengths.
transition_params: A [num_tags, num_tags] transition matrix, if available.
Returns:
log_likelihood: A [batch_size] `Tensor` containing the log-likelihood of
each example, given the sequence of tag indices.
transition_params: A [num_tags, num_tags] transition matrix. This is either
provided by the caller or created in this function.
"""
# Get shape information.
num_tags = inputs.get_shape()[2].value
# Get the transition matrix if not provided.
if transition_params isNone:
transition_params = vs.get_variable("transitions", [num_tags, num_tags])
sequence_scores = crf_sequence_score(inputs, tag_indices, sequence_lengths,
transition_params)
log_norm = crf_log_norm(inputs, sequence_lengths, transition_params)
# Normalize the scores to get the log-likelihood per example.
log_likelihood = sequence_scores - log_norm
return log_likelihood, transition_params
这里面4个参数:
inputs:batchsize x maxseqlen x numtags的三维矩阵,即是上一层结果的输入。tag_indices:batchsize x maxseq_len的二维矩阵,是标签。sequence_lengths:batch_size向量,序列长度。transition_params:numtags x numtags的状态转移矩阵,可以为空。
返回2个结果:
log_likelihood:对数似然值。transition_params:状态转移矩阵。
此处核心就是为了计算对应数据和标注之间的对数似然值。
另外还有预测方法,使用的是维特比算法,下面给出这个算法的源码。
def crf_decode(potentials, transition_params, sequence_length):
"""Decode the highest scoring sequence of tags in TensorFlow.
This is a function for tensor.
Args:
potentials: A [batch_size, max_seq_len, num_tags] tensor of
unary potentials.
transition_params: A [num_tags, num_tags] matrix of
binary potentials.
sequence_length: A [batch_size] vector of true sequence lengths.
Returns:
decode_tags: A [batch_size, max_seq_len] matrix, with dtype `tf.int32`.
Contains the highest scoring tag indices.
best_score: A [batch_size] vector, containing the score of `decode_tags`.
"""
# If max_seq_len is 1, we skip the algorithm and simply return the argmax tag
# and the max activation.
def _single_seq_fn():
squeezed_potentials = array_ops.squeeze(potentials, [1])
decode_tags = array_ops.expand_dims(
math_ops.argmax(squeezed_potentials, axis=1), 1)
best_score = math_ops.reduce_max(squeezed_potentials, axis=1)
return math_ops.cast(decode_tags, dtype=dtypes.int32), best_score
def _multi_seq_fn():
"""Decoding of highest scoring sequence."""
# For simplicity, in shape comments, denote:
# 'batch_size' by 'B', 'max_seq_len' by 'T' , 'num_tags' by 'O' (output).
num_tags = potentials.get_shape()[2].value
# Computes forward decoding. Get last score and backpointers.
crf_fwd_cell = CrfDecodeForwardRnnCell(transition_params)
initial_state = array_ops.slice(potentials, [0, 0, 0], [-1, 1, -1])
initial_state = array_ops.squeeze(initial_state, axis=[1]) # [B, O]
inputs = array_ops.slice(potentials, [0, 1, 0], [-1, -1, -1]) # [B, T-1, O]
# Sequence length is not allowed to be less than zero.
sequence_length_less_one = math_ops.maximum(
constant_op.constant(0, dtype=sequence_length.dtype),
sequence_length - 1)
backpointers, last_score = rnn.dynamic_rnn( # [B, T - 1, O], [B, O]
crf_fwd_cell,
inputs=inputs,
sequence_length=sequence_length_less_one,
initial_state=initial_state,
time_major=False,
dtype=dtypes.int32)
backpointers = gen_array_ops.reverse_sequence( # [B, T - 1, O]
backpointers, sequence_length_less_one, seq_dim=1)
