论文浅尝 | emrKBQA: 一个面向临床医疗问答的KBQA数据集
笔记整理 | 谭亦鸣,东南大学博士生

来源:BioNLP ’21 workshop, ACL ‘21
链接:https://www.aclweb.org/anthology/2021.bionlp-1.7.pdf
论文主要包含两个部分的核心工作:emrKBQA数据集,对应的benchmark。基于MIMIC-III KB,本文提出了一个面向临床医疗问答的KBQA数据集,emrKBQA,规模约为940K,包含389种提问类型,每种类型有约7.5种复述表达。为了验证数据集的质量,作者建立了一个benchmark,其模型流程可以大体描述为:通过语义解析预测问题逻辑结构,而后借助逻辑结构构建SQL查询指向答案。
贡献
论文建立了emrKBQA,第一个面向结构化病历记录的大规模社区共享问答数据集
数据集能够用于建模,解决基于结构化HER的问题解析及问答
作者为基于结构化病历记录的问答数据集建立了benchmark
背景与动机
电子病历EHRs和临床记录Clinics note在医疗过程中常常被作为临床诊断决策的支撑材料,因此,使机器理解和学习这些资料用于临床决策辅助是一个明确的未来趋势。
在以往的研究中,基于临床记录的emrQA问答数据集(2018)被提出,通过一个半自动的问题生成过程,这个数据集涵盖接近1M的问答对以及问题-逻辑结构对。
但是emrQA仅仅是利用到了临床记录这一资源,而没有充分利用EHRs,作者认为,一个完整的临床医疗问答系统应该同时利用好上述这两个资源。
因此,本文作者提出emrKBQA用于补充这一空白。
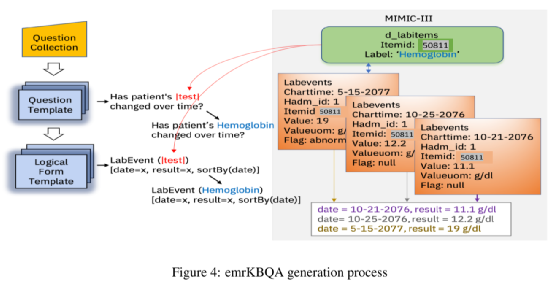
MIMIC-III KB被用作emrKBQA的知识库资源,如图1所示,左侧列出了该数据集中一些问题(和复述)的例子,右侧则是知识库里的答案形式。

数据集构建
根据论文的描述,emrKBQA的建立过程可以描述为以下步骤(半自动,如图4):
1.从emrQA获取初始问题
2.从初始问题中挖空(使用slot替换原本的实体,slot放置该实体对应的类别标签)形成模板template(提问形式)
3.医疗专家参与实体类别归纳
4.构建提问类型的逻辑形式
5.归并具有相同逻辑形式的提问形式(互为复述)
6.向template中填入合适的实体,得到问题/复述
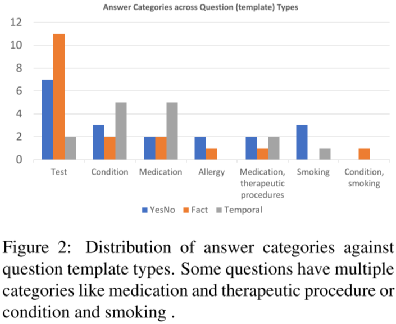
这里作者根据答案的特点将问题类型分为三种:事实,是非和时间,实际问题中可能同时涵盖这三类中的一个或多个。
图2列出了:各实体大类中问题类型的分布情况
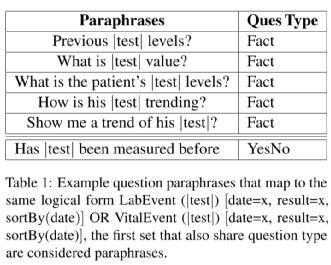
生成的问题如表1所示:
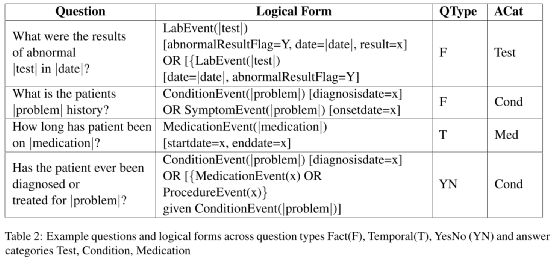
问题-逻辑形式-问题类型-答案类型如表2所示:
任务定义和模型
作者明确给出了本数据集对应的任务定义:
建模,对输入的知识库相关的问题,给出对应的答案
模型分为两个过程:
1.语义解析->逻辑结构
参照Gu et al, 2016的工作建立了一个seq2seq模型
2.逻辑结构->答案
具体为一组连续的映射构建(基于序列相似性得到):
问题->Template->SQL template->logical form
评价方式包含两个:
1.语义解析过程使用EM(Exact Match),即模型输出与标注结果相同算正例
2.答案生成过程使用Denotation Accuracy,即答案和逻辑结构均与标注结果相同算正例
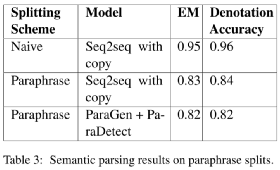
实验结果如表3所示
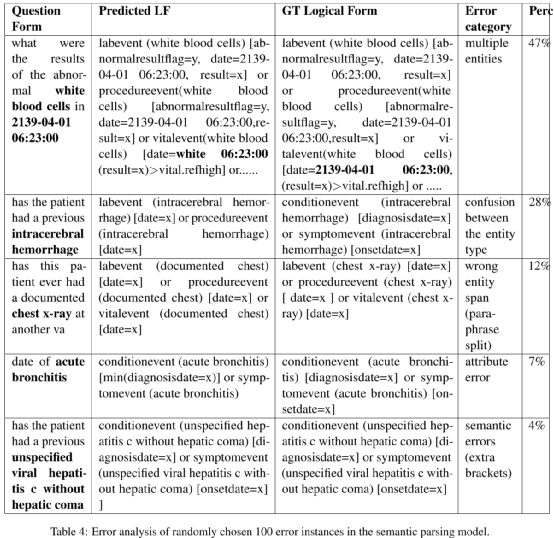
作者进一步做了一些错误分析,如下表:
OpenKG
OpenKG(中文开放知识图谱)旨在推动以中文为核心的知识图谱数据的开放、互联及众包,并促进知识图谱算法、工具及平台的开源开放。

点击阅读原文,进入 OpenKG 网站。