# Computes backward decoding. Extract tag indices from backpointers.
crf_bwd_cell = CrfDecodeBackwardRnnCell(num_tags)
initial_state = math_ops.cast(math_ops.argmax(last_score, axis=1), # [B]
dtype=dtypes.int32)
initial_state = array_ops.expand_dims(initial_state, axis=-1) # [B, 1]
decode_tags, _ = rnn.dynamic_rnn( # [B, T - 1, 1]
crf_bwd_cell,
inputs=backpointers,
sequence_length=sequence_length_less_one,
initial_state=initial_state,
time_major=False,
dtype=dtypes.int32)
decode_tags = array_ops.squeeze(decode_tags, axis=[2]) # [B, T - 1]
decode_tags = array_ops.concat([initial_state, decode_tags], # [B, T]
axis=1)
decode_tags = gen_array_ops.reverse_sequence( # [B, T]
decode_tags, sequence_length, seq_dim=1)
best_score = math_ops.reduce_max(last_score, axis=1) # [B]
return decode_tags, best_score
return utils.smart_cond(
pred=math_ops.equal(potentials.shape[1].value or
array_ops.shape(potentials)[1], 1),
true_fn=_single_seq_fn,
false_fn=_multi_seq_fn)
这里面3个参数,即输入向量和状态转移矩阵即可:
inputs:batchsize x maxseqlen x numtags的三维矩阵,即是上一层结果的输入。sequence_lengths:batch_size向量,序列长度。transition_params:numtags x numtags的状态转移矩阵。
返回2个结果:
decode_tags:batchsize x maxseq_len矩阵,对应每个输入的标注结果。best_score:batch_size 向量,表示每个样本预测结果的打分。
有这两个,基本就能把CRF给用起来,当然的,tensorflow给出非常丰富的crf接口,可以参考下面两个连接:
官方文档:https://tensorflow.google.cn/versions/r1.12/api_docs/python/tf/contrib/crf
源码:https://github.com/tensorflow/tensorflow/blob/r1.12/tensorflow/contrib/crf/python/ops/crf.py
CRF++方案
不看官方文档直接用绝对是不行的,下面的内容其实基本上都是基于官方文档整理的:
https://taku910.github.io/crfpp/
https://github.com/taku910/crfpp
这个其实并不是新工具,看他的更新时间其实都好久了。
先简单介绍一下吧,crf++是一个基于c++的条件随机场序列标注工具,除了c++外还有Perl/Ruby/Python/Java接口。
这次,我打算说原生c++的工程。
打开方式
我的环境CentOS,Linux环境,MacOS环境也可以,另外需要gcc3.0以上的环境,另外需要make构建工具。
下载地址在这里:https://drive.google.com/folderview?id=0B4y35FiV1wh7fngteFhHQUN2Y1B5eUJBNHZUemJYQV9VWlBUb3JlX0xBdWVZTWtSbVBneU0&usp=drive_web#list。
./configure
make
su
make install
很多人可能没有sudu权限,所以make install可能搞不定,我这里有一个方案,链接在这里:https://www.jianshu.com/p/0ef082354fc9。在这里简单说说原理,c++通过make一般打包为静态库或者动态库,而使用的时候需要默认去一个路径读取,链接里面的方法,就是增加这个读取路径。
构建训练集和测试集
训练集格式是这样的:
我 O
今天 O
想学 O
条件 MB
随机 MI
场 ME
隐 MB
马尔可夫 ME
一般的一共有N列,前N-1列都是特征,每一列是一种,最后一列是标注,每句话之间空行隔开。
测试集一般地会比训练集少一列,但是其实多一列不会有太大影响,他也不会用,并且在进行预测后,他会增加一列是他的预测结果。
构建规则模板
参考了这里的信息:https://www.cnblogs.com/gczr/p/10026567.html
CRF++里面要构造一个规则模板(TF为什么没有?原因可以看看两者的源码),根据规则模板来整理出条件随机场的结构。
# Unigram
U00:%x[-2,0]
U01:%x[-1,0]
U02:%x[0,0]
U03:%x[1,0]
U04:%x[2,0]
U05:%x[-1,0]/%x[0,0]
U06:%x[0,0]/%x[1,0]
# Bigram
B
下面其实就是一个实例规则模板。
这里分为两个部分,一个是Unigram,一个是Bigram,很显然就是让你定义N-Gram相关规则的。
以Unigram为例吧,以第一行为例,U00是Unigram的第0个规则,冒号后会看到有一个 %x[-2,0]的二元组,这个二元组是这么个含义:对第一个值,对于一句话的特定位置i,定义他的位置为0,则-2表示他前面第二个位置的内容,即表示的是行信息,第二个值就是列信息。有这个二元组,就能去构造转移函数。
说的有点玄乎,我来举个栗子,假设有这句话:
小 B
明 I
今 B
天 I
穿 S
了 S
一 B
件 I
红 B
色 I
上 B
衣 I
假设当前词是“今”,则有:
U00:%x[-2,0]=====>小
U01:%x[-1,0]=====>明
U02:%x[0,0]=====>今
U03:%x[1,0]=====>天
U04:%x[2,0]=====>穿
U05:%x[-2,0]/%x[-1,0]/%x[0,0]=====>小/明/今
U06:%x[-1,0]/%x[0,0]/%x[1,0]=====>明/今/天
U07:%x[0,0]/%x[1,0]/%x[2,0]=====>今/天/穿
U08:%x[-1,0]/%x[0,0]=====>明/今
U09:%x[0,0]/%x[1,0]=====>今/天
以U00为例就能够得到一系列转移函数:
func1=if(output=B and feature=’U00:小‘ ) return 1 else return 0
func2=if(output=I and feature=’U00:小’) return 1 else return 0
func3=if(output=S and feature=’U00:小) return 1 else return 0
类似的,对于Bigram,实质上就是增加了一个过去的标签信息:
func1 = if(prev_output = B and output = B and feature=B01:"北") return 1 else return 0
训练
在源码的bin路径下,会有一个 crf_learn,就执行他就行:
./crf_learn template_file train_file model_file
带入模板文件和训练数据即可,最后补一个模型的名字,当然的,你可以有一些自定义参数:
-a CRF-L2 or CRF-L1:正则化。
-c float:CRF超参数。
-f NUM:迭代次数。
-p NUM:多线程训练。
不用看源码,构件好后直接训练,真的很方便对吧。
测试
crf_test -m model_file test_files
必要参数 -m要带入模型文件,另外就是测试集了。
里面还有两个比较重要的参数:
结果级别
-v:默认是0,v1会给你整体预测的打分和句子内每个位置的标签的打分,v2会把其他可选项的打分也给你。备选结果个数
-n:给出N个可行结果,你可以根据自己的需要选择。
工程上的说明
上面的内容在进行线下实验的时候,很方便,但是建立工程,那就不这么好用了。
所有的接口,其实都在 crfpp.h里面。整个项目核心就是2个类:Model和Tagger,前者构建模型,后者负责整合模型,完成标注任务,所以在起项目的时候,是先用Model加载模型,然后构造Tagger,然后通过Tagger继续预测。
CRFPP::Model*crf_model = CRFPP::createModel("-m ./model -v 3 -n2");
CRFPP::Tagger*tagger = crf_model->createTagger();
tagger->clear();
加载模型后,就可以开始用模型进行预测了。
首先是,用分好词的句子,一个接着一个放入模型。
tagger->add((*term).c_str());
放入之后,其实就可以开始预测了,预测的时候,就一个一个把结果吐出来组合。
string tag = tagger->y2(i)
这里面的 y2是吐出每个位置的标签结果。
一个踩过的坑
多线程的时候,CRF++启动模型,一个线程只能有一个模型,否则会产生指针公指,读脏数据之类的问题,最终可能导致dump。
由于微信平台算法改版,公号内容将不再以时间排序展示,如果大家想第一时间看到我们的推送,强烈建议星标我们和给我们多点点【在看】。星标具体步骤为:
(1)点击页面最上方"AINLP",进入公众号主页。
(2)点击右上角的小点点,在弹出页面点击“设为星标”,就可以啦。
感谢支持,比心

推荐阅读
征稿启示| 200元稿费+5000DBC(价值20个小时GPU算力)
完结撒花!李宏毅老师深度学习与人类语言处理课程视频及课件(附下载)
模型压缩实践系列之——bert-of-theseus,一个非常亲民的bert压缩方法
文本自动摘要任务的“不完全”心得总结番外篇——submodular函数优化
斯坦福大学NLP组Python深度学习自然语言处理工具Stanza试用
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLPer(id:ainlper),备注工作/研究方向+加群目的。
阅读至此了,分享、点赞、在看三选一吧🙏


